Go语言基础学习笔记
Golang官方文档: 点击进入
尚硅谷视频:点击进入
目录
- 01、标识符
- 1.1、命名规则
- 1.2、标识符命名规范
- 1.3、go运算符优先级
- 02、数据类型
- 2.1、Go中数据类型分类
- 变量与常量
- 2.2、基本数据类型转string
- 2.3、string转基本数据类型
- 2.4、数组
- 2.5、切片
- 2.6、map
- 03、go流程控制
- 3.1、条件语句
- 3.2、选择语句
- 3.3、循环语句
- 3.4、标签、跳转语句
- 3.5、延迟语句
- 04、函数
- 4.1、基本概念
- 4.2、内置函数
- 4.3、init函数
- 4.4、匿名函数
- 4.5、闭包
- 4.6、函数值传递机制
- 4.7、字符串常用函数
- 4.8、时间和日期相关函数
- 4.9、生成随机数
- 4.10、错误处理
- 05、包
- 5.1、基本概念
- 5.2、go module
- 06、排序和查找
- 07、面向对象
- 7.1、结构体
- 7.2、工厂模式
- 7.3、方法
- 7.3.1、方法快速入门
- 7.3.2、方法的调用和传参机制
- 7.4、封装
- 7.5、继承
- 7.5.1、多重继承
- 7.6、多态
- 7.6.1、类型断言
- 08、接口与反射
- 8.1、接口
- 8.2、反射
- 09、文件处理
- 9.1、文件操作
- 9.2、命令行参数
- 9.3、json处理
- 10、安全与测试
- 10.1、单元测试
- 11、并发编程
- 11.1、基础概念
- 11.2、协程(goroutine)
- 11.2.1、MPG模式
- 11.3、设置Golang运行的cpu个数
- 11.4、通道(channel)
- 12、网络编程
- 12.1、socket编程
- 13、Redis
- 13.1、redis数据类型及其操作
01、标识符
1.1、命名规则
-
由26个英文字母大小写、0-9,_组成
-
数字不可以开头
-
golang严格区分大小写
-
标识符不能包含空格
-
下划线“ _ ”本身在go中是一个特殊的标识符,称为空标识符。可以代表任何其他的标识符,但是它对应的值会被忽略(比如:忽略某个返回值)。所以仅能作为占位符使用,不能单独作为标识符使用(与字母数字混合使用)。
-
不能以系统保留关键字作为标识符。(有25个)
break default func interface select case defer go map struct chan else goto package switch const fallthrough if range type continue for import return var
预定义标示符
除了保留关键字外,GO还提供了36个预定的标示符,其包括基本的数据类型和系统内嵌函数
append bool byte cap close complex
complex64 complex128 uint16 copy false float32
float64 imag int int8 int16 uint32
int32 int64 iota len make new
nil panic unit64 print println real
recover string true uint uint8 uintprt
hello //ok
hello12 //ok
1hello //error
h-b //error
x h //error
int //ok,语法可以但不要这样用
float32 //ok,语法可以但不要这样用
_ //error
Abc //ok
1.2、标识符命名规范
-
包名:保持package的名字和目录保持一致,尽量采用有意义的包名,简短,有意义,不要和标准库冲突 比如fmt。包名建议使用小写字母命名。
-
变量名、函数名、常量名:采用驼峰法
eg: var stuName string = “tom” 形式:xxxYyyZzz
-
如果变量名、函数名、常量名首字母大写,则可以被其他的包访问;如果首字母小写,则只能在本包中使用(理解:首字母大写是公开的,首字母小写是私有的;在golang中没有public,private等关键字)
1.3、go运算符优先级
由高到低
| 分类 | 运算符 | 结合性 |
|---|---|---|
| 后缀 | () [] -> . ++ – | 左到右 |
| 单目 | + - ! ~ (type) * & sizeof | 右到左 |
| 乘法 | * / % | 左到右 |
| 加法 | + - | 左到右 |
| 移位 | << >> | 左到右 |
| 关系 | < <= > >= | 左到右 |
| 相等(关系) | == != | 左到右 |
| 按位AND | & | 左到右 |
| 按位XOR | ^ | 左到右 |
| 按位OR | | | 左到右 |
| 逻辑AND | && | 左到右 |
| 逻辑OR | || | 左到右 |
| 赋值运算符 | = += -= *= /= %= >>= <<= &= ^= |= | 右到左 |
| 逗号 | , | 左到右 |
02、数据类型
2.1、Go中数据类型分类
1、值类型:变量直接存储值,内存通常分配在栈中,栈在函数调用完后会被释放
基本数据类型: int系列,float系列,bool,string,数组和结构体struct
int系列{int(32或64)、int8、int16、int32、int64,以及uint(32或64)、uint8、uint16、uint32、uint64}
float系列{flaot32、float64}
Go语言中有一种特殊的数据类型rune,该数据类型与int32是同义词,或者说其本身只是int32的别称。
byte 等同于uint8,常用来处理ascii字符
rune 等同于int32,常用来处理unicode或utf-8字符
type byte = uint8
type rune = int32
str := "我爱我的祖国ilovechina"//汉字占三个字节
fmt.Printf("str字符串长度是%v\n", len(str)) //28,string底层是一个[]byte数组
fmt.Printf("str字符串长度是%v\n", len([]rune(str))) //16
2、引用类型:变量直接存储的是一个地址,这个地址对应的空间才真正存储数据值,内存通常在堆上分配,当没有任何变量引用这个地址时该地址对应的数据空间就成为一个垃圾,由GC来回收
指针,slice切片,map,通道chan,interface,函数等
变量与常量
变量:
var a int
var b float32
var c, d float64
e, f := 9, 10
var g = "xinxiang"
- 在Golang中定义一个变量,需要使用var关键字,与java,c不同的是变量的类型需要写在变量的后面,在Golang中,允许我们一次性定义多个变量并同时赋值
- 还有另外的一种做法,是使用
:=这个符号(:=表示函数内部变量声明并赋值)。使用了这个符号之后,开发者不再需要写var关键字,只需要定义变量名,并在后面进行赋值即可。并且,Golang编译器会根据后面的值的类型,自动推导出变量的类型 - Golang是强类型的一种语言,所有的变量必须拥有类型,并且变量仅仅可以存储特定类型的数据
- 标识符为_(下划线)的变量,是系统保留的匿名变量,在赋值后,会被立即释放,称之为匿名变量。其作用是变量占位符,对其变量赋值结构。通常会在批量赋值时使用,函数返回多个值,我们仅仅需要其中部分,则不需要的 使用_来占位
- 局部变量定义了就一定要使用,否则panic
常量:
-
在Golang的常量定义中,使用
const关键字,并且不能使用:=标识符 -
常量的值必须是固定的,这个固定是要求在编译时就能确定的,常量在定义的时候就要初始化
-
常量只能修饰bool,int系列,float系列,string
-
Go中没有规定常量必须要字母大写
-
仍然可以通过首字母的大小写来控制常亮的访问范围
const identifier [type] = value
const pi = 3.1415926536
const pi float32= 3.1415926536
const c1 = 6/3 //ok
const c2 = getNumber() //panic
const(
a = 1
b = 2
)
fmt.Println(a,b) //1,2
const(
a = iota //给a赋值0,后面每行加1
b
c
d
)
fmt.Println(a, b, c, d) //0,1,2,3
2.2、基本数据类型转string
package main
import (
"fmt"
"strconv"
)
//基本数据类型转string
func main() {
var num1 int = 99
var num2 float64 = 23.345
var b bool = true
var myChar byte = 'm'
var str string
/*
方式一、使用第一种方式 fmt.Sprintf方法
func Sprintf(format string, a ...interface{}) string
Sprintf根据format参数生成格式化的字符串并返回该字符串。
*/
str = fmt.Sprintf("%d", num1)
fmt.Printf("str type %T str=%q\n", str, str)
str = fmt.Sprintf("%f", num2)
fmt.Printf("str type %T str=%q\n", str, str)
str = fmt.Sprintf("%t", b)
fmt.Printf("str type %T str=%q\n", str, str)
str = fmt.Sprintf("%c", myChar)
fmt.Printf("str type %T str=%q\n", str, str)
/*
方式二,使用strconv包中的FormatXxx函数
func FormatBool(b bool) string
func FormatInt(i int64, base int) string
func FormatUint(i uint64, base int) string
func FormatFloat(f float64, fmt byte, prec, bitSize int) string
func Itoa(i int) string
*/
var num3 int = 99
var num4 float64 = 23.345
var b2 bool = true
str = strconv.FormatInt(int64(num3), 10)
fmt.Printf("str type %T str=%q\n", str, str)
//说明:'f'格式 10:表示小数位保留10位 64:表示这个小数是float64
str = strconv.FormatFloat(num4, 'f', 10, 64)
fmt.Printf("str type %T str=%q\n", str, str)
str = strconv.FormatBool(b2)
fmt.Printf("str type %T str=%q\n", str, str)
//strconv中函数Itoa,将int转换成string
var num5 int = 456
str = strconv.Itoa(num5)
fmt.Printf("str type %T str=%q\n", str, str)
}
2.3、string转基本数据类型
package main
import (
"fmt"
"strconv"
)
/*
使用strconv包里面的函数,将string转基本数据类型
func ParseBool(str string) (value bool, err error)
func ParseInt(s string, base int, bitSize int) (i int64, err error)
func ParseUint(s string, base int, bitSize int) (n uint64, err error)
func ParseFloat(s string, bitSize int) (f float64, err error)
func Atoi(s string) (i int, err error)
*/
func main() {
var str string = "true"
var b bool
//ParseXxx函数会返回两个值,我们只想要value bool,不想获取err 所以使用 _ 忽略
b, _ = strconv.ParseBool(str)
fmt.Printf("b type %T b=%v\n", b, b)
var str2 string = "123456789"
var n1 int64
n1, _ = strconv.ParseInt(str2, 10, 64)
fmt.Printf("n1 type %T n1=%v\n", n1, n1)
var str3 string = "123.456"
var n2 float64
n2, _ = strconv.ParseFloat(str3, 64)
fmt.Printf("n2 type %T n2=%v\n", n2, n2)
//对以上说明:返回的是int64 float64,可以再转化成int32 float32
//注意:string转基本数据类型事项:要确保string能转成相应的基本数据类型
var str4 string = "hello"
var n3 int64
n3, _ = strconv.ParseInt(str4, 10, 64)
fmt.Printf("n3 type %T n3=%v\n", n3, n3) //不会报错,但无法转换,显示默认值n3=0
}
2.4、数组
数组的定义:
var 数组名 [数组大小]数据类型
初始化数组的方式
var array [3]int = [3]int{1,2,3}
array := [4][2]int{{10,11},{20,21},{30,31},{40,41}}
var array = [3]int{1,2,3}
array := [...]string{}
//给特定下标指定具体值
var array = [3]string{1:"tom",2:jack}
//...代替数组的长度,go语言根据初始化时数组的元素确定数组的长度
var array = [...]int{1,2,3}
数组的遍历
1、常规做法
var arr = [...]arr{1,2,3,4}
for i := 0;i < len(arr); i++ {
fmt.Printf("%d \n",arr[i])
}
2、for-range结构遍历
var arr = [...]int{1,2,3,4}
for _,v := range arr {
fmt.Printf("%v \n",v)
}
数组使用注意事项:
- [10]int 与 [30]int不是同一种类型
- 数组创建之后长度就确定了
- 数组第一个元素的地址就是数组的首地址
- 数组的各个元素的地址间隔是依据数组的类型决定
二维数组:
二维数组遍历:
var arr2 [2][3]int
for i := 0; i < len(arr2); i++ {
for j := 0; j < len(arr2[0]); j++ {
arr2[i][j] = i * j
}
}
for i, v := range arr2 {
for j, value := range v {
fmt.Printf("arr2[%v][%v]=%v\t", i, j, value)
}
fmt.Println()
}
2.5、切片
切片是数组的一个引用,
切片的长度是可以变化的,因此切片是一个动态变化数组
切片的定义:
var 切片名 []数据类型
var intArr [5]int = [...]int{1,22,3,4,5}
slice := intArr[1:3] //slice切片引用intArr数组的起始下标为1,最后的下标为3(但是不包括3)
fmt.Println("intArr",intArr)
fmt.Println("slice 的元素是", slice)
fmt.Println("slice 元素个数是", len(slice))
fmt.Println("slice 的容量是", cap(slice))
fmt.Printf("%T", slice) //[]int
输出:
intArr [1 22 3 4 5]
slice 的元素是 [22 3]
slice 元素个数是 2
slice 的容量是 4
slice[0] = 100
fmt.Println("intArr", intArr)
输出:
intArr [1 100 3 4 5]
对slice内存理解:
-
slice确实是一个引用类型
-
slice从底层来说,其实是一个数据结构(struct 结构体)
type slice struct{ ptr *[数组长度]数据类型 len int //长度 cap int //容量 }[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ofm6Qv4P-1668236508357)(https://gitee.com/lazyperson/typora-drawing-bed-01/raw/master/Image/202205070936911.png)]
-
slice对数组是引用,对slice修改,被引用的数组也会修改
切片的使用
-
定义一个切片,然后用切片去引用一个已经创建好的数组,如上
-
通过make来创建切片
基本语法:var sliceName []type = make([]type,len,[cap]) //sliceName := make([]type,len,cap) //type是数据类型,len大小,cap指定切片的容量,如果分配cap,则cap >= len -
定义一个切片,直接就指定具体数组,使用原理类似make方式
nil切片和空切片
只要在声明时不做任何初识化就会创建一个nil切片。在Golang中nil切片是很常见创建切片的方法,nil切片可以用于很多标准库和内置函数。在描述一个不存在的切片时,nil切片会很好用。
nil切片在底层数组中包含0个元素,也没有分配任何存储空间。
nil切片还可以用来表示空集合,例如数据库查询返回0个查询结果时,nil切片和普通切片一样,调用内置函数append、len、cap效果是一样的。
var slice []int

空切片和nil切片不同
// 使用 make 创建空的整型切片
myNum := make([]int, 0)
// 使用切片字面量创建空的整型切片
myNum := []int{}

切片使用的注意细节:
- 如果没有给切片的各个元素赋值,就会使用默认值
- 通过make方式创建的切片对应的数组是由make底层维护,对外不可见,即只能通过slice去访问各个元素
- 创建切片的方式1和方式2的区别:方式1是直接引用数组,这个数组是事先存在的,程序员是可见的。方式2是通过make来创建切片,make也会创建一个数组,是由切片在底层进行维护,程序员是不可见的
切片的遍历
- 循环常规方式遍历
- for-range结构遍历切片
切片使用注意事项和细节讨论
-
切片初始化时 var slice = arr[startIndex:endIndex]
说明:从arr数组下标为startIndex,取到下标为endIndex的元素(不包含arr[endIndex]),左闭右开区间
var slice = arr[0:end]可以简写var slice = arr[:end] var slice = arr[start:len(arr)] 可以简写 var slice = arr[start:] var slice = arr[0:len(arr)] 可以简写 var slice = arr[:] -
切片定义完后还不可以使用,因为本身是一个空的,需要让其引用到一个数组或者make一个空间供切片使用
-
切片可以继续切片
slice2 := slice[1,2] -
用append内置函数,可以对切片进行动态追加
-
相对于数组而言,使用切片的一个好处是:可以按需增加切片的容量。Golang 内置的 append() 函数会处理增加长度时的所有操作细节。要使用 append() 函数,需要一个被操作的切片和一个要追加的值,当 append() 函数返回时,会返回一个包含修改结果的新切片。函数 append() 总是会增加新切片的长度,而容量有可能会改变,也可能不会改变,这取决于被操作的切片的可用容量。
-
切片append操作的底层原理是对数组的扩容,扩容是在底层进行程序员不可见
func append(slice []Type, elems ...Type) []Type 内建函数append将元素追加到切片的末尾。若它有足够的容量,其目标就会重新切片以容纳新的元素。否则,就会分配一个新的基本数组。append返回更新后的切片,因此必须存储追加后的结果。var slice []int = [...]int{1,2,3} slice = append(slice,400,500,600) slice = append(slice,slice2...) -
-
切片是引用数据类型,在传递时,遵守引用传递机制
func main() { var arr [5]int = [5]int{11, 22, 33, 44, 55} var slice = arr[:] slice2 := slice slice2[0] = 666 fmt.Println(arr) fmt.Println(slice) fmt.Println(slice2) } 输出结果: [666 22 33 44 55] [666 22 33 44 55] [666 22 33 44 55]
切片中删除元素
go语言中并没有对删除切片元素提供专门的语法或接口
删除切片元素分为三种情况:开头位置删,中间位置删,尾部位置删
-
开头位置删
//删除开头位置元素可以直接移动数据指针 a = []int{1,2,3} a = a[1:] //删除第一个元素 a = a[N:] //删除开头N个元素 //也可以不移动数据指针,但是将后面的数据向开头移动,可以用 append 原地完成(所谓原地完成是指在原有的切片数据对应的内存区间内完成,不会导致内存空间结构的变化 a = []int{1, 2, 3} a = append(a[:0], a[1:]...) // 删除开头1个元素 a = append(a[:N], a[N:]...) // 删除开头N个元素 -
从中间位置删除
对于删除中间的元素,需要对剩余元素进行一次整体的移动,可以考虑使用append或者是copy
a := []int{1, 2, 3, ...} //这里面的...表示将切片打散然后append到a[:i]中 a = append(a[:i], a[i+1:]...) // 删除中间1个元素 a = append(a[:i], a[i+N:]...) // 删除中间N个元素 -
从尾部删除
a = []int{1, 2, 3} a = a[:len(a)-1] // 删除尾部1个元素 a = a[:len(a)-N] // 删除尾部N个元素
string和slice
- string底层是一个byte数组,因此string也可以进行切片处理
- string是不可变的,也就是不能通过str[0] = ‘z’ 方式来修改字符串
- 如果需要修改字符串,可以将string 转换成[]byte 或者 []rune -> 修改 -> 重新转成string
2.6、map
map是key-value数据结构,又称为字段或者关联数组。类似于其他编程语言的集合,在编程中是经常使用到。go中map在底层是用哈希(hash)表实现的,所以对map的读取顺序不固定
映射是一种数据结构,用于存储一系列无序的键值对,映射基于键来存储值。map可以基于键快速检索数据。键就像索引一样,指向与该键关联的值
基本语法
var map变量名 map[keytype]valuetype
such as:var age map[string]int
var users map[string]map[string]string -->value又是一个map
- key可以是什么类型?
