数据科学与工程理论基础复习提纲
一、Sketch
1.1 简单抽样算法
1.1.1 核心思想
对于到达的元素 a i a_i ai,以概率 p = M / m p=M/m p=M/m对该元素的频数加1。
- M M M:抽样后的数据流大小
- m m m:原始数据流大小
1.1.2 操作
- 更新:当元素 a i a_i ai到达时,以 p p p的概率更新 c i c_i ci的值;以 1 − p 1-p 1−p的概率保持 c i c_i ci的值不变;
- 估计元素频数:返回元素频数数组,其中每个元素的频数为 f i ^ = c i / p \hat{f_i}=c_i/p fi^=ci/p;
1.1.3 性能
- 空间需求: M = O ( m l o g ( 1 δ ) ϵ 2 ) M=O(\frac{mlog(\frac{1}{\delta})}{\epsilon^2}) M=O(ϵ2mlog(δ1)),所需空间与数据流大小有关

1.2 Basic Count Sketch算法
1.2.1 核心思想
维护一个计数数组 C C C和两个哈希函数 h ( ⋅ ) 、 g ( ⋅ ) h(\cdot)、g(\cdot) h(⋅)、g(⋅)
- h ( ⋅ ) h(\cdot) h(⋅):将 n n n个元素均匀映射到 k k k个位置
- g ( ⋅ ) g(\cdot) g(⋅):将 n n n个元素映射为 − 1 -1 −1和 + 1 +1 +1
1.2.2 特点
- 期望 E ( f a ^ ) = f a E(\hat{f_a})=f_a E(fa^)=fa,即输出结果为 f a f_a fa的无偏估计;
- 方差 V a r ( f a ^ ) = ∣ ∣ f − a ∣ ∣ 2 2 k Var(\hat{f_a})=\frac{||f_{-a}||^2_2}{k} Var(fa^)=k∣∣f−a∣∣22,随着 k k k值增大,即存储计数数组的空间增大,方差将随之减小;
1.2.3 性能
- 空间需求: k = O ( 1 ϵ 2 δ ) k=O(\frac{1}{\epsilon^2\delta}) k=O(ϵ2δ1),与数据流大小无关

1.3 Count Sketch算法
1.3.1 核心思想
在Count Sketch基础上,将哈希函数个数增加到 t t t个,将每个元素都映射到 t t t个位置上,再区 t t t个位置上频数估计的中位数。

1.4 Count-Min Sketch算法
1.4.1 核心思想
- 维护一个宽度为 w w w、深度为 d d d的计数器数组;
- 另有 d d d个哈希函数;
1.4.2 特点
- 放弃了频数的无偏估计(Count Sketch);
- 获得了更为高效的频数估计;
- E [ X i ] = ∣ ∣ f − a ∣ ∣ 1 k E[X_i]=\frac{||f_{-a}||_1}{k} E[Xi]=k∣∣f−a∣∣1
- P [ f a ^ − f a ≥ ϵ ∣ ∣ f − a ∣ ∣ 1 ] = P [ m i n { X 1 , . . . X d } ≥ ϵ ∣ ∣ f − a ∣ ∣ 1 ] = ∏ i = 1 d P [ X i ≥ ϵ ∣ ∣ f − a ∣ ∣ 1 ] ≤ 1 ( k ϵ ) d P[\hat{f_a}-f_a\geq\epsilon||f_{-a}||_1]=P[min\{X_1,...X_d\}\geq\epsilon||f_{-a}||_1]=\prod^d_{i=1}P[X_i\geq\epsilon||f_{-a}||_1]\leq\frac{1}{(k\epsilon)^d} P[fa^−fa≥ϵ∣∣f−a∣∣1]=P[min{X1,...Xd}≥ϵ∣∣f−a∣∣1]=∏i=1dP[Xi≥ϵ∣∣f−a∣∣1]≤(kϵ)d1
1.4.3 性能
- 计数器个数 M = O ( l o g ( 1 δ ) ϵ ) M=O(\frac{log(\frac{1}{\delta})}{\epsilon}) M=O(ϵlog(δ1))

二、整数规划
2.1 整数规划
2.1.1 0-1变量
2.1.1.1 概念
很多问题中,决策变量取值只能为1或0。与 x i ∈ { 0 , 1 } x_i\in\{0,1\} xi∈{0,1}等价的说法有 0 ≤ x i ≤ 1 0\leq x_i\leq1 0≤xi≤1且 x i ∈ Z x_i\in\mathbf{Z} xi∈Z。
