编译原理笔记03
第四章 语义分析
语义分析也称为类型检查,上下文相关分析,主要负责检查程序的上下文相关的属性,例如变量使用前要声明,函数调用要与声明一致等。
1.语义规则
通常来说,程序设计语言都采用自然语言来表达程序语言的语义,语义规则与具体语言相关,编译器的实现者必须对语言的语义规定有全面的理解。
2.符号表
对于上下文相关的属性,必须进行记录才能保证程序能够运行,例如变量的声明必须有所记录,语义检查也是通过这些记录完成好呢个的。程序中的变量相关信息记录在符号表当中,包含变量的类型,作用域,访问控制信息,符号表的使用伴随了编译的全过程。
符号表实现时,比较复杂的是考虑作用域的情况,不同作用域可以使用一个链表来记录:
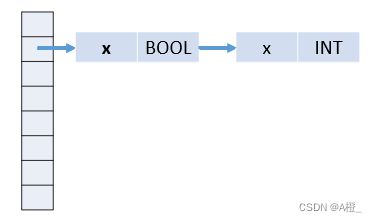
也可以符号表栈,进入一个作用域就插入新的符号表,退出则删除栈顶符号表。
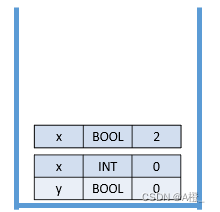
语义分析中包含的其他问题还有类型相容等。现代的编译器中的语义分析模块,除了做语义分析外,还要负责生成中间代码或目标代码。因此,语义分析模块往往是编译器中最庞大也最复杂的模块。接下来就介绍代码生成的部分。
第五章 代码生成
生成了抽象语法树,前端的工作就结束了。后端的工作是将输入的抽象语法树翻译生成目标代码。即代码生成。
代码生成是将源程序翻译成目标机器上的代码的过程,主要完成两个任务,同时要保证等价和效率。
- 给源程序的数据分配存储资源
- 数据:全局变量,局部变量,动态分配等。
- 存储资源:寄存器,内存。
- 给源程序的代码选择指令
- 源程序的代码:表达式,语句,函数等。
- 机器指令:算术运算,比较,跳转等。
代码生成技术与指令集有关,主要研究两种不同的指令集上的代码生成技术:栈计算机,寄存器计算机。
1.栈式计算机的代码生成技术
栈式计算机现在已经基本淘汰了,研究其代码生成技术的原因是其代码生成比较简单,且现在仍然有许多栈式的虚拟机。
栈式计算机的结构和指令集如下:
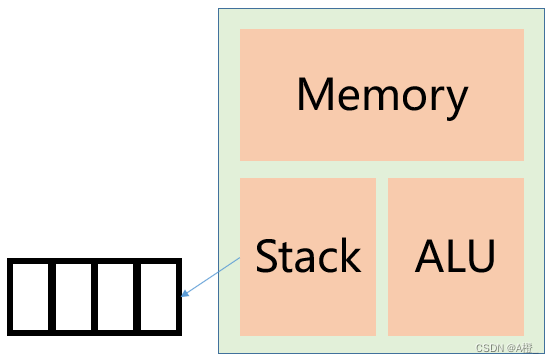
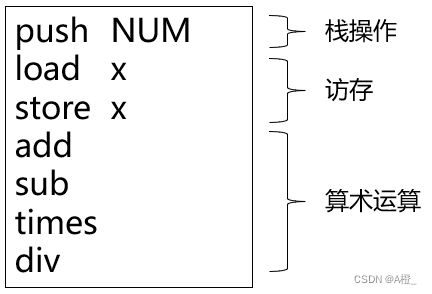
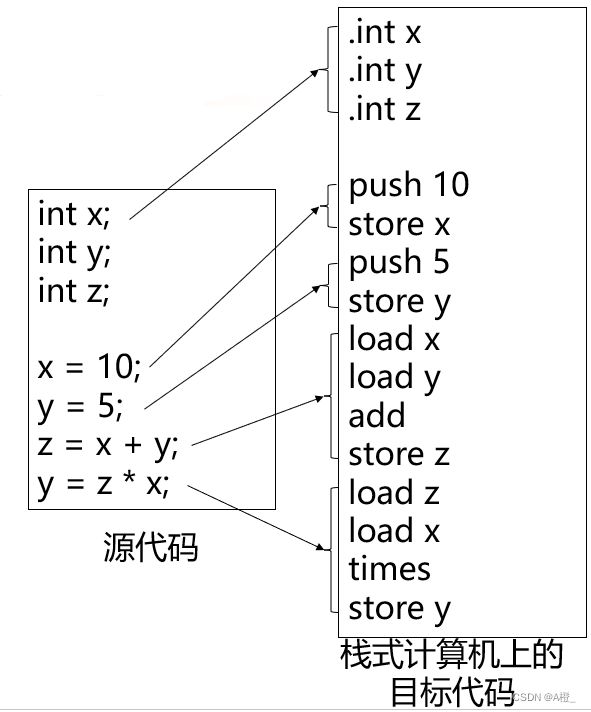
栈式计算机只支持一种数据类型int,给变量x分配内存的伪指令是:.int x。其他的指令执行的操作如下:
push NUM
top++;
stack[top] = NUM;
load x
top++;
stack[top] = x;
store x
x = stack[top];
top--;
