【Pandas指南】给我十分钟,带你光速起步Pandas
10 minutes to pandas
来源:Pandas官网:https://pandas.pydata.org/docs/getting_started/intro_tutorials/index.html
笔记托管:https://gitee.com/DingJiaxiong/machine-learning-study
对Pandas的简短介绍,主要面向新用户。

文章目录
-
- 10 minutes to pandas
-
-
- 导包
- 【1】对象创建
- 【2】查看数据
- 【3】选择
- 【4】缺少数据
- 【5】操作
- 【6】合并
- 【7】分组
- 【8】重塑
- 【9】时间序列
- 【10】分类
- 【11】plotting
- 【12】导入和导出数据
- 【13】陷阱 Gotchas
-
导包
import numpy as np
import pandas as pd
【1】对象创建
通过传递值列表来创建Series,让pandas 创建默认的整数索引:
s = pd.Series([1, 3, 5, np.nan, 6, 8])
s
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
通过传递 NumPy 数组来创建DataFrame,该数组的日期时间索引使用 date_range() 和标记的列:
dates = pd.date_range("20130101", periods=6)
dates
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD"))
df
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | -1.661953 | -0.547814 | 0.802949 | 1.029237 |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 1.067645 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | -0.007140 |
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | -0.509081 |
| 2013-01-05 | 1.532215 | -0.653700 | 0.084724 | 0.819242 |
| 2013-01-06 | 0.995105 | 0.093967 | -1.393533 | -0.234949 |
通过传递可转换为类似系列的结构的对象字典来创建DataFrame:
df2 = pd.DataFrame(
{
"A": 1.0,
"B": pd.Timestamp("20130102"),
"C": pd.Series(1, index=list(range(4)), dtype="float32"),
"D": np.array([3] * 4, dtype="int32"),
"E": pd.Categorical(["test", "train", "test", "train"]),
"F": "foo",
}
)
df2
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 0 | 1.0 | 2013-01-02 | 1.0 | 3 | test | foo |
| 1 | 1.0 | 2013-01-02 | 1.0 | 3 | train | foo |
| 2 | 1.0 | 2013-01-02 | 1.0 | 3 | test | foo |
| 3 | 1.0 | 2013-01-02 | 1.0 | 3 | train | foo |
生成的DataFrame的列具有不同的 dtype:
df2.dtypes
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
如果使用的是 IPython,则会自动启用列名称(以及公共属性)的制表符补全。下面是将要完成的属性的子集:
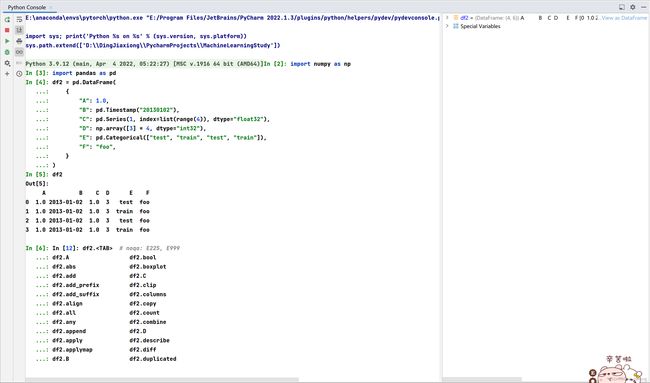
如上所示,A、B、C 和 D 列会自动按 Tab 完成。E 和 F 也在那里;为简洁起见,其余属性已被截断。
【2】查看数据
使用 DataFrame.head() 和 DataFrame.head()DataFrame.tail() 分别查看Frame的顶行和底行:
df.head()
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | -1.661953 | -0.547814 | 0.802949 | 1.029237 |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 1.067645 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | -0.007140 |
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | -0.509081 |
| 2013-01-05 | 1.532215 | -0.653700 | 0.084724 | 0.819242 |
df.tail(3)
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | -0.509081 |
| 2013-01-05 | 1.532215 | -0.653700 | 0.084724 | 0.819242 |
| 2013-01-06 | 0.995105 | 0.093967 | -1.393533 | -0.234949 |
显示 DataFrame.index DataFrame.columns:
df.index
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
df.columns
Index(['A', 'B', 'C', 'D'], dtype='object')
DataFrame.to_numpy() 给出了基础数据的 NumPy 表示形式。请注意,当您DataFrame具有具有不同数据类型的列时,这可能是一个昂贵的操作,这归结为 pandas 和 NumPy 之间的根本区别:NumPy 数组对整个数组有一个 dtype,而 pandas 数据帧每列有一个 dtype。当你调用DataFrame.to_numpy()时,pandas 会找到可以容纳数据帧中所有dtype的NumPydtype。这可能最终成为object,这需要将每个值强制转换为 Python 对象。
对于 df,我们所有浮点值和 DataFrame.to_numpy() 的数据DataFrame速度很快,不需要复制数据:
df.to_numpy()
array([[-1.66195316, -0.54781446, 0.8029485 , 1.02923736],
[ 0.25825064, 0.66194107, 0.8798367 , 1.06764452],
[ 0.37778957, -0.65456541, 0.5060444 , -0.00713967],
[-0.38581248, -1.61066891, -0.52749401, -0.50908121],
[ 1.53221498, -0.65370029, 0.08472432, 0.81924231],
[ 0.9951055 , 0.09396687, -1.39353276, -0.23494913]])
对于 df2,具有多个 dtype 的数据DataFrame DataFrame.to_numpy() 相对昂贵:
df2.to_numpy()
array([[1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'test', 'foo'],
[1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'train', 'foo'],
[1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'test', 'foo'],
[1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'train', 'foo']],
dtype=object)
【注意】DataFrame.to_numpy() 在输出中不包括索引或列标签。
describe() 显示数据的快速统计摘要:
df.describe()
| A | B | C | D | |
|---|---|---|---|---|
| count | 6.000000 | 6.000000 | 6.000000 | 6.000000 |
| mean | 0.185933 | -0.451807 | 0.058755 | 0.360826 |
| std | 1.118110 | 0.771019 | 0.881087 | 0.693339 |
| min | -1.661953 | -1.610669 | -1.393533 | -0.509081 |
| 25% | -0.224797 | -0.654349 | -0.374439 | -0.177997 |
| 50% | 0.318020 | -0.600757 | 0.295384 | 0.406051 |
| 75% | 0.840777 | -0.066478 | 0.728722 | 0.976739 |
| max | 1.532215 | 0.661941 | 0.879837 | 1.067645 |
转置数据:
df.T
| 2013-01-01 | 2013-01-02 | 2013-01-03 | 2013-01-04 | 2013-01-05 | 2013-01-06 | |
|---|---|---|---|---|---|---|
| A | -1.661953 | 0.258251 | 0.377790 | -0.385812 | 1.532215 | 0.995105 |
| B | -0.547814 | 0.661941 | -0.654565 | -1.610669 | -0.653700 | 0.093967 |
| C | 0.802949 | 0.879837 | 0.506044 | -0.527494 | 0.084724 | -1.393533 |
| D | 1.029237 | 1.067645 | -0.007140 | -0.509081 | 0.819242 | -0.234949 |
DataFrame.sort_index() 按轴排序:
df.sort_index(axis=1, ascending=False)
| D | C | B | A | |
|---|---|---|---|---|
| 2013-01-01 | 1.029237 | 0.802949 | -0.547814 | -1.661953 |
| 2013-01-02 | 1.067645 | 0.879837 | 0.661941 | 0.258251 |
| 2013-01-03 | -0.007140 | 0.506044 | -0.654565 | 0.377790 |
| 2013-01-04 | -0.509081 | -0.527494 | -1.610669 | -0.385812 |
| 2013-01-05 | 0.819242 | 0.084724 | -0.653700 | 1.532215 |
| 2013-01-06 | -0.234949 | -1.393533 | 0.093967 | 0.995105 |
DataFrame.sort_values() 按值排序:
df.sort_values(by="B")
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | -0.509081 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | -0.007140 |
| 2013-01-05 | 1.532215 | -0.653700 | 0.084724 | 0.819242 |
| 2013-01-01 | -1.661953 | -0.547814 | 0.802949 | 1.029237 |
| 2013-01-06 | 0.995105 | 0.093967 | -1.393533 | -0.234949 |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 1.067645 |
【3】选择
【注意】虽然用于选择和设置的标准Python / NumPy表达式非常直观,并且在交互式工作中派上用场,但对于生产代码,我们建议使用优化的pandas数据访问方法,DataFrame.at(),DataFrame.iat(),DataFrame.loc()和DataFrame.iat()DataFrame.at()DataFrame.iloc().
① 获得
选择单个列,这将生成一个 Series, 相当于df.A
df["A"]
2013-01-01 -1.661953
2013-01-02 0.258251
2013-01-03 0.377790
2013-01-04 -0.385812
2013-01-05 1.532215
2013-01-06 0.995105
Freq: D, Name: A, dtype: float64
通过 [] (__getitem__) 选择对行进行切片:
df[0:3]
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | -1.661953 | -0.547814 | 0.802949 | 1.029237 |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 1.067645 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | -0.007140 |
df["20130102":"20130104"]
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 1.067645 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | -0.007140 |
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | -0.509081 |
② 按标签选择
对于使用标签获取横截面:
df.loc[dates[0]]
A -1.661953
B -0.547814
C 0.802949
D 1.029237
Name: 2013-01-01 00:00:00, dtype: float64
在多轴上按标签选择:
df.loc[:, ["A", "B"]]
| A | B | |
|---|---|---|
| 2013-01-01 | -1.661953 | -0.547814 |
| 2013-01-02 | 0.258251 | 0.661941 |
| 2013-01-03 | 0.377790 | -0.654565 |
| 2013-01-04 | -0.385812 | -1.610669 |
| 2013-01-05 | 1.532215 | -0.653700 |
| 2013-01-06 | 0.995105 | 0.093967 |
显示标签切片,包括两个端点:
df.loc["20130102":"20130104", ["A", "B"]]
| A | B | |
|---|---|---|
| 2013-01-02 | 0.258251 | 0.661941 |
| 2013-01-03 | 0.377790 | -0.654565 |
| 2013-01-04 | -0.385812 | -1.610669 |
减少返回对象的尺寸:
df.loc["20130102", ["A", "B"]]
A 0.258251
B 0.661941
Name: 2013-01-02 00:00:00, dtype: float64
获取标量值:
df.loc[dates[0], "A"]
-1.6619531604669935
为了快速访问标量(相当于前面的方法):
df.at[dates[0], "A"]
-1.6619531604669935
③ 按position 选择
通过传递的整数的位置进行选择:
df.iloc[3]
A -0.385812
B -1.610669
C -0.527494
D -0.509081
Name: 2013-01-04 00:00:00, dtype: float64
通过整数切片,其行为类似于 NumPy/Python:
df.iloc[3:5, 0:2]
| A | B | |
|---|---|---|
| 2013-01-04 | -0.385812 | -1.610669 |
| 2013-01-05 | 1.532215 | -0.653700 |
通过整数位置位置列表,类似于 NumPy/Python 样式:
df.iloc[[1, 2, 4], [0, 2]]
| A | C | |
|---|---|---|
| 2013-01-02 | 0.258251 | 0.879837 |
| 2013-01-03 | 0.377790 | 0.506044 |
| 2013-01-05 | 1.532215 | 0.084724 |
对于显式切片行:
df.iloc[1:3, :]
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 1.067645 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | -0.007140 |