golang中map,的key可以是,bool、数字、string、指针、channel还可以是包含前面几个类型的接口、结构体、数组
通常key为int、string
注意:slice、map还有function不可以,因为这几个没法用==来判断
map声明之后是不会分配内存的,初始化需要make,分配内存后才能赋值和使用
-
value type的类型选择和key基本一致
通常为:数字(整型、浮点数)、string、map、struct
func main() {
//map的声明和注意事项
var a map[string]string
//在使用map前需要make,给map分配内存空间
a = make(map[string]string, 10)
a["no1"] = "刘备"
a["no2"] = "张飞"
a["no1"] = "曹操"
a["no3"] = "关羽"
fmt.Println(a)
}
对上面代码的说明:
- map在使用前一定要make
- map的key是不能重复的,如果重复了,则以最后这个key-value为准
- map的value是可以相同的
- map的key-value是无序的,无序的原因是map的实现使用了散列表
- make内置函数树目
func make
func make(Type, size IntegerType) Type
内建函数make分配并初始化一个类型为切片、映射、或通道的对象。其第一个实参为类型,而非值。make的返回类型与其参数相同,而非指向它的指针。其具体结果取决于具体的类型:
切片:size指定了其长度。该切片的容量等于其长度。切片支持第二个整数实参可用来指定不同的容量;
它必须不小于其长度,因此 make([]int, 0, 10) 会分配一个长度为0,容量为10的切片。
映射:初始分配的创建取决于size,但产生的映射长度为0。size可以省略,这种情况下就会分配一个
小的起始大小。
通道:通道的缓存根据指定的缓存容量初始化。若 size为零或被省略,该信道即为无缓存的。
map的使用方式:
一:先声明、再make、再赋值
二:声明就直接make
三:声明直接赋值
//第一种使用方式:先声明、再make、再赋值
//map的声明和注意事项
var a map[string]string
//在使用map前需要make,给map分配内存空间
a = make(map[string]string, 10)
a["no1"] = "刘备"
a["no2"] = "张飞"
a["no1"] = "曹操"
a["no3"] = "关羽"
fmt.Println(a)
//第二种方式:声明就直接make,再赋值
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "上海"
cities["no3"] = "新乡"
cities["no4"] = "南阳"
fmt.Println(cities)
//第三种方式:声明直接赋值
heroes := map[string]string{
"hero1": "宋江",
"hero2": "李逵",
}
heroes["hero3"] = "林冲"
fmt.Println(heroes)
实例:
//存放3个学生信息,每个学生有名字和性别
stus := make(map[string]map[string]string)
stus["stu01"] = make(map[string]string, 3)
stus["stu01"]["name"] = "tom"
stus["stu01"]["sex"] = "男"
stus["stu01"]["address"] = "河南郑州"
stus["stu02"] = make(map[string]string, 3)
stus["stu02"]["name"] = "mary"
stus["stu02"]["sex"] = "女"
stus["stu02"]["address"] = "河南新乡"
fmt.Println(stus)
map常见操作
map增加和更新:
- map[“key”] = value//如果key还没有,就是增加,如果key存在就是修改
map删除:
- delete(map,“key”),delete是一个内置函数,如果key存在,就删除该key-value,如果不存在,不操作,但是也不会报错
func delete(m map[Type]Type1, key Type)
内建函数delete按照指定的键将元素从映射中删除。若m为nil或无此元素,delete不进行操作。
细节说明:如果我们要删除map中所有的key,没有一个专门的方法一次删除,可以遍历一下key,逐个删除 或者map = make(…),make一个新的,让原来的成为垃圾,被GC回收
stus = make(map[string]map[string]string)
map查找
说明:如果stus这个map中存在"stu02",那么findRes就会返回true,否则返回false
val, findRes := stus["stu02"]
if findRes {
fmt.Println("找到了,val=", val)
} else {
fmt.Println("没有stu02这个key")
}
//找到了,val= map[address:上海浦东 name:mary sex:女]
map遍历
map遍历使用for-range
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "上海"
cities["no3"] = "天津"
cities["no4"] = "南阳"
fmt.Println(cities)
for k,v := range cities {
fmt.Printf("k=%v v=%v",k,v)
}
stus := make(map[string]map[string]string)
stus["stu01"] = make(map[string]string, 3)
stus["stu01"]["name"] = "tom"
stus["stu01"]["sex"] = "男"
stus["stu01"]["address"] = "河南郑州"
stus["stu02"] = make(map[string]string, 3)
stus["stu02"]["name"] = "mary"
stus["stu02"]["sex"] = "女"
stus["stu02"]["address"] = "上海浦东"
for k1,v1 := range stus{
fmt.Println("k1=",k1)
for k2,v2 := range v1{
fmt.Printf("\tk2=%v v2=%v",k2,v2)
}
fmt.Println()
}
map长度
len(keyType)
func len(v Type) int
内建函数len返回 v 的长度,这取决于具体类型:
数组:v中元素的数量
数组指针:*v中元素的数量(v为nil时panic)
切片、映射:v中元素的数量;若v为nil,len(v)即为零
字符串:v中字节的数量
通道:通道缓存中队列(未读取)元素的数量;若v为 nil,len(v)即为零
map切片
切片的数据类型如果是map,则我们称之为slice of map,这样使用则map个数就可以动态变化了
func main() {
//案例:使用一个map来记录monster的信息name和age,并且妖怪的个数可以动态增加
var monsters []map[string]string
monsters = make([]map[string]string, 2) //准备放入两个妖怪,make切片
if monsters[0] == nil {
monsters[0] = make(map[string]string, 2) //make的是map
monsters[0]["name"] = "牛魔王"
monsters[0]["age"] = "100"
}
if monsters[1] == nil {
monsters[1] = make(map[string]string, 2)
monsters[1]["name"] = "红孩儿"
monsters[1]["age"] = "20"
}
//下面写法是错误的
/*if monsters[2] == nil { //panic: runtime error: index out of range [2] with length 2
monsters[2] = make(map[string]string, 2)
monsters[2]["name"] = "玉兔"
monsters[2]["age"] = "18"
}*/
//这里我们要使用到切片的append函数,可以动态增加monster
//1.先定义个monster学习
newMonster := map[string]string{
"name": "玉兔",
"age": "18",
}
monsters = append(monsters, newMonster)
fmt.Println(monsters)
}
map排序
1.golang中没有一个专门的方法对map进行排序
2.golang中的map默认是无序的,不是按照添加的顺序存放的
3.golang中的排序,是先将key进行排序,然后根据key值遍历输出
func main() {
map1 := make(map[int]int)
map1[10] = 100
map1[2] = 44
map1[4] = 66
map1[6] = 88
map1[3] = 99
//1.先将map的key放入切片中
var keys []int
for k, _ := range map1 {
keys = append(keys, k)
}
//2.对keys切片排序
sort.Ints(keys)
fmt.Println(keys)
//3.按照key递增输出map1
for _, k := range keys {
fmt.Printf("map1[%v]=%v\n", k, map1[k])
}
}
map的使用细节
-
map是引用类型,遵守引用类型传递机制,在一个函数接受到map,修改后会直接修改原来的map
func modify(map1 map[int]int) { map1[10] = 666 } func main() { map1 := make(map[int]int) map1[10] = 100 map1[2] = 44 map1[4] = 66 map1[6] = 88 map1[3] = 99 modify(map1) fmt.Printn(mp1) } -
map的容量达到后,再增给map增加元素,会自动扩容,并不会发生panic,也就是说map能动态的增长键值对(key-value)
-
map的value也经常使用struct类型,更适合管理复杂的数据(比前面value是一个map更好),比如value为Student结构体
type Stu struct { Name string Age int Address string } func main() { students := make(map[string]Stu, 10) stu1 := Stu{"tom", 20, "上海浦东"} stu2 := Stu{"marry", 18, "北京"} students["no1"] = stu1 students["no2"] = stu2 fmt.Println(students) //遍历学生 for k, v := range students { fmt.Printf("学生的编号是%v\n", k) fmt.Printf("学生的名字是%v\n", v.Name) fmt.Printf("学生的年龄是%v\n", v.Age) fmt.Printf("学生的住址是%v\n", v.Address) fmt.Println() } }
03、go流程控制
3.1、条件语句
if判断、if-else判断、else if判断
初始话子语句:if语句可以有一个子语句,用于初始化局部变量。另外由于a的值是在if代码块中定义的,所以不能再代码块之外调用。
func main(){
if a := 10; a < 20 {
fmt.Printf("a小于10")
}else{
fmt.Printf("a的值是:%d\n",a)
}
}
//注意else不能换行
//else if中else不是必须的
3.2、选择语句
- switch语句(表达式switch、类型switch),switch语句同样拥有初始化语句,写在switch关键字后面,只能有一句
- select语句,这种语句用于配合通道(channel)的读写操作,用于多个channel的并发读写操作
switch使用注意事项和细节:
- case/switch后是一个表达式(即:常量值、变量、一个有返回值的函数都可以)
- case后的各个表达式的值的数据类型,必须和switch的表达式数据类型一致
- case后面可以带多个表达式,使用逗号间隔
- case后面的表达式如果是常量值(字面量),则要求不能重复
- case后面不需要带break,程序匹配到一个case后就会执行对应的代码块,然后退出switch,如果一个都匹配不到,则执行default
- default语句不是必须的。(都没匹配到就算了)
- switch后也可以不带表达式,类似于if-else分支来使用
- switch后面也可以直接声明/定义一个变量,分号结束。不推荐
- switch穿透-fallthrough,如果在case语句块后面增加fallhrough,则会继续执行下一个case,也叫switch穿透
var num int = 10
switch num {
case 10:
fmt.Printf("ok1")
fallthrough //默认只能穿透一层,case 20不用判断直接执行
case 20:
fmt.Printf("ok2")
case 30:
fmt.Printf("ok3")
default:
fmt.Printf("没有匹配到")
}
输出:
ok1
ok2
- Type Switch:switch语句还可以被用于type-switch来判断某个interface变量中实际指向的变量类型
package main
import "fmt"
func main(){
grade := "E"
marks := 90
//1、表达式switch
//类似于别的语言中的写法
//一般不这样写,不容易扩展选择语句,分数是100,91也会返回D
switch marks {
case 90 :
grade = "A"
case 80 :
grade = "B"
case 60,70 :
grade = "C"
default:
grade = "D"
}
fmt.Printf("你的成绩为:%s\n",grade)
//完整的switch表达式写法
switch { //switch后面不带表达式
case marks >= 90 :
grade = "A"
case marks >= 80 :
grade = "B"
case marks >= 70:
grade = "C"
case marks >= 60:
grade = "D"
default:
grade = "E"
}
switch { //switch后面不带表达式,switch不带default
case grade == "A":
fmt.Printf("成绩优秀!\n")
case grade == "B":
fmt.Printf("表现良好!\n")
case grade == "C",grade == "D":
fmt.Printf("再接再厉!\n")
case grade == "A":
fmt.Printf("成绩不合格!\n")
}
fmt.Printf("你的成绩为%s\n",grade)
}
package main
import "fmt"
var x interface{}//空接口
func main(){
x = 1 //修改x的值,查看返回结果的变化
switch i := x.(type){ //这里表达式只有一句初始化子语句
case nil:
fmt.Printf("这里是nil,x的类型是%T",i)
case int:
fmt.Printf("这里是int,x的类型是%T",i)
case float64:
fmt.Printf("这里是float64,x的类型是%T",i)
case bool:
fmt.Printf("这里是bool,x的类型是%T",i)
case string:
fmt.Printf("这里是string,x的类型是%T",i)
default:
fmt.Printf("未知类型")
}
}
3.3、循环语句
在go语言中循环语句的关键字是for,没有while关键字。for语句后面的三个子语句:初始化子语句、条件子语句、后置子语句。(顺序不能颠倒,其中条件子语句是必须的,条件子语句会返回一个bool值,true则执行代码块,false则跳出循环。
-> range子语句,每一个for语句都可以使用一个特殊的range子语句,其作用类似于迭代器,用于查询数组或切片值中的每一元素,也可以用于轮询字符串的每一个字符,数组,切片,以及字典值中的每个键值对,甚至可以读取一个通道类型值中的元素
for循环使用注意和细节:
-
循环条件是返回一个布尔值的表达式
-
for循环的第二种使用方式
for 循环判断条件 { //循环执行语句 } //将变量初始化和变量迭代写到其他位置 eg: j := 1 for j <= 10{ fmt.Printf("你好,",j) j++ } -
for循环的第三种使用方式
for { //循环执行语句 } eg: k := 1 for { if k <= 10 { fmt.Println("ok",k) }else{ break //break就是跳出这个for循环 } k++ } -
Golang提供for-range的方式,可以方便遍历字符串和数组
对于for-range遍历方式而言,是按照字符方式遍历。因此如果字符串有中文,也是ok的
//字符串遍历方式一:传统方式 var str string = "hello,world" for i := 0;i < len(str); i++ { fmt.Printf("%c \n",str[i]) } //字符串遍历方式二:for - range str = "abc~ok" for index,val := range str{ fmt.Printf("index=%d,val=%c \n",index,val) } /* //上面代码这样写便于理解range子句,但这样降低了代码可读性,也不容易管理后续的循环代码块 for index,val := range "abc~ok"{ fmt.Printf("index=%d,val=%c \n",index,val) } */ for _,char := range str { //忽略第一个值,忽略index fmt.Println(char) } for index := range str { //忽略第二个值 fmt.Println(index) } for range str { //忽略全部返回值,只执行下面代码 fmt.Println("执行成功") }两种遍历字符串方式的细节讨论:
如果字符串中含有中文,那么传统的遍历字符串的方式,就是错误,会出现乱码。原因是传统的对字符串的遍历是按照字节来遍历,而一个汉字在utf-8编码对应的是3个字节。
如何解决:
var str string = "hello,北京" str2 := []rune(str) //就是把str 转换成 []rune for i := 0; i < len(str2); i++ { fmt.Printf("%c ", str2[i]) } -
range 子句
range关键字的左边表示的是一对索引-值对,根据不同的表达式返回不同的结果
range返回值的输出如下表:
右边表达式返回的类型 第一值 第二个值 string index str[index],返回类型为rune array/slice index str[index] map key m[key] channel element -
用for实现while
for { if 循环条件表达式{ break } 循环操作 循环变量迭代 } -
用for实现do…while
for { 循环操作 循环变量迭代 if 循环条件表达式{ break } }
3.4、标签、跳转语句
标签可以给for、switch、select等流程控制代码块打上一个标签,配合标签标识符可以方便跳转到某一个地方继续执行,有助于提高编程效率。建议标签名用大写字母和数字。标签可以标记任何语句,并不限定于流程控制语句,未使用的标签会引发错误
1、break语句
break语句用于终止某个语句块的执行,用于中断当前for循环或跳出switch语句。
break使用注意事项和细节
-
break出现在多层嵌套的语句块中时,可以通过标签指明要终止的是哪一层语句块
lable2: for i := 0; i < 4; i++ { //lable1: for j := 0; j < 10; j++ { if j == 2 { //break 默认会跳出最近的for循环 //break lable1 //和不写lable1效果是一样的 break lable2 //执行到这直接退出两层for循环 } fmt.Println("j=", j) } } break 默认会跳出最近的for循环 break 后面可以指定标签,跳出标签对应的for循环
2、continue语句
continue语句是结束本次循环,继续执行下一次循环
continue语句出现在多层嵌套循环语句体中时,可以通过标签指明要跳过的是哪一层循环,这个和前面的break标签的使用是一样的
lable2:
for i := 0; i < 4; i++ {
//lable1:
for j := 0; j < 10; j++ {
if j == 2 {
continue //输出四次,每次都没有j=2,
}
fmt.Println("j=", j)
}
}
3、goto语句
goto语句可以无条件跳转到相同函数中带标签的语句。
goto语句通常与条件语句配合使用,可以实现条件转移,跳出循环体等
在go程序设计中一般不主张使用goto,以免造成程序流程的混乱,使理解和调试程序都产生困难
4、return
return使用在方法或函数中,表示跳出所在的方法或函数
- 如果return在普通函数中,表示跳出该函数,即不再执行函数中return后面的代码。也可以理解为终止函数。
- 如果return是在main函数中,表示终止main函数,也就是终止程序。
3.5、延迟语句
defer用于延迟调用指定函数,defer只能出现在函数内部。
因为defer的延迟特点,可以用于回收资源,清理收尾等工作。使用defer语句之后,不用纠结代码放在哪里,反正都是最后执行
在函数中,程序员经常需要创建资源(比如数据库连接、文件句柄、锁等),为了在函数执行完后,及时的释放资源,可以使用defer延时机制
defer使用注意和细节:
-
defer后面的表达式必须是 外部函数的调用
-
只有当defer语句全部执行,defer所在函数才算真正结束执行
-
当函数中有defer语句时,需要等待所有defer语句执行完毕,才会执行return语句
-
一个函数内部出现多个defer语句时,最后面的defer语句最先执行。(defer其实就是一个栈,遵循后进先出)
var i int = 0 func print(i int) { fmt.Printf("%d,", i) } func main() { //defer fmt.Printf("world") //fmt.Printf("hello ") //输出:5,5,5,5,5, for ; i < 5; i++ { defer print(i) } } //输出: 4,3,2,1,0, -
在defer将语句放入到栈时,也会将相关值拷贝同时入栈
func sum (n1 int, n2 int) int { defer fmt.Println("ok1 n1=",n1) //ok1 n1=10 defer fmt.Println("ok2 n2=",n2) //ok2 n2=20 n1++ //n1=11 n2++ //n2=21 res := n1 + n2 //32 fmt.Println("ok3 res=",res) return res } func main(){ res := sum(10,20) fmt.Println("res=",res) } 输出结果: ok3 res= 32 ok2 n2= 20 ok1 n1= 10 res= 32 -
因为defer的延迟特点,可以用于回收资源,清理收尾等工作。使用defer语句之后,不用纠结代码放在哪里,反正都是最后执行
- 在golang编程中常用做法是,在创建资源后,比如打开了文件,获取数据库的链接,或则是锁资源,可以在后面加上defer file.Close() defer connect.Close()
- 在defer后,可以继续使用创建资源
- 当函数执行完毕后,系统会依次从defer栈中,取出语句,关闭资源
04、函数
4.1、基本概念
为完成某一功能的指令(语句)的集合,称为函数。Golang中所有函数都以func开头
在go中,函数分为:自定义函数、系统函数
程序中引入函数可以:减少代码的冗余、有利于维护代码
func 函数名 (形参列表)(返回值列表){
执行语句...
