目标检测之fasterRCNN:关于学习使用fasterRCNN做目标检测
首先大体采用的是迁移学习的思路,注主要是对模型迁移,在img做了切割和西工大及北航的数据集上进行一个交叉训练,这样使得RPN的网络外面的打分函数有了一个更好的0.7的结果, 这个结果主要是通过对reLu这个网络进行求导发现这个函数的凸性问题从而得到局部最优,这样保证在训练时候能够更好的从概率密度函数中选取L2而不是L1,
通过以下流程说明网络种的核心(前后景问题)
首先RPN会找到一个提取候选框通过坐标的五个参数映射到特征图上(这个过程使用传统的CNN相关结构提取特征)得到RoI,下一步会出现RoI的调整尺寸,调整完后进行固定出现了带特征的RoI的pooling,通过RoI的特征可以回归(这个其实就是研究函数变化问题找到一个合适的参数)和分类(一般这个就是通过距离函数计算样本的有关距离问题)。
通过上面的办法得到的是Region Proposal Networks(候选网络/区域生成网络)得到的是最终检测框+类别(两个目标/这就是目标检测不是单纯的分类),这个过程种的分类工作是神经网络获得特征计算距离分类完成,而RPN实现的是提取候选区域实现输出的目标检测。
从rate上来看应该是ZF的RPN+FastRCNN比较好,效率高同时mAP好。接下来说哥关键环节
RPN在fasterRcnn中是介于feature Map和fastRcnn之间
RPN里面是三次卷积,流程如下:
公共特征区域就是说(Feature Map)后的(H x W),首先进行一次256*(H x W),这三个均为256个维度,图像的参数(x y w h),这里需要分清楚那个前景的分数和那个是背景的参数,同时我们要清楚的一个概念是HxW的2scores+4个坐标
每做一次卷积就会得到1xHxW和2个xHxW的特征图,这个HxW其实就是Feature Map
当我们得到9个anchor时候就是说9个HxWx9个结果:其实是18个scores和36个坐标。每个anchor对于K个框(HxWxk框映射位anchor boxes)这里出现了相对于原图的坐标位移同时k一般是9个,9个anchor得到两层score,前后景的score。框大小和比例是:(128X128 256X256 512X512)长宽比例:2:1,1:1,1:2,
整体网络流程:
CNN——3x3卷积/RPN——256x16x16(16x16个256维度的特征向量)——1x1卷积出现两层((2x9)x16x16/(4x9)x16x16)的两个scores和四个坐标——通过NMS删除背景框(16x16x9)的那个升序排序中分数最低的框,同时取出最高分数的K个框 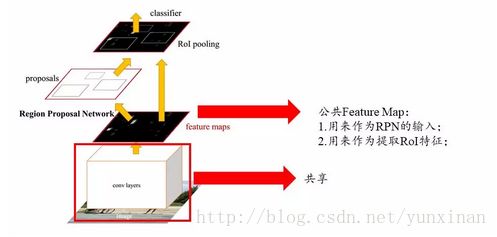
object localization
多任务学习,网络带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里还另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。
object detection
在目标定位中,通常只有一个或固定数目的目标,而目标检测更一般化,其图像中出现的目标种类和数目都不定。因此,目标检测是比目标定位更具挑战性的任务。
基于候选区域的目标检测算法‘
候选区域生成算法通常基于图像的颜色、纹理、面积、位置等合并相似的像素,最终可以得到一系列的候选矩阵区域。这些算法,如selective search或EdgeBoxes,通常只需要几秒的CPU时间,而且,一个典型的候选区域数目是2k,相比于用滑动窗把图像所有区域都滑动一遍,基于候选区域的方法十分高效。另一方面,这些候选区域生成算法的查准率(precision)一般,但查全率(recall)通常比较高,这使得我们不容易遗漏图像中的目标
兴趣区域汇合(region of interest pooling, RoI pooling)
兴趣区域汇合旨在由任意大小的候选区域对应的局部卷积特征提取得到固定大小的特征,这是因为下一步的两分支网络由于有全连接层,需要其输入大小固定。其做法是,先将候选区域投影到卷积特征上,再把对应的卷积特征区域空间上划分成固定数目的网格(数目根据下一步网络希望的输入大小确定,例如VGGNet需要7×7的网格),最后在每个小的网格区域内进行最大汇合,以得到固定大小的汇合结果。和经典最大汇合一致,每个通道的兴趣区域汇合是独立的。
为什么要使用锚盒(anchor box)
锚盒是预先定义形状和大小的包围盒。使用锚盒的原因包括:(1). 图像中的候选区域大小和长宽比不同,直接回归比对锚盒坐标修正训练起来更困难。(2). conv5特征感受野很大,很可能该感受野内包含了不止一个目标,使用多个锚盒可以同时对感受野内出现的多个目标进行预测。(3). 使用锚盒也可以认为这是向神经网络引入先验知识的一种方式。我们可以根据数据中包围盒通常出现的形状和大小设定一组锚盒。锚盒之间是独立的,不同的锚盒对应不同的目标,比如高瘦的锚盒对应于人,而矮胖的锚盒对应于车辆。
基于候选区域的目标检测算法通常需要两步:第一步是从图像中提取深度特征,第二步是对每个候选区域进行定位(包括分类和回归)。其中,第一步是图像级别计算,一张图像只需要前馈该部分网络一次,而第二步是区域级别计算,每个候选区域都分别需要前馈该部分网络一次。因此,第二步占用了整体主要的计算开销。R-CNN, Fast R-CNN, Faster R-CNN, R-FCN这些算法的演进思路是逐渐提高网络中图像级别计算的比例,同时降低区域级别计算的比例。R-CNN中几乎所有的计算都是区域级别计算,而R-FCN中几乎所有的计算都是图像级别计算。
(3) 基于直接回归的目标检测算法
YOLO的优点在于:(1). 基于候选区域的方法的感受野是图像中的局部区域,而YOLO可以利用整张图像的信息。(2). 有更好的泛化能力。
YOLO的局限在于:(1). 不能很好处理网格中目标数超过预设固定值,或网格中有多个目标同时属于一个锚盒的情况。(2). 对小目标的检测能力不够好。(3). 对不常见长宽比的包围盒的检测能力不强。(4). 计算损失时没有考虑包围盒大小。大的包围盒中的小偏移和小的包围盒中的小偏移应有不同的影响。
相比YOLO,SSD在卷积特征后加了若干卷积层以减小特征空间大小,并通过综合多层卷积层的检测结果以检测不同大小的目标。此外,类似于Faster R-CNN的RPN,SSD使用3×3卷积取代了YOLO中的全连接层,以对不同大小和长宽比的锚盒来进行分类/回归。SSD取得了比YOLO更快,接近Faster R-CNN的检测性能。后来有研究发现,相比其他方法,SSD受基础模型性能的影响相对较小。
FPN融合多层特征,以综合高层、低分辨率、强语义信息和低层、高分辨率、弱语义信息来增强网络对小目标的处理能力。此外,和通常用多层融合的结果做预测的方法不同,FPN在不同层独立进行预测。FPN既可以与基于候选区域的方法结合,也可以与基于直接回归的方法结合。FPN在和Faster R-CNN结合后,在基本不增加原有模型计算量的情况下,大幅提高对小目标的检测性能。
RetinaNet
RetinaNet认为,基于直接回归的方法性能通常不如基于候选区域方法的原因是,前者会面临极端的类别不平衡现象。基于候选区域的方法可以通过候选区域过滤掉大部分的背景区域,但基于直接回归的方法需要直接面对类别不平衡。因此,RetinaNet通过改进经典的交叉熵损失以降低对已经分的很好的样例的损失值,提出了焦点(focal)损失函数,以使模型训练时更加关注到困难的样例上。RetinaNet取得了接近基于直接回归方法的速度,和超过基于候选区域的方法的性能。
语义分割(semantic segmentation)
语义分割是目标检测更进阶的任务,目标检测只需要框出每个目标的包围盒,语义分割需要进一步判断图像中哪些像素属于哪个目标。
逐像素进行图像分类。我们将整张图像输入网络,使输出的空间大小和输入一致,通道数等于类别数,分别代表了各空间位置属于各类别的概率,即可以逐像素地进行分类。
全卷积网络+反卷积网络
为使得输出具有三维结构,全卷积网络中没有全连接层,只有卷积层和汇合层。但是随着卷积和汇合的进行,图像通道数越来越大,而空间大小越来越小。要想使输出和输入有相同的空间大小,全卷积网络需要使用反卷积和反汇合来增大空间大小。
(3) 语义分割常用技巧
扩张卷积(dilated convolution)
经常用于分割任务以增大有效感受野的一个技巧。标准卷积操作中每个输出神经元对应的输入局部区域是连续的,而扩张卷积对应的输入局部区域在空间位置上不连续。扩张卷积保持卷积参数量不变,但有更大的有效感受野。
实例分割(instance segmentation)
语义分割不区分属于相同类别的不同实例。例如,当图像中有多只猫时,语义分割会将两只猫整体的所有像素预测为“猫”这个类别。与此不同的是,实例分割需要区分出哪些像素属于第一只猫、哪些像素属于第二只猫。
基本思路
目标检测+语义分割。先用目标检测方法将图像中的不同实例框出,再用语义分割方法在不同包围盒内进行逐像素标记。
Mask R-CNN
用FPN进行目标检测,并通过添加额外分支进行语义分割(额外分割分支和原检测分支不共享参数),即Master R-CNN有三个输出分支(分类、坐标回归、和分割)。此外,Mask R-CNN的其他改进有:(1). 改进了RoI汇合,通过双线性差值使候选区域和卷积特征的对齐不因量化而损失信息。(2). 在分割时,Mask R-CNN将判断类别和输出模板(mask)这两个任务解耦合,用sigmoid配合对率(logistic)损失函数对每个类别的模板单独处理,取得了比经典分割方法用softmax让所有类别一起竞争更好的效果。
Coursera吴恩达《卷积神经网络》课程笔记(3)– 目标检测
Object Localization目标检测
Landmark Detection 除了使用矩形区域检测目标类别和位置外,我们还可以仅对目标的关键特征点坐标进行定位,这些关键点被称为landmarks。
该网络模型共检测人脸上64处特征点,加上是否为face的标志位,输出label共有64x2+1=129个值。通过检测人脸特征点可以进行情绪分类与判断,或者应用于AR领域等等。
除了人脸特征点检测之外,还可以检测人体姿势动作
Object Detection
目标检测的一种简单方法是滑动窗算法,Convolutional Implementation of Sliding Windows
滑动窗算法可以使用卷积方式实现,以提高运行速度,节约重复运算成本。
首先,单个滑动窗口区域进入CNN网络模型时,包含全连接层。那么滑动窗口算法卷积实现的第一步就是将全连接层转变成为卷积层
这一节主要介绍YOLO算法的流程,算是对前几节内容的回顾。网络结构如下图所示,包含了两个Anchor Boxes。
- For each grid call, get 2 predicted bounding boxes.
- Get rid of low probability predictions.
- For each class (pedestrian, car, motorcycle) use non-max suppression to generate final predictions.Region Proposals的方法。具体做法是先对原始图片进行分割算法处理,然后支队分割后的图片中的块进行目标检测。
Region Proposals共有三种方法:
R-CNN: 滑动窗的形式,一次只对单个区域块进行目标检测,运算速度慢。
Fast R-CNN: 利用卷积实现滑动窗算法,类似第4节做法。
Faster R-CNN: 利用卷积对图片进行分割,进一步提高运行速度。
比较而言,Faster R-CNN的运行速度还是比YOLO慢一些。