add
temp = stack[top-1] + stack[top];
top = top-2;
push temp;
语法如下:
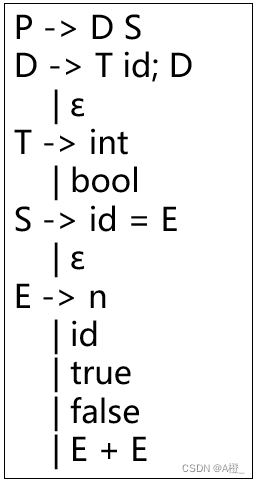
每个非终结符都有一个代码生成函数,在代码生成时,表达式对应的值总是在栈顶。
Gen_E(E e){
switch (e)
case n:
emit("push n");
break;
case id:
emit("load id");
break;
case true:
emit("push 1");
break;
case e1+e2:
Gen_E(e1);
Gen_E(e2);
emit("add");
break;
case...
}
Gen_T(T t){
switch(t)
case int:
emit(".int");
break;
case bool:
emit(".int");
break;
}
Gen_S(S s){
switch (s)
case id=e:
Gen_E(e);
emit("store id");
break;
}
Gen_D(T id; D){
Gen_T(T);
emit(" id");
Gen_D(D);
}
Gen_P(D S){
Gen_D(D);
Gen_S(S);
}
一个代码生成的示例如下:
2.寄存器计算机的代码生成技术
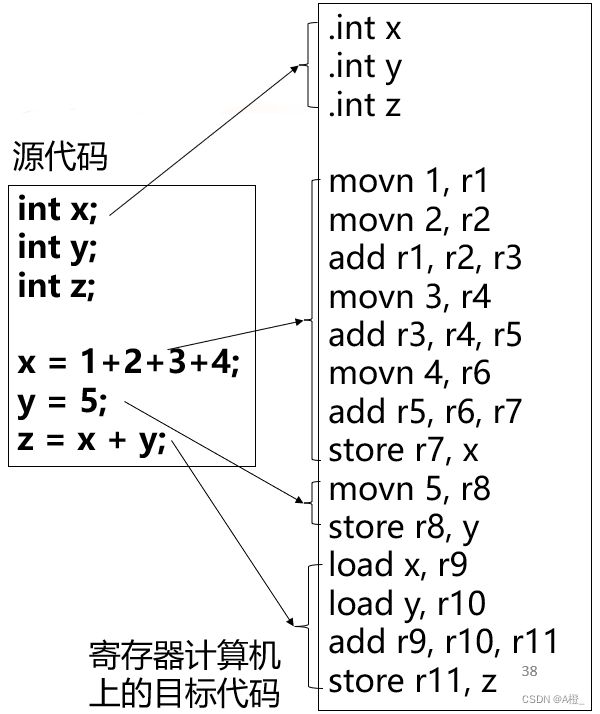
寄存器计算机是目前最流行的机器体系结构。寄存器计算机中寄存器代替了栈式计算机的栈,在寄存器存放部分变量和中间结果。在考虑代码生成技术时,假定有无限多个寄存器。代码生成的过程和栈式计算机相似。只是目标指令不同,入栈出栈都转变为了寄存器分配,然后存值。
以下是一个简单寄存器计算机的指令集:
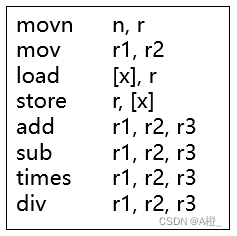
文法仍然为上述介绍栈式计算机时的文法,每一个非终结符的函数变为:
Gen_E(E e){
switch (e)
case n:
r = getNewReg();
emit("movn n,r");
return r;
case id:
r = getNewReg();
emit("mov id,r");
return r;
case true:
r = getNewReg();
emit("movn 1,r");
return r;
case e1+e2:
r1 = Gen_E(e1);
r2 = Gen_E(e2);
r3 = getNewReg();
emit("add r1,r2,r3");
break;
case...