2.1.1.2 利用0-1变量表示互相排斥的约束条件
例1:假设两个约束通过逻辑或运算进行了组合
x ≤ 2 或 x ≥ 6 x\leq2 或 x\geq6 x≤2或x≥6
引入0-1变量 w w w:
w = { 1 , x ≤ 2 0 , x ≥ 6 w=\left\{ \begin{aligned} 1,\quad x\leq2 \\ 0,\quad x\geq6 \end{aligned} \right. w={1,x≤20,x≥6
和一个足够大的整数 M M M可以将约束条件改写成:
x ≤ 2 + M ( 1 − w ) x ≥ 6 − M w w ∈ { 0 , 1 } x\leq2+M(1-w)\\ x\geq6-Mw\\ w\in\{0,1\} x≤2+M(1−w)x≥6−Mww∈{0,1}
例2:假设两个约束条件通过逻辑或运算进行了组合
x 1 + 2 x 2 ≥ 12 或 4 x 1 − 10 x 3 ≤ 1 x_1+2x_2\geq12 或 4x_1-10x_3\leq1 x1+2x2≥12或4x1−10x3≤1
引入0-1变量 w w w:
w = { 1 , x 1 + 2 x 2 ≥ 12 0 , 4 x 1 − 10 x 3 ≤ 1 w=\left\{ \begin{aligned} 1,\quad x_1+2x_2\geq12 \\ 0,\quad 4x_1-10x_3\leq1 \end{aligned} \right. w={1,x1+2x2≥120,4x1−10x3≤1
可以改写成:
x 1 + 2 x 2 ≥ 12 − M ( 1 − w ) 4 x 1 − 10 x 3 ≤ 1 + M w w ∈ { 0 , 1 } x_1+2x_2\geq12-M(1-w)\\ 4x_1-10x_3\leq1+Mw\\ w\in\{0,1\} x1+2x2≥12−M(1−w)4x1−10x3≤1+Mww∈{0,1}
2.1.2 松弛线性规划
2.1.2.1 概念
将去掉整数约束的整数规划问题成为整数规划的松弛线性规划
2.1.2.2 例题
整数规划问题:
I P ( 1 ) m a x 10 x 1 + 4 x 2 + 9 x 3 5 x 1 + 4 x 2 + 3 x 3 ≤ 9 0 ≤ x i ≤ 1 , x i ∈ Z , 1 ≤ i ≤ 3 IP(1)\\ max\quad 10x_1+4x_2+9x_3\\ 5x_1+4x_2+3x_3\leq9\\ 0\leq x_i\leq1,x_i\in\mathbf{Z},1\leq i\leq3 IP(1)max10x1+4x2+9x35x1+4x2+3x3≤90≤xi≤1,xi∈Z,1≤i≤3
该整数规划的松弛线性规划为:
I P ( 1 ) m a x 10 x 1 + 4 x 2 + 9 x 3 5 x 1 + 4 x 2 + 3 x 3 ≤ 9 0 ≤ x i ≤ 1 , 1 ≤ i ≤ 3 IP(1)\\ max\quad 10x_1+4x_2+9x_3\\ 5x_1+4x_2+3x_3\leq9\\ 0\leq x_i\leq1,1\leq i\leq3 IP(1)max10x1+4x2+9x35x1+4x2+3x3≤90≤xi≤1,1≤i≤3
2.2 单纯形算法
单纯形算法是求解线性规划的经典方法。它的执行时间在最坏情况下不是多项式的,但是在实际中此算法通常相当快速。
2.2.1 主要思想
- 每轮迭代都关联一个“基本解”,容易从松弛型中计算得到。
- 每轮迭代把一个松弛型转换成一个等价的松弛型。
- 最终,指导一个最优解变得“明显”
2.3 分支定界算法
2.3.1 枚举树
2.3.1.1 概念
枚举树是以树状结构将可行域不断进行划分并一一列举出来的数据结构。
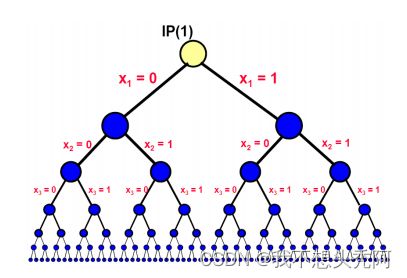
2.3.2 分支定界算法
2.3.2.1 剪枝规则
分支定界算法是为了对上述的枚举树进行剪枝,剪枝规则如下:
- 若已找到某个节点的最优解,删除其所有子孙节点;
- 若已知枚举树中某个节点的最优解,而当前节点的松弛线性规划问题的最优解都比这个解要小,则删除当前节点及其子孙节点;
- 若当前节点对应的松弛线性规划问题没有可行解,删除当前节点及其子孙节点。
2.3.2.2 算法

三、集合覆盖
3.1 问题定义
3.1.1 覆盖
