机器学习模型的可解释性——LIME
以下文章摘录自:
《机器学习观止——核心原理与实践》
京东: https://item.jd.com/13166960.html
当当:http://product.dangdang.com/29218274.html
(由于博客系统问题,部分公式、图片和格式有可能存在显示问题,请参阅原书了解详情)
1.1.1 LIME

图 ‑ 什么是“解释一个模型”?
“解释一个模型”本身应该怎么理解呢?针对人类来说,它指的是提供可视化的文字或者图像来让人们可以直观地理解模型是基于什么理由给出的预测结果。更通俗一点来讲,就是模型“自证清白”的过程。
例如上图所示的范例中描述了一个用于“辅助看病”的模型向医生证实其可信的过程:模型不但要给出它的预测结果(flu),而且还同时提供了得出这一结论的依据——sneeze、headache以及no fatigue(反例)。这么做才能让医生有理由相信,它的诊断是有理有据的,从而避免“草菅人命”的悲剧发生。
如果大家做过机器学习项目,那么可能遇到过这样的困惑:明明模型在训练时的accuracy很高,但上线后的效果却大打折扣。导致这个问题的潜在因素很多,而其中有两个是我们必须要高度重视的。如下所示:
l Data Leakage
请参见Shachar Kaufman等人所著的论文《Leakage in Data Mining: Formulation, Detection, and Avoidance》
l Dataset shift
请参见MIT JOAQUIN QUIÑONERO-CANDELA等人所著的论文《DATASET SHIFT IN MACHINE LEARNING》
所谓“当局者迷”,我们总会倾向于“高估”自己的模型——而利用CNN可视化,可以在一定程度上解决或者缓解这个困惑。
当然,可视化还有其它一些好处,比如作者提到的可以帮助人们在多个模型中选择最优秀的实现。如下示意图所示:

图 ‑ 可视化助力模型择优
上面这个例子告诉我们,训练时精度更高的算法模型事实上并不一定可信。因为从可视化过程来看,它所基于的“论据”并不能有效支撑它的“论点”。
接下来我们将从多个维度来讲解LIME。
1.1.1.1 解释器的核心特征
在LIME对应的论文中,作者提出了解释器需要具备的几个核心特征,如下所示:
l interpretability
这一点是毋庸置疑的,我们在前面也已经强调过了
l local fidelity
解释器至少要是局部忠诚的,即对于被评估的样本可以很好地反映出模型的优劣
l model-agnostic
这一点不难理解,即解释器与被评估模型之间是独立的,或者说模型可以被当成黑盒来处理
l global perspective
全局视野,意即评估模型不能采用片面的指标。比如之前所举的例子中,模型在训练时的高精度未必是最好的评估指标
LIME所提供的解释器的原理就是基于上述几个核心特征展开的,我们将在下一个小节中做详细分析。
1.1.1.2 LIME原理
LIME是Local Interpretable Model-agnostic Explanations的缩写,它的关键目标就是让模型以可解释的方式呈现出来。前一小节我们讲解了它所遵循的几个原则,不难理解其实这些原则也已经体现在了它的名字中了。
我们接下来逐一分析LIME是如何践行这些原则的。
(1) Local Interpretable

图 ‑ LIME原理的直观理解
如上图所示,不同的颜色区域代表的是模型(对我们而言是黑盒的)的decision function(f)针对不同预测对象的输出结果。很明显这是一个复杂的模型,我们不能用一个linear model来轻易拟合它。但是我们却可以做到局部可解释——假设图中大的十字叉表示的是被预测对象(instance),那么通过一些扰动方法可以产生若干其它相邻的instances,并利用f来获取模型对它们的预测结果。然后我们就可以基于这些数据集得到一个locally faithful的线性模型了。
这样子讲解大家可能会觉得比较抽象,所以接下来我们以一个图像分类为例来做进一步的分析。