}
Gen_T(T t){
switch(t)
case int:
emit(".int");
break;
case bool:
emit(".int");
break;
}
Gen_S(S s){
switch (s)
case id=e:
r = Gen_E(e);
emit("store r,id");
break;
}
Gen_D(T id; D){
Gen_T(T);
emit(" id");
Gen_D(D);
}
Gen_P(D S){
Gen_D(D);
Gen_S(S);
}
一个代码生成的示例如下:
第六章 中间表示
在上一章中介绍了代码生成,即从抽象语法树生成目标代码的过程。实际在编译过程中,抽象语法树通常不直接生成目标代码,而是先生成一些中间表示,再通过中间表示,生成不同目标机器上的目标代码。中间表示的作用是提供一个中间层,抽象语法树只需要生成中间表示,而不需要根据具体的机器生成目标代码,由后端在后续过程中将中间表示进行优化,并转换为目标代码。基本思想是与目标机器无关,且对于多种源语言通用。
一般编译器有多阶段的中间表示,高层中间表示接近源语言,便于进行语义分析和冗余检查;低层中间表示接近目标语言,便于优化和翻译。常用的中间表示有:
- 图IR:树和有向无环图DAG
- 线性IR:三地址码
- 混合IR:控制流图CFG,静态单赋值形式SSA
下面分别介绍这几种中间表示。
1.有向无环图DAG
有向无环图DAG是抽象语法树AST的进一步抽象,解决抽象语法树存储开销大,不便于优化的问题。
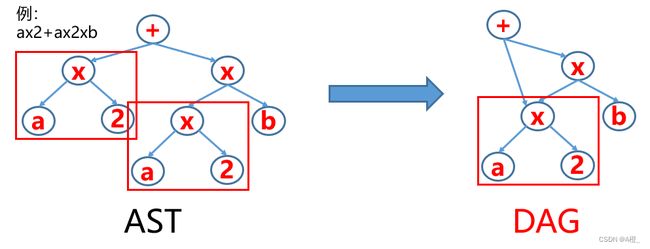
使用有向无环图DAG的一般用途为:
- 减少内存占用:减小AST的内存开销
- 后端代码优化:查找冗余,减少翻译出的机器指令
DAG在生成时,会检查节点是否已经存在,如果需要的节点已经生成,就直接进行引用。手动构造一个DAG的步骤如下:
- 将操作数不重复的排成一排
- 标出表达式中运算符生效的顺序
- 按顺序加入运算符 结果保存在操作数最大层数的上一层
- 检查同层运算符是否能够合并
其中合并可以直接在加入运算符时进行。
2.三地址代码
三地址代码是一种每个指令最多有三个操作数,一个运算符的代码。基本思想是:
- 给每个中间变量和计算结果命名,没有复合表达式
- 只有最基本的控制流,只有goto和call指令
- 是指令集的抽象
以下是一个三地址代码的例子:
//源代码
a = 3 + 4 * 5;
if (x < y)
z = 6;
else
z = 7;
//三地址码
t1 = 4 * 5;
a = 3 + t1;
if (x < y) goto L_1;
goto L_2;
L_1:
z = 6;
goto L_3;
L_2:
z = 7;
goto L_3:
使用三地址码的好处是:
- 类似寄存器计算机的指令,便于代码生成
- 代码紧凑,空间占用少
- 形式灵活,表达清晰,且每个中间变量和计算结果命名,便于控制名字和值的复用
三地址码的主要不足在于程序的控制流信息是隐式的,因为控制流被简化了,因此通过三地址代码难以理解源程序的控制流结构。
三地址码的生成过程和第五章代码生成中的生成方式很相似。也可以使用语法制导定义SDD直接在语法分析时生成,直接跳过抽象语法树的生成。
3.控制流图CFG
控制流图是一个有向图G=(V,E)。其中每个节点V是一个基本块,E是基本块之间的边,表示跳转关系。每个基本块只能从第一条语句进入,从最后一条语句离开。主要的用途为:
- 控制流分析:分析程序的内部结构,如是否存在循环。并可以通过分析修改或优化程序,例如删除死基本块。
- 数据流分析:例如一个变量可能的取值。
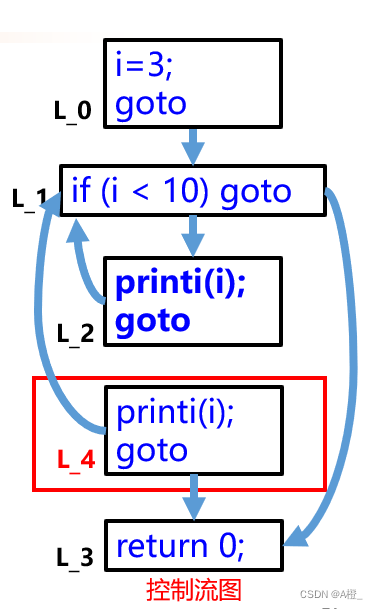
控制流图可以由三地址码生成。而控制流图的操作可以使用图论中的各种算法实现。
控制流图的缺点在于没有显式的数据流信息。不能通过数据流对程序进行优化。
4.静态单赋值形式SSA
静态单赋值形式在数据流图的基础上添加了数据流信息,基本思想是:
- 每个变量只定义一次。
- 使用数据时必须指向一个特定的变量。
主要的用途就是基于数据流和控制流进行优化。由于在数据流图的基础上显式添加了数据流,主要是在数据流的基础上进行优化:
- 删除冗余赋值
- 常量传播
第七章 代码优化
代码优化是一个在保持语义的基础上进行代码变换的过程。可以按照不同的阶段分为:
- 前期优化
- 在抽象语法树上进行
- 常量折叠、代数优化、不可达代码删除等
- 中期优化
- 在中间表示上进行
- 常量传播、拷贝传播、死代码删除、公共子表达式删除等
- 后期优化
- 在后端(汇编代码级)进行
- 寄存器分配、指令调度、窥孔优化等
1.前期优化
前期优化包括常量折叠,代数优化,不可达代码删除。在抽象语法树上进行。
常量折叠是对程序中表达式的常量计算进行优化。因为一些表达式的值在编译过程中就可以得到,例如a=3+5,可以直接优化为a=8。在语法树或者中间表示上,这种优化是容易实现的,且通常实现为公共子函数,可以被其他优化调用。但在优化过程中必须遵守语言的语义,例如考虑异常或溢出,例如x=4294967294+1,如果x为unsigned int,则值正常+1,如果x是int,结果为-1。
代数优化是对表达式计算的化简,利用的是代数系统的性质。例如a=1b = ab,a+1024+b-1024 = a+b。进行代数化简,也要注意遵守语言的语义,考虑溢出或异常。
不可达代码删除的基本思想是删除程序中不会执行的代码。这种优化也可以中期在控制流图上完成。
2.中期优化
前期优化可简化中后端处理,但是优化能力有限,进行如不可达代码删除这样的优化很不方便。在中间表示位置可以进行进一步的优化。优化的方式则依赖于具体所使用的中间表示。本部分介绍基于控制流图的中期优化。
中期优化一般分为两步。第一步是程序分析,通过控制流分析,数据流分析,依赖分析等得到被优化程序的静态保守信息(对动态运行行为的保守估计)。第二步是程序重写,基于程序分析的信息对程序进行重写。
本章主要介绍的是程序分析的两种方法:到达定义分析和活性分析。
2.1 到达定义分析
到达定义分析主要分析的是对每个变量的使用点,有哪些定义可以到达。其中定义指的是对变量的赋值,使用点是对变量值的读取。
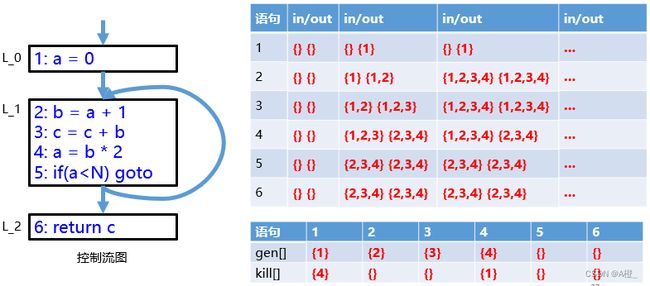
使用集合来表示到达定义分析的结果,分析每一个语句对到达定义的改变。设每一个语句都有一个in集,表示到达该语句时,有哪些语句的定义有效,每一个语句还有一个out集,表示经过该语句后,还有哪些语句的定义是有效的。 为了求解in和out集,每个语句还有一个gen集和一个kill集,分别表示该语句产生了一个语句定义,该语句使哪些语句的定义无效。
假设每条语句编号i,对变量x定义,则到达定义的计算为:
-
gen = {i}
-
kill = defs[x] - {i}
- defs[x]表示所有定义x的语句
-
in[i] = 所有到达i的语句的out集
-
out[i] = gen[i] ∪ (in[i] - kill[i]),即经过该语句有效的定义语句,是当前语句加上到达该语句有效的定义语句再减去当前语句使之无效的那些语句。
由于后面的定义需要包含前面的有效定义,即out[i]依赖于in[i],对于语句in和out集的计算应该从前往后进行,即从第一条语句开始,计算in和out集的方程被称为前向数据流方程。
以下是一个控制流图的到达定义分析示例,由于in集取决于来源语句的out集,而来源语句的out集可能还没有计算结束,因此要反复计算in和out集,直到集合不发生改变。
2.2 活性分析
到达定义分析分析的是对变量的使用点,有哪些定义可以到达。另一种常用的程序分析方法是活性分析,分析的是在程序的每个语句,有哪些变量正在处于使用状态。活性分析主要用于寄存器分配,在中间代码生成时,通常假设有无限多个寄存器,从而简化代码生成,最终产生目标代码,必须将无限的虚拟寄存器分配到机器的有限的寄存器当中。进行活性分析,可以确定哪些变量可以共用一个寄存器。
活性分析需要确定变量在哪些语句是活跃的,活跃的这些语句就是变量的活跃区间。变量活跃的定义如下:
-
如果变量x在程序点p(含)之后被使用,则x在p点是活跃的。(显然,如果变量x在点p被有效定义,在点p也是活跃的)
-
