注意力机制【译】
非常好的一篇关于注意力机制的博客,翻译如下以飨读者。
自从2015年深度学习和人工智能兴起以来,许多研究者开始对神经网络中的注意力机制开始感兴趣。这篇博客的目的是在更高维度的对深度注意力机制作解释,并且细化计算注意力的某些技术细节步骤。如果你想看更详细的内容,最近Cho写的review是不二选择。很遗憾的是,许多模型并不能直接拿来使用,仅有一小部分是有开源代码的。
Attention
涉及到注意力机制的神经处理,已经在神经科学和计算神经科学中被大量研究了,比如[1,2]。一个特殊的研究方向是视觉注意力:许多动物集中于视野内的某些部分从而做出合适的反应。这种现象对神经计算有很大影响,比如我们需要选择出最相关的信息片段,而非使用所有的可用信息,其中大部分是对神经反应没有用处的信息。相似的思路(集中于输入的特定部分)已经应用到了深度学习中,例如语音识别、机器翻译、推断、目标识别等。
Attention for Image Captioning
举个例子来解释下注意力机制,我们想根据一张图片生成注释。
一个经典的图像注释系统会使用预训练的CNN网络来编码这张图片,生成隐状态 h h h,然后通过RNN来解码这个隐状态,来生成注释的语句。这种方法已经被几个研究团队用过,包括[11]。

这种方法的缺陷在于,当模型试着生成下一个词时,该词通常仅仅描述图片的某一部分。使用整个图片的表示 h h h来条件生成每个词,不能对图片的不同部分有效地生成不同的词。这也是注意力机制能够精确地起到作用的地方。
在注意力机制下,图片被分成了n部分,用CNN表示成 h 1 , h 2 , , , , h n h_1, h_2, ,,, h_n h1,h2,,,,hn。当RNN生成新词时,注意力总是集中到最相关的图片部分,所以解码器只是使用图片的特定部分来解码。
如下图[from 11],我们能够看到每个生成的单词是图片的哪些部分(白色的区域)用来生成的该词的。

如下图[form 11], 我们可以查看生成划线词的最相关的图片部分。

接下来我们即将解释注意力模型是如何工作的,更详细的基于Encoder-Decoder的注意力应用review请见[3]。
What is an Attention Model

注意力模型是种接收 n n n个输入 y 1 , y 2 , , , , y n y_1, y_2, ,,, y_n y1,y2,,,,yn和上下文信息 c c c,并返回向量 z z z,该值汇总了 y i y_i yi并集中于 c c c的相关信息。更官方的说法是返回 y i y_i yi的加权平均值,并且权重依赖于 y i y_i yi和 c c c的相关性。
在上述例子中,上下文是指已生成的句子, y i y_i yi是图片某部分的表示 h i h_i hi,输出是经过滤图片的表示,该过滤器是集中关注正要生成词的最相关的图片部分。
注意力机制非常有意思的特质之一是,权重的加权平均是可理解并能绘图的。这就是前面展现的那几张图,如果图像的权重很高则该像素点很亮。
那么这个黑箱具体干了什么呢?完整的注意力模型如下所示。
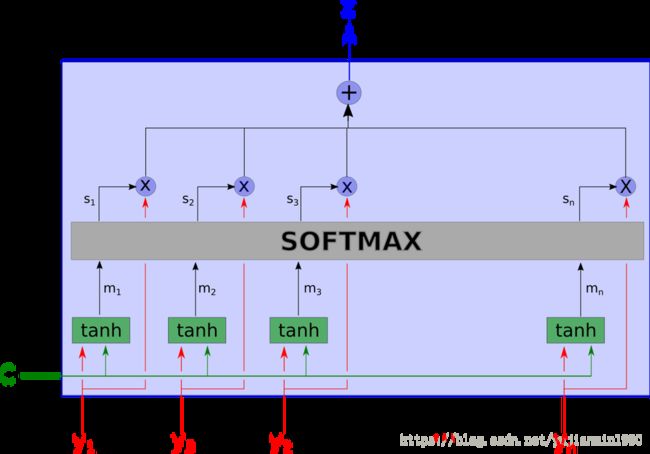
上面这个网络看起来很复杂,我们即将一步一步地来拆开解释。
首先,输入都有哪些呢? c c c是上下文信息, y i y_i yi是我们正在看的数据的某个部分。
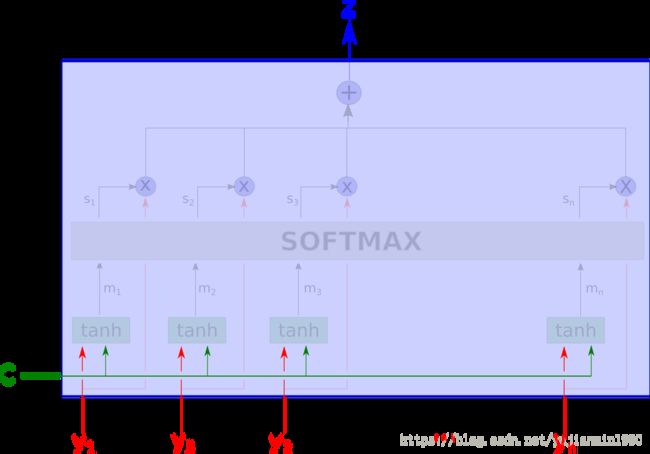
下一步,该网络使用 t a n h tanh tanh层计算 m 1 , m 2 , , , , m n m_1, m_2, ,,, m_n m1,m2,,,,mn,这意味着对 y i y_i yi和 c c c做一次聚合。值得注意的是, m i m_i mi并不考虑 y j f o r j ≠ i y_j for j \neq i yj for j=i,是独立计算的。 m i = t a n h ( W c m c + W y m y i ) m_i = tanh(W_{cm}c + W_{ym}y_i) mi=tanh(Wcmc+Wymyi)
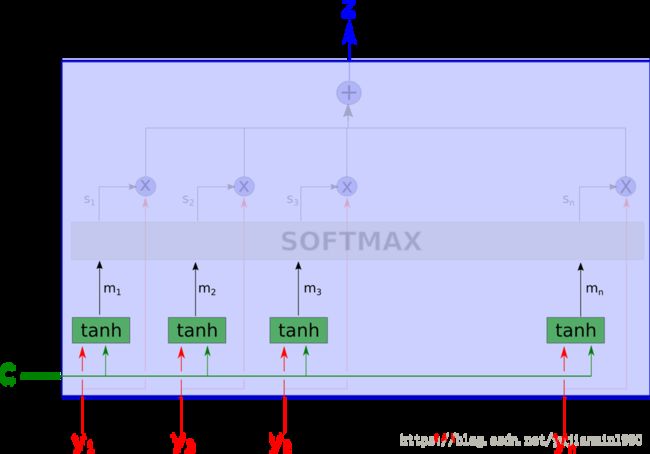
然后,对每个权重计算 s i = s o f t m a x ( m i ) = e ⟨ w m i , m i ⟩ ∑ k = 1 n e ⟨ w m k , m k ⟩ s_i = softmax(m_i)=\frac{e^{\left \langle w_{mi}, m_i \right \rangle}}{\sum_{k=1}^n e^{\left \langle w_{mk}, m_k \right \rangle}} si=softmax(mi)=∑k=1ne⟨wmk,mk⟩e⟨wmi,mi⟩
这里, s i s_i si是 m i m_i mi投射到学习方向上的softmax值,所以softmax可以认为是依据上下文 c c c得到的最相关值。
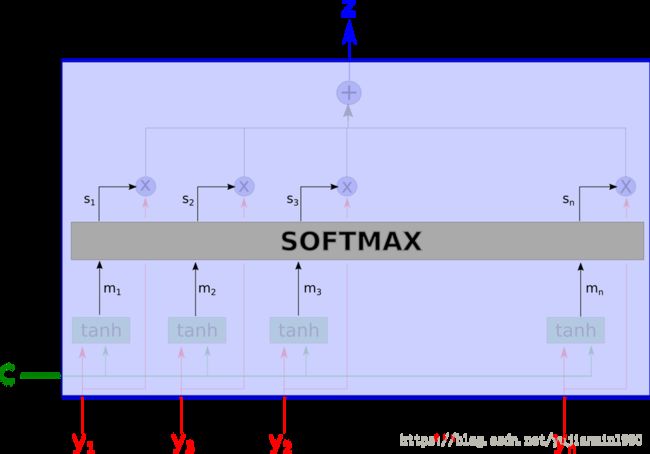
输出值 z z z是所有 y i y_i yi的加权平均值,权重表示每个变量跟上下文 c c c的相关性。 z = ∑ i s i y i z = \sum_i s_i y_i z=∑isiyi

An Other Computation of Relevance
上面的注意力模型可以调整如下,首先 t a n h tanh tanh层可以替换为其他网络层。这唯一重要的模块是混合 c c c和 y i y_i yi的函数,一个常常被使用的是内积函数。

这个版本很容易就能够理解,据当前所知,两个版本可以产生相近的结果。上述注意力模型是软选择与上下文最相关的变量,另外一种重要的变种是hard attention。
Soft Attention and Hard Attention
上面讲到的被称之为soft Attention是因为是可微分的,并能够插入已知的任意系统,且梯度可以在attention模块里面传播。
hard attention 是个随机过程,不同于使用所有的隐状态作为编码的输入,而是系统以概率 s i s_i si采样隐状态 y i y_i yi。为了在这一过程中传递梯度,我们通常用Monte Carlo 采样来估计梯度。

soft/hard attention都有各自的优势和劣势,但是现在的趋势更为关注soft attention机制因为梯度是可以直接计算,而随机过程的梯度是需要估计的无法直接计算。
Return to the Image Captioning
现在,我们就能够理解图像注释系统了。

这是个经典的带有注意力层的图像注释的结构图。当我们要预测一个新词时,发生了哪些操作呢?如果我们已经预测了第 i i i个词,隐状态是 h i h_i hi,利用上下文和 h i h_i hi选择图片最相关的部分。然后,输出 z i z_i zi表示图片经过滤最相关的部分的表示留下来了,将其作为LSTM的输入。最后,借助LSTM预测新词并返回新的隐状态 h i + 1 h_{i+1} hi+1。
Learning to Align in Machine Translation
Bahdanau[5]为NMT引入了注意力机制。
在解释注意力机制之前,先明确大部分NMT使用Encoder-Decoder模式。Encoder利用RNN(GUR/LSTM)接收输入语句(英语),然后生成隐状态 h h h,隐状态输入给Decoder来产生正确的翻译(法语)。

对翻译而言,比起图像注释有相同的直观感觉。当我们生成一个新词时,通常翻译原始语言的某个词。注意力机制允许预测词集中到原始输入的某个部分内容上。
NMT与图像注释唯一的不同是 h i h_i hi是RNN的连续隐层。
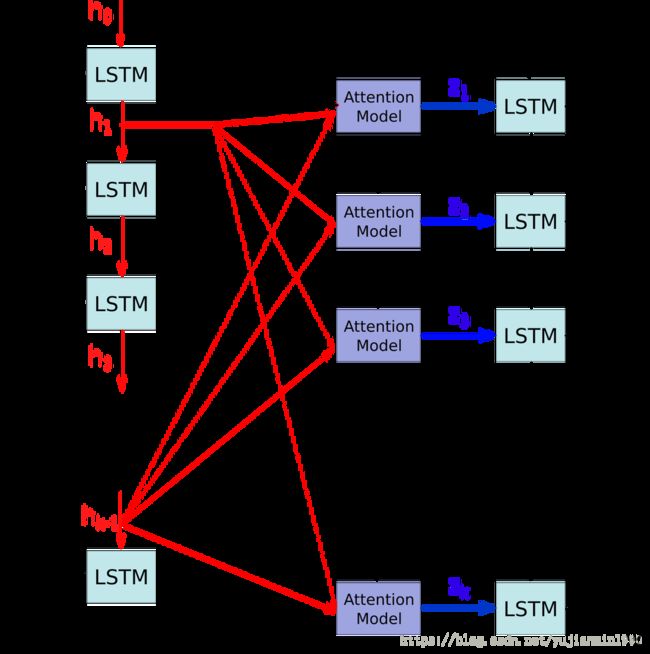
不同于相对于整个句子处理其中某一个隐状态,Encoder为每个输入词都生成一个 h j h_j hj。每次当Decoder预测一个新词时, h h h决定这每个隐状态作为输入的贡献值,贡献比例(注意力权重) α j \alpha_j αj用softmax计算,所有的 h j h_j hj同时列入 α j \alpha_j αj的考虑。
在这个例子里,注意力机制是完全可微分的,不需要额外的监督信息,可以简单直接地加入到已知的Encoder-Decoder结构之上。
这一过程可以看做是alignment,因为网络通常会学习每次产生输出时集中到某一单词信息上。这意味着大部分的注意力权重是0(black),1是被激活的(whilte),这揭示了alignment关系,使得解释网络学习到什么成为可能(这对RNN来说是个难题)。

Attention without Recurrent Neural Network
截止到目前为止,我们只介绍了在Encoder-Decoder中的注意力机制(比如带有RNN的),然而当输入顺序不再重要时,考虑独立的隐状态就成为可能了。这就变成了Raffel et AI[10]的例子,其中的注意力模型是全连接的前向网络。同样的例子也适用于Memory 网络[6],下面会介绍。
From Attention to Memory Addressing
2015年的NIPS组织了一次非常有意思的名为“RAM for Reasoning, Attention and Memory”的讨论。不仅包括注意力,也包括记忆网络[6],神经图灵机[7],,可微分堆叠RNNs[8]和其他的网络。这些模型有个共同点,采用外部记忆的形式来读或者写。
对比和解释这些模型不在本博客范围内,但是关于注意力机制和记忆机制的联系是有趣的。在记忆网络中,会考虑外部记忆(一组事实存在或者句子)和输入 q q q。网络学习访问记忆,这意味着选择哪些事实存在来作为关注点以产生答案。这与注意力机制在外部记忆上非常一致,记忆网络唯一的不同是软性选择事实(下图中的蓝色部分)是与事实(下图中的粉色部分)的embedding-sum权重去相关的。在神经图灵机中,基于QA模型的最近记忆使用soft注意力机制。这些模型会在后续的博客中介绍。
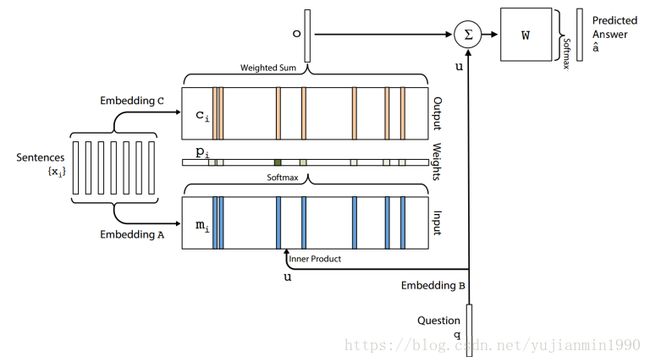
注意力机制和其他的全可微分记忆寻址网络现在已经被许多研究者做了广泛的研究,虽然它还很年轻并且并没有广泛地应用到现实世界,但是已有研究表明可以用来搞定最顶尖的涉及Encoder-Decoder的难题。
在Heuritech,我们在几个月前开始对注意力机制感兴趣,并且组织了讨论来快速交流信息,并用注意力机制实现Encoder-Decoder。虽然暂时并没有在生成环境中使用,但是我们可以预料到它必将在高级文本理解中起到重要作用。
原文链接
Bibliography
[1] Itti, Laurent, Christof Koch, and Ernst Niebur. « A model of saliency-based visual attention for rapid scene analysis. » IEEE Transactions on Pattern Analysis & Machine Intelligence 11 (1998): 1254-1259.
[2] Desimone, Robert, and John Duncan. « Neural mechanisms of selective visual attention. » Annual review of neuroscience 18.1 (1995): 193-222.
[3] Cho, Kyunghyun, Aaron Courville, and Yoshua Bengio. « Describing Multimedia Content using Attention-based Encoder–Decoder Networks. » arXiv preprint arXiv:1507.01053 (2015)
[4] Xu, Kelvin, et al. « Show, attend and tell: Neural image caption generation with visual attention. » arXiv preprint arXiv:1502.03044 (2015).
[5] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. « Neural machine translation by jointly learning to align and translate. » arXiv preprint arXiv:1409.0473 (2014).
[6] Sukhbaatar, Sainbayar, Jason Weston, and Rob Fergus. « End-to-end memory networks. » Advances in Neural Information Processing Systems. (2015).
[7] Graves, Alex, Greg Wayne, and Ivo Danihelka. « Neural Turing Machines. » arXiv preprint arXiv:1410.5401 (2014).
[8] Joulin, Armand, and Tomas Mikolov. « Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets. » arXiv preprint arXiv:1503.01007 (2015).
[9] Hermann, Karl Moritz, et al. « Teaching machines to read and comprehend. » Advances in Neural Information Processing Systems. 2015.
[10] Raffel, Colin, and Daniel PW Ellis. « Feed-Forward Networks with Attention Can Solve Some Long-Term Memory Problems. » arXiv preprint arXiv:1512.08756 (2015).
[11] Vinyals, Oriol, et al. « Show and tell: A neural image caption generator. » arXiv preprint arXiv:1411.4555 (2014).