对于显式切片列:
df.iloc[:, 1:3]
| B | C | |
|---|---|---|
| 2013-01-01 | -0.547814 | 0.802949 |
| 2013-01-02 | 0.661941 | 0.879837 |
| 2013-01-03 | -0.654565 | 0.506044 |
| 2013-01-04 | -1.610669 | -0.527494 |
| 2013-01-05 | -0.653700 | 0.084724 |
| 2013-01-06 | 0.093967 | -1.393533 |
为了显式获取值:
df.iloc[1, 1]
0.6619410684623654
为了快速访问标量(相当于前面的方法):
df.iat[1, 1]
0.6619410684623654
④ 布尔索引
使用单个列的值选择数据:
df[df["A"] > 0]
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 1.067645 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | -0.007140 |
| 2013-01-05 | 1.532215 | -0.653700 | 0.084724 | 0.819242 |
| 2013-01-06 | 0.995105 | 0.093967 | -1.393533 | -0.234949 |
从满足布尔条件的DataFrame 中选择值:
df[df > 0]
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | NaN | NaN | 0.802949 | 1.029237 |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 1.067645 |
| 2013-01-03 | 0.377790 | NaN | 0.506044 | NaN |
| 2013-01-04 | NaN | NaN | NaN | NaN |
| 2013-01-05 | 1.532215 | NaN | 0.084724 | 0.819242 |
| 2013-01-06 | 0.995105 | 0.093967 | NaN | NaN |
使用 isin() 方法进行过滤:
df2 = df.copy()
df2
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | -1.661953 | -0.547814 | 0.802949 | 1.029237 |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 1.067645 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | -0.007140 |
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | -0.509081 |
| 2013-01-05 | 1.532215 | -0.653700 | 0.084724 | 0.819242 |
| 2013-01-06 | 0.995105 | 0.093967 | -1.393533 | -0.234949 |
df2["E"] = ["one", "one", "two", "three", "four", "three"]
df2
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 2013-01-01 | -1.661953 | -0.547814 | 0.802949 | 1.029237 | one |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 1.067645 | one |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | -0.007140 | two |
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | -0.509081 | three |
| 2013-01-05 | 1.532215 | -0.653700 | 0.084724 | 0.819242 | four |
| 2013-01-06 | 0.995105 | 0.093967 | -1.393533 | -0.234949 | three |
df2[df2["E"].isin(["two", "four"])]
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | -0.007140 | two |
| 2013-01-05 | 1.532215 | -0.653700 | 0.084724 | 0.819242 | four |
⑤ 设置
设置新列会自动按索引对齐数据:
s1 = pd.Series([1, 2, 3, 4, 5, 6], index=pd.date_range("20130102", periods=6))
s1
2013-01-02 1
2013-01-03 2
2013-01-04 3
2013-01-05 4
2013-01-06 5
2013-01-07 6
Freq: D, dtype: int64
df["F"] = s1
按标签设置值:
df.at[dates[0], "A"] = 0
按位置设置值:
df.iat[0, 1] = 0
通过使用 NumPy 数组赋值进行设置:
df.loc[:, "D"] = np.array([5] * len(df))
C:\Users\DingJiaxiong\AppData\Local\Temp\ipykernel_27496\3488720058.py:1: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
df.loc[:, "D"] = np.array([5] * len(df))
df
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 0.000000 | 0.802949 | 5 | NaN |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 5 | 1.0 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | 5 | 2.0 |
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | 5 | 3.0 |
| 2013-01-05 | 1.532215 | -0.653700 | 0.084724 | 5 | 4.0 |
| 2013-01-06 | 0.995105 | 0.093967 | -1.393533 | 5 | 5.0 |
where操作与设置:
df2 = df.copy()
df2[df2 > 0] = -df2
df2
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 0.000000 | -0.802949 | -5 | NaN |
| 2013-01-02 | -0.258251 | -0.661941 | -0.879837 | -5 | -1.0 |
| 2013-01-03 | -0.377790 | -0.654565 | -0.506044 | -5 | -2.0 |
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | -5 | -3.0 |
| 2013-01-05 | -1.532215 | -0.653700 | -0.084724 | -5 | -4.0 |
| 2013-01-06 | -0.995105 | -0.093967 | -1.393533 | -5 | -5.0 |
【4】缺少数据
Pandas 主要使用值 np.nan 来表示缺失的数据。默认情况下,它不包含在计算中。
重新索引允许您更改/添加/删除指定轴上的索引。这将返回数据的副本:
df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ["E"])
df1
| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 0.000000 | 0.802949 | 5 | NaN | NaN |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 5 | 1.0 | NaN |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | 5 | 2.0 | NaN |