return 返回值列表
}
1.形参列表:表示函数的输入
2.函数中的语句:表示为了实现某一功能的代码块
3.函数可以有返回值,也可以没有
函数的使用注意和说明:
-
Go语言函数不支持嵌套、重载、和默认参数
-
函数名称首字母大写可以被其他包调用,小写不行
-
go语言支持返回多个值,这一点是其他语言没有的
func 函数名 (形参列表) (返回值类型列表){ 语句.. return 返回值列表 } 1.如果返回多个值时,在接受时,希望忽略掉某个值时,则使用_符号占位忽略 2.如果返回值只有一个,(返回值列表)可以不写() -
函数中的变量是局部的,函数外不生效
-
基本数据类型和数组默认都是值传递的,即进行值拷贝,在函数内部修改不会影响到原来的值
-
如果希望函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以指针的方式操作变量
-
go语言不支持函数重载
-
在go中函数也是一种数据类型,可以赋值给一个变量,该变量就是一个函数类型的变量了,通过该变量可以实现对函数的调用
func getSum(n1 int,n2 int) int { return n1 + n2 } func main() { a := getSum fmt.Printf("type a is:%T,type getSum() is:%T\n", a, getSum) //func (int, int) int fmt.Println("10 + 20 =", getSum(10, 20)) //10 + 20 = 30 } -
函数既然是一种数据类型,因此在go中函数可以作为形参,并且调用
func getSum(n int, m int) int { return n + m } func getSub(n int, m int) int { return n - m } func myFun(funvar func(int, int) int, num1 int, num2 int) int { return funvar(num1, num2) } func main() { var i int = 10 var j int = 10 f1 := getSum f2 := getSub fmt.Println("求和,和为:", f1(i, j)) fmt.Printf("%T\n", f1) fmt.Println("求差,差为:", f2(i, j)) fmt.Printf("%T\n", f2) fmt.Println(myFun(f1, 100, 44)) fmt.Println(myFun(f2, 100, 44)) fmt.Println(myFun(getSum, 100, 44)) fmt.Println(myFun(getSub, 100, 44)) } -
为了简化数据类型定义,go支持自定义数据类型(相当于起一个别名)
- 基本语法:type 自定义数据类型名 数据类型
-
支持对函数返回值命名
func getSumAndSub(n1 int, n2 int) (sum int, sub int){ sub = n1 - n2 sum = n1 + n2 //return 后面可以不再写返回值 return } func main(){ a1, b1 := getSumAndSub(3,4) fmt.Printf("a1=%v,b1=%v",a1,b1) //a1=7,b1=-1 } -
使用_标识符,忽略返回值
-
go 通过切片实现支持可变参数
- args是slice切片,通过args[index]可以访问到各个值
- 如果一个函数的形参列表中有可变参数,则可变参数需要放在形参列表最后
//支持0到多个参数 func sum(args... int) int{ } //支持1到多个参数 func sum (n1 int,args... int) int { }func sum(n1 int, args ...int) int { sum := n1 for i := 0; i < len(args); i++ { sum += args[i] } return sum } func main(){ res4 := sum(10, 10, 10, 10, 10, 10) fmt.Println(res4) }
4.2、内置函数
golang设置者为了变成方便,提供了一些函数,这些函数可以直接使用,称之为内置函数(内建函数)
-
len:用于求长度,比如string、array、slice、map、channel
func len(v Type) int 内建函数len返回 v 的长度,这取决于具体类型: 数组:v中元素的数量 数组指针:*v中元素的数量(v为nil时panic) 切片、映射:v中元素的数量;若v为nil,len(v)即为零 字符串:v中字节的数量,注意一个汉字占三个字节 通道:通道缓存中队列(未读取)元素的数量;若v为 nil,len(v)即为零 -
new:用来分配内存,主要用来分配值类型,比如int、float32,struct…返回的是 指针
func new(Type) *Type 内建函数new分配内存。其第一个实参为类型,而非值。其返回值为指向该类型的新分配的零值的指针 num := new(int) fmt.Printf("num的类型%T,num的值%v,num的地址%v,num指向的值是%v\n", num, num, &num,*num) //num的类型*int,num的值0xc000018030,num的地址0xc000006058,num指向的值是0 -
make:用来分配内存,主要用来分配引用类型,比如chan、map、slice
func make(Type, size IntegerType) Type
内建函数make分配并初始化一个类型为切片、映射、或通道的对象。其第一个实参为类型,而非值。make的返回类型与其参数相同,而非指向它的指针。其具体结果取决于具体的类型:
切片:size指定了其长度。该切片的容量等于其长度。切片支持第二个整数实参可用来指定不同的容量;
它必须不小于其长度,因此 make([]int, 0, 10) 会分配一个长度为0,容量为10的切片。(cap 10是可选项)
映射:初始分配的创建取决于size,但产生的映射长度为0。size可以省略,这种情况下就会分配一个
小的起始大小。
通道:通道的缓存根据指定的缓存容量初始化。若 size为零或被省略,该信道即为无缓存的。
| 内置函数 | 介绍 |
|---|---|
| close | 主要用来关闭channel |
| len | 用来求长度,比如string、array、slice、map、channel |
| new | 用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针 |
| make | 用来分配内存,主要用来分配引用类型,比如chan、map、slice |
| append | 用来追加元素到数组、slice中 |
| panic和recover | 用来做错误处理 |
4.3、init函数
每一个源文件都可以包含一个init函数,该函数会在main函数执行前,被Go运行框架调用,也就是说init函数会在main函数前被调用
这种特殊的函数不接收任何参数也没有任何返回值,我们也不能在代码中主动调用它。当程序启动的时候,init函数会按照它们声明的顺序自动执行。
-
如果一个文件中同时包含全局变量、init函数、main函数
- 执行顺序是 全局变量定义 -> init函数 -> main函数
-
如果main.go引入utils.go,两者都含有变量定义,init函数,执行的顺序是?
utils中全局变量定义 -> utils中init函数 -> main中全局变量的定义 -> main中init函数 -> main函数package main import "fmt" var age = test() //为了看到全局变量定义是先被初始化的,这里写个test函数 func test() int{ fmt.Println("test()") return 66 } //init函数,通常可以在init函数中完成初始化工作 func init(){ fmt.Println("init()") } func main(){ fmt.Println("main()") } 执行结果 test() init() main() -
一个包的初始化过程是按照代码中引入的顺序来进行的,所有在该包中声明的
init函数都将被串行调用并且仅调用执行一次。每一个包初始化的时候都是先执行依赖的包中声明的init函数再执行当前包中声明的init函数。确保在程序的main函数开始执行时所有的依赖包都已初始化完成。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GPgi0SbR-1668236508370)(https://gitee.com/lazyperson/typora-drawing-bed-01/raw/master/Image/202205082330804.png)]
4.4、匿名函数
go支持匿名函数,匿名函数就是没有名字的函数,如果我们某个函数只是希望调用一次,可以考虑使用匿名函数,匿名函数也可以实现多次调用
- 在定义匿名函数时就直接调用,这种方式匿名函数只能调用一次
func main(){
res := func(n1 int, n2 int) int {
return n1 + n2
}(10,20)
}
- 将匿名函数赋给一个变量(函数变量),再通过该变量来调用匿名函数
a := func(n1 int, n2 int) int {
return n1 + n2
}
res1 := a(10,20)
res2 := a(20,30)
- 如果将匿名函数赋给一个全局变量,那么这个匿名函数,就成为一个全局匿名函数,可以在程序有效
4.5、闭包
闭包就是一个函数和其相关的引用环境组合的一个整体(实体),闭包实质返回了一个函数
一个闭包继承了函数声明时的作用域。这种状态(作用域内的变量)会共享到闭包的环境中,因此这些变量可以在闭包中被操作,直到被销毁。
闭包经常被用作包装函数,预先定义好一个或多个参数以用于包装,另一种常见的应用就是使用闭包来完成更加简洁的错误检查
package main
import "fmt"
//累加器
func addUpper() func(int) int {
var n int = 10
var str = "hello"
return func(x int) int {
n = n + x
str += "a"
fmt.Println("str=", str)
return n
}
}
func main() {
f := addUpper()
fmt.Println(f(1))
fmt.Println(f(5))
fmt.Println(f(10))
fmt.Println(f(40))
}
输出结果:
str= helloa
11
str= helloaa
16
str= helloaaa
26
str= helloaaaa
66
对上面函数的说明
1.AddUpper()是一个函数,返回的数据类型是fun(int)int
2.闭包的说明:
var n int = 10
return func(x int) int {
n = n + x
return n
}
这个就是一个闭包。返回的是一个匿名函数,但是这个匿名函数引用到函数外面的n,因此这个匿名函数和n就形成了一个整体,构成闭包。
3.这样理解:闭包是类,n是属性,函数是方法。函数和它使用到的变量就构成闭包
4.我们反复调用AddUpper函数时,n只初始化一次,
fmt.Println(addUpper()(1))
fmt.Println(addUpper()(55))
fmt.Println(addUpper()(5))
这样写输出的结果是:11 65 15
5.搞清闭包的关键就是要分析出返回的函数它使用到哪些变量,因为函数和它引用的变量构成闭包。
关于闭包的实践:
编写一个makeSuffix函数,其可以接收一个文件后缀名(比如.jpg),并返回一个闭包。调用闭包,可以传入一个文件名,如果该文件名没有指定的后缀(比如.jpg),则返回文件名.jpg,如果已经有后缀(比如.jpg),则返回原文件名
引用知识点:func HasSuffix(s, suffix string) bool,该函数可以判断某个字符串是否有指定的后缀
func makeSuffix(suffix string) func(string) string {
return func(name string) string {
if !strings.HasSuffix(name, suffix) {
//如果name没有指定后缀,则加上,否则就返回原来的名字
return name + suffix
}
return name
}
}
func main() {
f := makeSuffix(".jpg")
fmt.Println("文件处理后=", f("winter"))
fmt.Println("文件处理后=", f("summer.jpg"))
}
1.返回的匿名函数和makeSuffix(suffix string)的suffix变量组合成一个闭包 返回的函数引用到suffix这个变量

4.6、函数值传递机制
值传递和引用传递
其实不管是值传递还是引用传递,传递给函数的都是变量的副本。值传递的是值的拷贝,引用传递是地址的拷贝。一般来说地址拷贝效率高,因为数据量小
- 值类型:基本数据类型 int系列、float系列、bool、string、数组和结构体struct
- 引用类型:指针、slice切片、map、管道chan、interface等
4.7、字符串常用函数
函数的调用:包名.函数名(参数)
len(str),strconv.Atoi(s string),strconv.Itoa(i int),
package strconv
-
统计字符串的长度,按字节len(str)。 内建函数,不需要引包
func len(v Type) int 内建函数len返回 v 的长度,这取决于具体类型: 数组:v中元素的数量 数组指针:*v中元素的数量(v为nil时panic) 切片、映射:v中元素的数量;若v为nil,len(v)即为零 字符串:v中字节的数量 //ASCII的字符占一个字节,汉字占3个字节 通道:通道缓存中队列(未读取)元素的数量;若v为 nil,len(v)即为零 -
字符串遍历,同时处理有中文的问题 r := []rune(str)
当然字符串的遍历可以使用for-range,其不必转切片
str := "hello北京" fmt.Println("str len=",len(str)) //11 str2 := []rune(str) for i := 0; i <len(str2); i++ { fmt.Printf("字符=%c ",str2[i]) } -
字符串转整数:strconv包中Atoi函数
func Atoi(s string) (i int, err error) Atoi是ParseInt(s, 10, 0)的简写。str := "hello" n,err := strconv.Atoi(str) if err != nil { fmt.Println("转换错误",err) }else { fmt.Println("转换的结果是",n) } -
整数转字符串:strconv 中Itoa函数
func Itoa(i int) string Itoa是FormatInt(i, 10) 的简写。 -
字符串转[]byte : var bytes = []byte(“hello,go”)
var bytes = []byte("hello,go") fmt.Printf("bytes=%v\n",bytes) //输出:bytes=[104 101 108 108 111 44 103 111] -
[]byte 转 字符串:str = string([]byte{97,98,99})
str = string([]byte{97,98,99}) -
10进制转换成2,8,16进程: str = strconv.FormatInt(133,2)
func FormatInt(i int64, base int) string 返回i的base进制的字符串表示。base 必须在2到36之间,结果中会使用小写字母'a'到'z'表示大于10的数字。
package strings
-
查找子串是否在指定的字符串中:
func Contains(s, substr string) bool 判断字符串s是否包含子串substr。 -
统计一个字符串中有几个指定的子串
func Count(s, sep string) int 返回字符串s中有几个不重复的sep子串。 -
不区分大小写的字符串比较(==是区分大小写的)
func EqualFold(s, t string) bool 判断两个utf-8编码字符串(将unicode大写、小写、标题三种格式字符视为相同)是否相同。 -
返回字串在字符串中第一次出现的index值,如果没有返回-1
func Index(s, sep string) int 子串sep在字符串s中第一次出现的位置,不存在则返回-1。 -
返回子串最后一次出现的index,如果没有返回-1
func LastIndex(s, sep string) int 子串sep在字符串s中最后一次出现的位置,不存在则返回-1。 -
将指定的子串替换成另一个子串:strings.Replace(“go go hello”,“go”,“go语言”,n) n可以指定替换几个,如果n=-1,表示全部替换
func Replace(s, old, new string, n int) string 返回将s中前n个不重叠old子串都替换为new的新字符串,如果n<0会替换所有old子串。 -
按照指定的某个字符,为分割标识,将一个字符串拆分成字符串数组:strings包下面
func Split(s, sep string) []string 用去掉s中出现的sep的方式进行分割,会分割到结尾,并返回生成的所有片段组成的切片(每一个sep都会进行一次切割,即使两个sep相邻,也会进行两次切割)。如果sep为空字符,Split会将s切分成每一个unicode码值一个字符串。strArr := strings.Split("hello,wrold,ok", ",") for i := 0; i < len(strArr); i++ { fmt.Printf("str[%v]=%v\n", i, strArr[i]) } fmt.Printf("strArr=%v\n", strArr) 输出结果是: str[0]=hello str[1]=wrold str[2]=ok strArr=[hello wrold ok] -
将字符串的字母进行大小写转换
func ToLower(s string) string 返回将所有字母都转为对应的小写版本的拷贝。 func ToUpper(s string) string 返回将所有字母都转为对应的大写版本的拷贝。 -
将字符串左右两边的空格去掉
func TrimSpace(s string) string 返回将s前后端所有空白(unicode.IsSpace指定)都去掉的字符串。 -
将字符串左右两边指定的字符去掉
func Trim(s string, cutset string) string 返回将s前后端所有cutset包含的utf-8码值都去掉的字符串。 -
将字符串左边指定的字符去掉
func TrimLeft(s string, cutset string) string 返回将s前端所有cutset包含的utf-8码值都去掉的字符串。 -
将字符串右边指定的字符去掉
func TrimRight(s string, cutset string) string 返回将s后端所有cutset包含的utf-8码值都去掉的字符串。 -
判断字符串是否以指定的字符串开头
func HasPrefix(s, prefix string) bool 判断s是否有前缀字符串prefix。 -
判断字符串是否以指定的字符串结束
func HasSuffix(s, suffix string) bool 判断s是否有后缀字符串suffix。
4.8、时间和日期相关函数
在编程时经常会用到日期相关的函数,比如:统计某段代码执行花费的时间等
-
日期和时间相关函数,需要导入time包
-
time.Time类型,用于表示时间
now := time.Now() fmt.Printf("now=%v type=%T\n",now,now) //输出结果是:now=2022-04-02 21:20:23.5149432 +0800 CST m=+0.004880201 type=time.Time fmt.Printf("年=%v\n", now.Year()) fmt.Printf("月=%v\n", now.Month()) fmt.Printf("月=%v\n", int(now.Month())) fmt.Printf("日=%v\n", now.Day()) fmt.Printf("时=%v\n", now.Hour()) fmt.Printf("分=%v\n", now.Minute()) fmt.Printf("秒=%v\n", now.Second()) 输出结果是: 年=2022 月=October 月=10 日=15 时=20 分=41 秒=36 -
格式化日期
- 方式一:使用Printf 或者 Sprintf
fmt.Printf("当前年月日 %d-%d-%d %d:%d:%d\n",now.Year(),now.Month(),now.Day(),now.Hour(),now.Minute(),now.Second) dateStr := fmt.Sprintf("当前年月日 %d-%d-%d %d:%d:%d\n",now.Year(),now.Month(),now.Day(),now.Hour(),now.Minute(),now.Second) fmt.Printf("dateStr=%v\n",dateStr)- 方式二:使用time.Format()方法完成
func (t Time) Format(layout string) string Format根据layout指定的格式返回t代表的时间点的格式化文本表示。layout定义了参考时间: Mon Jan 2 15:04:05 -0700 MST 2006 格式化后的字符串表示,它作为期望输出的例子。同样的格式规则会被用于格式化时间。 预定义的ANSIC、UnixDate、RFC3339和其他版式描述了参考时间的标准或便捷表示。要获得更多参考时间的定义和格式,参见本包的ANSIC和其他版式常量。fmt.Printf(now.Format("2006-01-02 15:04:05")) fmt.Println() fmt.Printf(now.Format("2006-01-02")) fmt.Println() fmt.Printf(now.Format("15:04:05")) fmt.Println() 输出: 2022-04-03 11:12:52 2022-04-03 11:12:52 说明; "2006/01/02 15:04:05" 这个字符串各个数字时固定的,必须这样写 -
时间的常量
在程序中可以用于获取指定时间单位的时间爱你,比如想得到100毫秒 :100 * time.Millisecond
type Duration int64 Duration类型代表两个时间点之间经过的时间,以纳秒为单位。可表示的最长时间段大约290年。 const ( Nanosecond Duration = 1 //纳秒 Microsecond = 1000 * Nanosecond //微妙 Millisecond = 1000 * Microsecond //毫秒 Second = 1000 * Millisecond //秒 Minute = 60 * Second //分钟 Hour = 60 * Minute //小时 ) //毫秒、微妙、纳秒之间进制是1000 -
time.Sleep休眠
//每隔1秒输出1个数字 i := 0 for { i++ fmt.Println(i) time.Sleep(time.Second) if i == 10 { break } } -
time的Unix和UnixNano的方法
func (Time) Unix func (t Time) Unix() int64 Unix将t表示为Unix时间,即从时间点January 1, 1970 UTC到时间点t所经过的时间(单位秒)。 func (Time) UnixNano func (t Time) UnixNano() int64 UnixNano将t表示为Unix时间,即从时间点January 1, 1970 UTC到时间点t所经过的时间(单位纳秒)。如果纳秒为单位的unix时间超出了int64能表示的范围,结果是未定义的。注意这就意味着Time零值调用UnixNano方法的话,结果是未定义的。 -
日期和时间函数:统计代码执行时间
func test() {
str := ""
for i := 0; i < 100000; i++ {
str += "hello" + strconv.Itoa(i)
}
}
func main() {
start := time.Now().Unix()
test()
end := time.Now().Unix()
fmt.Printf("执行test()好费时间:%v\n", end-start)
}
4.9、生成随机数
在go语言中,生成随机数需要先添加一个随机数种子,否则每次运行生成的随机数都是同样顺序的数字
1、func (*Rand) Intn 方法
func (r *Rand) Intn(n int) int
返回一个取值范围在[0,n)的伪随机int值,如果n<=0会panic
2、func Seed
func Seed(seed int64)
使用给定的seed将默认资源初始化到一个确定的状态;如未调用Seed,默认资源的行为就好像调用了Seed(1)。
func main() {
rand.Seed(time.Now().UnixMilli())
for i := 0; i < 10; i++ {
fmt.Println(rand.Intn(100))
}
}
4.10、错误处理
- 在默认情况下,当发生错误后(panic),程序就会退出(崩溃)
- 如果我们希望发生错误后,可以捕获到错误,并进行处理,保证程序可以继续执行,还有可以给管理员一个提示(邮件,短信)
- 使用
panic/recover模式来处理错误。panic可以在任何地方引发,但recover只有在defer调用的函数中有效。 首先来看一个例子:
基本说明:
-
go追求语言简洁优雅,所以go没有采用try…catch…finally
-
go中引用的处理方式为defer、panic、recover
func panic(v interface{}) 内建函数panic停止当前Go程的正常执行。当函数F调用panic时,F的正常执行就会立刻停止。F中defer的所有函数先入后出执行后,F返回给其调用者G。G如同F一样行动,层层返回,直到该Go程中所有函数都按相反的顺序停止执行。之后,程序被终止,而错误情况会被报告,包括引发该恐慌的实参值,此终止序列称为恐慌过程。
x func recover() interface{} 内建函数recover允许程序管理恐慌过程中的Go程。在defer的函数中,执行recover调用会取回传至panic调用的错误值,恢复正常执行,停止恐慌过程。若recover在defer的函数之外被调用,它将不会停止恐慌过程序列。在此情况下,或当该Go程不在恐慌过程中时,或提供给panic的实参为nil时,recover就会返回nil。
-
这几个异常的使用场景可以这么描述:go中可以抛出一个panic异常,然后在defer中通过recover捕获这个异常,然后正常处理
func division() {
defer func() {
err := recover()
if err != nil {
fmt.Println(err)
//这里可以将错误信息发送
fmt.Println("发送错误邮件给管理员")
}
}()
a := 10
b := 0
res := a / b
fmt.Println("res=", res)
}
func main() {
division()
fmt.Printf("这里是main函数")
}
自定义错误
go语言中,也可以自定义错误,使用errors.New和panic内置函数
- errors.New(“错误说明”),会返会一个error类型的值,表示一个错误
- panic内置函数,接受一个interface{}类型的值作为参数,可以接受error类型的变量,输出错误信息,并退出程序
func readConf(name string) (err error) {
if name == "config.ini" {
//读取
return nil
} else {
//返回一个自定义错误
return errors.New("读取文件错误...")
}
}
func test01() {
err := readConf("confige.ini")
if err != nil {
//如果读取文件发生错误就输出这个错误并终止程序
panic(err)
}
fmt.Println("test01()继续执行")
}
func main() {
test01()
fmt.Println("main()函数继续执行")
}
/*文件错误的情况:
panic: 读取文件错误...
goroutine 1 [running]:
main.test01()
D:/MyCode/goWorkspace/gostudy/src/func4_2/errortest.go:36 +0x49
main.main()
D:/MyCode/goWorkspace/gostudy/src/func4_2/errortest.go:44 +0x19
*/
05、包
5.1、基本概念
包实际上是函数与数据的集合。创建不同的文件夹,来存放程序文件
在实际开发中,需要在不同的文件中,去调用其他文件定义的函数,比如:main.go中,去使用utils.go文件中的函数。
go是以包的形式来管理文件和项目目录结构的。go语言不允许导入包却又不使用
包的作用:
- 区分相同名字的函数,变量等标识符
- 当程序文件很多时,可以很好的管理项目
- 控制函数、变量等访问范围,即作用域
包的结构:
go语言编译工具对源码目录有很严格的要求,每个工作空间(workspace)必须由bin、pkg、src三个目录组成。bin目录主要是存放可执行文件;pkg目录存放编译好的库文件,主要是*.a文件;src目录主要是存放go语言的源文件。
包的源文件:
源文件头部必须一致使用package
go通过首字母大小写来判断一个对象(全局变量、全局常量、类型、结构、字段、函数、方法)确定访问权限
包的注意事项和细节说明
-
在给一个文件打包时,该包对应一个文件夹,文件的包名通常和文件所在的文件夹名是一致的,一般为小写字母
-
当一个文件要使用其他包函数或变量时,需要先引入对应的包
-
package指令在文件第一行,然后是import指令
-
在import包时,路径是从$GOPATH的src下开始,不用带src,编译器会自动从src下开始引入
-
为了让其他包的文件,可以访问到本包的函数,则该函数的首字母需要大写
-
在访问其它包函数、变量时,其语法是
包名.函数名 -
如果包名较长,Go支持给包取别名,注意:取别名之后原来的包名就不能使用了
-
在同一包下不能有相同的函数名(也不能有相同的全局变量)
package main import ( "fmt" util "go_code/chapter/fundemo/utils" ) -
如果要编译成一个可执行文件,就需要将这个包声明为main,即package main 。这就是一个语法规范,如果你写的是一个库,包名可以自定义
-
包名为
main的包是应用程序的入口包,这种包编译后会得到一个可执行文件,而编译不包含main包的源代码则不会得到可执行文件。
-
-
Golang中没有强制要求包名和目录名称一致,也就是包名和路径是两个概念。在Golang的引用中我们要填入的是源文件所在的相对路径。
通常引用的格式是:packageName.FunctionName
- import 导入的参数是路径,而非包名。
- 在习惯上将包名和路径名保持一致,但这不是强制规定
- 在代码中引用包内的成员时,使用包名而不是目录名
- 一个文件夹内,只能存在一种包名,源文件的名称也没有其他的限制
- 如果多个文件夹下有相同名字的package,它们其实是彼此无关的package
- package不局限于一个文件,可以由多个文件组成
- go引用自定义包要使用绝对路径
-
如果引入一个包的时候为其设置了一个特殊
_作为包名,那么这个包的引入方式就称为匿名引入。一个包被匿名引入的目的主要是为了加载这个包,从而使得这个包中的资源得以初始化。 被匿名引入的包中的init函数将被执行并且仅执行一遍。import _ "github.com/go-sql-driver/mysql"-
匿名引入的包与其他方式导入的包一样都会被编译到可执行文件中。
-
需要注意的是,Go语言中不允许引入包却不在代码中使用这个包的内容,如果引入了未使用的包则会触发编译错误。
-
5.2、go module
在Go语言的早期版本中,我们编写Go项目代码时所依赖的所有第三方包都需要保存在GOPATH这个目录下面。这样的依赖管理方式存在一个致命的缺陷,那就是不支持版本管理,同一个依赖包只能存在一个版本的代码。可是我们本地的多个项目完全可能分别依赖同一个第三方包的不同版本。
go module:
Go module 是 Go1.11 版本发布的依赖管理方案,从 Go1.14 版本开始推荐在生产环境使用,于Go1.16版本默认开启。Go module 提供了以下命令供我们使用:
相关命令:
| 命令 | 介绍 |
|---|---|
| go mod init | 初始化项目依赖,生成go.mod文件 |
| go mod download | 根据go.mod文件下载依赖 |
| go mod tidy | 比对项目文件中引入的依赖与go.mod进行比对 |
| go mod graph | 输出依赖关系图 |
| go mod edit | 编辑go.mod文件 |
| go mod vendor | 将项目的所有依赖导出至vendor目录 |
| go mod verify | 检验一个依赖包是否被篡改过 |
| go mod why | 解释为什么需要某个依赖 |
GOPROXY
这个环境变量主要是用于设置 Go 模块代理(Go module proxy),其作用是用于使 Go 在后续拉取模块版本时能够脱离传统的 VCS 方式,直接通过镜像站点来快速拉取。
GOPROXY 的默认值是:https://proxy.golang.org,direct,由于某些原因国内无法正常访问该地址,所以我们通常需要配置一个可访问的地址。目前社区使用比较多的有两个https://goproxy.cn和https://goproxy.io,当然如果你的公司有提供GOPROXY地址那么就直接使用。设置GOPAROXY的命令如下:
go env -w GOPROXY=https://goproxy.cn,direct
GOPROXY 允许设置多个代理地址,多个地址之间需使用英文逗号 “,” 分隔。最后的 “direct” 是一个特殊指示符,用于指示 Go 回源到源地址去抓取(比如 GitHub 等)。当配置有多个代理地址时,如果第一个代理地址返回 404 或 410 错误时,Go 会自动尝试下一个代理地址,当遇见 “direct” 时触发回源,也就是回到源地址去抓取。
GOPRIVATE
设置了GOPROXY 之后,go 命令就会从配置的代理地址拉取和校验依赖包。当我们在项目中引入了非公开的包(公司内部git仓库或 github 私有仓库等),此时便无法正常从代理拉取到这些非公开的依赖包,这个时候就需要配置 GOPRIVATE 环境变量。GOPRIVATE用来告诉 go 命令哪些仓库属于私有仓库,不必通过代理服务器拉取和校验。
GOPRIVATE 的值也可以设置多个,多个地址之间使用英文逗号 “,” 分隔。我们通常会把自己公司内部的代码仓库设置到 GOPRIVATE 中,例如:
$ go env -w GOPRIVATE="git.mycompany.com"
这样在拉取以git.mycompany.com为路径前缀的依赖包时就能正常拉取了。
此外,如果公司内部自建了 GOPROXY 服务,那么我们可以通过设置 GONOPROXY=none,允许通内部代理拉取私有仓库的包。
go.mod文件
go.mod文件中记录了当前项目中所有依赖包的相关信息,声明依赖的格式如下:
require module/path v1.2.3
其中:
- require:声明依赖的关键字
- module/path:依赖包的引入路径
- v1.2.3:依赖包的版本号。支持以下几种格式:
- latest:最新版本
- v1.0.0:详细版本号
- commit hash:指定某次commit hash
引入某些没有发布过tag版本标识的依赖包时,go.mod中记录的依赖版本信息就会出现类似v0.0.0-20210218074646-139b0bcd549d的格式,由版本号、commit时间和commit的hash值组成。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wjSLzjTA-1668236508381)(https://gitee.com/lazyperson/typora-drawing-bed-01/raw/master/Image/202205082343950.png)]
go.sum文件
使用go module下载了依赖后,项目目录下还会生成一个go.sum文件,这个文件中详细记录了当前项目中引入的依赖包的信息及其hash 值。go.sum文件内容通常是以类似下面的格式出现。
<module> <version>/go.mod <hash>
或者
<module> <version> <hash>
<module> <version>/go.mod <hash>
不同于其他语言提供的基于中心的包管理机制,例如 npm 和 pypi等,Go并没有提供一个中央仓库来管理所有依赖包,而是采用分布式的方式来管理包。为了防止依赖包被非法篡改,Go module 引入了go.sum机制来对依赖包进行校验。
06、排序和查找
排序分为内部排序和外部排序;
内部八大排序算法:
插入排序:直接插入排序、希尔排序
交换排序:冒泡排序、快速排序
选择排序:简单选择排序、堆排序
归并排序
基数排序
冒泡排序:
func BubbleSort(arr *[5]int) {
fmt.Println("排序前arr=", (*arr))
temp := 0
fmt.Printf("arr=%T,*arr=%T\n", arr, (*arr))
for i := 0; i < len(arr)-1; i++ {
for j := 0; j < len(*arr)-1-i; j++ {
if (*arr)[j] > (*arr)[j+1] {
temp = (*arr)[j]
(*arr)[j] = (*arr)[j+1]
(*arr)[j+1] = temp
}
}
}
fmt.Println("排序后arr=", (*arr))
}
func main() {
var arr = [5]int{5, 3, 87, 6, 66}
BubbleSort(&arr)
fmt.Println("排序后arr=", arr)
}
顺序查找:就是遍历
二分查找:要求要查找的序列本身是有序的
func binarySort(arr *[10]int, leftIndex int, rightIndex int, finval int) {
if leftIndex > rightIndex {
fmt.Println("找不到")
return
}
middle := (leftIndex + rightIndex) / 2
if (*arr)[middle] > finval {
binarySort(arr, leftIndex, middle-1, finval)
} else if (*arr)[middle] < finval {
binarySort(arr, middle+1, rightIndex, finval)
} else {
fmt.Println("找到了,下标是:", middle)
}
}
func main() {
arr := [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
binarySort(&arr, 0, len(arr)-1, 3)
}
07、面向对象
Golang也支持面向对象编程(OOP),但是和传统的面向对象编程有区别,并不是纯粹的面向对象语言。所以我们说Golang支持面向对象语言是比较准确的。
Golang没有类(class),Go语言的结构体(struct)和其他语言的类(class)有同等地位,可以理解Golang是基于struct来实现OOP特性的
Golang面向对象编程非常简洁,去掉了传统OOP语言的继承、方法重载、构造函数、和析构函数、隐藏的this指针等等
Golang仍有面向对象的继承、封装和多态的特性,只是实现的方式和其他的OOP语言不一样,比如继承,Golang没有extends关键字,继承是通过匿名字段来实现
Golang面向对象很优雅,OOP本身就是语言类型系统(type system)的一部分,通过接口(interface)关联,耦合性低,也非常灵活。在Golang中面向接口编程是非常重要的特性
7.1、结构体
结构体与结构体变量(实例/对象)的关系
比如:猫所有特征提取出来 --> Cat结构体{1.字段/属性(Name、Age、Color) 2.行为(方法)} --> 变量(实例)、变量(实例)、……
- 将一类事物特性提取出来,形成一个新的数据类型,就是一个结构体
- 通过这个结构体,我们可以创建多个变量(实例/对象)
- 事物可以是猫类,也可以是Person、Fish、也可以是某个工具类
案例:
type Cat struct {
Name string
Age int
Color string
Hobby string
Scores [3]int
}
func main() {
//使用struct结构体
var cat1 Cat
cat1.Name = "小白"
cat1.Age = 3
cat1.Color = "白色"
cat1.Hobby = "吃鱼"
fmt.Println(cat1)
}
结构体和结构体变量的区别和联系
通过上面实例可以看出
- 结构体是自定义的数据类型,代表一类事物
- 结构体变量(实例)是具体的,实际的,代表一个具体变量
- 结构体变量的成员是有默认值的
- 结构体变量是值类型
结构体的声明:
type 结构体名称 struct{
field1 type
field2 type
}
字段/属性:
- 从概念或叫法上看:结构体字段 = 属性 = field
- 字段是结构体的一个组成部分,一般是基本数据类型、数组,也可以是引用类型
字段/属性注意事项
- 字段声明语法同变量
- 字段的类型可以是基本类型、数组、引用类型
- 在创建一个结构体变量之后,如果没有给字段赋值,都对应一个零值(默认值)
- bool是false,数值是0,字符串是""
- 数组类型的默认值和元素的类型相关
- 指针、slice、map的零值都是nil,即还没有分配空间
- 不同结构体变量的字段是独立,互不影响,一个结构体变量字段的更改,不影响另外一个,结构体是值类型
创建结构体变量和访问结构体字段
-
方式一:直接声明
var person Person
-
方式二:{}
person1 := Person{}
-
方式三:&
var person *Person = new(Person)
-
方式四:{}
var person *Person = &Person{}
func main() {
//方式一:直接声明
var p1 Person
p1.Name = "xioaming"
p1.Age = 17
//方式二:{}
p2 := Person{"marry", 20}
fmt.Println(p2)
--------------------------------------------------------------------------
//方式三:&
var p3 *Person = new(Person)
//因为p3是一个指针,因此标准赋值方式为
(*p3).Name = "smith"
(*p3).Age = 18
fmt.Println(*p3)
//(*p3).Name = "smith" 也可以这样写p3.Name = "smith"
//原因:go设计者为了程序员使用方便,底层会对p3.Name = "smith"进行处理,给p3加上取值运算(*p3).Name = "smith"
var p4 *Person = new(Person)
p4.Name = "john"
p4.Age = 20
fmt.Println(*p4)
//方式四:{}
//下面的方式也可以直接赋值
var p5 *Person = &Person{}
//p5是一个指针,说法同上
p5.Name = "tom"
p5.Age = 16
}
struct类型的内存分配机制
-
结构体的所有字段在内存中是连续的
type Point struct { //坐标 x int y int } type Rect struct { leftUp, rightDown Point //字段为坐标结构体 } type Rect1 struct { leftUp, rightDown *Point } func main() { //r1有四个int,在内存中是连续的 r1 := Rect{Point{1, 2}, Point{3, 4}} fmt.Printf("r1.leftUp.x 地址=%p r1.leftUp.y 地址=%p r1.rightDown.x 地址=%p r1.rightDown.y 地址=%p\n", &r1.leftUp.x, &r1.leftUp.y, &r1.rightDown.x, &r1.rightDown.y) //1.leftUp.x 地址=0xc00000e1c0 r1.leftUp.y 地址=0xc00000e1c8 r1.rightDown.x 地址=0xc00000e1d0 r1.rightDown.y 地址=0xc00000e1d8 //r2有两个*Point类型,这两个*Point类型的本身地址是连续的,但是他们指向的地址不一定是连续的 r2 := Rect1{&Point{10, 20}, &Point{30, 40}} fmt.Printf("r2.leftUp 本身地址=%p r2.rightDown 本身地址=%p\n", &r2.leftUp, &r2.rightDown) fmt.Printf("r2.leftUp 指向地址=%p r2.rightDown 指向地址=%p\n", r2.leftUp, r2.rightDown) //r2.leftUp 指向地址=0xc0000180b0 r2.rightDown 指向地址=0xc0000180c0 } -
结构体是用户单独定义的类型,和其他类型进行转换时需要有完全相同的字段(字段名字、个数、类型)
type A struct { Num int } type B struct { Num int } func main() { var a A var b B a = A(b) fmt.Println(a, b) } -
结构体进行type重新定义,Golang认为是新的数据类型,不可以直接把type后的结构体赋给原数据类型,但是相互间可以强转
-
struct的每个字段上,可以写上一个tag,该tag可以通过反射机制获取,常见的使用场景就是序列化和反序列化
Monster序列化[json] --> 字符串 发送给 客户端进行处理
package main
import (
"encoding/json"
"fmt"
)
type Monster struct {
Name string `json:"name"`
Age int `json:"age"`
Skill string `json:"skill"`
}
func main() {
monster := Monster{"牛魔王", 500, "芭蕉扇"}
//将monster变量序列化为json格式字符串
//json.Marshal 函数中使用反射
jsonStr, err := json.Marshal(monster)
if err != nil {
fmt.Println("json 处理错误", err)
}
fmt.Println("jsonStr", string(jsonStr))
}
7.2、工厂模式
Golang的结构体没有构造函数(构造器),通常可以使用工厂模式来解决这个问题
package model
type Student struct{
Name string
……
}
当Student首字母大写,如果想在其他包创建Student的实例,引入model包就可以了,但是当student首字母小写,就不行了 --> 工厂模式解决
案例:
当Student结构体首字母大写,没有问题
package model
type Student struct {
Name string
Score float64
}
package main
import (
"fmt"
"gostudy/src/oop4_15/exer/factory/model"
)
func main() {
var stu = model.Student{"msk", 99}
fmt.Println(stu)
}
当student首字母小写,工厂模式:
package model
type student struct {
Name string
Score float64
}
//因为student结构体首字母是小写的,因此只能在model中使用
//我们通过工厂模式来解决
func NewStudnet(n string, s float64) *student {
return &student{
Name: n,
Score: s,
}
}
//如果字段首字母小写,在其他包中不可以直接访问.写一个返回的方法,在其他包中调用stu.GetScore()
func (s *student) GetScore() float64{
return s.score
}
package main
import (
"fmt"
"gostudy/src/oop4_15/exer/factory/model"
)
func main() {
var stu = model.NewStudnet("tom", 88)
fmt.Println(stu)
fmt.Println("name=", stu.Name, "score=", stu.Score)
}
7.3、方法
Golang中方法是作用在指定的数据类型上的(即:和数据类型绑定),因此自定义类型,都可以有方法,而不仅仅是struct。
Go方法是作用在接受者receiver上的一个函数,接受者是某种类型的变量,所以在go语言里方法是一种特殊类型的函数
方法的声明:
func (recv receiver_type) methodName(parameter_list)(return_value_list){
……
}
func (变量名 绑定的数据类型) 方法名(形参列表)(返回值列表){
//操作
}
type A struct{
Num int
}
func (a A) test(){
fmt.Println(a.Num)
}
//说明
1.func (a A) test() {} 表示A结构体有一方法,方法名为test
2.(a A) 体现 test方法是和 A 类型绑定的
案例:
type Person struct {
Name string
}
func (p Person) test() {
fmt.Println(p.Name)
}
func main() {
var p Person
p.Name = "tom"
p.test()
}
- test()方法和Person类型绑定
- test()只能通过Person类型变量调用,不能直接调用也不能使用其他类型变量调用
- func(p Person) test() {} 中p表示哪个Person变量调用,这个p就是它的副本,这点和函数传参非常相似。在方法中改变结构变量成员对主函数中结构体变量没有影响,传地址除外
- p这个名字,由程序员指定,不固定,比如修改成person也是可以的。尽量写的有含义点
7.3.1、方法快速入门
-
给Person结构体添加speak方法,输出 xxx是个好人
func (p Person) speak() { fmt.Println(p.Name, "是一个好人") } -
给Person结构体添加jisuan方法,计算从1 + 1000 的结果,说明方法和函数是一样的
func (p Person) jisuan() { res := 0 for i := 1; i <= 1000; i++ { res += i } fmt.Println(p.Name, "计算结果是:", res) } -
给Person结构体添加jisuan2,该方法可以接受一个数n,计算从1加到n
func (p Person) jisuan2(n int) { res := 0 for i := 1; i <= n; i++ { res += i } fmt.Println(p.Name, "计算2结果是:", res) } -
给Person结构体添加getSum,该方法可以计算两个数的和,并返回结果
func (p Person) getSum(n1 int, n2 int) int { return n1 + n2 } -
方法的调用
var p Person p.Name = "tom" p.test() p.speak() p.jisuan() p.jisuan2(100) fmt.Println("sum=", p.getSum(3, 3))
7.3.2、方法的调用和传参机制
方法的调用和传参机制和函数基本一样,不一样的地方是方法调用时,会将调用方法的变量,当做实参也传递给方法(如果变量是值类型,则进行值拷贝。如果变量是引用类型,则进行地址拷贝)
案例:
type Circle struct {
radius float64
}
func (c Circle) area() float64 {
return 3.14 * c.radius * c.radius
}
func main() {
var circle Circle
circle.radius = 1.0
fmt.Println("Ciecle area =", circle.area())
}
//注意:return 3.14 * c.radius * c.radius中的radius是拷贝之后的
func (c *Circle) area() float64 {
return 3.14 * c.radius * c.radius
}
这个里面的radius是主函数中的radius
方法的注意事项和细节
-
结构体类型是值类型,在方法的调用中,遵守值传递机制,是值拷贝传递方式
-
如果程序员希望在方法中,修改结构体变量的值,可以通过结构体指针的方式来处理
type Circle struct { radius float64 } func (c *Circle) area() float64 { fmt.Printf("c 是 *Circle 指向的地址=%p\n", c) c.radius = 2 //c.radius相当于(*c).radius return 3.14 * c.radius * c.radius } func main() { var circle Circle circle.radius = 1.0 fmt.Printf("main circle 结构体变量地址 =%p\n", &circle) fmt.Println("Ciecle area =", circle.area()) } -
Golang中方法是作用在指定的数据类型上的(即:和数据类型绑定),因此自定义类型,都可以有方法,而不仅仅是struct。
type integer int func (i integer) print() { fmt.Println("i=", i) } func main() { var i integer i.print() } -
方法的访问范围控制和函数一样,方法名首字母小写,只能在本包中访问,方法名首字母大写,可以在本包和其他包中访问
-
如果一个方法实现了String()方法,那么fmt.Println默认会调用这个变量的String()进行输出
type Student struct { Name string Age int } //给Student实现String() func (stu *Student) String() string { str := fmt.Sprintf("Name=[%v] Age=[%v]", stu.Name, stu.Age) return str } func main() { stu := Student{"msk", 20} fmt.Println(&stu) }
方法与函数的区别
-
调用方式不一样
函数:函数名(实参列表)
方法:变量.方法名(实参列表)
-
对于普通函数,接受者为值类型时,不能将指针类型的数据直接传递,反之亦然
-
对于方法(如struct方法),接受者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以。 技巧:看方法中绑定的是值类型还是指针类型
- 不管调用形式如何,真正决定是值拷贝还是地址拷贝,看这个方法是和哪个类型绑定
7.4、封装
封装就是把抽象出的字段和字段的操作封装在一起,数据被保护在内部,程序的其他包只能通过被授权的操作(方法),才能对字段进行操作
好处
- 隐藏实现细节
- 对数据进行验证,保证安全合理
封装实步骤:
-
将结构体、字段首字母小写
-
给结构体所在包提供一个工厂模式的函数,首字母大写。类似一个构造函数
-
提供一个首字母大写的Set方法,用于对属性判断并赋值
func (var 结构体类型名) SetXxx(参数列表){ //加入数据验证逻辑 var.字段 = 参数 } -
提供一个首字母大写的Get方法,用于获取属性的值
func (var 结构体类型名) GetXxx()(返回值列表){ return var.age }
案例:
package model
import "fmt"
type account struct {
accountNo string
pwd string
balance float64
}
func NewAccount(accountNo string, pwd string, balance float64) *account {
if len(accountNo) < 6 || len(accountNo) > 10 {
fmt.Println("账号位数不对")
return nil
}
if len(pwd) != 6 {
fmt.Println("密码位数不对")
return nil
}
if balance < 20 {
fmt.Println("初始余额不足20!")
return nil
}
return &account{
accountNo: accountNo,
pwd: pwd,
balance: balance,
}
}
func (account *account) Depsodite(money float64, pwd string) {
if pwd != account.pwd {
fmt.Println("密码输入错误!")
return
}
if money <= 0 {
fmt.Println("输入金额不正确!")
return
}
account.balance += money
fmt.Println("存款成功")
}
func (account *account) WithDraw(money float64, pwd string) {
if pwd != account.pwd {
fmt.Println("密码输入错误!")
return
}
if money > account.balance || money < 0 {
fmt.Println("账户余额不足!")
} else {
account.balance -= money
fmt.Println("取款成功")
}
}
func (account *account) Query(pwd string) {
if pwd != account.pwd {
fmt.Println("密码输入错误!")
}
fmt.Println(account.accountNo, "你的账号余额为:", account.balance)
}
package main
import (
"fmt"
"gostudy/src/oop4_15/exer/factory/model"
)
func main() {
account := model.NewAccount("123456", "234564", 20)
account.WithDraw(20, "234564")
account.Query("234564")
account.Depsodite(1000, "234564")
account.Query("234564")
}
7.5、继承
继承可以提高代码复用性,让我们的编程更加靠近人类思维。解决代码冗余,利于功能扩展,代码维护
当多个结构体中存在相同的属性(字段)和方法时,可以从这些结构体中抽象出结构体。(少年、青少年、壮年、老年人,都继承Person),因此抽象出结构体Perosn之后,其他结构体中相同属性就可以不用重复定义了,只需要嵌套一个Person匿名结构体即可
细节:
-
结构体可以使用嵌套匿名结构体中所有的字段和方法,即首字母大写或小写的字段、方法都可以使用
type A struct { Name string Age int sal float64 } func (a *A) sayOK() { fmt.Println("你好", a.Name) } func (a *A) saySal() { fmt.Println(a.Name, "薪水是:", a.sal) } type B struct { A } func (b *B) sayOk(){ fmt.Println("你好",b.Name) } func main() { var b B b.A.Name = "Tom" b.A.Age = 21 b.A.sal = 33333 b.A.saySal() } -
匿名结构体字段访问可以简化
func main() {
//var b B
//b.A.Name = "Tom"
//b.A.Age = 21
//b.A.sal = 33333
//b.A.saySal()
var b B
b.Name = "Tom"
b.Age = 21
b.sal = 33333
b.saySal()
}
对上述代码的总结
当我们直接通过b访问字段或方法时,比如b.Name,其执行流程:编译器会先看b对应的类型有没有Name,如果有就直接调用B类型的Name字段。如果没有就去看B嵌入的匿名结构体A中有没有声明Name字段,如果有就调用,如果没有就继续查找,,如果都没有就报错
-
当结构体和匿名结构体有相同字段或方法时,编译器采取就近访问原则,如希望访问匿名结构体的字段和方法,可以通过匿名结构体名来区分
func main() { var b B b.Name = "Tom" //就近原则 b.A.Name = "jack" //明确访问的是A匿名结构体中的Name字段 b.Age = 18 b.sayOK() //就近原则 b.A.sayOK() //明确访问的是A匿名结构体中的sayOk()方法 } -
结构体中嵌入两个(或多个)匿名结构体,如两个匿名结构体有相同的字段和方法(同时结构体本身没有相同的字段和方法),在访问时就必须明确指定匿名结构体的名字,否则编译报错
-
如果一个struct嵌套了一个有名的结构体,这种模式就是组合,如果是组合关系,那么在访问组合的结构体的字段或方法时,就必须带上结构体的名字
type D struct { a A //有名的结构体 } func main(){ //比如D中是一个有名的结构体,则访问有名结构体的字段时就必须带上有名结构体的名字 var d D d.a.Name = "jack" } -
嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值。
type TV1 struct { Goods Brand } type TV2 struct { *Goods *Brand } func main() { tv1 := TV1{Goods{"电视01", 1200}, Brand{"海尔", "山东"}} tv2 := TV1{ Goods{ "电视02", 1100, }, Brand{ "夏普", "北京", }, } fmt.Println(tv1) fmt.Println(tv2) tv3 := TV2{&Goods{"电视03", 1000}, &Brand{"创维", "上海"}} tv4 := TV2{ &Goods{ "电视04", 999, }, &Brand{ "小米", "上海", }, } fmt.Println(*tv3.Goods, *tv3.Brand) fmt.Println(*tv4.Goods, *tv4.Brand) } -
如果一个结构体中有int类型的匿名字段,就不能有第二个。如果需要有多个int的字段,就必须给int字段指定名字
7.5.1、多重继承
如一个struct嵌套了多个匿名结构体,那么该结构体可以直接访问嵌套的匿名结构体的字段和方法,从而实现多重继承
type Goods struct {
Name string
Price float64
}
type Brand struct {
Name string
address string
}
type TV1 struct {
Goods
Brand
}
对多重继承的细节说明:
- 如嵌入的匿名结构体有相同的字段名或方法名,在访问时,需要通过匿名结构体类型来区分
- 为了保证代码的简洁性,建议尽量不使用多重继承
7.6、多态
实例(变量)具有多种形态。面向对象的第三大特征,在Go语言中,多态性是通过接口实现的,可以按照统一的接口来掉不同的实现,这时候接口变量就呈现不同的形态
func (c Computer) Working(usb Usb){ //usb变量会根据传入的实参,来判断到底是Phone还是Camera
//通过usb接口变量来调用Start和Stop方法
usb.Start()
usb.Stop()
}
//usb Usb,既可以接受手机变量,又可以接受相机变量就体现了Usb接口的多态性
案例
package main
import (
"fmt"
)
type Usb interface {
Start()
Stop()
}
type Phone struct {
Name string
}
func (p Phone) Start() {
fmt.Println("手机开始工作了")
}
func (p Phone) Stop() {
fmt.Println("手机停止工作")
}
type Camera struct {
Name string
}
func (c Camera) Start() {
fmt.Println("相机开始工作")
}
func (c Camera) Stop() {
fmt.Println("相机停止工作")
}
func main() {
var usb [3]Usb
usb[0] = Phone{"小米手机"}
usb[1] = Phone{"华为手机"}
usb[2] = Camera{"尼康相机"}
fmt.Println(usb)
usb[0].Start()
}
7.6.1、类型断言
type Point struct {
x int
y int
}
func main(){
var a interface{}
var point Point = Point{1,2}
a = point
//如何将一个接口变量,赋给自定义类型的变量 --> 类型断言
var b Point
b = a.(Point)
fmt.Println(b)
}
//b = a.(Point)就是类型断言,表示判断a是否是指向Point类型的变量,如果是就转成Point类型并赋值给b变量,否则报错
//在进行类型断言时,如果类型不匹配,就会报panic,因此进行类型断言时,要确保原来的空接口指向的就是断言的类型。
在进行类型断言时,带上检测机制,如果成功就ok,否则也不要报painc
func main() {
var i float64 = 88.88
var x interface{}
x = i
j, ok := x.(float32)
if ok == true {
fmt.Println("convert success")
fmt.Println(j)
} else {
fmt.Println("convert fail")
}
fmt.Println("继续执行~~")
}
08、接口与反射
8.1、接口
interface类型可以定义一组方法,但是这些不需要实现。并且interface不能包含任何变量。到某个自定义类型(比如结构体Phone)要使用的时候,再根据具体情况把这些方法写出来(实现)
基本语法:
type 接口名 interface{
method1(参数列表) 返回值列表
method2(参数列表) 返回值列表
}
func (t 自定义类型) method1(参数列表) 返回值列表{
//方法实现
}
func (t 自定义类型) method2(参数列表) 返回值列表{
//方法实现
}
说明:
-
接口里面所有方法都没有设方法体,即接口的方法都是没有实现的方法。接口体现了程序设计的多态和高内聚低耦合
-
Golang中的接口,不需要显示的实现。只要一个变量,含有接口类型中的所有方法,那么这个变量就实现了这个接口。因此,Golang中没有implement这样的关键字