否则,如果变量x在程序点p(含)之后未被使用,则x在p点是死的。(如果变量x在点p被定义,在后面却没有被使用,这个定义实质是无效的,x在点p不是活跃的。)
根据以上的变量活跃的定义,变量活跃,只需要重点关注使用情况,而不需要关注定义情况。并且在分析时,还应该将一些无效的定义语句将被排除在变量活跃区间以外。例如下面的例子:
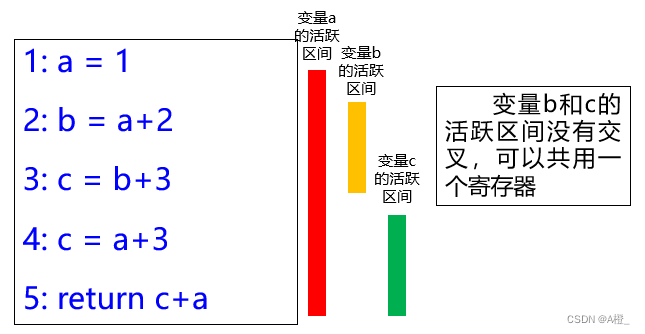
在语句3和语句4都有对变量c的定义,根据变量活跃的定义,语句3开始就是c的活跃区间,但语句3的定义是无效的,c的活跃区间里不应该有语句3。在求活跃区间时避免这种情况的方式是:从后往前求活跃区间。下面描述一下求解过程。
类似到达定义分析,设每个语句都有一个in集和一个out集,分别表示到该语句仍然活跃的活跃变量,在该语句之后的还保持活跃的活跃变量。还使用两个辅助的集合use集和def集,分别表示该语句使用了哪些变量,定义了哪些变量。假设语句编号i,这是个集合的计算如下:
- use = {x|x在语句i中出现}
- def = {x|x由语句i定义}
- out[i]:所有从该语句离开,所到达的语句的in集合的并集
- in[i] = use[i] ∪ (out[i] - def[i])
为了解决上面已经提到的无效定义问题,应该从后往前计算,即in[i]依赖于out[i],所以从最后的语句开始进行分析,且先计算out集,再计算in集。计算in和out集的方程被称为后向数据流方程。
对于上图中的程序,求出的in和out集如下:

以下是一个控制流图的活性分析示例,由于out集取决于从当前语句离开所到达语句的in集,而对应语句的out集可能还没有计算结束,因此要反复计算in和out集,直到集合不发生改变。由于要反复进行计算,尽管应该按照从后往前的顺序计算,但实际上从前往后或从后往前都可以,因为整个集合不改变时才停止计算,不会遗漏。
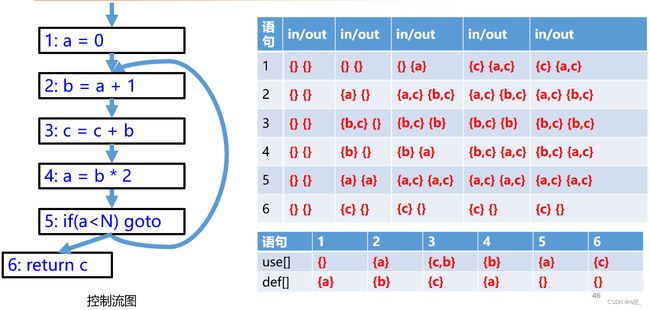
以上已经给出了求in和out集的方法,求in和out集的目的是求变量的活跃区间。因此此时再来分析以下这两个集合,in表示到该语句仍然活跃的活跃变量,out表示在该语句之后的还保持活跃的活跃变量,所以只要根据变量是否在该语句的in集或out集当中,就可以划分出变量的活跃区间了。
2.3 优化方法
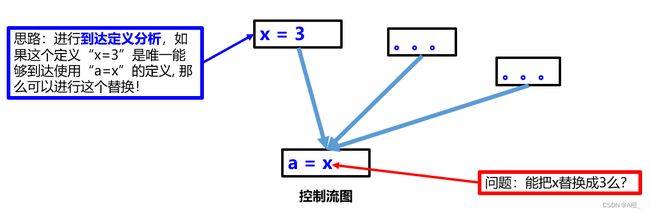
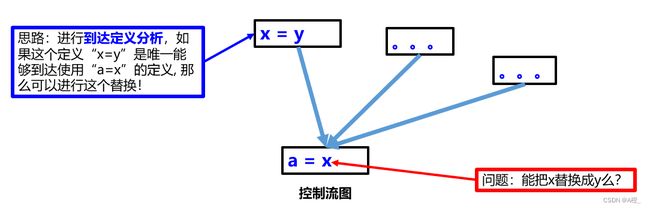
中期优化一般分为两步。第一步是程序分析,通过控制流分析,主要的两种方法就是到达定义分析和活性分析。第二步是程序重写,基于程序分析的信息对程序进行重写。接下来就用例子展现程序重写的方法:常量传播,拷贝传播,死代码删除。
常量传播优化
拷贝传播优化:
死代码删除
