MindSpore笔记:训练手写数字识别
前言
万物皆需前言。
如果该文章无法阅读懂,没关系,后面有较为明了的解释文章。
如果还没装mindspore,请点击:here
先来硬的!!
那么,学习一个新东西,要先来硬的。一门语言是Hello World,那么深度学习是MNIST!
什么是MNIST?
这时一个共6万多张数字的手写数字数据集,今天我们就使用它来训练一个会识别数字的人工智能。
在此之前,我们需要了解机器学习的计算方式,我们可以回顾一下直线方程:
y = k x + b y=kx+b y=kx+b
我们知道了x但不知道y。需要求k与b。
那么我们也可以这么写:
y = k 1 x 2 + k 2 x 2 + . . . + k i x i + b y=k_1x_2+k_2x_2+...+k_ix_i+b y=k1x2+k2x2+...+kixi+b
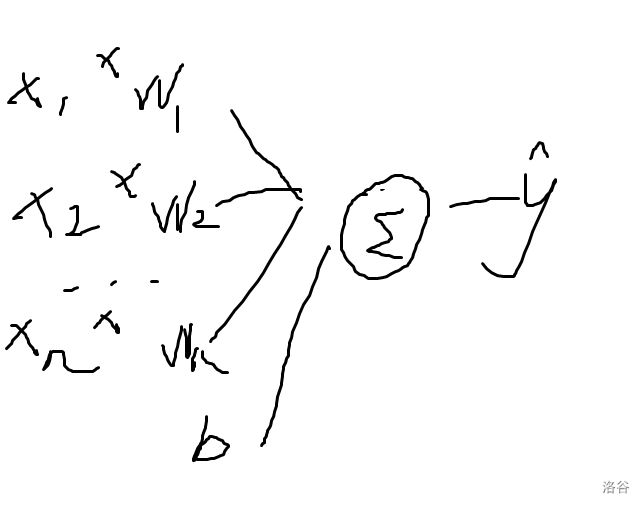
(图丑勿说)
或者:
y = f ( g ( x ) ) y=f(g(x)) y=f(g(x))

我这里不多述了。大家可以上网找一下博文。
《深度学习与MindSpore实践》中提到过前向网络,这里不复制了。
建议大家也复习一下《高等数学》,挺有用的。
进入正题…之前
我们需要再下一个库,方便我们下载数据集:
pip install download -i https://pypi.douban.com/simple/
以后用到pip安装时就不多说pypi源了,方便大家直接下载。
# 从开源数据集下载
from download import download
# 定义url地址
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip"
# 下载并解压
path = download(url, "./", kind="zip", replace=True)
我们还需要一个解析该文件的库,mindspore提供了这个功能:
from mindspore.dataset import MnistDataset
然后:
from mindspore.dataset import MnistDataset
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
就可以获得数据集对象了。
分析数据
这个数据集里有什么?我们可以看见吗?
type(train_dataset)
mindspore.dataset.engine.datasets_vision.MnistDataset
我们可以发现,这是一个 MnistDataset 的类型,我们可以看一下里面的行数:
train_dataset.get_col_names()
['image', 'label']
可见有一个 图片 与 标签。但是这些图片可能不是我们想要的,我们需要预处理一下。
预处理
预处理可以使用MindSpore提供的api。
from mindspore.dataset import vision, transforms
为了方便我们理解,可以把这个处理封装成函数:
import mindspore
def datapipe(dataset, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
先看,datapipe中传入了 数据集 与 batch大小 。 batch 指的是一组数据的大小,为什么这么说呢?
在训练网络时,我们不可能一下子训练完,这是要花很大的代价的,就把数据集一个一个分割,就可以很快的训练完。
其中 image_transforms 是图像转化的操作,label_transform 是标签转化的操作。
先看 image_transforms ,其中有 Rescale(rescale, shift):
基于给定的缩放和平移因子调整图像的像素大小。输出图像的像素大小为:$ output = image * rescale + shift $。
这里呢,就是要将0~255的rgb压缩为0~1之间,为下文铺垫。
Normalize(mean, std, is_hwc=True):
根据均值和标准差对输入图像进行归一化。
此处理将使用以下公式对输入图像进行归一化:图像的每个通道将根据mean和std(max-min)进行调整,计算公式为 o u t p u t c = ( i n p u t c − m e a n c m a x c − m i n c ) output_{c} = (input_{c} - \frac{mean_{c}}{max_{c}-min_{c}}) outputc=(inputc−maxc−mincmeanc),其中 c c c代表通道索引。
上文中压缩至0~1,是为了在这里归一后压缩至-0.5~0.5,计算机喜欢这样的数据。
0.1307和0.3081是mnist数据集的均值和标准差,因为mnist数据值都是灰度图,所以图像的通道数只有一个,因此均值和标准差各一个。所以说,这个是自己算的。
HWC2CHW()
将输入图像的shape从
一个图片其实是一个三维数组,长宽是二维,哪什么是第三维呢?