-
接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量(实例)
type AInterface interface { Say() } type Stu struct { Name string } func (stu Stu) Say() { fmt.Println("stu Say()") } func main() { var stu Stu var a AInterface = stu a.Say() } -
Golang中,一个自定义类型需要将某个接口的所有方法都实现,我们说这个自定义类型实现了该接口
-
一个自定义类型只有实现了某个接口,才能将该自定义类型的实例(变量)赋给接口类型
-
只要是自定义数据类型,就可以实现某个接口,不仅仅是结构体类型
type AInterface interface { Say() } type Integer int func (i Integer) Say() { fmt.Println("Integer Say i =", i) } func main() { var i Integer = 10 var b AInterface = i b.Say() } -
一个自定义类型可以实现多个接口
-
Golang接口中不能有变量
-
一个接口(比如A)可以继承多个别的接口(比如B、C),这时如果要实现A接口,也必须将B,C接口的方法也全部实现
-
interface类型默认是一个指针(引用类型),如果没有对interface初始化就使用,那么会输出nil
-
空接口interface {} 没有任何方法,所有类型都实现了空接口,即我们可以把任何一个变量赋给空接口
func main() { var i Integer = 10 var b AInterface = i b.Say() var t I = i var t2 interface{} = i var num1 float64 = 8.9 t2 = num1 t = num1 fmt.Println(t, t2) }
接口案例:对hero结构体进行排序
package main
import (
"fmt"
"math/rand"
"sort"
)
type Hero struct {
Name string
Age int
}
type HeroSlice []Hero
//实现Interface接口
func (hs HeroSlice) Len() int {
return len(hs)
}
//方法决定使用什么标准进行排序
//按Hero年龄从小到大
func (hs HeroSlice) Less(i, j int) bool {
return hs[i].Age < hs[j].Age
//修改成对Name排序
//return hs[i].Name < hs[j].Name
}
func (hs HeroSlice) Swap(i, j int) {
//temp := hs[i]
//hs[i] = hs[j]
//hs[j] = temp
//上面等价于下面一句代码
hs[i], hs[j] = hs[j], hs[i]
}
func main() {
//var intSlice = []int{2, 1, 9, 8, 4}
//sort.Ints(intSlice)
//fmt.Println(intSlice)
var heroes HeroSlice
for i := 0; i < 10; i++ {
hero := Hero{
Name: fmt.Sprintf("英雄~%d", rand.Intn(100)),
Age: rand.Intn(100),
}
heroes = append(heroes, hero)
}
//排序前
//for _, v := range heroes {
// fmt.Println(v)
//}
//调用sort中Sort方法
sort.Sort(heroes)
//排序后
for _, v := range heroes {
fmt.Println(v)
}
}
接口与继承的关系
继承的价值主要是:解决代码的复用性和可维护性
接口的价值主要在于:设计,设计好各种规范(方法),让其他自定义类型去实现这些方法
接口比集成更加灵活 Person Student BirdAble LittleMonkey
接口比继承更加灵活,继承满足is - a的关系,而接口只需要满足 like - a的关系
接口在一定程度上实现了代码解耦
8.2、反射
反射的本质是 在运行时
反射是指在程序运行期对程序本身进行访问和修改的能力。
基本介绍:
-
反射可以在程序运行时动态获取变量的各种信息,比如变量的类型(type)、类别(kind)
-
如果是结构体变量,还可以获取到结构体本身的信息(字段、方法)
-
通过反射可以修改变量的值,可以调用关联方法
-
使用反射需要import(“reflect”)
import "reflect" reflect包实现了运行时反射,允许程序操作任意类型的对象。典型用法是用静态类型interface{}保存一个值,通过调用TypeOf获取其动态类型信息,该函数返回一个Type类型值。调用ValueOf函数返回一个Value类型值,该值代表运行时的数据。Zero接受一个Type类型参数并返回一个代表该类型零值的Value类型值。
两个重要函数:
-
reflect.TypeOf(变量名),获取变量的类型,返回reflect.Type类型
-
reflect.ValueOf(变量名),获取变量的值,返回reflect.Value类型(是一个结构体类型),通过reflect.Value可以获取关于变量的很多信息
-
变量、interface{}、reflect.Value可以相互转换
var student Stu var num int //变量 -> reflect.value 1. 变量传递参数到interface{} 2. reflect.ValueOf(i interface{}) //reflect.Value -> interface{} iVal := rVal.Interface() //interfac{} -> 变量 :使用类型断言 v := iVal.(Stu)案例: func reflectTest01(b interface{}) { //通过反射获取传入的变量的类型、类别 //1.获取reflect.Type rTyp := reflect.TypeOf(b) fmt.Printf("rTyp=%T\n", rTyp) //fmt.Printf("rTyp=%v\n", rTyp) fmt.Println("rTyp=", rTyp) rVal := reflect.ValueOf(b) fmt.Println("rVal=", rVal) n2 := 2 + rVal.Int() fmt.Println("n2=", n2) //将rVal转成interface{} iv := rVal.Interface() //将interfac{} 通过类型断言转成需要的类型 num2 := iv.(int) fmt.Println("num2=", num2) } func reflectTest02(b interface{}) { //1.获取reflect.Type rTyp := reflect.TypeOf(b) fmt.Printf("rTyp=%T\n", rTyp) //获取 reflect.Value rVal := reflect.ValueOf(b) //将rVal转成interface{} iv := rVal.Interface() fmt.Printf("iv = %v,ivTyp = %T\n", iv, iv) //将interfac{} 通过类型断言转成需要的类型 stu, ok := iv.(Student) if ok { fmt.Println(stu.Name) fmt.Println(stu.Age) } } func main() { //对基本数据类型、interface、reflect.Value进行反射的基本操作 var num int = 100 reflectTest01(num) var stu Student stu.Name = "tom" stu.Age = 21 reflectTest02(stu) }
反射常见应用场景:
-
不知道接口代用哪个函数,根据传入参数在运行时确定调用的具体接口,这种需要对函数或方法反射。
func bridge(funcPtr interface{},args...interface{}) 第一个参数funcPtr以接口的形式传入函数指针,函数参数args以可参数的形式传入,bridge函数中可以使用反射来动态执行funcPtr函数 -
结构体序列化时,如果结构体有指定的tag,会使用反射生成对应的字符串
反射注意事项:
-
reflect.Value.Kind 获取变量的类别,返回的是一个常量。可以通过reflect.Type和Value获取
-
Type和Kind的区别
Type是类型,Kind是类别,Type和kind可能是相同的,也可能是不同的。(Kind范围比较大) var num int = 10 num的Type是int,Kind是int var stu Student stu的Type是pkg.Student,Kind是struct -
通过反射,变量、interface{}、reflect.Value可以相互转换
-
使用反射的方式获取变量的值(并返回对应的类型),要求数据类型匹配,比如x是int,那么就应该使用reflect.Value(x).Int(),而不能使用其它的,否则报panic。 注意reflect.Value 和原来的Value类型不一样
-
通过反射来修改变量,注意当使用SetXxx方法来设置需要通过对应的指针类型来完成,这样才能改变传入的变量的值,同时需要使用到reflect.Value.Elem()方法,Elem()方法能通过指针变量找到变量进而可以修改原变量值
func reflect01(b interface{}) { rVal := reflect.ValueOf(b) fmt.Printf("rVal Kind =%v\n", rVal.Kind()) //rVal是指针 fmt.Println("rVal =", rVal) rVal.Elem().SetInt(100) } func main() { //通过反射修改num var num int = 10 reflect01(&num) fmt.Println("num =", num) } -
reflect.Value.Elem()方法,
func (v Value) Elem() Value Elem返回v持有的接口保管的值的Value封装,或者v持有的指针指向的值的Value封装。如果v的Kind不是Interface或Ptr会panic;如果v持有的值为nil,会返回Value零值。
反射案例:
-
使用反射来遍历结构体的字段,调用结构体的方法,并获取结构体标签的值
方法一、func (v Value) Method(i int) Value :默认按 方法名排序(ASCII) 对应i从0开始
方法二、func (v Value) Call(in []Value) []Value :传入参数和返回参数时 []reflect.Value
09、文件处理
文件是数据源(保存数据的地方)的一种,word文档、txt文件,excel文件都是文件。文件最主要的作用就是保存数据,既可以保存一张图片,也可以保存视频、音频……
9.1、文件操作
输入流和输出流
文件在程序中是以流的形式来操作的。
流:数据在数据源(文件)和程序(内存)之间经历的路径
文件 ----> Go程序 :输入流【读文件】
Go程序 ----> 文件 :输出流【写文件】
os.File 封装所有和文件相关操作,File是结构体
type File
func Create(name string) (file *File, err error)
func Open(name string) (file *File, err error)
func OpenFile(name string, flag int, perm FileMode) (file *File, err error)
func NewFile(fd uintptr, name string) *File
func Pipe() (r *File, w *File, err error)
func (f *File) Name() string
func (f *File) Stat() (fi FileInfo, err error)
func (f *File) Fd() uintptr
func (f *File) Chdir() error
func (f *File) Chmod(mode FileMode) error
func (f *File) Chown(uid, gid int) error
func (f *File) Readdir(n int) (fi []FileInfo, err error)
func (f *File) Readdirnames(n int) (names []string, err error)
func (f *File) Truncate(size int64) error
func (f *File) Read(b []byte) (n int, err error)
func (f *File) ReadAt(b []byte, off int64) (n int, err error)
func (f *File) Write(b []byte) (n int, err error)
func (f *File) WriteString(s string) (ret int, err error)
func (f *File) WriteAt(b []byte, off int64) (n int, err error)
func (f *File) Seek(offset int64, whence int) (ret int64, err error)
func (f *File) Sync() (err error)
func (f *File) Close() error
//操作文件就使用这些函数和方法
File常用函数和方法
-
打开文件
func Open(name string) (file *File, err error) -
关闭文件
func (f *File) Close() error案例:
import ( "fmt" "os" ) func main() { //file的叫法:file对象、file指针、file文件句柄 //打开文件 file, err := os.Open("e:/test111.txt") if err != nil { fmt.Println("open file err=", err) } //输出文件,看看文件是什么,--> file就是一个指针 *File fmt.Printf("file=%v", file) //file=&{0xc00007a780} //关闭文件 err = file.Close() if err != nil { fmt.Println("close file err=", err) } } -
读文件:
-
读取大文件:bufio包中Reader结构体,Reader实现了给io.Reader接口对象附加缓冲
func NewReader(rd io.Reader) *Reader NewReader创建一个具有默认大小缓冲、从r读取的*Reader。 案例: /* const ( defaultBufSize = 4096 //默认缓冲区为4096 ) */ //创建一个*reader,是带缓冲的 reader := bufio.NewReader(file) //循环读取文件内容 for { //读到一个换行就结束 str, err := reader.ReadString('\n') if err == io.EOF { //io.EOF表示文件的末尾 break } fmt.Print(str) } -
读取小文件:io/ioutil.ReadFile
func ReadFile(filename string) ([]byte, error) ReadFile 从filename指定的文件中读取数据并返回文件的内容。成功的调用返回的err为nil而非EOF。因为本函数定义为读取整个文件,它不会将读取返回的EOF视为应报告的错误。 func main() { //使用ioytil.ReadFile一次性将文件读取就位 file := "e:/test.txt" content, err := ioutil.ReadFile(file) if err != nil { fmt.Printf("read file err=%v", err) } //把读取到的内容显示到终端 fmt.Printf("%v", string(content)) //[]byte //没有显示的open文件,所以也不需要显示的close文件。文件的open和close被封装到ioutil.ReadFile中 }
-
-
写文件
按照指定权限打开文件,然后进行操作
func OpenFile(name string, flag int, perm FileMode) (file *File, err error)
说明:os.OpenFile是一个更具一般性的文件打开函数,它会使指定的选项(如:O_RDONIY等)、指定的模式(如0666等)打开指定名称的文件。如果操作成功,返回的文件可以用于I/O。如果出错,错误的底层类型是 *PathError
name string:文件名
flag int:打开方式:用于包装底层系统的参数用于Open函数,不是所有的flag都能在特定系统里使用的。
//这些常量要记住,这是操作文件的前提
const (
O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件
O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件
O_RDWR int = syscall.O_RDWR // 读写模式打开文件
O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部
O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件
O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在
O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O
O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件
)
FileMode:权限控制:在windows下无效,在linux和unix中使用
const (
// 单字符是被String方法用于格式化的属性缩写。
ModeDir FileMode = 1 << (32 - 1 - iota) // d: 目录
ModeAppend // a: 只能写入,且只能写入到末尾
ModeExclusive // l: 用于执行
ModeTemporary // T: 临时文件(非备份文件)
ModeSymlink // L: 符号链接(不是快捷方式文件)
ModeDevice // D: 设备
ModeNamedPipe // p: 命名管道(FIFO)
ModeSocket // S: Unix域socket
ModeSetuid // u: 表示文件具有其创建者用户id权限
ModeSetgid // g: 表示文件具有其创建者组id的权限
ModeCharDevice // c: 字符设备,需已设置ModeDevice
ModeSticky // t: 只有root/创建者能删除/移动文件
// 覆盖所有类型位(用于通过&获取类型位),对普通文件,所有这些位都不应被设置
ModeType = ModeDir | ModeSymlink | ModeNamedPipe | ModeSocket | ModeDevice
ModePerm FileMode = 0777 // 覆盖所有Unix权限位(用于通过&获取类型位)
)
练习1:
import (
"bufio"
"fmt"
"os"
)
func main() {
//创建新文件,在文件中写入hello,gardon
filePath := "e:/newfile.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v", err)
return
}
//及时关闭file句柄
defer file.Close()
//准备写入5句hello,gardon
str := "Hello,Gardon\n"
//写入时,使用带缓存的*Writer
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
//因为writer是带缓存的,因此在调用WriterString,内容是先写到缓存中的,
//所以需要调用Flush方法将缓存数据写到文件中
writer.Flush()
}
练习2
import (
"bufio"
"fmt"
"os"
)
func main() {
//打开已经存在的文件,修改其内容
filePath := "e:/newfile.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_TRUNC, 0666)
if err != nil {
fmt.Printf("open file err=%v", err)
return
}
defer file.Close()
str := "你好,新时代\n"
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
writer.Flush()
}
练习3
import (
"bufio"
"fmt"
"os"
)
func main() {
//追加内容
filePath := "e:/newfile.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
fmt.Println("open file err=", err)
return
}
defer file.Close()
str := "这是追加的内容\n"
writer := bufio.NewWriter(file)
for i := 0; i < 3; i++ {
writer.WriteString(str)
}
writer.Flush()
}
练习4
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
//打开一个文件,将原来的内容显示在终端,并且追加内容
filePath := "e:/newfile.txt"
file, err := os.OpenFile(filePath, os.O_RDWR|os.O_APPEND, 0666)
if err != nil {
fmt.Println("open file err=", err)
return
}
defer file.Close()
//读取原来的内容
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF { //io.EOF表示文件末尾
break
}
fmt.Print(str) //显示到终端
}
//追加内容
str := "这里是二次追加\n"
writer := bufio.NewWriter(file)
for i := 0; i < 3; i++ {
writer.WriteString(str)
}
writer.Flush()
}
练习5:
func WriteFile(filename string, data []byte, perm os.FileMode) error
函数向filename指定的文件中写入数据。如果文件不存在将按给出的权限创建文件,否则在写入数据之前清空文件。
import (
"fmt"
"io/ioutil"
)
func main() {
//将d盘下面file1导入到d盘file2
//1.将file内容读取到内存
file1Path := "e:/GoFileOperation/file1.txt"
file2Path := "e:/GoFileOperation/file2.txt"
data, err := ioutil.ReadFile(file1Path)
if err != nil {
fmt.Println("open file err=", err)
return
}
err = ioutil.WriteFile(file2Path, data, 6666)
if err != nil {
fmt.Println("write file error=", err)
}
}
-
判断文件是否存在
func (f *File) Stat() (fi FileInfo, err error) Stat返回描述文件f的FileInfo类型值。如果出错,错误底层类型是*PathError。 1.如果返回的错误为nil,说明文件或文件夹存在 2.如果返回的错误类型使用os.IsNotExist()判断为true,说明文件或文件夹不存在 3.如果返回的错误为其他类型,则不确定文件是否存在//基于这个方法可以自己写一个函数判断文件是否存在 func PathExists(path string)(bool,error){ _,err ;= os.Stat(path) if err == nil{ return true,nil } if os.IsNotExist(err){ return false,nil } return false,nil } -
拷贝文件
io包提供 func Copy(dst Writer, src Reader) (written int64, err error) 将src的数据拷贝到dst,直到在src上到达EOF或发生错误。返回拷贝的字节数和遇到的第一个错误。 对成功的调用,返回值err为nil而非EOF,因为Copy定义为从src读取直到EOF,它不会将读取到EOF视为应报告的错误。如果src实现了WriterTo接口,本函数会调用src.WriteTo(dst)进行拷贝;否则如果dst实现了ReaderFrom接口,本函数会调用dst.ReadFrom(src)进行拷贝。import ( "bufio" "fmt" "io" "os" ) //自己编写一个函数,接收两个文件路径 srcFileName dstFileName func CopyFile(dstFileName string, srcFileName string) (written int64, err error) { srcFile, err := os.Open(srcFileName) if err != nil { fmt.Println("open file err=", err) } defer srcFile.Close() //通过srcfile,获取到Reader reader := bufio.NewReader(srcFile) //打开文件 dstFile, err := os.OpenFile(dstFileName, os.O_WRONLY|os.O_CREATE, 6666) if err != nil { fmt.Println("open file err=", err) return } wtiter := bufio.NewWriter(dstFile) defer dstFile.Close() return io.Copy(wtiter, reader) } func main() { //拷贝文件 srcFile := "C:/Users/92609/Pictures/picture/green trees.jpg" dstFile := "E:/GoFileOperation/green.jpg" _, err := CopyFile(dstFile, srcFile) if err == nil { fmt.Println("拷贝完成!") } else { fmt.Println("拷贝失败!copy err=", err) } }
9.2、命令行参数
我们希望获取到命令行输入的各种参数
var Args []string
Args是一个string切片,保管了命令行参数,第一个是程序名。
import (
"fmt"
"os"
)
func main() {
fmt.Println("命令行参数有", len(os.Args))
for i, v := range os.Args {
fmt.Println("args[", i, "]=", v)
}
}
//在命令行输入参数然后执行args.go,结果如下:
命令行参数有 5
args[ 0 ]= args.exe
args[ 1 ]= beijing
args[ 2 ]= shanghai
args[ 3 ]= nanyang
args[ 4 ]= xinxiang
flag包调用解析命令行参数
前面的方式是比较原生的方式,对解析参数不是特别方便,特别是带有指定形式的命令行
比如:cmd>main.exe -f c:/aaa.txt -p 200 -u root
func IntVar(p *int, name string, value int, usage string)
IntVar用指定的名称、默认值、使用信息注册一个int类型flag,并将flag的值保存到p指向的变量。
func StringVar(p *string, name string, value string, usage string)
StringVar用指定的名称、默认值、使用信息注册一个string类型flag,并将flag的值保存到p指向的变量。
func Parse()
从os.Args[1:]中解析注册的flag。必须在所有flag都注册好而未访问其值时执行。未注册却使用flag -help时,会返回ErrHelp。
import (
"flag"
"fmt"
)
func main() {
//定义几个变量,用于接受命令行的参数
var user string
var pwd string
var host string
var port int
//&user 就是接收用户命令行中输入的-u 后面的参数值
//"u" 就是-u指定参数
//"",默认值
//"用户名,默认为空" ,说明
flag.StringVar(&user, "u", "", "用户名,默认为空")
flag.StringVar(&pwd, "pwd", "", "密码,默认为空")
flag.StringVar(&host, "h", "localhost", "主机名,默认为localhost")
flag.IntVar(&port, "port", 3306, "用户名,默认为3306")
//转换,必须调用该方法
flag.Parse()
fmt.Printf("user=%v,pwd=%v,host=%v,port=%v",
user, pwd, host, port)
}
9.3、json处理
JSON(JavaScript Object Notation),是一种轻量级数据交换格式,易于阅读和编写。同时也易于机器解析和生成。key-value
JSON2001年开始推广使用,目前已经是主流的数据格式
json易于机器解析和生成,并有效的提升网络传输效率,通常程序在网络传输时会先将数据(结构体、mao等)序列化成json字符串,到接收方得到json字符串时,再反序列化恢复成原来的数据类型(结构体、map等)。这种方式已然成为各个语言的标准。
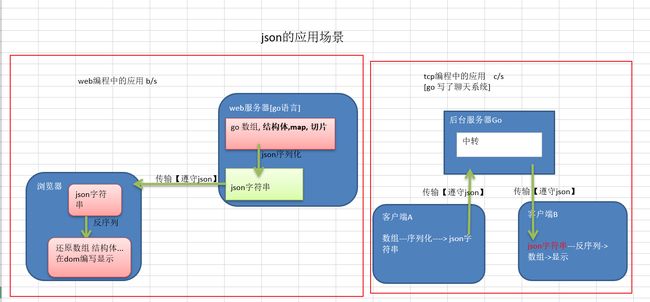
json数据格式说明
在JS语言中,一切都是对象。故,任何数据类型都可以通过JSON来表示
JSON**键值对(key-value)是用来保存数据的一种方式:键/值对组合的键名写在前面并用双引号""包裹,使用*分隔,然后紧接着值
https://www.json.cn/, 网站可以验证json格式的数据是否正确
方式一:
{"key1":val1,"key2":"val2","key3":"val3","key4":[val4,val5]}
方式二
[{"key1":val1,"key2":"val2","key3":"val3","key4":[val4,val5]},
{"key1":val1,"key2":"val2","key3":"val3","key4":[val4,val5]}]
比如:
{"firstName":"Json"}
[{"name":"tom","age":18,"address":"["北京","上海"]}
{"name":"jack","age":21,"address":"["广州","深圳"]}]
练习
[{"Name":"Tom","age":18,"address":["北京","上海"],"hobby":["篮球","足球","羽毛球"]},{"Name":"Marry","age":17,"address":["天津","南京"],"hobby":["足球","乒乓球"]}]
//结果:
[
{
"Name":"Tom",
"age":18,
"address":[
"北京",
"上海"
],
"hobby":[
"篮球",
"足球",
"羽毛球"
]
},
{
"Name":"Marry",
"age":17,
"address":[
"天津",
"南京"
],
"hobby":[
"足球",
"乒乓球"
]
}
]
json序列化:
json序列化,将有key-value结构的数据类型(比如结构体、map、切片)序列化成json字符串的操作
--注意:对于结构体的序列化,如果我们希望序列化后的key名字自己又重新定义,那么可以给struct指定一个tag标签
encoding/json包下
func Marshal(v interface{}) ([]byte, error)
Marshal函数返回v的json编码。
Marshal函数会递归的处理值。如果一个值实现了Marshaler接口切非nil指针,会调用其MarshalJSON方法来生成json编码。nil指针异常并不是严格必需的,但会模拟与UnmarshalJSON的行为类似的必需的异常。
案例:对key-value序列化
package main
import (
"encoding/json"
"fmt"
)
type Monster struct {
Name string `json:"monster_name"`
Age int `json:"monster_age"`
Birthday string `json:"birthday"`
Sal float64 `json:"salary"`
Skill string `json:"skill"`
}
func testStruct() {
var monster Monster = Monster{
Name: "哥斯拉",
Age: 500,
Birthday: "1520-01-01",
Sal: 1000000.0,
Skill: "吞噬",
}
data, err := json.Marshal(&monster)
if err != nil {
fmt.Println("序列化失败,err=", err)
}
//输出序列化后的结果
fmt.Printf("monster序列化后=%v\n", string(data))
}
func testMap() {
var a map[string]interface{}
a = make(map[string]interface{})
a["name"] = "金刚"
a["age"] = 500
a["address"] = "forest"
//将a序列化
data, err := json.Marshal(a)
if err != nil {
fmt.Println("序列化失败,err=", err)
}
//输出序列化后的结果
fmt.Printf("a map序列化后=%v\n", string(data))
}
func testSlice() {
var slice []map[string]interface{}
var m1 map[string]interface{}
m1 = make(map[string]interface{})
m1["name"] = "jack"
m1["age"] = 18
m1["address"] = "南阳"
slice = append(slice, m1)
var m2 map[string]interface{}
m2 = make(map[string]interface{})
m2["name"] = "marry"
m2["age"] = 18
m2["address"] = [2]string{"上海", "北京"}
slice = append(slice, m2)
data, err := json.Marshal(slice)
if err != nil {
fmt.Println("序列化失败,err=", err)
}
//输出序列化后的结果
fmt.Printf("slice 序列化后=%v\n", string(data))
}
func testFloat64() {
var num1 float64 = 2345.67
data, err := json.Marshal(num1)
if err != nil {
fmt.Println("序列化失败,err=", err)
}
//输出序列化后的结果
fmt.Printf("float64 序列化后=%v\n", string(data))
}
func main() {
//序列化结构体、map、切片
testStruct()
//monster序列化后={"Name":"哥斯拉","Age":500,"Birthday":"1520-01-01","Sal":1000000,"Skill":"吞噬"}
//monster序列化后={"monster_name":"哥斯拉","monster_age":500,"birthday":"1520-01-01","salary":1000000,"skill":"吞噬"}
testMap()
//a map序列化后={"address":"forest","age":500,"name":"金刚"}
testSlice()
//slice 序列化后=[{"address":"南阳","age":18,"name":"jack"},{"address":["上海","北京"],"age":18,"name":"marry"}]
//对基本数据类型序列化,意义不大
testFloat64()
//float64 序列化后=2345.67
}
json反序列化:
反序列化是将json字符串反序列化成对应的数据类型
import (
"encoding/json"
"fmt"
)
type Monster struct {
Name string
Age int
Birthday string
Sal float64
Skill string
}
func unmarshalStruct() {
str := "{\"Name\":\"哥斯拉\",\"Age\":500,\"Birthday\":\"1520-01-01\",\"Sal\":1000000,\"Skill\":\"吞噬\"}"
var monster Monster
err := json.Unmarshal([]byte(str), &monster)
if err != nil {
fmt.Println("unmarshal err=", err)
}
fmt.Println("monster=", monster)
}
func main() {
unmarshalStruct()
}
注意:
- 在反序列化一个json字符串时要确保反序列化后的数据类型和序列化前的数据类型一致。
- 如果json字符串是通过程序获取到的,则不需要再对 “ 进行转义处理
10、安全与测试
10.1、单元测试
Go语言中自带一个轻量级的测试框架testing和自带的go test命令来实现单元测试和性能测试
通过单元测试,可以解决:
- 确保函数是可以运行,并且运行结果是正确的
- 确保写出来的代码性能是好的
- 单元测试能及时发现程序设计或代码实现的逻辑错误,而性能测试重点在于发现程序设计上的一些问题,让程序能在高并发的情况下还能保持稳定
testing:
import "testing"
testing 提供对 Go 包的自动化测试的支持。通过 `go test` 命令,能够自动执行如下形式的任何函数:
func TestXxx(*testing.T)
其中 Xxx 可以是任何字母数字字符串(但第一个字母不能是 [a-z]),用于识别测试例程。
在这些函数中,使用 Error, Fail 或相关方法来发出失败信号。
package cal
//被测试的函数
func AddUpper(n int) int {
res := 0
for i := 1; i < n-1; i++ {
res += i
}
return res
}
func GetSub(n1 int, n2 int) int {
return n1 - n2
}
package caltest
import (
"gostudy/src/testing4_21/cal"
"testing"
)
func TestAddUpper(t *testing.T) {
//编写测试用例,测试addUpper
res := cal.AddUpper(10)
if res != 55 {
//fmt.Printf("AddUpper(10) 执行错误,期望值=%v 实际值=%v\n",55,res)
t.Fatalf("AddUpper(10) 执行错误,期望值=%v 实际值=%v\n", 55, res)
}
//如果正确,输出日志
t.Logf("AddUpper(10) 执行正确...")
}
func TestGetSub(t *testing.T) {
res := cal.GetSub(10, 4)
if res != 6 {
t.Fatalf("GtuSub(10,3) 执行错误 期望值=%v 实际值=%v", 7, res)
}
t.Logf("GetSub 执行正确...")
}
关于单元测试的细节:
-
测试用例文件名必须以**_test.go**结尾,比如cal_test.go,cal不是固定的
-
测试用例函数必须以Test开头,一般来说是Test+被测函数名
-
TestXxx(t *testing.T)的形参必须是*testing.T。T是一个结构体,绑定了很多方法,比如Falatf方法和Logf方法
-
一个测试用例文件中可以有多个测试用例函数
-
运行测试用例指令
- go test [如果运行正确,无日志,错误时会输出日志]
- go test -v [运行正确还是错误都输出日志]
-
当出现错误时,可以用t.Fatalf来格式化输出错误信息,并退出程序
-
t.Logf方法可以输出相应的日志
-
测试用例函数,并没有放到main函数中,也执行了,这也是测试用例的方便之处
-
PASS 表示测试用例运行成功,FAIL表示测试用例运行失败
-
测试单个文件,一定要带上被测试的源文件
go test cal_test.go cal.go -
测试单个方法
go test -v -test.run TestAddUpper
单元测试综合案例:
创建Monster结构体,字段为Name,Age,Skill
1.Store方法绑定Monster结构体,序列化Monster变量并且保存到文件中
2.ReStore方法绑定Monster结构体,反序列化Monster,并输出
编写测试用例文件测试
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
)
type Monster struct {
Name string
Age int
Skill string
}
func (this *Monster) Store() bool {
//1,序列化
data, err := json.Marshal(this)
if err != nil {
fmt.Println("序列化失败 err=", err)
return false
}
//2.保存到文件中
filePath := "e:/GoFileOperation/monster.ser"
err = ioutil.WriteFile(filePath, data, 666)
if err != nil {
fmt.Println("writer file err=", err)
return false
}
return true
}
func (this *Monster) ReStore() bool {
//反序列化
err = json.Unmarshal([]byte(content), content)
if err != nil {
fmt.Println("unmarshal err=", err)
}
fmt.Println(content)
//先从文件中读取序列化的字符
filePath := "e:/GoFileOperation/monster.ser"
data, err := ioutil.ReadFile(filePath)
if err != nil {
fmt.Println("read file err=", err)
return false
}
//使用data []byte ,反序列化
err = json.Unmarshal(data, this)
if err != nil {
fmt.Println("unmarshal err=", err)
return false
}
return true
}
func main() {
monster := Monster{
Name: "牛魔王",
Age: 666,
Skill: "芭蕉扇",
}
//序列化
monster.Store()
//反序列化
monster.ReStore()
}
package main
import "testing"
func TestMonster_Store(t *testing.T) {
//1.创建monster
monster := Monster{
Name: "红孩儿",
Age: 200,
Skill: "吐火",
}
res := monster.Store()
if !res {
t.Fatalf("moster.Store() error 希望值%v 实际值%v", true, res)
}
t.Logf("monster.Store() 测试成功")
}
func TestMonster_ReStore(t *testing.T) {
//测试数据是很多的,测试很多次,才能确定模块,函数...
