数据集样本类别不均衡时,训练测试集应该如何做?
作者:小鹿鹿lulu
链接:https://www.zhihu.com/question/373862904/answer/1039080874
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
多分类任务中类别不均衡是非常常见的一个问题,但是差别多少才算分布不均匀呢?
这个没有一个确定的衡量标准。根据我个人的经验的话,不同类别数量差异超过一个数量级,我才会认为样本类别分布不均匀,需要特别关注和调整。比如题主的截图,最大的类别数是最小类别的三个数量集,差距非常大,触犯了样本类别分布不均的情况。
针对样本分布不均匀,可以从以下几个方面来多加关注和尝试:
- sample数据:
当样本类别分布不均匀的时候,什么都不管还是直接将数据shuffle,随机切分训练/验证/测试集,显然是不太合理的。常用的有简单欠采样和过采样的方法。
欠采样:如题主,就这桶的最短板“一刀切”,每个类别sample最小值239,这样就保证了数据分布绝对均匀,但是造成了严重的数据浪费。
过采样:以最高板为标准,重复拼接短板(重复抽样类别量小的数据)。这样数据重复使用,肯定不会造成浪费了吧。但是问题来了,对数量少的类别(如总共只有239个样本),强行将每个样本重复10^3遍,模型训练一个epoch的时候,对这类数据重复学习了10^3次,并且数据量本身就非常小,只有239个,极大可能造成在这些类别上过拟合。
两者之间更智能的方法:
简单讲一下工作中亲测有效的方法,也是在multi-task learning中常用的sample方式。使用multinomial distribution,对不均衡的数据分布做平滑。
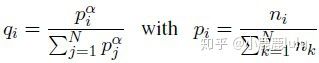
pi为原始数据分布中第i类数据出现的概率,qi为平滑处理后抽取第i类数据的概率。通过这个分布平滑抽样,抽样结果不会改变原始的各类别数据量大小的序关系,但是对类别数量过大的类数据量会相对减少,对类别数量过小的类数据量会相对增加。减少过拟合的可能性,也没有过度浪费数据。
参见论文:https://arxiv.org/pdf/1901.07291.pdf
2. 加权的损失函数
对于样本数量少的类别,可以考虑加大对该类别误判的惩罚,实质上时增加这类样本的权重,修正模型因为数量少而关注少的问题。
3. 评估指标
不要一股脑的只看所有类别整合的评估指标如ACC(当类别分布不均匀的时候会有极度的欺骗性)。
不妨细致的对比验证集和测试集的混淆矩阵,计算各类别的precision和recall,通过结果发现问题,指导你后续应该怎么优化。
采样方法、加权损失,个人认为还是治标不治本。在使用神经网络等需要大量数据支撑的模型算法时,该增加数据量还是得跟上,不管通过人工标注,还是使用其他一些数据增强的方法。
类别不平衡学习大致有三种策略:一,欠采样,针对数量过多的样例。二,过采样,针对数量较少的样例。三,阈值移动,就是对阈值进行调整。直接基于原始数据训练,进行预测时,用样例的真实观测几率来修正阈值。
作者:傅煜铭
链接:https://www.zhihu.com/question/373862904/answer/1035664224
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
 。
。
解决方案主要有:
- 过采样(随机采样、SMOTE、ADASYN等)
- 降采样
- 过采样与降采样结合(SMOTEENN、SMOTETomek)等。
在这些思想或者算法的基础上,有许多人提出了各种自带采样器的集成学习方法,比如包含采样的随机森林(Random Forest)、提升学习(Boosting)方法等。采样可以说是处理类别不平衡问题的第一种思路。关于这部分,python包imbalanced-learn做了很好的总结,可以直接使用它的模块,或者参考模块的写法。
第二种思路是修改权重(re-weighting)。简言之,如果在训练时降低多数类样本对损失函数的贡献,使其总贡献与少数类样本对损失函数的总贡献均衡,那么学习器对多数类的偏重就会减轻。比如,sklearn中的随机森林等算法,可以手动设置"class_weight"参数,一般来说将class_weight设置成与类别比成反比即可,多类的情况同理,具体可以参考文档。
有的答主提到了深度学习中的“focal loss”损失函数,它和GHM等损失函数也都是通过修改权重来起作用的。与简单的“class weight”不同,“focal loss”和GHM将类别不平衡问题的难点归结为分类“硬度”(hardness)问题,即造成困难的主要是少数难分类的样本,而非大多数易分类的样本。因此,如果将某些难分样本的损失函数权重提高,将大多数易分类样本的权重降低,那么就能提升整体的学习效果。
以上两种思路是数据和算法层面的考量。第三点也有答主指出来了,就是使用比accuracy、F1-score等更合适的评价标准。Accuracy、F1-score并未考虑类别比例,在类别不平衡情况下没有太高的参考价值。我个人倾向于使用Matthews correlation coefficient (MCC) ,因为它在数学上考虑了类别比例。下面这篇文章对MCC的重要性有比较详细的检验和介绍:【Chicco, D., Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation.BMC Genomics21,6 (2020). https://doi.org/10.1186/s12864-019-6413-7】
https://bmcgenomics.biomedcentral.com/articles/10.1186/s12864-019-6413-7bmcgenomics.biomedcentral.com
当然,类别不平衡问题是一个深坑,很多出色的算法遇到它时也风光不再。不过有时候,你可能会发现类别不平衡并未对你的任务带来什么困难(考虑“硬度”,或者特征空间中的类别重叠程度)。我觉得目前还没有通用的/好用的针对类别不平衡问题的方法,但是现有的算法,结合你自己对于数据的理解,多多少少可以减轻类别不平衡带来的影响。(有空再填)