【论文精度】AutoBERT-Zero (使用NAS搜索预训练语言模型)
AutoBERT-Zero
论文地址: https://arxiv.org/pdf/2107.07445.pdf

Abstract
基于 Transformer 的预训练模型,如 BERT 在很多 NLP 任务中取得了良好的效果,然而,传统范式通过纯堆叠人工设计的全局自注意层来构建主干,引入了归纳偏置(inductive bias),陷入局部最优,从而影响模型效果。
论文的研究点:
- 首次尝试在一个包含最基本操作的灵活搜索空间上自动发现新的预训练语言模型主干。具体来说,提出了一个设计良好的搜索空间,(i)在层内层次包含原始数学操作,以探索新的注意力结构;(ii)利用卷积块作为层间层次注意的补充,以更好地学习局部依赖。
- 为了提高神经架构搜索的效率,提出了一种**操作优先级的神经架构搜索(operation-priority neural architecture search, OP-NAS)**算法,对候选模型的搜索算法和评估过程进行了优化。具体来说,提出了Operation-priority(OP)进化策略,通过平衡探索和开发来促进模型搜索。
- 设计了一种双分支权重共享(BIWS)训练策略,用于快速模型评估。
实验结果:所提出的架构(AutoBERT-Zero)在各种下游任务上的性能都明显优于BERT及其不同容量的模型变体,证明了该架构具有迁移和扩展的能力。值得注意的是,AutoBERT-Zero-base比RoBERTa-base(使用更多的数据)和BERT-large(使用更大的模型大小)在GLUE测试集上的得分分别高出2.4和1.4.
1. Introduction
基于transformer的自注意力结构的强大能力,各种预训练语言模型在各种NLP任务上取得了很好的性能,传统范式通过堆叠固定的人工设计的自注意力层来构建主干,然而最近许多工作指出自注意力结构的设计并不是最优的,其归纳偏置限制了其性能和效率,特别地, (Dong et al. 2021)发现重复堆叠自注意力会导致“token 一致性”问题,即不同的token被映射到相似的潜在表示,尽管有提出说skip connection与multi-layer perceptions缓解了这一问题,但是问题其实还是存在的;另一项工作发现共享query与key的权重并不影响模型的性能,这表明自注意力结构中存在冗余参数;此外,ConvBERT表明,卷积等局部操作有助于更好地学习自然语言中固有的局部依赖关系。
使用NAS来设计PLM骨干结构的相关工作有:AdaBERT/DynaBERT使用NAS将全尺寸BERT压缩为小模型;Evolutionary Transformer在特定的下游任务上搜索架构。而AdaBER与ET中的架构是特定与任务的,这些模型并不适用于一般的NLP任务;同时DynaBERT与ET的搜索模型仍然是基于transformer的,没有探索更强大的注意力结构。而在该论文之前使用NAS从头发现一个新的通用PLM骨干还没有进行过研究。
**本文目标是通过灵活的搜索空间中发现新的注意力结构和整个骨干结构来探索强大的PLM骨干。**具体来说,设计了层内和层间搜索空间,提供了各种候选架构,以防止传统transformer中的归纳偏置。具有很少约束的层内搜索空间能够找到新颖的自注意力机制,其中包含各种原始数学运算,以构造具有可变路径长度和灵活输入节点的计算图;层间搜索空间在骨干层上包含全局(自注意力)和局部(卷积)操作,这些在学习不同层的全局和局部依赖关系方面提供了灵活性。
由于预训练PLM非常耗时,因此PLM NAS的计算负担比CV任务中使用NAS要大得多,特别是在搜索空间极其巨大的情况下,因此如何提高NAS算法的速度和存储效率至关重要。为此,本文提出一种操作优先级神经架构搜索(operation-priority neural architecture search, OP-NAS),搜索阶段采用操作优先级进化策略,该策略利用计算路径中每个位置操作的先验信息,在变异新架构时灵活平衡探索和利用,从而逃脱局部最优,加快搜索速度。为了便于模型评估,设计了双分支权重共享(BIWS)训练策略,该策略引入了一个超网来跟踪每层注意力结构和卷积块的权重,候选架构在评估期间使用从超网中提取的权重进行初始化,以防止重复的预训练。
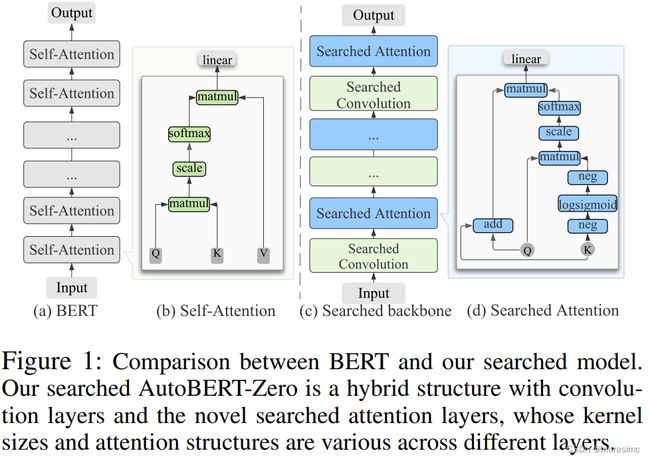
在广泛使用的NLU与QA基准上进行了大量实验,最好的架构AutoBERT-Zero堆叠了新的搜索到的注意力结构和卷积。在常用的原始预训练任务上训练时,达到了87.7分的GLUE分数(4.1 higher than T5),始终优于当前的SOTA方法,同时需要更少的参数(52.7% fewer than T5);在GLUE测试集上比RoBERTa-base(使用更多的数据)和BERT-large(使用更大的模型大小)高出2.4分与1.4分。
论文主要贡献为:
- 第一个利用NAS为PLM自动搜索新的自注意力结构和更好的骨干结构的工作;
- 所设计的搜索空间允许在自注意力结构/输入节点/局部和全局操作的组合中灵活变化,使得派生出强大的架构成为可能;
- 所提出的OP进化算法和BIWS训练策略显著加快了模型的搜索和评估;
- 下游实验验证了AutoBERT-Zero模型的有效性和可扩展性。
2. Related Works
-
预训练语言模型(PLM):transformer范式主导了预训练语言模型的研究,BERT通过堆叠transformer的encoder在各种NLU任务中实现了SOTA性能;后来出现了多种BERT变种:
- UniLM、XLNet、ELECTRA引入了新的预训练目标;
- Synthesizer考虑使用随机矩阵来取代点积自注意力机制;
- ConvBERT用基于跨度的卷积取代了部分注意力头。
然而,除了ConvBERT与Synthesizer之外,没有其他工作去挑战纯粹的使用点积自注意力模块的transformer骨干。本论文则通过原始数学运算的组合,深入研究了一种更通用的注意力表达公式。
-
NAS:早期的NAS方法基于强化学习搜索SOTA架构,计算成本高。随后,AmoebaNet将进化算法应用于NAS,后面更多的基于EA的方法被提出,通过修改种群列表的维护方式来开发评估的候选架构;后面如DART提出了基于梯度的方法,以更高的内存消耗为代价加快模型搜索;最近,AutoML-Zero证明了使用基本数学算子可以成功开发机器学习算法。
-
NAS for PLM:尽管NAS在CV领域取得了令人满意的性能,但对于预训练的语言模型,NAS方法仅用于BERT压缩。AdaBERT首先引入了NAS,使用传统的卷积操作将BERT压缩为小模型,然而,其搜索的架构是特定与任务的,而不是一般的预训练语言模型;DynaBERT提出了一种训练方法,允许在宽度和深度方向对全尺寸的teacher BERT模型进行压缩,但是它的搜索模型仍然是transformer骨干。正交于上述方法,同时借鉴AutoML-Zero的思想,本论文设计了包含原始算子的搜索空间,并提出了新的NAS方法,为通用PLM从头开发新的注意力结构和骨干网。
3. Methods
本部分,提出了一个高效的PLM架构搜索管道,它从头开始(from scratch)演化骨干网。
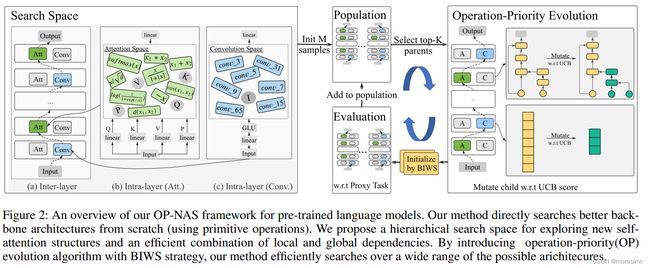
首先介绍了由粗到细的分层搜索空间(hierarchical coarse-to-fine search space),然后详细阐述了操作优先级神经架构搜索算法。
3.1 搜索空间的设计
为了发现新的自注意力结构,设计了一个双层的搜索空间和一个整体高效的PLM骨架:
-
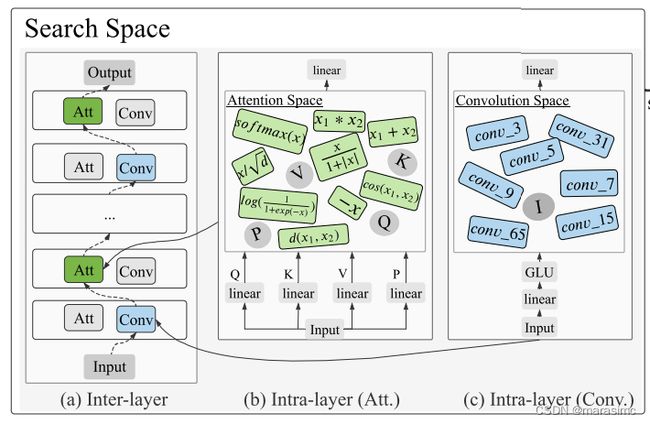
intra-layer level search space:层内级搜索空间,可以从原始操作层探索新的自注意力结构。
原始的自注意力投可以被表示为:

提出两个问题:
(a)可以使用更少的输入(原来是三个输入Q、K、V)来使transformer更高效吗?
(b)能够通过整合各种数学运算来构建一个更强大的自注意架构?
-
(1)Flexible Input Nodes(弹性输入节点):对于问题(a),允许所提出的自注意力架构有灵活的输入节点数。具体来说,添加一个输入节点P以构造一个具有四个输入节点的搜索空间,其中P通过原始输入的另一个线性变换矩阵映射得到(P = XW_P)。与原来固定3个输入节点的transformer不同,层内搜索空间允许2-4个输入节点范围。
- 问题:输入节点具体指的是哪部分,为什么原来是固定3个输入节点? —— Q/K/V
-
(2)Primitive Operations(原语操作):transformer架构的关键组件是自注意力层,它首先生成一个注意力矩阵,然后用它来计算值的加权和,注意力矩阵用来衡量query与key之间的相似度。对于问题(b),通过设计更灵活的原语操作搜索空间来实现更好的自注意结构。所涉及的原语操作搜索空间不是像原来的transformer那样只使用 与,而是包括各种单元元素的函数和二元聚合函数。如表1所示,像负、加、乘这样的操作既可以对标量输入,也可以对矩阵输入执行。

-
(3)Computation Graph with Variable Path Length(可变路径长度的计算图):如图2所示,将新的注意力结构表示为有向无环图(DAG),它将输入节点转换为张量输出,在中间图中使用多个原语算子,以更好地促进对新颖注意力结构的探索,并不将注意力计算图的路径长度进行固定。需要注意,计算图中输入特征的维数有可能在计算过程中不匹配,检查每一个操作是否合法并在早期剔除那些非法的计算图;还验证所搜索到的注意力架构的输入和输出维度是否匹配,以确保层可以正确堆叠。
-
-
inter-layer level search space:层间级搜索空间,利用全局注意力层和局部卷积,实现局部和全局依赖关系的有效组合。
针对整个骨干网的设计:
(a)通过轻量级卷积融合局部依赖;
(b)采用宏搜索空间提高设计的灵活性。
-
(1)Incorporating Local Dependencies(结合局部依赖):如(Jiang et al. 2020; Wu et al. 2018)所提出的,部分注意力头可以用局部操作替代,以更好地学习局部依赖关系并降低模型复杂度。因此本论文中,为了实现强大而高效的语言模型,考虑通过在层间搜索空间中添加局部操作来搜索一个混合骨干来取代只使用attention的架构。具体来说,将轻量级卷积作为候选操作,因为它的有效性已经在机器翻译等NLP任务中得到了证明。
为了探索不同层是否偏好不同的感受野(reception fields),进一步跨层允许不同的核大小(3 × 1, 5 × 1, 7 × 1, 9 × 1, 15 × 1, 31 × 1, 65 × 1);对于每个卷积层,输入层后边跟着一个GLU(Gated Linear Unit)层。
-
(2)Macro Search Space(宏观搜索空间):采用宏搜索空间作为骨干架构。具体来说,允许每一层都有不同的搜索自注意力结构和卷积块。先前研究采用微搜索空间(cell-based),从中搜索一个cell结构,并反复堆叠cell来构建骨干。与微搜索空间相比,本文的搜索空间要灵活得多,它有超过1020种可能的组合,因此搜索的骨干架构效率更高,可以有效地捕获全局和局部的上下文。
-
3.2 操作优先级神经架构搜索(OP-NAS)
由于在一个极其大的宏搜索空间中从零开始搜索新的架构,这涉及到层内和层间级别,我们所设计的NAS算法必须是高效的、可扩展的、计算可行的。
尽管DARTS等基于梯度的搜索算法在搜索速度上有很大的吸引力,但它们并不适合我们搜索具有更大灵活性的新颖注意力机制的需求,因为基于梯度的算法中超网络需要存储所有用于梯度更新的中间变量,这需要巨大的内存成本,而本文提出的搜索空间没有限制注意力的路径长度、允许大量可能的操作组合,因此基于梯度的搜索算法并不适用。
进化算法(EA)对搜索空间提出了更少的约束,然而传统EA在庞大的搜索空间中面临着局部最优的风险。为此,本文提出了一种操作优先级(OP)方法,通过平衡探索和利用来提高模型搜索的效率。并在此基础上,提出了双分支权重共享(Bi-branch Weight-Sharing, BIWS)训练策略,通过防止重复预训练来提高模型评估效率。具体算法如算法1所示:

-
Operation-priority Evolution Strategy:OP-NAS是一种基于进化的搜索算法。具体来说,它从随机抽样候选架构开始,在任务上对它们进行评估,得到初始种群M;然后接下来在每次迭代中,都会从种群M中选出排名前k个个体被视为父代,通过交叉变异生成子代。在层间级,主要选择self-attention结构还是卷积结构,父代遵循最原始EA执行随机变异;在层内级,主要搜索self-attention的内部结构,由于存在许多可能的操作组合,且attention路径长度不受约束,随机变异会导致在搜索注意力结构时效率非常低下。
-
为解决上述问题:在执行层内级变异时利用了每个操作的先验信息。贪心假设为:如果一个模型表现良好,那么它的架构中的操作是有前途的(promising),应该有更高的机会被采样;同时,算法也应该鼓励采样频率较低的操作,以防止陷入局部最优。因此,本文采用UCB(upper confidence bound)函数来平衡探索与利用(既要利用效果好的操作,也要充分发掘较少采样的操作),以提高搜索效率和减少需要评估的候选架构数量。
-
与先前利用采集函数(acquisition function)来衡量整个架构潜力、而变异仍然随机进行的方法相比,本文使用UCB采集函数作为衡量标准,评估操作的优先级,因此本文方法更加高效且灵活,可以利用每个操作的先验知识来生成由前途的子代。对于操作i,其UCB评分ui为:

,其中,μi为包含操作i的枚举路径的代理任务平均得分,μi越高说明操作效果越好;α是控制探索水平的超参数;Ni是操作i被采样的次数,N是历史上采样的总次数。因此任务得分高的操作和采样次数少的操作具有较高的UCB得分,更有可能被采样到。 -
与DARTS等其他架构路径长度固定的NAS方法不同,本文的注意力路径长度是灵活的,在搜索过程中允许改变,因此,在每个位置为操作分配独立的概率分布是不可行的,因为位置可能会因为路径长度的变化而发生变化。为了解决这个问题,建立了n个概率分布模型,其中n是搜索过程中采用的最长路径的长度;对于长度为k的父路径,子路径总是基于前k个分布发生变异;对于卷积层,可以直接为每一层计算不同核大小的经验概率分布。操作的概率计算为:p1,…,pn = softmax(u1,…,un),其中ui表示操作i的UCB得分。
-
-
Bi-branch Weight-Sharing (BIWS) Training Strategy:为了避免对候选模型的重复训练,设计了BIWS训练策略以加快模型评估速度。值得注意的是,即使使用非常精简的训练方案,通常从头开始训练来评估一个架构也需要200个GPU小时,而使用BIWS策略可以使得评估成本大大降低了80%。
策略的主要思想是重用上一轮搜索中训练好的模型参数。首先引入一个包含最大可能候选架构集的双分支超网,包含最大的候选架构:一个分支包含最大的注意力结构(4个输入节点);另一个分支包含最大的卷积结构(kernal size = 65 X 1),每个候选架构都由从超网的相应层和位置采集的参数进行初始化。这样,只需要经过几个epoch的微调即可获得高保真的评估结果。
为了实现可重复使用的超网,设计了以下策略:

(1)Convolution layer weight-sharing(卷积层权重共享):在整个搜索过程中保持最大卷积层(kernal size = 65 X 1)的权重,然后共享中心位置的权重,以初始化候选架构的小核。由于共享权重在他们应用于不同大小的子核中扮演不同的角色,这些子核中的权重应该具有不同的分布和大小属性,为此本文引入了核变换矩阵来适应不同大小的子核的共享权重。具体来说,在不同层的训练过程中学习不同的核转换矩阵,同时在每层内的所有通道之间共享,在每一轮训练候选模型之后,子核的权重被更新到超网中最大的核。
(2) Attention layer weight-sharing(注意力层权重共享):自注意结构的参数在于query、key、value与P的线性变换矩阵,由于在每一轮搜索中只改变了部分计算图,所以可以使用从超网对应层中提取的权重直接在子个体中初始化这些全连接层。
4. Experiments
4.1 Dataset and Setting
- Datasets and metrics(数据集和指标):首先使用大量文本数据语料库预训练骨干架构,然后针对每个特定的下游任务对模型进行微调。
- 对于预训练,使用BooksCorpus和English Wikipedia数据集;
- 对于微调和评估,使用GLUE(General Language Understanding evaluation)和SQuAD(Stanford Question Answering Dataset).
- 除非另有说明,否则使用BERT中的相同指标对下游任务进行评估,其他设置与BERT论文中的设置相同。
- Implementation Details(实现细节):使用MLM(Masked Language Model)和NSP(Next Sentence Prediction)作为预训练任务,整个过程可以分为两个阶段:NAS阶段和全训练阶段。
- 对于NAS阶段,训练基模型,其配置与BERT-base模型相同(L=12,H=768,A=12);初始种群大小M设为100,top阈值K设为5,每个父节点会变异出5个子架构;为每个候选架构训练40000个步数,然后再代理任务(GLUE)上评估这些步骤。在Nvidia V100中搜索阶段花费了大约24K GPU小时(760+个被评估的候选架构),如果只使用EA而不使用BIWS策略,估计计算时间约为182K GPU小时。
- 对于全训练阶段,为了进一步验证模型的可扩展性(scaling ability),在小模型(L=12,H=256,A=4)和大模型(L=24,H=1024,A=16)上对模型进行了全训练。具体来说,将每两个连接的层视为一个块,并通过在原始块之后插入相同的块来讲基础模型扩展为大模型。
4.2 Results and Analysis
- Structure Analysis of AutoBERT-Zero(AutoBER-Zero的结构分析):将OP-NAS的最佳搜索架构命名为AutoBERT-Zero。如图7所示,AutoBERT-Zero的混合骨干网由堆叠的conv-att块构建,高效地结合了自然语言的局部和全局依赖关系。

- 对于搜索得到的attention,在较浅的层中V与Q/K共享,而在深层则不共享(这是合理的,因为浅层只处理低级特征,而深层需要更多参数来捕获复杂的语义特征)
- 对于搜索得到的卷积,卷积层的核大小遵循一个降序(从65到3),这表明卷积层从宽到窄学习局部信息(这是合理的,因为更大的感受野可以捕获更多的信息,这有助于强调有信息的特征,同时抑制不重要特征;当较浅层高效地降低信息冗余之后,深层可以专注于重要的语义特征)
- Results on GLUE & SQuAD(GLUE和SQuAD结果):NAS阶段之后,搜索得到的模型被完全训练,并在下游任务上进行评估。
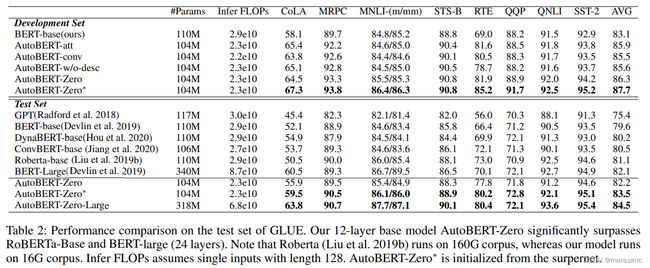
为了证明AutoBERT-Zero的优越性,对搜索得到的其他几个骨干进行了完全训练:(i)AutoBERT-w/o-desc:对于卷积层没有降低内核大小;(ii)AutoBERT-att:包含三个连续的attention层;(iii)AutoBERT-conv:包含三个连续的卷积层。
AutoBER-Zero获得了最高的GLUE评分,与BERT-base相比有显著的性能增益。
AutoBERT-Zero的性能远好于AutoBERT-att和AutoBERT-conv,这表明conv-att块能够更好地集成局部依赖和全局依赖。
AutoBERT-Zero性能优于AutoBERT-w/o-desc,表明在卷积层中采用由宽到窄的核尺寸模式有利于提高性能。
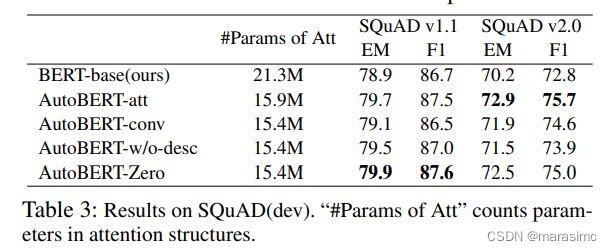
图table3所示,AutoBERT-Zero在SQuAD v1.1和v2.0上均优于BERT,表明了模型的通用性。
- Representation ability of AutoBERT-Zero(AutoBERT-Zero的表示能力):“Token uniformity”(token均匀性)损害了模型的表示能力,为了衡量"Token uniformity"的程度,使用残差相对范数(relative norm of residual)来衡量输出的秩(当残差等于0时秩等于1),并在STS-B的1280个样本上测量不同token的表示之间的平均两两余弦相似度(average pairwise cosine-similarity)。

如图5所示,纯堆叠BERT的潜在表示(latent representations)相似性高,输出的秩更接近1(残差的相对范数更接近0),表示token之间没有显著差异;另一方面,AutoBERT-Zero的输出具有相对较大的残差和较低的token相似度,表明混合骨干网有助于缓解这一问题。
- Scaling ability of AutoBERT-Zero(扩展能力):进一步将AutoBERT-Zero结构扩展到不同的容量,在大模型和小模型中都显示出强度。

如表4所示,large model在GLUE上比BERT-large高出3.5个点;小模型在纯MLM任务上显著超过了SOTA ConvBERT-small(高4.6)和BERT-small(高5.4);此外,小模型在性能和复杂性方面都大大优于GPT;
- The Efficiency of OP-NAS(OP-NAS的效率):搜索过程中,观察到通过采用OP策略,EA的探索能力大大提升,可以避免陷入局部最优(如图6所示)。

结果表明,使用OP-NAS的搜索策略比其他NAS算法有较大的性能提升。优于NAS阶段模型评估的质量极大地影响了算法的有效性,因此进一步检验评估结果的保真度,采用Kendall相关分析评估模型在NAS阶段和全训练阶段性能之间的相关性,如下图所示。由于BIWS策略的有效性,在大多数下游任务中都捕捉到了高度的相关性。

- Ablation study(消融实验):为了研究搜索得到的混合架构的优越性,评估了attention-only(将搜索得到的attention layer堆叠,即将卷积块用其后面的注意力层取代)和convolution-only(将搜索得到的convolution layer堆叠)两种变体的性能。

如表5所示,可以发现混合骨干网架构的性能都优于attention-only和convolution-only两种变体。此外,attention-only大幅超过了BERT-base,显示了searched attention结构的有效性。
5 Conclusion
本文提出了一个新颖的分层搜索空间和一个高效的NAS框架,能够自动从头发现有潜力的PLM主干。搜索得到的自注意力结构和骨干架构可以为NLP社区的模型设计带来新的思路。