个性化习题推荐-Exercise recommendation based on knowledge concept prediction
一、基本信息
时间:2020年
期刊:Knowledge-Based Systems(SCI1区)
作者:吴正洋等(作者主页链接:http://faculty.scholat.com/homepage/scnu/cs/0/134)
机构:华南师范大学
二、论文五要素
1、论文动机
1.1 背景:
习题练习可以巩固学生的知识,推荐难度适中的习题可以指引学生正确的学习方向,同时还可以激发学生的学习兴趣。
1.2 目的:
给学生推荐个性化的习题,个性化的习题包括了个人难度适中、习题新颖(指重点推荐学生以前未答或者答题不正确的)、习题多样性(指习题种)
1.3 挑战:
①不同的学生有着不同的学习状态
②题库中的习题数量庞大
③如何使得推荐的习题难度适中、习题类型丰富、习题包含的知识点和当前的学习阶段相适应
2、传统方法
2.1 习题推荐的传统方法:
协同过滤(CF):依赖学生之间的相似度或者习题之间的相似度进行推荐
缺点:无法直接为学生提供难度适中的习题,因为协同过滤中的难度标签是人工评估的,不是针对个人的主观难度,因此不可避免的导致存在偏差;本文中针对的难度是个人难度。
2.2 前人工作-习题推荐
①content-based filtering(CBF): 基于习题属性或者推荐目标属性的相似性
②collaborative filtering(CF):
③hybrid filtering(HF)
2.3 前人工作-习题难度预测(个人难度)
注意:这篇论文中提及的难度是个人难度
①基于学生的情感分析
②基于学生的行为分析
③基于学生的答题序列(知识追踪):知识追踪模型从传统的BKT到深度知识追踪模型DKT
3、主要方法
提出了一种新的习题推荐方法KCP-ER(exercise recommendation method based on knowledge concept prediction)。该方法除了输入层和输出层外,包含了两个大部分:KCPL (the knowledge concept prediction layer)和ESPL (the exercise set filtering layer)。框架图如下图所示。

输入层:输入学生的答题记录
KCPL层:该层分为两个模块,上面是KCCP(使用LSTM模型),用于预测下一个时刻进行的习题应该包含的知识点;下面是KCMP(使用深度知识追踪模型DKT),用于预测该学生在下一个时刻的能否答对该习题。
ESFL层:该层从基于上一层得到的预测知识点和学生的学习情况对题库中的习题进行筛选得到ES(习题集),以找到合适的习题进行推荐;此外,在该层中,为了增加习题的多样性,引入了模拟退火算法进一步对ES中的习题进行筛选。
输出层:输出习题推荐序列
具体的
①KCCP中的KCCP模块(即图中的上半部分)利用学生的答题序列得到学生答题过程中每个知识点出现的次数以及学生对于每个知识点的答题情况,为了推荐给学生适合的习题,论文中赋予了学生答题过程中未答知识点和回答错误的知识点更大的权重,便于后续对包含未答或者回答错误的知识点的习题优先进行推荐,因此体现了论文目的中推荐习题的新颖度(novelty)
②KCCP中的KCMP模块(即图中的下半部分)利用学生的答题序列得到每个学生关于所有知识点的掌握程度,进而得到学生关于每道习题的个人难度。因此体现了论文目的中推荐习题的难度适中(difficulty)
③在ESFL层中使用的模拟退火算法将基于KCCP和KCMP模块得到的推荐习题再次进行筛选,作者将ES(即基于KCCP和KCMP的输入结果筛选得到的习题集)认为是一个高维空间,而ES中的每个习题就是空间中的一个点,因此习题多样性则体现在空间中最远距离的点上。
④KCCP模型的输入是,KCMP模型(即DKT)的输入是one-hot编码后的答题序列。
4、实验
1、数据集
注意:这里的个性化推荐不是真正实时进行了推荐,具体看评价指标。

2、对比方法
①SB-CF(the student-based collaborative filter method)
②EB-CF(the exercise-based collaborative filter method)
③CBF(content-based filtering)
④HB-DeepCF(deep collaborative)
⑤KGEB-CF(knowledge-graph embedding based collaborative filtering)
3、评价指标
①针对个人难度:作者的推荐习题的三个目的之一是难度适中,因此作者认为推荐的准确度可表示为理想的个人难度和推荐习题的个人难度之间的差,为了更加直观,作者进行了一些小调整,因此该公式如下:(U表示推荐的习题个数,理想的个人难度作者依据前人的论文设置为0.7,该评价指标是作者认为的)准确度越大越好
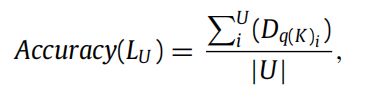
②针对新颖度:这篇论文中作者认为习题新颖度为包含学生未答过的知识点或者答错的知识点的习题,最后的公式如下图所示:(新颖度是前人已提出,作者根据实际情况进行了调整)新颖度越大越好