//先创建Monster实例,不需要赋值
var monster Monster
monster.ReStore()
res := monster.Store()
if !res {
t.Fatalf("moster.ReStore() error 希望值%v 实际值%v", true, res)
}
//进一步判断
if monster.Name != "红孩儿" {
t.Fatalf("moster.ReStore() error 希望值%v 实际值%v", "红孩儿", monster.Name)
}
t.Logf("monster.ReStore() 测试成功")
}
11、并发编程
11.1、基础概念
进程与线程
- 进程就是程序在操作系统中一次执行过程,是系统进行资源分配和调度的基本单位
- 线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单位
- 一个进程可以创建和销毁多个线程,同一个进程中多个线程可以并发执行
- 一个程序至少有一个进程,一个进程至少有一个线程
并发与并行
多线程程序在单核上运行,就是并发
多线程程序在多核上运行,就是并行
并发:因为是在一个cpu上,比如有10个线程,每个线程执行10毫秒(进行轮询操作),宏观上看,好像这10个线程都在运行,但是从微观上看,在某个时间点上看,其实就是只有一个线程在执行
并行:因为是在多个cpu上,比如有10个线程,每个线程执行10毫秒(各自在不同的cpu上执行),宏观上看,好像这10个线程都在运行,但是从微观上看,在某个时间点上看,也同时有10个线程在执行
11.2、协程(goroutine)
执行体是个抽象的概念,在操作系统层面有许多概念与之对应,比如进程(process)、线程(thread),以及进程内的协程(coroutine,也叫轻量级线程)。协程最大的优势在于其“轻量级”,可以轻松创建上百万个协程而不会导致系统资源衰竭,而线程和进程通常最多也不能超过1万个。
Go协程的特点
- 有独立的栈空间
- 共享程序堆空间
- 调用由用户控制
- 协程是轻量级的线程
案例
1.在主线程(可以理解为进程)中,开启一个goroutine,该协程每隔1秒输出“Hello,World”
2.在主线程中每隔1秒输出“Hello,World”,输出10个后退出
3.要求主线程和goroutine同时执行
import (
"fmt"
"strconv"
"time"
)
func test() {
for i := 1; i <= 10; i++ {
fmt.Println("test()~Hello,World" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func main() {
//1.在主线程(可以理解为进程)中,开启一个goroutine,该协程每隔1秒输出“Hello,World”
//2.在主线程中每隔1秒输出“Hello,World”,输出10个后退出
//3.要求主线程和goroutine同时执行
go test() //开启了协程
for i := 1; i <= 10; i++ {
fmt.Println("main()~Hello,World" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
小结:
- 主线程是一个物理线程,直接作用在cpu上。是重量级的,非常耗费cpu资源
- 协程是从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗相对小
- Golang的协程机制是重要的的特点,可以轻松的开启上万个协程。其他编程语言的并发机制一般是基于线程的,开启过多的线程,资源消耗大
11.2.1、MPG模式
M:操作系统的主线程(是物理线程)
P:协程执行需要的上下文。逻辑处理器,负责调度协程;通常数量和
CPU数量一致G:协程
在实际执行过程中,M 和 P 共同为 G 提供有效的运行环境,多个可执行的 G 顺序挂载在 P 的可执行 G 队列下面,等待调度和执行。当 G 中存在一些 I/O 系统调用阻塞了 M时,P 将会断开与 M 的联系,从调度器空闲 M 队列中获取一个 M 或者创建一个新的 M 组合执行, 保证 P 中可执行 G 队列中其他 G 得到执行,且由于程序中并行执行的 M 数量没变,保证了程序 CPU 的高利用率。
11.3、设置Golang运行的cpu个数
为了充分利用多cpu的优势,在Golang程序中,设置运行的cpu数目
import (
"fmt"
"runtime"
)
func main() {
cpuNum := runtime.NumCPU()
fmt.Println("cpuNum=", cpuNum)
//可以自己设置使用的cpu个数
runtime.GOMAXPROCS(cpuNum-1)
fmt.Println("ok~~")
}
1.go1.8后默认让程序运行在多个核上,可以不用设置
2.go1.8前,还是要设置一下,可以更高效的利用cpu
11.4、通道(channel)
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的 goroutine 中容易发生竞态问题。为了保证数据交换的正确性,很多并发模型中必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
基本概念
-
Go语言采用的并发模型是
CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。 -
如果说 goroutine 是Go程序并发的执行体,
channel就是它们之间的连接。channel是可以让一个 goroutine 发送特定值到另一个 goroutine 的通信机制。 -
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
案例
//计算1-200各个数的阶乘,并把各个数的阶乘放到map中
//1.编写函数计算各个数的阶乘并放到map中
//2.启功多个协程
//3.map要设置成全局变量
import (
"fmt"
"sync"
"time"
)
var (
myMap = make(map[int]int, 10)
//lock是一个全局的互斥锁
//sync 是包,全称是synchornized同步
lock sync.Mutex
)
func factorial(n int) {
res := 1
for i := 1; i <= n; i++ {
res *= i
}
//将结果放入map中
//加锁
lock.Lock()
myMap[n] = res
//解锁
lock.Unlock()
}
func main() {
//主线程休眠10s,等待协程完成任务,不然主线程结束后,程序就结束了
time.Sleep(10 * time.Second)
for i := 1; i <= 200; i++ {
go factorial(i)
}
//主线程和协程同时进行,主线程不知道协程的情况,底层仍可能出现资源争夺
lock.Lock()
for i, v := range myMap {
fmt.Printf("myMap[%d]=%d ", i, v)
}
lock.Unlock()
}
不同goroutine之间如何通讯
-
全局变量加锁
- 主线程在等待所有goroutine全部完成的时间很难确定,上面设置10s,仅仅是估算
- 通过全局变量加锁实现通讯,也不利于多个协程对全局变量的读写操作
-
channel通道
- 本质是一个数据结构->队列
- 数据是先进先出
- 线程安全,多goroutine,不需要加锁,channel本身就是线程安全的
- channel有类型的,一个string的channel只能存放string类型数据
channel类型
channel是 Go 语言中一种特有的引用数据类型。声明通道类型变量的格式如下:
var 变量名称 chan 元素类型
其中:
- chan:是关键字
- 元素类型:是指通道中传递元素的类型
举几个例子:
var intChan chan int // 声明一个传递整型的通道
var boolChan chan bool // 声明一个传递布尔型的通道
var intSliceChan chan []int // 声明一个传递int切片的通道
var perChan chan Person
var perChan chan *person
初始化channel
声明的通道类型变量需要使用内置的make函数初始化之后才能使用。具体格式如下:
make(chan 元素类型, [缓冲大小])
其中:
- channel的缓冲大小是可选的。
举几个例子:
ch4 := make(chan int)
ch5 := make(chan bool, 1) // 声明一个缓冲区大小为1的通道
channel操作
通道共有发送(send)、接收(receive)和关闭(close)三种操作。而发送和接收操作都使用<-符号。
现在我们先使用以下语句定义一个通道:
ch := make(chan int)
发送
将一个值发送到通道中。
ch <- 10 // 把10发送到ch中
接收
从一个通道中接收值。
x := <- ch // 从ch中接收值并赋值给变量x
<-ch // 从ch中接收值,忽略结果
关闭
我们通过调用内置的close函数来关闭通道。关闭后不能再写数据,但是仍可以读取数据。
close(ch)
注意:一个通道值是可以被垃圾回收掉的。通道通常由发送方执行关闭操作,并且只有在接收方明确等待通道关闭的信号时才需要执行关闭操作。它和关闭文件不一样,通常在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
关闭后的通道有以下特点:
- 对一个关闭的通道再发送值就会导致 panic。
- 对一个关闭的通道进行接收会一直获取值直到通道为空。
- 对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
- 关闭一个已经关闭的通道会导致 panic。
案例:
func main() {
var intChan chan int
intChan = make(chan int, 3)
//intChan 的值:0xc00007e080,本身的地址:0xc000006028,类型:chan int
fmt.Printf("intChan 的值:%v,本身的地址:%p,类型:%T\n", intChan, &intChan, intChan)
//向通道写入数据
intChan <- 10
num := 50
intChan <- num
intChan <- 66
//intChan <- 98 //fatal error: all goroutines are asleep - deadlock!
fmt.Printf("intChan length=%v,Capacity=%v\n", len(intChan), cap(intChan)) //3,3
//从通道读取数据
var num2 int
num2 = <-intChan
fmt.Println("num2=", num2)
fmt.Printf("intChan length=%v,Capacity=%v\n", len(intChan), cap(intChan)) //2,3
//在没有使用协程情况下,如果我们的管道数据已经全部取出,再取就会deadlock
num3 := <-intChan
num4 := <-intChan
//num5 := <-intChan //fatal error: all goroutines are asleep - deadlock!
fmt.Println("num3=", num3, "num4=", num4)
}
1.通道只能存放指定的数据类型
2.注意给通道写入数据时,不能超过其容量
3.在没有使用协程情况下,如果我们的管道数据已经全部取出,再取就会deadlock
对channel遍历
channel支持for-range方式遍历
-
遍历时,如果channel没有关闭会出现deadlock错误
-
遍历时,如果channel已经关闭,会正常遍历数据,遍历完后就会退出遍历
close(intChan2) for v := range intChan2 { fmt.Printf("v=%v ", v) }
对channel使用的细节
-
通道可以声明为只读或只写,(默认情况下通道是双向的)
可以用在函数中,指定该函数对channel类型操作的权限
//声明为只写 var chan1 chan<- int chan1 = make(chan int, 10) chan1 <- 20 //num := <-chan1 //cannot receive from send-only channel chan1 //声明为只读 var chan2 <-chan int num2 := <-chan2 fmt.Println(num2) //chan2 <- 10 //cannot send to receive-only channel chan2 -
使用select可以解决从通道取数据的阻塞问题
//传统方法在遍历通道时,如果不关闭会阻塞,deadlock //label: for { select { //如果通道一直没有关闭,不会一直阻塞而deadlock,会到下一个case匹配 case v := <-intChan: fmt.Println("从intChan读取的数据", v) case v := <-strChan: fmt.Println("从strChan通道取到的数据", v) default: fmt.Println("都没取到,可以执行别的逻辑") //break label return } } -
goroutine中使用recover,解决协程中出现了painc导致程序崩溃的问题。
func sayHello() { for i := 0; i < 10; i++ { time.Sleep(time.Second) fmt.Println("hello,world") } } func test() { //这里我们可以使用defer + recover defer func() { //捕获test抛出的panic if err := recover(); err != nil { // assignment to entry in nil map fmt.Println("test() 发生错误", err) } }() //定义了一个map var myMap map[int]string myMap[0] = "golang" //error } func main() { go sayHello() go test() for i := 0; i < 10; i++ { fmt.Println("main() ok=", i) time.Sleep(time.Second) } }
12、网络编程
网络编程有两种:
- TCP socket编程,是网络编程的主流。之所以叫Tcp socket编程,时因为底层是基于Tcp/ip协议的,比如:QQ聊天
- B/S结构的http编程,使用浏览器去访问服务器时,使用的就是http协议,而http底层依旧是用的tcp socket实现的。
端口:
- 只要是服务程序,必须监听一个端口。例如:tomcat、mysql
- 端口是其他程序和该服务通讯的通道
- 一台电脑上有65535(256*256)个端口
- 一旦一个端口被某个程序监听(占用),那么其他程序就不能再该端口监听
- 端口分类:0是保留端口,1-1024是固定端口,又称有名端口、1025-65535是动态端口
- 在计算机尤其是服务器要尽可能少开端口
- netstat -an可以查看本机有哪些端口在监听,nerstat -anb 查看监听端口的pid,结合任务管理器关闭不安全的端口
12.1、socket编程
服务端的处理流程:
- 监听端口8888
- 接受客户端tcp链接,建立客户端和服务端的链接
- 创建goroutine,处理该链接的请求(客户端会通过链接发送请求包)
客户端的处理流程:
- 建立与服务端的链接
- 发送请求数据[终端],接收服务端返回的结果数据
- 关闭链接
服务器端代码:
import (
"fmt"
"net"
)
func process(conn net.Conn) {
defer conn.Close() //关闭conn
//这里循环接受客户端发送的数据
for {
//创建一个新的切片
buf := make([]byte, 1024)
//等待客户端通过conn发送信息
//如果客户端没有Write,协程就阻塞在这里
//fmt.Println("服务器在等待客户端", conn.RemoteAddr().String(), "发送信息")
n, err := conn.Read(buf) //接受conn
if err != nil {
//io.EOF
fmt.Println("客户端退出")
//fmt.Println("服务端Read err=", err)
return
}
//显示客户端发送数据到服务器终端
fmt.Print(string(buf[:n])) //buf[:n] n很巧妙
}
}
func main() {
fmt.Println("服务器开始监听了..")
//
listen, err := net.Listen("tcp", "0.0.0.0:8888")
if err != nil {
fmt.Println("listen err=", err)
return
}
defer listen.Close() //延迟关闭
//循环等待客户端连接
for {
//等待客户端链接
fmt.Println("等待客户端链接...")
conn, err := listen.Accept()
if err != nil {
fmt.Println("Accept() err", err)
} else {
fmt.Printf("Accept() success con=%v,客户端ip=%v\n", conn, conn.RemoteAddr().String())
}
//起一个协程为客户端服务
go process(conn)
}
//fmt.Println("listen suc =", listen)
}
客户端代码:
import (
"bufio"
"fmt"
"net"
"os"
"strings"
)
func main() {
conn, err := net.Dial("tcp", "10.1.1.240:8888")
if err != nil {
fmt.Println("client didl, err=", err)
return
}
fmt.Println("conn success, conn=", conn)
for {
//客户端发送单行数据,然后退出
reader := bufio.NewReader(os.Stdin) //os.Stdin标准输入,就是终端
//从终端读取一行用户的输入,并准备发送给服务器
line, err := reader.ReadString('\n')
if err != nil {
fmt.Println("readString err=", err)
}
//如果用户输入的是 ecit就退出
line = strings.Trim(line, "\r\n")
if line == "exit" {
fmt.Println("客户端退出")
break
}
//将line发送给服务器he
n, err := conn.Write([]byte(line + "\n"))
if err != nil {
fmt.Println("conn.Write err=", err)
}
fmt.Println("客户端发送了", n, "字节数据")
}
}
13、Redis
redis指令:Redis 命令参考
-
Redis是NoSQL数据库,不是传统的关系型数据库
-
Redis:REmote Dlctionary Server(远程字典服务器),Redis性能非常高,单机能达到15w qps,通常适合做缓存,也可以支持持久化
-
Redis完全开源,高性能的(key/value)分布式内存数据库,基于内存运行并支持持久化的NoSQL数据库,是热门的NoSQL数据库之一。Redis 通常被称为数据结构服务器,因为值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。
Redis的基本使用
Redis安装好后默认有16个数据库,初识默认使用0号库,编号是0-15
- 添加key-val [set]
- 查看当前redis的所有key [keys *]
- 获取key对应的值 [get key]
- 切换redis数据库 [select index]
- 如何查看当前数据库的key-val数量 [dbsize]
- 清空当前数据库的key-val和清空所有数据库的key-val [flushdb flushall]
Redis数据类型和CRUD
- Redis五大数据类型:String(字符串)、Hash(哈希)、List(列表)、Set(集合)和zset(sorted set:有序集合)
- set 如果存在相当于修改,如果没有表示添加。get/del
- setex(set with expire)键秒值;语法:setex key seconds value
- mset 同时设置一个或多个key-value对 ;mset key-value [key-value]
- mget 同时获取一个或多个键值对;mget key-value [key-value]
13.1、redis数据类型及其操作
Redis五大数据类型:String(字符串)、Hash(哈希)、List(列表)、Set(集合)和zset(sorted set:有序集合)
String介绍
- String是redis最基本的类型,一个key对应一个value。
- string类型在redis中是二进制安全的,除普通的字符串外,也可以存放图片等数据
- redis字符串最大是512M
- 操作:set/get/mset/mget
Hash(哈希,类似golang里的Map)
-
Redis hash 是一个键值对集合。 var user1 map[string]string
-
Redis hash 是一个string类型的field和value的映射表,hash特别适用用于存储对象
-
存放 hset : hset key field value
-
读取hget : hget key field
1.存放:
hset user1 name "smith"
hset user1 age 20
hset user1 job "golang coder"
2.读取:
hget user1 job
hgetall user1
3.删除:
hdel user1 field [field...]
4.一次存取多个:hmset hmget
hmset key field1 value1 [field value...]
hmget key field1 field2 field...
5.统计一个hash有多少个元素
hlen key
6.判断哈希key中 field是否存在
hexists key field
List(列表)
-
列表示简单的字符串列表,按照插入顺序,可以添加一个元素到列表的头部(左边)或者尾部(右边)
-
List本身是一个链表,List的元素是有序的,元素的值可以重复
-
操作:lpush,rpush,lrange,lpop,rpop,del
-
lindex,按照索引下标获取元素,从左到右,编号从0开始
-
llen key ,返回列表的长度,如果key不在,则key被解释为一个空列表,返回0
-
pop出所有值,键也就不存在了
左边插入:
lpush : lpush key value [value...]
右边插入
rpush : rpush key value [value...]
返回列表元素
lrange : lrange key start stop ,0表示第一分元素,1表示第二个元素,-1表示倒数第一个元素,以此类推
左边取(并拿走):
lpop : lpop key
右边取(并拿走):
rpop : rpop key
删除:
del key
Set(集合)
- redis的set是string类型的无序集合
- 底层是HashTable数据结构,set也是存放很多字符串元素,字符串元素是无序的,而且元素的值不能重复
存入:
sadd key member [member...]
取出所有元素:
smembers key
判断值是否是成员:
sismember key member
删除指定值:
srem key member [member...]
13.2、Go操作redis
下载第三方redigo库:
go get -u github.com/gomodule/redigo/redis
注意使用go get下载redigo库需要电脑已经安装并配置好git
//连接redis
conn, err := redis.Dial("tcp", "localhost:6379")
if err != nil {
fmt.Println("redis.Dial err=", err)
return
}
defer conn.Close()
//通过go向redis写入数据
_, err = conn.Do("Set", "name", "tom")
if err != nil {
fmt.Println("set err,", err)
return
}
//获取数据
res, err := redis.String(conn.Do("Get", "name"))
if err != nil {
fmt.Println("set err,", err)
return
}
//返回的res是interface{},
//fmt.Println("name =", res.(string))//interface conversion: interface {} is []uint8, not string
//使用redis提供的方法,如上
fmt.Println("name=", res)
fmt.Println("操作成功")
Go操作redis连接池
- 事先初始化一定数量的连接,放入到连接池
- 当go需要擦做redis时,直接从redis连接池中获取连接
- 这样可以节省获取redis连接的时间,从而提高效率
连接池案例
//定义一个全局的pool
var pool *redis.Pool
//当程序启东时就初始化连接池
func init() {
pool = &redis.Pool{
MaxIdle: 8, //最大空闲连接数
MaxActive: 0, //表示和数据库的最大连接数,0表示没有限制
IdleTimeout: 100, //最大空闲时间
Dial: func() (redis.Conn, error) { //初始化连接的代码,连接哪个ip的redis
return redis.Dial("tcp", "localhost:6379")
},
}
}
func main() {
//先从pool中取出一个连接
conn := pool.Get()
defer conn.Close()
_, err := conn.Do("set", "name", "tomcat")
if err != nil {
fmt.Println("conn.do err", err)
return
}
res, err := redis.String(conn.Do("get", "name"))
if err != nil {
fmt.Println("get err", err)
}
fmt.Println("res =", res)
//如果我们要从pool中取出连接,要确保连接诶是没有关闭的
pool.Close()
conn2 := pool.Get()
fmt.Println("conn2", conn2)
_, err = conn2.Do("set", "name2", "tiger01") //conn.do err redigo: get on closed pool
if err != nil {
fmt.Println("conn.do err", err)
return
}
}