模型发生过拟合了怎么办?分享一个调参实例
文章目录
-
- 1 什么是过拟合
- 2 一个过拟合模型
- 3 处理上述过拟合
- 3.1 减少网络容量
- 3.2 使用正则化
- 3.3 Dropout
- 4 总结
1 什么是过拟合
过拟合:当你的模型拟合的很好,但在新的,未见过的数据上不能很好地泛化时,就发生了过拟合。
简单来讲:train loss 不断下降,但 val loss 停止下降,甚至不断增大时,就说明过拟合了。
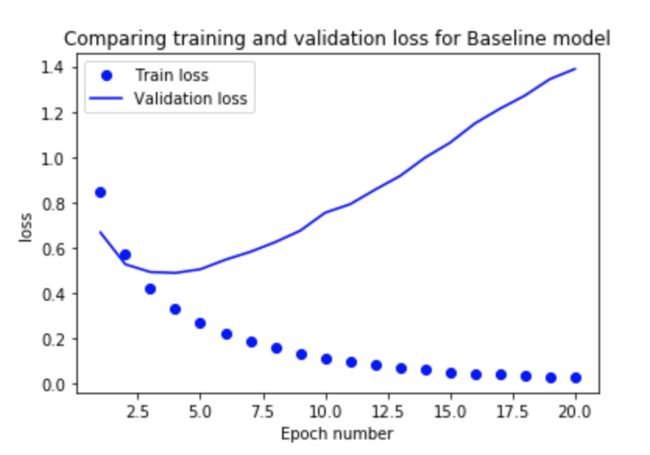
如图,train loss 在不断下降,但是 val loss 在几个 epoch 后开始上升了,和 train loss 的差距越来越大,这就是明显的过拟合。
2 一个过拟合模型
首先,我们设计一个基线模型,让它发生过拟合。
基线模型:它有 2 个 64 个元素的密集连接层。第一层的input_shape等于卷积后的所有隐藏单元(10000个)。
我们需要预测 3 个不同的情感类别,因此最后一层有 3 个元素,并使用
SOFTMAX激活。该SOFTMAX激活功能可确保三个概率加起来为1。
base_model = models.Sequential()
base_model.add(layers.Dense(64, activation='relu', input_shape=(NB_WORDS,)))
base_model.add(layers.Dense(64, activation='relu'))
base_model. add(layers.Dense(3, activation='softmax'))
base_model.name = '基线模型'
要训练的参数数量计算为(nb 个输入 x nb 个隐藏层中的元素)+ nb 个偏置项。所以每层的参数数量是:
- 第一层:(10000 x 64) + 64 = 640064
- 第二层:(64 x 64) + 64 = 4160
- 最后一层:(64 x 3) + 3 = 195
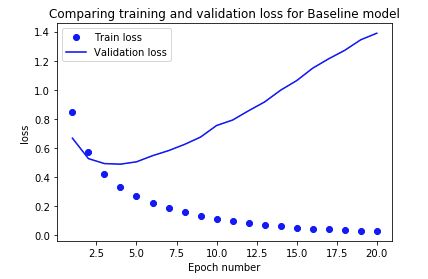
一开始,验证损失下降。但是在 epoch 3 这停止了,验证损失开始迅速增加。这是模型开始过度拟合的时候。
该训练损失继续下跌,并在 epoch=20 几乎达到零,以适应训练数据.
3 处理上述过拟合
- 通过移除层或减少隐藏层中的元素数量来降低网络容量
- 使用正则化,这归结为为大权重的损失函数增加成本
- 使用 Dropout 层,它将通过将某些特征设置为零来随机删除某些特征
我们会介绍这三种方法对结果带来的影响。
3.1 减少网络容量
我们的第一个模型有大量可训练的参数。这个数字越大,模型就越容易记住每个训练样本的目标类别。显然,这对于概括新数据来说并不理想。
通过降低网络的容量,你迫使它学习重要的模式或最小化损失的模式。另一方面,过多地降低网络容量会导致欠拟合。该模型将无法学习训练数据中的相关模式。因此,要把握好度。
我们通过移除一个隐藏层并将剩余层中的元素数量减少到 16 来减少网络的容量。(之前是两个 Dense, 每个 Dense 有64个元素)
reduce_model = models.Sequential() Reduce_model.add(
layers.Dense(16, activation='relu', input_shape=(NB_WORDS,)))
reduction_model.add(layers.Dense(3, activation='softmax'))
reduction_model. name = '简化模型'
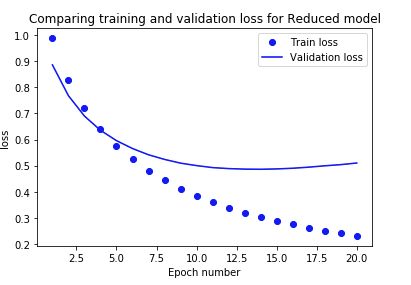
我们可以看到,减少容量后,模型过拟合的速度变慢了,train loss 和 val loss的差距变小了。
但是train loss 比基线模型更大,没有基线拟合的好,毕竟我们删除了一个全连接层。
3.2 使用正则化
为了解决过拟合问题,我们可以对模型应用权重正则化。这将为大权重(或参数值)的网络损失函数增加成本。因此,您将获得一个更简单的模型,该模型将被迫仅学习训练数据中的相关模式。
有L1 正则化和 L2 正则化。
- L1 正则化将增加关于参数绝对值的成本。这将导致某些权重为零。
- L2 正则化将增加与参数平方值有关的成本。这导致较小的权重。
reg_model = models.Sequential()
reg_model.add(layers.Dense(64, kernel_regularizer=regularizers.l2(0.001), activation='relu', input_shape=(NB_WORDS,)))
reg_model.add(layers.Dense(64, kernel_regularizer=regularizers.l2(0.001), activation='relu'))
reg_model.add(layers.Dense(3, activation='softmax'))
reg_model.name = 'L2 正则化模型'
这是keras的正则化方法,在pytorch中不是这样的,在pytorch中,最常见的正则化为
optim = torch.optim.SGD(parameters(), lr=lr, weight_decay=1e-2)
这里的 weight_decay=1e-2就是使用了L2正则化
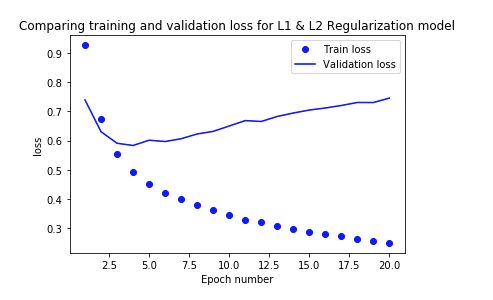
正则化后,val loss 没有基线大,但是过拟合也十分明显。
3.3 Dropout
我们将尝试的最后一个选项是添加 Dropout 层。Dropout 层会将设定层的输出特征随机设置为零。
drop_model = models.Sequential()
drop_model.add(layers.Dense(64, activation='relu', input_shape=(NB_WORDS,)))
drop_model.add(layers.Dropout(0.5))
drop_model.add(layers.Dense( 64, activation='relu'))
drop_model.add(layers.Dropout(0.5))
drop_model.add(layers.Dense(3, activation='softmax'))
drop_model.name = 'Dropout layers model'
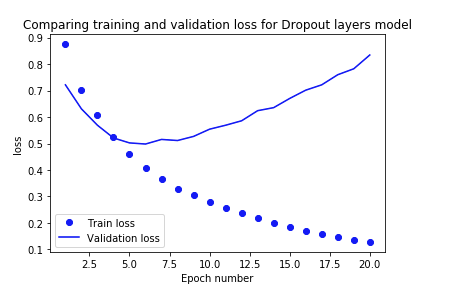
带有 dropout 层的模型开始过拟合的时间晚于基线模型。损失的增加速度也比基线模型慢。
乍一看,缩减模型似乎是泛化的最佳模型。但是让我们在测试集上检查一下。正则化和Dropout的结果更好。

4 总结
如上所示,所有三个选项都有助于减少过度拟合。我们设法大大提高了测试数据的准确性。在这三个选项中,带有 Dropout 层的模型在测试数据上的表现最好。当然,也可以将这些方法组合使用。
您可以在 GitHub 上找到该代码, GitHub code
文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连