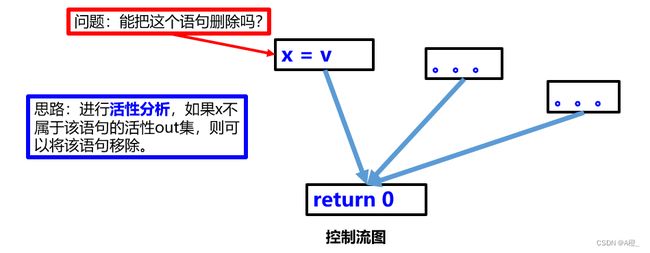
其中的死代码删除和前期优化提到过的不可达代码删除是有区别的。不可达代码不会被执行,而死代码是可以执行,但没有意义的代码。
3.后期优化
后期优化在生成代码后,在汇编代码级进行优化。后期优化与目标机器相关,和寄存器数量,指令集等都有关系。后期优化的方法有寄存器分配,指令调度,窥孔优化等。这里重点介绍寄存器分配。
在代码生成时,为了简化代码生成的过程,假设寄存器有无限个,真实的目标机器的寄存器数量是有限的,不同机器的寄存器数量也不一样,例如RISC机器通常有32个寄存器。因此在生成代码后,要进行寄存器分配,重写代码,将使用的多个变量分配到少数物理寄存器中,保证使用的寄存器数量不超过机器的真实寄存器数量。以下是一个寄存器分配的例子:

寄存器分配的主要思路就是让不同时活跃的变量共用一个寄存器,从而减少寄存器数量。一种简单的寄存器分配算法是遇到一个变量就使用一个当前不活跃变量所使用的寄存器,如果分配失败,就把某个变量放回内存,重用他的寄存器。这种方式分配效率很低,程序性能可能很差。在1980年,IBM研究员尝试了使用图着色算法进行寄存器分配,这种方法分配更简单,效果也更好。
图着色算法分配寄存器的步骤如下:
- 计算活性分析
- 画出寄存器冲突图(RIG)
- 对RIG着色分配寄存器
- 将无法分配寄存器的变量溢出到内存
下面以一个完整的例子说明图着色算法分配寄存器的过程。
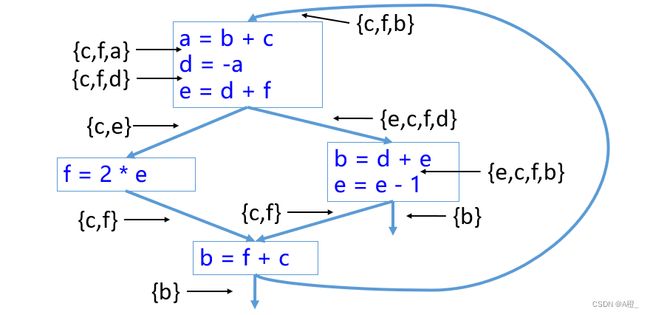
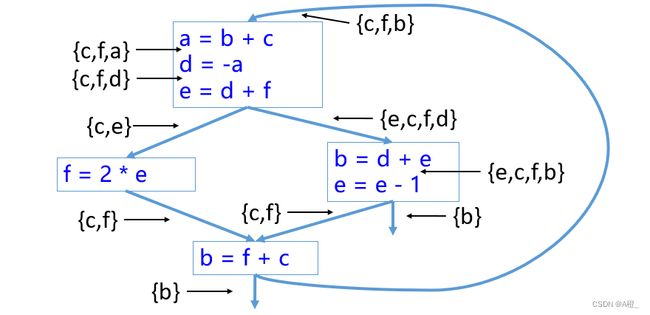
活性分析
对以下控制流图所示的程序进行活性分析,结果标在图中。
画出寄存器冲突图
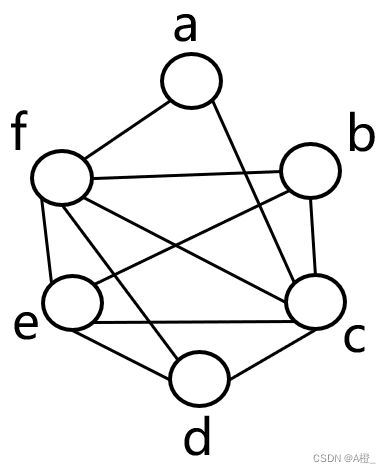
寄存器冲突图是一个无向图,每个节点是一个变量,如果两个变量有同时活跃的情况,添加一条边连接两个变量对应的节点。如果两个变量没有边连接,说明他们可以使用同一个寄存器。
以上程序的寄存器冲突图如下:
对RIG进行图着色分配寄存器
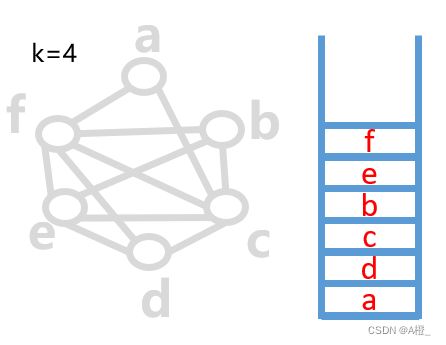
给每个节点着色,相当于为每个变量分配寄存器。如果一个图可以被k种颜色着色,两个连接的节点颜色不相同,该图为k可着色图。k可着色图的特点是,从图中删除一个边小于k的点,如果删除后的图是k可着色的,那么原图也一定是k可着色的,因为这个删除的点连接的边数小于k,总能找到一种不一样的颜色。根据这个特点,可以使用启发式算法对RIG进行图着色,将着色算法分为两部分:
- 删除点
- 选择一个邻居数量小于k个的节点t(暂时假设总能找到),从RIG中删除t和它所有的边
- 把t放在栈顶
- 重复上述步骤直到RIG中没有节点