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | 5 | 3.0 | NaN |
df1.loc[dates[0]:dates[1], "E"] = 1
df1
| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 0.000000 | 0.802949 | 5 | NaN | 1.0 |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 5 | 1.0 | 1.0 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | 5 | 2.0 | NaN |
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | 5 | 3.0 | NaN |
DataFrame.dropna() 删除任何缺少数据的行:
df1.dropna(how="any")
| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 5 | 1.0 | 1.0 |
DataFrame.fillna() 填充缺失的数据:
df1.fillna(value=5)
| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 0.000000 | 0.802949 | 5 | 5.0 | 1.0 |
| 2013-01-02 | 0.258251 | 0.661941 | 0.879837 | 5 | 1.0 | 1.0 |
| 2013-01-03 | 0.377790 | -0.654565 | 0.506044 | 5 | 2.0 | 5.0 |
| 2013-01-04 | -0.385812 | -1.610669 | -0.527494 | 5 | 3.0 | 5.0 |
isna() 获取值为 nan 的布尔掩码:
pd.isna(df1)
| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2013-01-01 | False | False | False | False | True | False |
| 2013-01-02 | False | False | False | False | False | False |
| 2013-01-03 | False | False | False | False | False | True |
| 2013-01-04 | False | False | False | False | False | True |
【5】操作
① 统计
操作通常排除缺失的数据。
执行描述性统计:
df.mean()
A 0.462925
B -0.360504
C 0.058755
D 5.000000
F 3.000000
dtype: float64
在另一个轴上执行相同的操作:
df.mean(1)
2013-01-01 1.450737
2013-01-02 1.560006
2013-01-03 1.445854
2013-01-04 1.095205
2013-01-05 1.992648
2013-01-06 1.939108
Freq: D, dtype: float64
使用具有不同维度且需要对齐的对象进行操作。此外,pandas 会自动沿指定维度广播:
s = pd.Series([1, 3, 5, np.nan, 6, 8], index=dates).shift(2)
s
2013-01-01 NaN
2013-01-02 NaN
2013-01-03 1.0
2013-01-04 3.0
2013-01-05 5.0
2013-01-06 NaN
Freq: D, dtype: float64
df.sub(s, axis="index")
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | NaN | NaN | NaN | NaN | NaN |
| 2013-01-02 | NaN | NaN | NaN | NaN | NaN |
| 2013-01-03 | -0.622210 | -1.654565 | -0.493956 | 4.0 | 1.0 |
| 2013-01-04 | -3.385812 | -4.610669 | -3.527494 | 2.0 | 0.0 |
| 2013-01-05 | -3.467785 | -5.653700 | -4.915276 | 0.0 | -1.0 |
| 2013-01-06 | NaN | NaN | NaN | NaN | NaN |
② 应用
DataFrame.apply() 将用户定义的函数应用于数据:
df.apply(np.cumsum)
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 0.000000 | 0.802949 | 5 | NaN |
| 2013-01-02 | 0.258251 | 0.661941 | 1.682785 | 10 | 1.0 |
| 2013-01-03 | 0.636040 | 0.007376 | 2.188830 | 15 | 3.0 |
| 2013-01-04 | 0.250228 | -1.603293 | 1.661336 | 20 | 6.0 |
| 2013-01-05 | 1.782443 | -2.256994 | 1.746060 | 25 | 10.0 |
| 2013-01-06 | 2.777548 | -2.163027 | 0.352527 | 30 | 15.0 |
df.apply(lambda x: x.max() - x.min())
A 1.918027
B 2.272610
C 2.273369
D 0.000000
F 4.000000
dtype: float64
③ 直方图
s = pd.Series(np.random.randint(0, 7, size=10))
s
0 1
1 1
2 2
3 3
4 2
5 4
6 3
7 5
8 2
9 5
dtype: int32
s.value_counts()
2 3
1 2
3 2
5 2
4 1
dtype: int64
④ 字符串方法
Series 在 str 属性中配备了一组字符串处理方法,可以轻松对数组的每个元素进行操作,如下面的代码片段所示。请注意,str 中的模式匹配通常默认使用正则表达式(在某些情况下总是使用它们)。
s = pd.Series(["A", "B", "C", "Aaba", "Baca", np.nan, "CABA", "dog", "cat"])
s
0 A
1 B
2 C
3 Aaba
4 Baca
5 NaN
6 CABA
7 dog
8 cat
dtype: object
s.str.lower()
0 a
1 b
2 c
3 aaba
4 baca
5 NaN
6 caba
7 dog
8 cat
dtype: object
【6】合并
① concat
pandas 提供了各种工具,用于轻松地将 Series 和数据帧对象与各种集合逻辑组合在一起,用于索引和关系代数功能,以防连接/合并类型操作。
使用 concat() 沿轴将pandas 对象连接在一起:
df = pd.DataFrame(np.random.randn(10, 4))
df
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | -1.501972 | 1.908571 | -1.827746 | -0.676275 |
| 1 | -1.501192 | -0.000630 | 0.748949 | -0.218242 |
| 2 | 0.703699 | 1.053803 | 0.414212 | -0.377126 |
| 3 | 0.036981 | 0.553182 | 0.305325 | -0.318815 |
| 4 | -0.690239 | 1.469397 | -1.428759 | -1.982591 |
| 5 | -0.007730 | 0.149848 | 1.687858 | 0.863261 |
| 6 | -0.659958 | -0.146510 | 0.261012 | -0.010747 |
| 7 | -0.078179 | 0.547765 | -0.492360 | 0.607742 |
| 8 | 0.051510 | 0.103854 | 0.769028 | -1.140059 |
| 9 | -0.170038 | -2.136560 | -0.421837 | -0.145998 |
pieces = [df[:3], df[3:7], df[7:]]