③针对多样性:作者认为习题的多样性可表示为推荐习题的之间的相似度,最后的公式如下所示:(多样性也是前人已提出,作者进行了调整)多样性越大越好

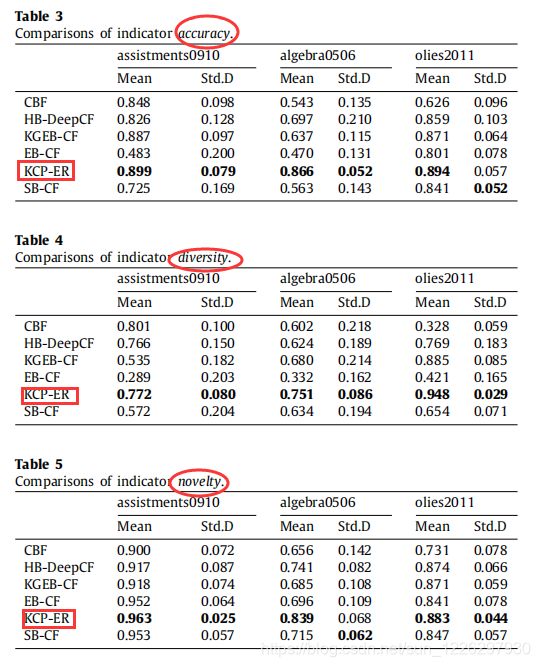
4、实验结果
从三个评价指标的结果来看,作者提出的KCP-ER方法整体上都优于其他5种习题推荐方法。画图更直观,蓝色线条为作者提出的方法。(3个指标的范围为0-1)

5、创新点
①提出了一个基于预测知识点的习题推荐方法,预测知识点用于筛选学生未答知识点和答错知识点的习题,更加有利于学生的学习
②论文中使用DKT模型得到的个人难度对学生进行推荐,因此在习题的难度标签缺失的情况下也能进行推荐(这点有点牵强,个人难度和习题标签的客观难度之间没有可比性)
③使用模拟退火算法对推荐的习题进行再次筛选,保证了习题的多样性
三、论文总结
(1)论文中有些错误的地方,如table4中的CBF方法中的第一个mean需要标粗,错标成了论文中的方法
(2)实验评价指标准确度的理性个人难度是人为进行设定,这个评价指标有点牵强
(3)作为个性化习题推荐,论文中提出的方法并没有进行真实环境下的习题推荐实验
(4)论文中的代码不开源
(5)作者认为未来的工作可以考虑加入①习题的文本信息,或者②建立学生行为和习题之间的语义联系(这里不明白作者的意思),还可以③考虑知识点之间的内在联系,④使用其他学习系统中的cross-dimensional data解决冷启动问题等
阅读论文中的疑惑:(红色表示未解决)
1. difficulty novelty diversity分别指的是什么? 习题的难度(是主观难度还是客观难度) 习题的多样性是指题型方面的多样性还是知识点方面的多样性 ?如何体现?
答:分别指推荐的个人难度,习题新颖度,习题多样性。具体看评价指标那一节。
2. 为什么要预测下一个时刻习题中出现的知识点?
答: 筛选未答过知识点以及答过知识点中正确回答次数不多的知识点.
3. 公式(2)感觉有问题,推荐的习题中包含的知识点为什么要是和预测的知识点之间的相似度大。而指定的难度阈值是客观难度还是主观难度,如果是客观难度,而相似度比较的另一个却是学生的主观难度,这个能进行比较吗?
答:还是觉得公式(2)的描述有问题。指定的难度阈值是主观难度,即个人难度。这里需要再思考!
4. 论文中KC coverage prediction模型的输出为什么需要降低出现次数多且正确回答的知识点?
答: 为了让推荐学生未答过知识点以及答过知识点中正确回答次数不多的知识点.即KC coverage prediction模型的作用是预测下一个时刻每个知识点中出现的概率,其实是筛选未答过知识点以及答过知识点中正确回答次数不多的知识点.
5. 论文中的评价指标是否合理? 为什么设置的个人难度为0.7,依据在哪里?准确度这个指标很迷惑。
答:准确度这个指标有点牵强,难度值设置是根据其他论文得到。
6.作者说自己提出的方法考虑了知识点和习题类型,但未感觉用到习题类型,是在多样性中使用到?
答: