CompressAI基于pytorch框架的图像压缩使用
CompresssAI介绍
CompressAI 是将四篇基于深度学习端到端图像压缩代码从tensorflow搬移到了pytorch上,提供了完整的实例代码和使用教程,具体可以看CompressAI的Github官方库,同时提供了与传统图像编码方式的对比。CompressAI对图像压缩领域的新手来说是一个比较好的入手方向。
项目地址:CompressAI
项目使用教程
四篇端到端图像编码算法代码:
《End-to-end Optimized Image Compression》
《Variational Image Compression With A Scale Hyperprior》
《Joint Autoregressive and Hierarchical Priors for Learned Image Compression》
《Learned Image Compression with Discretized Gaussian Mixture Likelihoods and
Attention Modules》
传统图像编码算法:
BPG
HEVC HM
VVC VTM
环境安装
使用conda环境安装pytorch 1.7.1 cuda=11.0
conda create -n env_name python=3.8
安装pytorch
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
pytorch安装过程中推荐使用中科大源
CompressAI安装
复制CompressAI库
git clone https://github.com/InterDigitalInc/CompressAI compressai
安装CompressAI
cd compressai
pip install -e .
使用
数据准备
在某个文件夹下准备数据集,/path/to/my/image/dataset/ 表示数据集的目录, 该数据集下分为 train 和test目录, train内部放train的 .png图像, test放测试图像。
训练
-m 指模型, -d 数据集地址,-e epoch数, --lambda 拉格朗日乘子,–batch-size训练时的batchsize 根据数据而定,–patch-size 图像块大小。–cuda 使用GPU,–save保存训练好的模型。
python examples/train.py -m "mbt2018" -d /path/to/my/image/dataset/ -e 100 --lambda 1e-2 --batch-size 32 --test-batch-size 16 --patch-size 256 256 --cuda --save
训练结束后需要更新CDF保证熵编码的正常运行(此处模型与上面一致):
python -m compressai.utils.update_model --architecture mbt2018 checkpoint_best_loss.pth.tar
测试
python -m compressai.utils.eval_model checkpoint /path/to/my/image/dataset/test -a mbt2018 -p checkpoint_best_loss-a57a3f14.pth.tar
模型选择:
bmshj2018_factorized
bmshj2018_hyperprior
mbt2018
mbt2018_mean
cheng2020_anchor
cheng2020_attn
注意事项
使用inference的时候
1.对于entropy estimation 使用cuda会比使用CPU快
2. 对于自回归模型,不建议使用cuda编解码,因为熵编码部分,会在CPU上顺序执行。
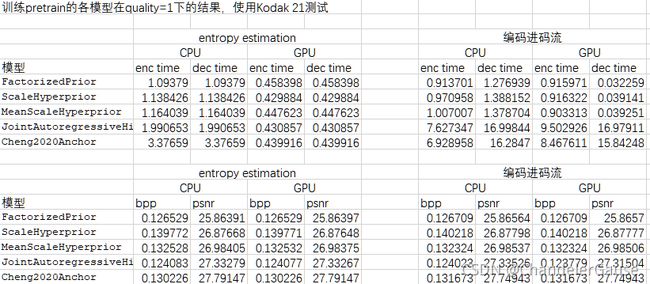
3.以下为测试结果说明几个问题:
(a)GPU对非自回归模型推理,在码率估计和实际压缩都能起到加速作用。GPU对自回归模型不能起到加速左右,因为熵编码是在CPU中线性运算编码的。
(b)使用GPU或者CPU,码率估计结果是与实际结果是接近的。
坑
训练好的模型无法更新CDF
此时更改examples/train.py中的save_checkpoint
def save_checkpoint(state, filename="checkpoint.pth.tar"):
torch.save(state, filename)
另外保存代码也更新一下
if args.save:
save_checkpoint(
{
"epoch": epoch,
"state_dict": net.state_dict(),
"loss": loss,
"optimizer": optimizer.state_dict(),
"aux_optimizer": aux_optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
}
)
if is_best:
save_checkpoint(
{
"epoch": epoch,
"state_dict": net.module.state_dict(),
"loss": loss,
"optimizer": optimizer.state_dict(),
"aux_optimizer": aux_optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
},
filename="checkpoint_best_loss.pth.tar"
)