pd.concat(pieces)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | -1.501972 | 1.908571 | -1.827746 | -0.676275 |
| 1 | -1.501192 | -0.000630 | 0.748949 | -0.218242 |
| 2 | 0.703699 | 1.053803 | 0.414212 | -0.377126 |
| 3 | 0.036981 | 0.553182 | 0.305325 | -0.318815 |
| 4 | -0.690239 | 1.469397 | -1.428759 | -1.982591 |
| 5 | -0.007730 | 0.149848 | 1.687858 | 0.863261 |
| 6 | -0.659958 | -0.146510 | 0.261012 | -0.010747 |
| 7 | -0.078179 | 0.547765 | -0.492360 | 0.607742 |
| 8 | 0.051510 | 0.103854 | 0.769028 | -1.140059 |
| 9 | -0.170038 | -2.136560 | -0.421837 | -0.145998 |
【注意】向DataFrame添加列相对较快。但是,添加行需要副本,并且可能很昂贵。我们建议将预生成的记录列表传递给 DataFrame 构造函数,而不是通过迭代地向其追加记录来生成DataFrame。
② join
merge() 启用沿特定列的 SQL 样式连接类型。
left = pd.DataFrame({"key": ["foo", "foo"], "lval": [1, 2]})
left
| key | lval | |
|---|---|---|
| 0 | foo | 1 |
| 1 | foo | 2 |
right = pd.DataFrame({"key": ["foo", "foo"], "rval": [4, 5]})
right
| key | rval | |
|---|---|---|
| 0 | foo | 4 |
| 1 | foo | 5 |
pd.merge(left, right, on="key")
| key | lval | rval | |
|---|---|---|---|
| 0 | foo | 1 | 4 |
| 1 | foo | 1 | 5 |
| 2 | foo | 2 | 4 |
| 3 | foo | 2 | 5 |
另一个可以举的例子是:
left = pd.DataFrame({"key": ["foo", "bar"], "lval": [1, 2]})
left
| key | lval | |
|---|---|---|
| 0 | foo | 1 |
| 1 | bar | 2 |
right = pd.DataFrame({"key": ["foo", "bar"], "rval": [4, 5]})
right
| key | rval | |
|---|---|---|
| 0 | foo | 4 |
| 1 | bar | 5 |
pd.merge(left, right, on="key") ## 因为key不一样,牛逼牛逼
| key | lval | rval | |
|---|---|---|---|
| 0 | foo | 1 | 4 |
| 1 | bar | 2 | 5 |
【7】分组
通过“分组依据”,我们指的是涉及以下一个或多个步骤的过程:
- 根据某些条件将数据拆分为组
- 将函数独立应用于每个组
- 将结果合并到数据结构中
df = pd.DataFrame(
{
"A": ["foo", "bar", "foo", "bar", "foo", "bar", "foo", "foo"],
"B": ["one", "one", "two", "three", "two", "two", "one", "three"],
"C": np.random.randn(8),
"D": np.random.randn(8),
}
)
df
| A | B | C | D | |
|---|---|---|---|---|
| 0 | foo | one | 0.876897 | 0.354409 |
| 1 | bar | one | 0.132805 | -0.896589 |
| 2 | foo | two | 0.221896 | 0.098292 |
| 3 | bar | three | 0.216217 | 0.385754 |
| 4 | foo | two | 0.720764 | -1.409517 |
| 5 | bar | two | -0.409181 | -1.978768 |
| 6 | foo | one | 0.194605 | -0.676546 |
| 7 | foo | three | -1.992642 | -0.024417 |
分组,然后将 sum() 函数应用于生成的组:
df.groupby("A")[["C", "D"]].sum()
| C | D | |
|---|---|---|
| A | ||
| bar | -0.060160 | -2.489602 |
| foo | 0.021521 | -1.657779 |
按多列分组形成一个分层索引,我们可以再次应用 sum() 函数:
df.groupby(["A", "B"]).sum()
| C | D | ||
|---|---|---|---|
| A | B | ||
| bar | one | 0.132805 | -0.896589 |
| three | 0.216217 | 0.385754 | |
| two | -0.409181 | -1.978768 | |
| foo | one | 1.071503 | -0.322136 |
| three | -1.992642 | -0.024417 | |
| two | 0.942660 | -1.311226 |
【8】重塑
① 叠
tuples = list(
zip(
["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
["one", "two", "one", "two", "one", "two", "one", "two"],
)
)
tuples
[('bar', 'one'),
('bar', 'two'),
('baz', 'one'),
('baz', 'two'),
('foo', 'one'),
('foo', 'two'),
('qux', 'one'),
('qux', 'two')]
index = pd.MultiIndex.from_tuples(tuples, names=["first", "second"])
index
MultiIndex([('bar', 'one'),
('bar', 'two'),
('baz', 'one'),
('baz', 'two'),
('foo', 'one'),
('foo', 'two'),
('qux', 'one'),
('qux', 'two')],
names=['first', 'second'])
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=["A", "B"])
df
| A | B | ||
|---|---|---|---|
| first | second | ||
| bar | one | 0.023920 | 1.740133 |
| two | -0.005497 | -1.493211 | |
| baz | one | 0.072019 | -0.277144 |
| two | -0.803952 | -1.651290 | |
| foo | one | 0.038674 | -0.324725 |
| two | 1.867110 | -1.853248 | |
| qux | one | 0.644155 | -0.587385 |
| two | -0.804620 | 0.661867 |
df2 = df[:4]
df2
| A | B | ||
|---|---|---|---|
| first | second | ||
| bar | one | 0.023920 | 1.740133 |
| two | -0.005497 | -1.493211 | |
| baz | one | 0.072019 | -0.277144 |
| two | -0.803952 | -1.651290 |
stack() 方法“压缩” DataFrame中的一个级别:
stacked = df2.stack()
stacked
first second
bar one A 0.023920
B 1.740133
two A -0.005497
B -1.493211
baz one A 0.072019
B -0.277144
two A -0.803952
B -1.651290
dtype: float64
对于“堆叠” DataFrame或 Series(以 MultiIndex 作为index),stack() 的反向操作是 unstack()默认情况下,它取消堆栈最后一个级别:
stacked.unstack()
| A | B | ||
|---|---|---|---|
| first | second | ||
| bar | one | 0.023920 | 1.740133 |
| two | -0.005497 | -1.493211 | |
| baz | one | 0.072019 | -0.277144 |
| two | -0.803952 | -1.651290 |
stacked.unstack(1)
| second | one | two | |
|---|---|---|---|
| first | |||
| bar | A | 0.023920 | -0.005497 |
| B | 1.740133 | -1.493211 | |
| baz | A | 0.072019 | -0.803952 |
| B | -0.277144 | -1.651290 |
stacked.unstack(0)
| first | bar | baz | |
|---|---|---|---|
| second | |||
| one | A | 0.023920 | 0.072019 |
| B | 1.740133 | -0.277144 | |
| two | A | -0.005497 | -0.803952 |
| B | -1.493211 | -1.651290 |
② 数据透视表
df = pd.DataFrame(
{
"A": ["one", "one", "two", "three"] * 3,
"B": ["A", "B", "C"] * 4,
"C": ["foo", "foo", "foo", "bar", "bar", "bar"] * 2,
"D": np.random.randn(12),
"E": np.random.randn(12),
}
)
df
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | one | A | foo | -1.597460 | 0.669553 |
| 1 | one | B | foo | -0.444221 | 0.499254 |
| 2 | two | C | foo | -1.766302 | 2.171487 |
| 3 | three | A | bar | -0.157257 | -0.401207 |
| 4 | one | B | bar | 2.214681 | 1.439942 |
| 5 | one | C | bar | 0.212569 | 0.997841 |
| 6 | two | A | foo | 1.544844 | -1.171785 |
| 7 | three | B | foo | 0.551262 | -0.698599 |
| 8 | one | C | foo | 1.120333 | -1.439108 |
| 9 | one | A | bar | -0.221291 | 1.762135 |
| 10 | two | B | bar | 1.287042 | 1.470357 |
| 11 | three | C | bar | 0.830811 | 2.315429 |
pivot_table() 透视指定values、index和columns的数据DataFrame
pd.pivot_table(df, values="D", index=["A", "B"], columns=["C"])
| C | bar | foo | |
|---|---|---|---|
| A | B | ||
| one | A | -0.221291 | -1.597460 |
| B | 2.214681 | -0.444221 | |
| C | 0.212569 | 1.120333 | |
| three | A | -0.157257 | NaN |
| B | NaN | 0.551262 | |
| C | 0.830811 | NaN | |
| two | A | NaN | 1.544844 |
| B | 1.287042 | NaN | |
| C | NaN | -1.766302 |
【9】时间序列
Pandas 具有简单、强大和高效的功能,用于在变频期间执行重采样操作(例如,将二次数据转换为 5 分钟数据)。这在(但不限于)金融应用中极为常见。
rng = pd.date_range("1/1/2012", periods=100, freq="S")
rng
DatetimeIndex(['2012-01-01 00:00:00', '2012-01-01 00:00:01',
'2012-01-01 00:00:02', '2012-01-01 00:00:03',
'2012-01-01 00:00:04', '2012-01-01 00:00:05',
'2012-01-01 00:00:06', '2012-01-01 00:00:07',
'2012-01-01 00:00:08', '2012-01-01 00:00:09',
'2012-01-01 00:00:10', '2012-01-01 00:00:11',
'2012-01-01 00:00:12', '2012-01-01 00:00:13',
'2012-01-01 00:00:14', '2012-01-01 00:00:15',
'2012-01-01 00:00:16', '2012-01-01 00:00:17',
'2012-01-01 00:00:18', '2012-01-01 00:00:19',
'2012-01-01 00:00:20', '2012-01-01 00:00:21',
'2012-01-01 00:00:22', '2012-01-01 00:00:23',
'2012-01-01 00:00:24', '2012-01-01 00:00:25',
'2012-01-01 00:00:26', '2012-01-01 00:00:27',
'2012-01-01 00:00:28', '2012-01-01 00:00:29',
'2012-01-01 00:00:30', '2012-01-01 00:00:31',
'2012-01-01 00:00:32', '2012-01-01 00:00:33',
'2012-01-01 00:00:34', '2012-01-01 00:00:35',
'2012-01-01 00:00:36', '2012-01-01 00:00:37',
'2012-01-01 00:00:38', '2012-01-01 00:00:39',
'2012-01-01 00:00:40', '2012-01-01 00:00:41',
'2012-01-01 00:00:42', '2012-01-01 00:00:43',
'2012-01-01 00:00:44', '2012-01-01 00:00:45',
'2012-01-01 00:00:46', '2012-01-01 00:00:47',
'2012-01-01 00:00:48', '2012-01-01 00:00:49',
'2012-01-01 00:00:50', '2012-01-01 00:00:51',
'2012-01-01 00:00:52', '2012-01-01 00:00:53',
'2012-01-01 00:00:54', '2012-01-01 00:00:55',
'2012-01-01 00:00:56', '2012-01-01 00:00:57',
'2012-01-01 00:00:58', '2012-01-01 00:00:59',
'2012-01-01 00:01:00', '2012-01-01 00:01:01',
'2012-01-01 00:01:02', '2012-01-01 00:01:03',
'2012-01-01 00:01:04', '2012-01-01 00:01:05',
'2012-01-01 00:01:06', '2012-01-01 00:01:07',
'2012-01-01 00:01:08', '2012-01-01 00:01:09',
'2012-01-01 00:01:10', '2012-01-01 00:01:11',
'2012-01-01 00:01:12', '2012-01-01 00:01:13',
'2012-01-01 00:01:14', '2012-01-01 00:01:15',
'2012-01-01 00:01:16', '2012-01-01 00:01:17',