对了,是颜色。三色rgb是三个维度。上文中的C是通道(维度,也就是1,彩色图片是3)数,H是高度,W是宽度。下面这句话引用自知乎【pytorch】transforms.ToTorch要把(H,W,C)的矩阵转为(C,H,W)?,虽然是讲pytorch的,但是也很有帮助:
pytorch选择设计成chw而不是hwc(毕竟传统的读图片的函数opencv的cv2.imread或者sklearn的imread都是读成hwc的格式的)这点确实比较令初学者困惑。个人感觉是因为pytorch做矩阵加减乘除以及卷积等运算是需要调用cuda和cudnn的函数的,由于cuda和cudnn涉及到图片操作的都是和卷积相关的,而内部做卷积运算的加速设计成chw在操作上会比hwc处理起来更容易,更快;而这些接口都设成成chw格式了,故而pytorch为了方便起见也设计成chw格式了。因为pytorch很多函数都是设计成假设你的输入是 (c,h,w)的格式,当然你如果不嫌麻烦的话可以每次要用这些函数的时候转成chw格式,但我想这会比你输入的时候就转成chw要麻烦很多。
Mindspore大概也如此。
好了,图片处理讲完了,现在讲 label_transform:
TypeCast(data_type)
将输入的Tensor转换为指定的数据类型。
没有为什么,mindspore.int32好算呗。
不过这里就要引用 mindspore 了。所以 import mindspore。
后面进行map变换并指定变换的是哪一个——前面输出过了,image与label。
最后 batch 一下分组。
全部代码:
from mindspore.dataset import vision, transforms
import mindspore
def datapipe(dataset, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
# map转换和批处理数据集
train_dataset = datapipe(train_dataset, 64)
test_dataset = datapipe(test_dataset, 64)
看看数据集
使用 create_tuple_iterator 或 create_dict_iterator 对数据集进行迭代。这里我说明 create_dict_iterator :创建字典迭代:
for data in test_dataset.create_dict_iterator():
print(f"Shape of image [N, C, H, W]: {data['image'].shape} {data['image'].dtype}")
print(f"Shape of label: {data['label'].shape} {data['label'].dtype}")
break
Shape of image [N, C, H, W]: (64, 1, 28, 28) Float32
Shape of label: (64,) Int32
当然我们也可以使用next获取:
dit = next(test_dataset.create_dict_iterator())
print(f"Shape of image [N, C, H, W]: {dit['image'].shape} {dit['image'].dtype}")
print(f"Shape of label: {dit['label'].shape} {dit['label'].dtype}")
同时,我们也输出一下我们的图片。
我们需要安装一个库:
pip3 install -i https://pypi.doubanio.com/simple/ matplotlib
先把数据集转换为numpy类型。
import numpy
image = dit['image'].asnumpy()
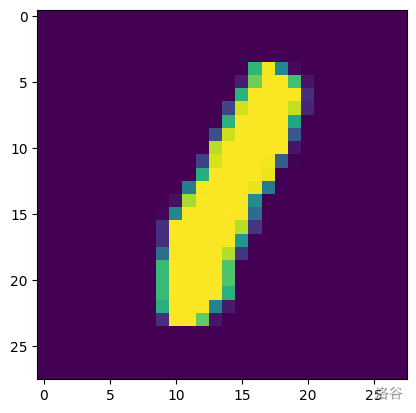
转换后再用plt库显示图片:
import matplotlib.pyplot as plt
plt.imshow(image[0][0]) # 显示图片第0张第0维
补充,显示图像前可以运行以下命令:
%matplotlib notebook
注意,是在notebook里运行,不是在cmd里运行。
在开头加上可以在jupyter notebook行内形成交互式的图表。
%matplotlib inline
开头加上可以显示图像,但无交互功能。
再查看label,输出:
label[0]
1
可以发现和上面图片一致,无误。
定义模型
代码:
from mindspore import nn
# 定义模型
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
nn是mindspore的网络构建库。我们先调用 super().__init__() 调用自己的父类的初始化方法。再看其中的 self.flatten,这是一个“展开”层(降维函数),用一个形象的比喻——二向箔。由我最上面的图:
可见边边都是 x 1 x_1 x1 、 x 2 x_2 x2 、 …… 、 x n x_n xn 的一维“数组”,那么我们的“二维”图片就要通过“二向箔”转换为 “一维”。
self.dense_relu_sequential 中定义了一系列的Dense层与Relu层。
- Dense——全连接层:
全连接?什么意思?