图 ‑ LIME针对图像分类的解释原理
假设需要被解释的对象是上面的左侧图像,而且模型给出的Top 3预测结果分别是:
tree frog
pool table
balloon
我们的问题是:在不了解模型内部实现的前提条件下,如何有效获知模型是基于图像中的哪些部位分别给出了上述3种预测结果的呢?
结合前面几个小节的分析,有一种办法看上去是既简单又有可行性的——我们如果遮掩原图中的若干部位,然后观察模型的预测结果变化,不就可以知晓不同部位对于结果值的“贡献”了吗?
其实LIME的原理说白了就这么简单。只不过真正实现起来还有不少问题要解决,例如:
l 如何切分图像
如果以像素为单位,那显然效率会非常低。所以LIME作者的做法是将具备相似颜色、纹理等特征的相邻像素点组成“块”来组成基础的处理单元,并称之为super-pixels。具体的实现算法有很多,比如quickshift, slic等等。LIME就是使用了scikit-image库提供的这些算法来实现的。这一点可以从它的开源代码(https://github.com/marcotcr/lime)中了解到:

l 如何选取不同部位的组合
显然图像的分割部位越多,那么它们的潜在组合情况自然也越多——通过穷举来完成不同部位的选择和验证理论上是可行的,但不是一个明智的选择。
LIME的作者另辟蹊径,他们通过有限次数的数据扰动(将某些部分变为灰色)来产生一个数据集,基于此数据集训练出一个简单的模型,然后再利用后者来做拟合。这样一来我们只要将具有最高权重的一些super-pixels接合起来,就可以得到可解释的结果了。
参考下面所示的流程图:
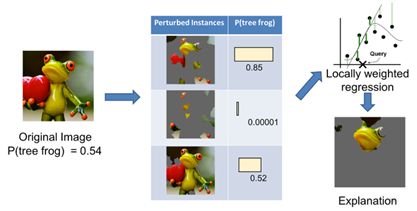
图 ‑ LIME的具体处理流程
(2) Model agnostic
根据上面的讲解,我们不难看出LIME的实现原理与具体的模型框架确实是完全解藕的。换句话说,model agnositc这一原则它自然是满足的。
而且利用LIME,我们还可以得到模型针对上述tree frog图像给出的预测结果中包含“pool table”和“balloon”的原因:

图 ‑ 模型预测原因分析
从上图中不难发现,这些支撑模型给出类别(中:pool table;右:balloon)预测结果的重要部位,确实和该类别的特征是相匹配的。
1.1.1.3 LIME实践
我们以inception v3模型为例,讲解基于LIME的可视化实践。
首先需要安装lime,参考如下命令:
pip install lime
模型采用的是keras提供的预训练的inception v3 model。
https://keras.io/applications/
使用lime来完成可视化的核心代码段如下所示:
from keras.applications import inception_v3 as inc_net
… ##导入各种依赖模块
inet_model = inc_net.InceptionV3() ##inception v3模型,keras会负责下载并加载weights
##接下来加载并预处理图像
img_path = 'asian-african-elephants.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = inet_model.predict(x) ##利用inception v3来做预测
from imagenet_decoder import imagenet_decoder
top5_result = imagenet_decoder(preds) ##将结果值与label结合起来,并打印出来
print(top5_result)
预测的top5结果如下所示:
![]()
explainer = lime_image.LimeImageExplainer()
explanation = explainer.explain_instance(x[0], inet_model.predict,
top_labels=5,
hide_color=0,
num_samples=1000) ##只需要调用一个函数就可以实现可视化
Indian_elephant =385 ##类别所对应的index值
temp, mask = explanation.get_image_and_mask(Indian_elephant, positive_only=True, num_features=5, hide_rest=True)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask)) ##针对重要部位做mask操作
plt.show()
最终效果图如下所示:

图 ‑ LIME效果图
我们还可以把模型预测某个class的pros and cons展示出来,示例代码如下:
temp, mask = explanation.get_image_and_mask(Indian_elephant, positive_only=False, num_features=10, hide_rest=False)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))

图 ‑ 构成预测结果的pros and cons
其中pros部分显示为绿色(主要集中在左上部分),cons部分则为红色。