'2012-01-01 00:01:18', '2012-01-01 00:01:19',
'2012-01-01 00:01:20', '2012-01-01 00:01:21',
'2012-01-01 00:01:22', '2012-01-01 00:01:23',
'2012-01-01 00:01:24', '2012-01-01 00:01:25',
'2012-01-01 00:01:26', '2012-01-01 00:01:27',
'2012-01-01 00:01:28', '2012-01-01 00:01:29',
'2012-01-01 00:01:30', '2012-01-01 00:01:31',
'2012-01-01 00:01:32', '2012-01-01 00:01:33',
'2012-01-01 00:01:34', '2012-01-01 00:01:35',
'2012-01-01 00:01:36', '2012-01-01 00:01:37',
'2012-01-01 00:01:38', '2012-01-01 00:01:39'],
dtype='datetime64[ns]', freq='S')
ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
ts.resample("5Min").sum()
2012-01-01 24741
Freq: 5T, dtype: int32
Series.tz_localize() 将时间序列本地化为时区:
rng = pd.date_range("3/6/2012 00:00", periods=5, freq="D")
ts = pd.Series(np.random.randn(len(rng)), rng)
ts
2012-03-06 -0.092872
2012-03-07 0.183605
2012-03-08 -0.640347
2012-03-09 -0.247768
2012-03-10 0.792072
Freq: D, dtype: float64
ts_utc = ts.tz_localize("UTC")
ts_utc
2012-03-06 00:00:00+00:00 -0.092872
2012-03-07 00:00:00+00:00 0.183605
2012-03-08 00:00:00+00:00 -0.640347
2012-03-09 00:00:00+00:00 -0.247768
2012-03-10 00:00:00+00:00 0.792072
Freq: D, dtype: float64
Series.tz_convert() 将时区感知时间序列转换为另一个时区:
ts_utc.tz_convert("US/Eastern")
2012-03-05 19:00:00-05:00 -0.092872
2012-03-06 19:00:00-05:00 0.183605
2012-03-07 19:00:00-05:00 -0.640347
2012-03-08 19:00:00-05:00 -0.247768
2012-03-09 19:00:00-05:00 0.792072
Freq: D, dtype: float64
在时间跨度表示之间进行转换:
rng = pd.date_range("1/1/2012", periods=5, freq="M")
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2012-01-31 0.182211
2012-02-29 -1.675358
2012-03-31 -1.003107
2012-04-30 -0.878146
2012-05-31 1.439653
Freq: M, dtype: float64
ps = ts.to_period()
ps
2012-01 0.182211
2012-02 -1.675358
2012-03 -1.003107
2012-04 -0.878146
2012-05 1.439653
Freq: M, dtype: float64
ps.to_timestamp()
2012-01-01 0.182211
2012-02-01 -1.675358
2012-03-01 -1.003107
2012-04-01 -0.878146
2012-05-01 1.439653
Freq: MS, dtype: float64
在句点和时间戳之间进行转换可以使用一些方便的算术函数。在以下示例中,我们将以 11 月结束的季度频率转换为季度结束后的月底上午 9 点:
prng = pd.period_range("1999Q1", "2000Q4", freq="Q-NOV")
prng
PeriodIndex(['1999Q1', '1999Q2', '1999Q3', '1999Q4', '2000Q1', '2000Q2',
'2000Q3', '2000Q4'],
dtype='period[Q-NOV]')
ts = pd.Series(np.random.randn(len(prng)), prng)
ts.index = (prng.asfreq("M", "e") + 1).asfreq("H", "s") + 9
ts.head()
1999-03-01 09:00 0.088378
1999-06-01 09:00 0.271346
1999-09-01 09:00 -1.074885
1999-12-01 09:00 0.097069
2000-03-01 09:00 0.799008
Freq: H, dtype: float64
【10】分类
pandas 可以在 DataFrame 中包含分类DataFrame。
df = pd.DataFrame(
{"id": [1, 2, 3, 4, 5, 6], "raw_grade": ["a", "b", "c", "a", "a", "e"]}
)
df
| id | raw_grade | |
|---|---|---|
| 0 | 1 | a |
| 1 | 2 | b |
| 2 | 3 | c |
| 3 | 4 | a |
| 4 | 5 | a |
| 5 | 6 | e |
将原始成绩转换为分类数据类型:
df["grade"] = df["raw_grade"].astype("category")
df["grade"]
0 a
1 b
2 c
3 a
4 a
5 e
Name: grade, dtype: category
Categories (4, object): ['a', 'b', 'c', 'e']
将类别重命名为更有意义的名称:
new_categories = ["very good", "good", "bad", "very bad"]
df["grade"] = df["grade"].cat.rename_categories(new_categories)
df
| id | raw_grade | grade | |
|---|---|---|---|
| 0 | 1 | a | very good |
| 1 | 2 | b | good |
| 2 | 3 | c | bad |
| 3 | 4 | a | very good |
| 4 | 5 | a | very good |
| 5 | 6 | e | very bad |
对类别重新排序并同时添加缺少的类别(默认情况下,Series.cat() 下的方法会返回一个新Series):
df["grade"] = df["grade"].cat.set_categories(
["very bad", "bad", "medium", "good", "very good"]
)
df["grade"]
0 very good
1 good
2 bad
3 very good
4 very good
5 very bad
Name: grade, dtype: category
Categories (5, object): ['very bad', 'bad', 'medium', 'good', 'very good']
排序是按类别中的顺序排序,而不是按词法顺序排序:
df.sort_values(by="grade")
| id | raw_grade | grade | |
|---|---|---|---|
| 5 | 6 | e | very bad |
| 2 | 3 | c | bad |
| 1 | 2 | b | good |
| 0 | 1 | a | very good |
| 3 | 4 | a | very good |
| 4 | 5 | a | very good |
按分类列分组还会显示空类别:
df.groupby("grade").size()
grade
very bad 1
bad 1
medium 0
good 1
very good 3
dtype: int64
【11】plotting