懂了吧,还是这张图。这种就是全连接层。
第一个全连接层是 nn.Dense(28*28, 512) 将28*28的图片转换为512长的隐藏层。
- ReLU——激活函数:
在大脑中,我们的神经会受一些数据影响,也会不理一些数据。ReLU模拟了这种情况。当传入的数据小于0,则返回0,否则返回自身。即:
R e L U ( x ) = m a x ( x , 0 ) ReLU(x)=max(x,0) ReLU(x)=max(x,0)

在最后,Dense(512, 10) 把图像转换为10个维度,分别是 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 0,1,2,3,4,5,6,7,8,9 0,1,2,3,4,5,6,7,8,9 的概率。
nn.SequentialCell:
构造Cell顺序容器。
SequentialCell将按照传入List的顺序依次将Cell添加。
现在我们用 model 调用我们的函数,并输出:
model = Network()
model
Network<
(flatten): Flatten<>
(dense_relu_sequential): SequentialCell<
(0): Dense
(1): ReLU<>
(2): Dense
(3): ReLU<>
(4): Dense
>
>
我们可以看到我们模型的内容。
训练模型
终于到这个时刻了!
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
我们需要知道损失函数是什么:
每次训练肯定有误差,而我们需要知道误差在哪里。这里提供几个损失函数:(以下定义预测值为 y y y,真实值为 y ~ \tilde{y} y~)
- 均方误差损失函数(MSE)
L = ( y ~ − y ) 2 \mathcal{L}=(\tilde{y}-y)^2 L=(y~−y)2
- 均方根误差损失函数(RMSE)
L = ( y ~ − y ) 2 \mathcal{L}=\sqrt{(\tilde{y}-y)^2} L=(y~−y)2
- 平均绝对误差损失函数(MAE)
L = ∣ y ~ − y ∣ \mathcal{L}=\lvert\tilde{y}-y\rvert L=∣y~−y∣
好了,我们这里使用的是多分类交叉熵损失函数。
loss_fn = nn.CrossEntropyLoss()
SGD是随机梯度下降:
梯度下降的一个直观的解释:比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。 这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
对于MSE,我们的函数为:
J ( θ ) = 1 m ∑ i = 1 m ( θ x i − y i ) 2 \mathcal{J(\theta)}=\frac{1}{m} \sum_{i=1}^{m} (\theta x_i-y_i)^2 J(θ)=m1i=1∑m(θxi−yi)2
我们的高等数学这时就起作用了。我们知道
d L d w = d L d y d y d w \frac{dL}{dw} = \frac{dL}{dy}\frac{dy}{dw} dwdL=dydLdwdy
这是我们的链式法则,求导后,我们知道:
d y d w = d ( w x + b ) d w = x \frac{dy}{dw} = \frac{d(wx+b)}{dw} = x dwdy=dwd(wx+b)=x
d L d y = d ( y ~ − y ) 2 d y = ( y ~ − y ) \frac{dL}{dy} = \frac{d(\tilde{y}-y)^2}{dy} = (\tilde{y}-y) dydL=dyd(y~−y)2=(y~−y)
得
d L d w = x ( y ~ − y ) \frac{dL}{dw} = x(\tilde{y}-y) dwdL=x(y~−y)
这样就可以求了。
随机梯度下降算法的原理如下:
w t + 1 = w t − η 1 n ∑ x ∈ B ∇ l ( x , w t ) w_{t+1}=w_{t}-\eta \frac{1}{n} \sum_{x \in \mathcal{B}} \nabla l\left(x, w_{t}\right) wt+1=wt−ηn1x∈B∑∇l(x,wt)
公式中, n n n是批量大小(batch size), η η η是学习率(learning rate)。另外, w t w_{t} wt为训练轮次 t t t中的权重参数, ∇ l \nabla l ∇l为损失函数的导数。除了梯度本身,这两个因子直接决定了模型的权重更新,从优化本身来看,它们是影响模型性能收敛最重要的参数。
model.trainable_params()是模型每一层的参数
optimizer = nn.SGD(model.trainable_params(), 1e-2)
官网教程:
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
参数优化:将梯度更新到参数上。
MindSpore使用函数式自动微分机制,因此针对上述步骤需要实现:
正向计算函数定义。
通过函数变换获得梯度计算函数。
训练函数定义,执行正向计算、反向传播和参数优化。
以及官网的代码:
from mindspore import ops
def train(model, dataset, loss_fn, optimizer):
# 前向传播
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# 生成求导函数
grad_fn = ops.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# 进行一次训练
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
loss = ops.depend(loss, optimizer(grads))
return loss
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