设 A A A是非空集合, C C C是集合 A A A的非空子集组成的集合,即 C = { A α ∣ A α ⊂ A , A α ≠ ∅ } C=\{A_\alpha|A_\alpha\subset A,A_\alpha\neq\empty\} C={Aα∣Aα⊂A,Aα=∅}, C C C是集合 A A A的覆盖,若 C C C满足
∪ A α ∈ C A α = A \cup_{A_\alpha\in C}A_\alpha=A ∪Aα∈CAα=A
3.1.2 最小全覆盖问题
令 U U U为一有限集, S = { s 1 , s 2 , . . . , s n } S=\{s_1,s_2,...,s_n\} S={s1,s2,...,sn}为由 U U U的 n n n个子集构成的集族,全覆盖问题是找到 S S S最小的自己覆盖集合 U U U。
3.1.3 最大子覆盖问题
令 U U U为一有限集, S = { s 1 , s 2 , . . . , s n } S=\{s_1,s_2,...,s_n\} S={s1,s2,...,sn}为由 U U U的 n n n个子集构成的集族,给定正整数 k k k,最大子覆盖问题是从 S S S中找到 k k k个子集,使得这 k k k个子集覆盖集合 U U U中最多的元素。
3.2 爬山算法
3.2.1 概念
爬山算法(hill-climbing algorithm)是一个解决子模优化问题的局部搜索算法。算法12.1是爬山算法的一个实例,它解决了最大子覆盖问题。

四、模块度及社区发现
4.1 模块度
4.1.1 概念
社区划分的好坏与划分后的社区内部顶点及社区之间顶点的连接程度紧密相关,划分越好的社区中各社区内部顶点之间连接得也越紧密,而社区之间连接得越稀疏。模块度正是基于这样的一个观测而定义的。
4.1.2 无向图的模块度定义
4.1.2.1 表达式
无向图的模块度可以计算为:
Q = 1 2 m ∑ i , j ( A i j − k i k j 2 m ) δ ( C i , C j ) Q=\frac{1}{2m}\sum_{i,j}(A_{ij}-\frac{k_ik_j}{2m})\delta(C_i,C_j) Q=2m1i,j∑(Aij−2mkikj)δ(Ci,Cj)
- n n n:顶点个数
- m m m:边数
- A A A:邻接矩阵
- k i k_i ki:顶点 v i v_i vi的度
- δ ( C i , C j ) = { 1 , 如果 v i 和 v j 属于同一个社区 0 , 否则 \delta(C_i,C_j)=\left\{ \begin{aligned} 1,如果v_i和v_j属于同一个社区\\ 0,&否则 \end{aligned} \right. δ(Ci,Cj)={1,如果vi和vj属于同一个社区0,否则
4.1.2.2 例题
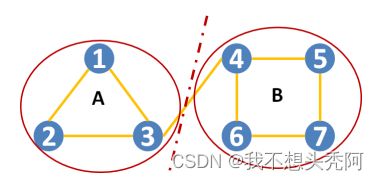
解:由图可知, m = 8 , k 1 = 2 , k 2 = 2 , k 3 = 3 , k 4 = 3 , k 5 = 2 , k 6 = 2 , k 7 = 2 m=8,k_1=2,k_2=2,k_3=3,k_4=3,k_5=2,k_6=2,k_7=2 m=8,k1=2,k2=2,k3=3,k4=3,k5=2,k6=2,k7=2。
Q = 1 16 [ ( A 11 − k 1 k 1 16 ) + 2 ( A 12 − k 1 k 2 16 ) + 2 ( A 13 − k 1 k 3 16 ) + ( A 22 − k 2 k 2 16 ) + 2 ( A 23 − k 2 k 3 16 ) + ( A 33 − k 3 k 3 16 ) + ( A 44 − k 4 k 4 16 ) + 2 ( A 45 − k 4 k 5 16 ) + 2 ( A 46 − k 4 k 6 16 ) + 2 ( A 47 − k 4 k 7 16 ) + ( A 55 − k 5 k 5 16 ) + 2 ( A 56 − k 5 k 6 16 ) + 2 ( A 57 − k 5 k 7 16 ) + ( A 66 − k 6 k 6 16 ) + 2 ( A 67 − k 6 k 7 16 ) + ( A 77 − k 7 k 7 16 ) ] = 47 128 Q=\frac{1}{16}[(A_{11}-\frac{k_1k_1}{16})+2(A_{12}-\frac{k_1k_2}{16})+2(A_{13}-\frac{k_1k_3}{16})\\ +(A_{22}-\frac{k_2k_2}{16})+2(A_{23}-\frac{k_2k_3}{16})+\\ (A_{33}-\frac{k_3k_3}{16})\\ +(A_{44}-\frac{k_4k_4}{16})+2(A_{45}-\frac{k_4k_5}{16})+2(A_{46}-\frac{k_4k_6}{16})+2(A_{47}-\frac{k_4k_7}{16})\\ +(A_{55}-\frac{k_5k_5}{16})+2(A_{56}-\frac{k_5k_6}{16})+2(A_{57}-\frac{k_5k_7}{16})\\ +(A_{66}-\frac{k_6k_6}{16})+2(A_{67}-\frac{k_6k_7}{16})\\ +(A_{77}-\frac{k_7k_7}{16}) ]=\frac{47}{128} Q=161[(A11−16k1k1)+2(A12−16k1k2)+2(A13−16k1k3)+(A22−16k2k2)+2(A23−16k2k3)+(A33−16k3k3)+(A44−16k4k4)+2(A45−16k4k5)+2(A46−16k4k6)+2(A47−16k4k7)+(A55−16k5k5)+2(A56−16k5k6)+2(A57−16k5k7)+(A66−16k6k6)+2(A67−16k6k7)+(A77−16k7k7)]=12847
4.1.2.3 另一种模块度表达式
Q = 1 2 m ∑ i , j ( A i j − k i k j 2 m ) δ ( C i , C j ) = ∑ i , j ( A i j 2 m − k i k j 4 m 2 ) δ ( C i , C j ) = ( ∑ i , j A i j 2 m − ∑ i k i ∑ j k j 4 m 2 ) δ ( C i , C j ) = ∑ c ∈ C [ ∑ i n c 2 m − ( ∑ t o t c 2 m ) 2 ] Q=\frac{1}{2m}\sum_{i,j}(A_{ij}-\frac{k_ik_j}{2m})\delta(C_i,C_j)\\ =\sum_{i,j}(\frac{A_{ij}}{2m}-\frac{k_ik_j}{4m^2})\delta(C_i,C_j)\\ =(\sum_{i,j}\frac{A_{ij}}{2m}-\frac{\sum_ik_i\sum_jk_j}{4m^2})\delta(C_i,C_j)\\ =\sum_{c\in C}[\frac{\sum^c_{in}}{2m}-(\frac{\sum^c_{tot}}{2m})^2] Q=2m1i,j∑(Aij−2mkikj)δ(Ci,Cj)=i,j∑(2mAij−4m2kikj)δ(Ci,Cj)=(i,j∑2mAij−4m2∑iki∑jkj)δ(Ci,Cj)=c∈C∑[2m∑inc−(2m∑totc)2]
- ∑ i n c \sum^c_{in} ∑inc:社区 c c c内部有向边的数量;
- ∑ t o t c \sum^c_{tot} ∑totc:社区 c c c内部所有顶点度的总和;
4.1.2.4 例题
用上述表达式计算上图的模块度:
Q = [ 6 16 − ( 7 16 ) 2 ] + [ 8 16 − ( 9 16 ) 2 ] = 47 128 Q=[\frac{6}{16}-(\frac{7}{16})^2]+[\frac{8}{16}-(\frac{9}{16})^2]=\frac{47}{128} Q=[166−(167)2]+[168−(169)2]=12847
4.1.3 权重无向图的模块度定义
4.1.3.1 表达式
假设 W W W为图 G G G的权重矩阵,其中
W i j = { w i j , 如果 A i j = 1 0 , 否则 W_{ij}=\left\{ \begin{aligned} w_{ij},如果A_{ij}=1\\ 0,否则 \end{aligned} \right. Wij={wij,如果Aij=10,否则
即图 G G G的每条边上赋予了一个权重 w i j w_{ij} wij。权重无向图的模块度定义为:
Q = 1 2 m ∑ i , j ( W i j − k i k j 2 m ) δ ( C i , C j ) Q=\frac{1}{2m}\sum_{i,j}(W_{ij}-\frac{k_ik_j}{2m})\delta(C_i,C_j) Q=2m1i,j∑(Wij−2mkikj)δ(Ci,Cj)
- 2 m = ∑ i , j W i j 2m=\sum_{i,j}W_{ij} 2m=∑i,jWij
- k i = ∑ j W i j k_i=\sum_jW_{ij} ki=∑jWij
4.1.4 有向图的模块度定义
4.1.4.1 表达式
假设 A A A为有向图 G G G的邻接矩阵,其中 m m m为有向边的数量,定义顶点 v i v_i vi的出度和入度分别为:
k i o u t = ∑ j A i j 和 k i i n = ∑ j A j i k_{i}^{out}=\sum_jA_{ij}\quad和\quad k^{in}_i=\sum_jA_{ji} kiout=j∑Aij和kiin=j∑Aji
有向图的模块度定义如下
Q = 1 m ∑ i , j ( A i j − k i o u t k j i n m ) δ ( C i , C j ) Q=\frac{1}{m}\sum_{i,j}(A_{ij}-\frac{k^{out}_ik^{in}_j}{m})\delta(C_i,C_j) Q=m1i,j∑(Aij−mkioutkjin)δ(Ci,Cj)
4.1.5 模块度的矩阵定义
4.1.5.1 表达式
定义一个 n × k n\times k n×k的矩阵 S S S, S i j = 1 S_{ij}=1 Sij=1表示顶点 v i v_i vi属于第 j j j个社区, S i j = 0 S_{ij}=0 Sij=0表示顶点 v i v_i vi不属于第 j j j个社区,所以
δ ( C i , C j ) = ∑ r S i r S j r \delta(C_i,C_j)=\sum_rS_{ir}S_{jr} δ(Ci,Cj)=r∑SirSjr
定义实对称矩阵 B B B,其元素满足
B i j = A i j − k i k j 2 m B_{ij}=A_{ij}-\frac{k_ik_j}{2m} Bij=Aij−2mkikj
则社区结构模块度可以改写为:
Q = 1 2 m ∑ i , j ( A i j − k i k j 2 m ) δ ( C i , C j ) = 1 2 m ∑ i , j B i j ∑ r S i r S j r = 1 2 m ∑ i , j ∑ r B i j S i r S j r = 1 2 m T r ( S T B S ) Q=\frac{1}{2m}\sum_{i,j}(A_{ij}-\frac{k_ik_j}{2m})\delta(C_i,C_j)\\ =\frac{1}{2m}\sum_{i,j}B_{ij}\sum_{r}S_{ir}S_{jr}\\ =\frac{1}{2m}\sum_{i,j}\sum_{r}B_{ij}S_{ir}S_{jr}\\ =\frac{1}{2m}Tr(S^TBS) Q=2m1i,j∑(Aij−2mkikj)δ(Ci,Cj)=2m1i,j∑Bijr∑SirSjr=2m1i,j∑r∑BijSirSjr=2m1Tr(STBS)
其中 T r ( S T B S ) Tr(S^TBS) Tr(STBS)为矩阵的迹,即对角元素之和。
4.2 Louvain算法
4.2.1 算法步骤

4.2.2 表达式
模块度增益 Δ Q ( v i → B ) \Delta Q(v_i\rightarrow B) ΔQ(vi→B)计算为
KaTeX parse error: Can't use function '$' in math mode at position 2: $̲\Delta Q(v_i\ri…
模块度损失 Δ Q ( A → v i ) \Delta Q(A\rightarrow v_i) ΔQ(A→vi)计算为
Δ Q ( A → v i ) = ∑ i , t o t A ′ ⋅ k i 2 m 2 − k i , i n A ′ 2 m \Delta Q(A\rightarrow v_i)=\frac{\sum^{A'}_{i,tot}\cdot k_i}{2m^2}-\frac{k^{A'}_{i,in}}{2m} ΔQ(A→vi)=2m2∑i,totA′⋅ki−2mki,inA′