我们使用标准约定来引用 matplotlib API:
import matplotlib.pyplot as plt
plt.close("all")
plt.close 方法用于关闭图形窗口:
ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
ts = ts.cumsum()
ts.plot();
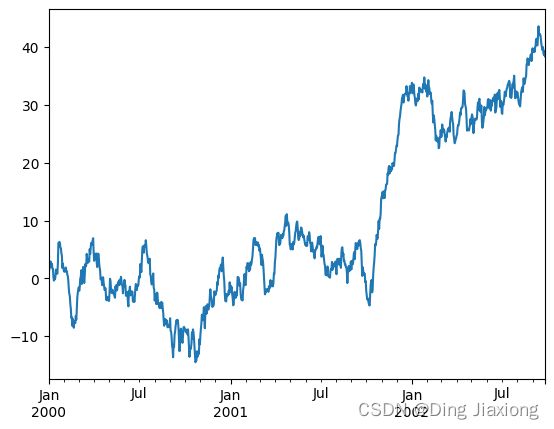
如果在 Jupyter Notebook 下运行,则绘图将显示在 plot() 上。否则,请使用matplotlib.pyplot.show显示它,或使用matplotlib.pyplot.savefig将其写入文件。
plt.show()
在DataFrame 上,plot() 方法可以方便地使用标签绘制所有列:
df = pd.DataFrame(
np.random.randn(1000, 4), index=ts.index, columns=["A", "B", "C", "D"]
)
df = df.cumsum()
plt.figure()
df.plot()
plt.legend(loc='best')
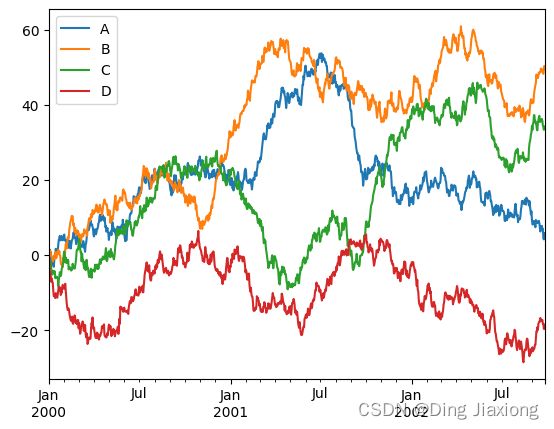
【12】导入和导出数据
① .CSV
写入 csv 文件:使用 DataFrame.to_csv()
df.to_csv("foo.csv")
从 csv 文件读取:使用 read_csv()
pd.read_csv("foo.csv")
| Unnamed: 0 | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | 2000-01-01 | 1.103927 | 0.318768 | -1.357570 | -0.738451 |
| 1 | 2000-01-02 | 0.913892 | 0.143248 | -2.171791 | -1.649351 |
| 2 | 2000-01-03 | 1.503745 | 0.430192 | -2.052008 | -4.730574 |
| 3 | 2000-01-04 | -0.808721 | 1.217011 | -2.150429 | -4.499976 |
| 4 | 2000-01-05 | 0.691127 | -0.151941 | -1.467477 | -5.704463 |
| ... | ... | ... | ... | ... | ... |
| 995 | 2002-09-22 | 7.002782 | 48.526129 | 34.526967 | -18.212873 |
| 996 | 2002-09-23 | 4.536758 | 48.246189 | 34.103467 | -18.272512 |
| 997 | 2002-09-24 | 4.212873 | 49.560632 | 33.363865 | -19.548444 |
| 998 | 2002-09-25 | 5.183976 | 50.327186 | 33.869713 | -19.583376 |
| 999 | 2002-09-26 | 5.873369 | 49.505085 | 34.220054 | -18.475834 |
1000 rows × 5 columns
② HDF5
读取和写入 HDFStores.
使用 DataFrame.to_hdf() 写入 HDF5 存储:
df.to_hdf("foo.h5", "df")
使用 read_hdf() 从 HDF5 存储读取:
pd.read_hdf("foo.h5", "df")
| A | B | C | D | |
|---|---|---|---|---|
| 2000-01-01 | 1.103927 | 0.318768 | -1.357570 | -0.738451 |
| 2000-01-02 | 0.913892 | 0.143248 | -2.171791 | -1.649351 |
| 2000-01-03 | 1.503745 | 0.430192 | -2.052008 | -4.730574 |
| 2000-01-04 | -0.808721 | 1.217011 | -2.150429 | -4.499976 |
| 2000-01-05 | 0.691127 | -0.151941 | -1.467477 | -5.704463 |
| ... | ... | ... | ... | ... |
| 2002-09-22 | 7.002782 | 48.526129 | 34.526967 | -18.212873 |
| 2002-09-23 | 4.536758 | 48.246189 | 34.103467 | -18.272512 |
| 2002-09-24 | 4.212873 | 49.560632 | 33.363865 | -19.548444 |
| 2002-09-25 | 5.183976 | 50.327186 | 33.869713 | -19.583376 |
| 2002-09-26 | 5.873369 | 49.505085 | 34.220054 | -18.475834 |
1000 rows × 4 columns
③ Excel
读取和写入 Excel.
使用 DataFrame.to_excel() 写入 Excel 文件:
df.to_excel("foo.xlsx", sheet_name="Sheet1")
使用 read_excel() 从 excel 文件中读取:
pd.read_excel("foo.xlsx", "Sheet1", index_col=None, na_values=["NA"])
| Unnamed: 0 | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | 2000-01-01 | 1.103927 | 0.318768 | -1.357570 | -0.738451 |
| 1 | 2000-01-02 | 0.913892 | 0.143248 | -2.171791 | -1.649351 |
| 2 | 2000-01-03 | 1.503745 | 0.430192 | -2.052008 | -4.730574 |
| 3 | 2000-01-04 | -0.808721 | 1.217011 | -2.150429 | -4.499976 |
| 4 | 2000-01-05 | 0.691127 | -0.151941 | -1.467477 | -5.704463 |
| ... | ... | ... | ... | ... | ... |
| 995 | 2002-09-22 | 7.002782 | 48.526129 | 34.526967 | -18.212873 |
| 996 | 2002-09-23 | 4.536758 | 48.246189 | 34.103467 | -18.272512 |
| 997 | 2002-09-24 | 4.212873 | 49.560632 | 33.363865 | -19.548444 |
| 998 | 2002-09-25 | 5.183976 | 50.327186 | 33.869713 | -19.583376 |
| 999 | 2002-09-26 | 5.873369 | 49.505085 | 34.220054 | -18.475834 |
1000 rows × 5 columns
【13】陷阱 Gotchas
如果尝试对Series或DataFrame执行布尔运算,则可能会看到如下异常:
if pd.Series([False, True, False]):
print("I was true")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[117], line 1
----> 1 if pd.Series([False, True, False]):
2 print("I was true")
File E:\anaconda\envs\pytorch\lib\site-packages\pandas\core\generic.py:1527, in NDFrame.__nonzero__(self)
1525 @final
1526 def __nonzero__(self) -> NoReturn:
-> 1527 raise ValueError(
1528 f"The truth value of a {type(self).__name__} is ambiguous. "
1529 "Use a.empty, a.bool(), a.item(), a.any() or a.all()."
1530 )
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().