我们通过前向函数 forward_fn 得到模型结果。
grad_fn梯度函数。这里需要讲一讲。
value_and_grad(fn, grad_position=0, weights=None, has_aux=False)
生成求导函数,用于计算给定函数的正向计算结果和梯度。
函数求导包含以下三种场景:
对输入求导,此时 grad_position 非None,而 weights 是None;
对网络变量求导,此时 grad_position 是None,而 weights 非None;
同时对输入和网络变量求导,此时 grad_position 和 weights 都非None。
可见这里是对网络变量求导。因为计算完成后才能return,防止return无意义结果,需要用loss = ops.depend(loss, optimizer(grads))处理顺序关系。
grad 和 value_and_grad 提供 has_aux 参数,当其设置为 True 时,可以自动实现前文手动添加 stop_gradient 的功能,满足返回辅助数据的同时不影响梯度计算的效果。
系列预告: stop_gradient 是什么?
注意做单元测试时,需要给Cell打训练或推理的标签,PyTorch 训练 .train(),推理.eval(),MindSpore训练.set_train(),推理.set_train(False)
enumerate 是python关键字,enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
for i, element in enumerate(seq):
print(i, element)
0 one
1 two
2 three
除训练外,我们定义测试函数,用来评估模型的性能。
def test(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
训练
训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。
epochs = 3
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(model, train_dataset, loss_fn, optimizer)
test(model, test_dataset, loss_fn)
print("Done!")
运行后:
Epoch 1
-------------------------------
loss: 2.302499 [ 0/938]
loss: 2.287828 [100/938]
loss: 2.260857 [200/938]
loss: 2.124385 [300/938]
loss: 1.817491 [400/938]
loss: 1.361336 [500/938]
loss: 0.904153 [600/938]
loss: 0.659850 [700/938]
loss: 0.810218 [800/938]
loss: 0.471213 [900/938]
Test:
Accuracy: 85.3%, Avg loss: 0.515648
Epoch 2
-------------------------------
loss: 0.477927 [ 0/938]
loss: 0.609416 [100/938]
loss: 0.373210 [200/938]
loss: 0.396753 [300/938]
loss: 0.342351 [400/938]
loss: 0.666409 [500/938]
loss: 0.307072 [600/938]
loss: 0.434895 [700/938]
loss: 0.498040 [800/938]
loss: 0.235593 [900/938]
Test:
Accuracy: 90.2%, Avg loss: 0.333401
Epoch 3
-------------------------------
loss: 0.325658 [ 0/938]
loss: 0.238063 [100/938]
loss: 0.211704 [200/938]
loss: 0.379786 [300/938]
loss: 0.323287 [400/938]
loss: 0.435941 [500/938]
loss: 0.577042 [600/938]
loss: 0.426509 [700/938]
loss: 0.215510 [800/938]
loss: 0.403007 [900/938]
Test:
Accuracy: 91.9%, Avg loss: 0.277796
Done!
可见准确度越来越高,损失越来越低。
保存模型
模型训练完成后,需要将其参数进行保存。
# 保存模型
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")
Saved Model to model.ckpt
加载模型
加载保存的权重分为两步:
重新实例化模型对象,构造模型。
加载模型参数,并将其加载至模型上。
# 定义模型
model = Network()
# 加载模型
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)
[]
- param_not_load是未被加载的参数列表,为空时代表所有参数均加载成功。
加载后的模型可以直接用于预测推理。
model.set_train(False)
for data, label in test_dataset:
pred = model(data)
predicted = pred.argmax(1)
print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"')
break
Predicted: "Tensor(shape=[10], dtype=Int32, value= [3, 9, 6, 1, 6, 7, 4, 5, 2, 2])
总之,多打,多练,多查。