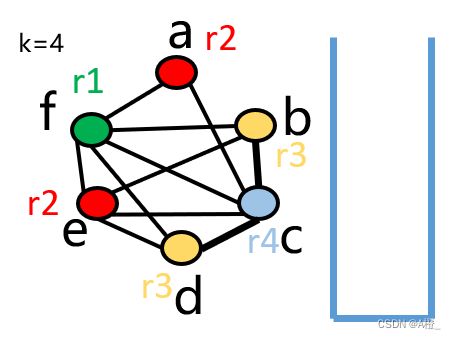
- 着色
- 从栈顶弹出1个节点
- 给该节点选择1种与其邻居都不同的颜色
- 重复上述步骤直到栈为空
将无法分配寄存器的变量溢出
如果使用以上的着色算法无法找到邻居数量小于k个的节点,就需要溢出变量,将其存放在内存里。方式是选择一个邻居大于等于k的节点f照常入栈,然后进行着色,直到出栈节点为溢出的节点f,先尝试对其进行着色,如果无法着色,就在每次使用节点前插入load指令,在每次定义节点后插入store指令,然后重新计算活性分析,再重新画出RIG图,进行寄存器分配。
找到可行的图着色方案,可能需要多次溢出,溢出哪个变量很关键,也很难确定,可能的启发式算法有:
- 选择与其他变量冲突最多的变量
- 选择使用较少的变量
- 避免溢出循环内部的变量
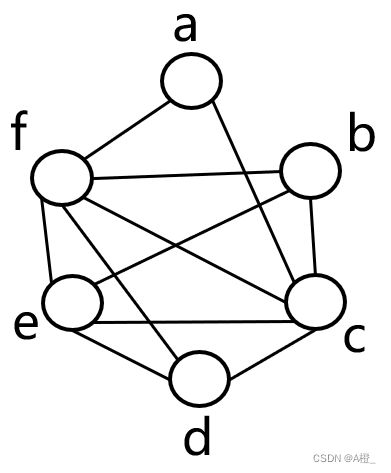
画出寄存器冲突图
寄存器冲突图是一个无向图,每个节点是一个变量,如果两个变量有同时活跃的情况,添加一条边连接两个变量对应的节点。如果两个变量没有边连接,说明他们可以使用同一个寄存器。
以上程序的寄存器冲突图如下:
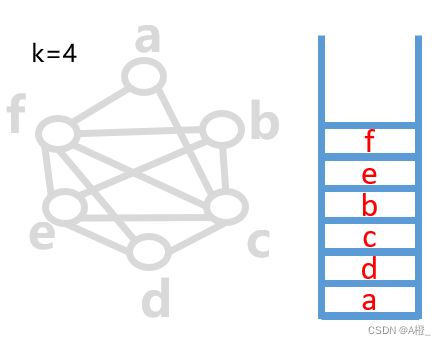
对RIG进行图着色分配寄存器
给每个节点着色,相当于为每个变量分配寄存器。如果一个图可以被k种颜色着色,两个连接的节点颜色不相同,该图为k可着色图。k可着色图的特点是,从图中删除一个边小于k的点,如果删除后的图是k可着色的,那么原图也一定是k可着色的,因为这个删除的点连接的边数小于k,总能找到一种不一样的颜色。根据这个特点,可以使用启发式算法对RIG进行图着色,将着色算法分为两部分:
- 删除点
- 选择一个邻居数量小于k个的节点t(暂时假设总能找到),从RIG中删除t和它所有的边
- 把t放在栈顶
- 重复上述步骤直到RIG中没有节点
- 着色
- 从栈顶弹出1个节点
- 给该节点选择1种与其邻居都不同的颜色
- 重复上述步骤直到栈为空
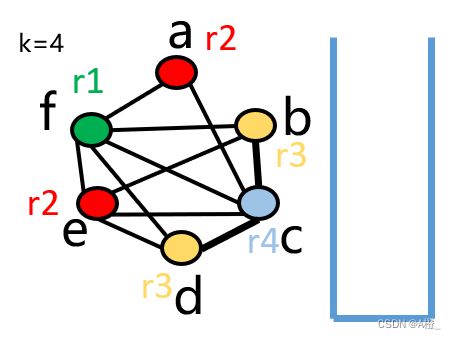
将无法分配寄存器的变量溢出
如果使用以上的着色算法无法找到邻居数量小于k个的节点,就需要溢出变量,将其存放在内存里。方式是选择一个邻居大于等于k的节点f照常入栈,然后进行着色,直到出栈节点为溢出的节点f,先尝试对其进行着色,如果无法着色,就在每次使用节点前插入load指令,在每次定义节点后插入store指令,然后重新计算活性分析,再重新画出RIG图,进行寄存器分配。
找到可行的图着色方案,可能需要多次溢出,溢出哪个变量很关键,也很难确定,可能的启发式算法有:
- 选择与其他变量冲突最多的变量
- 选择使用较少的变量
- 避免溢出循环内部的变量