自然语言处理概念及发展
自然语言处理( Natural Language Processing ,简称 NLP )是计算机科学领域以及人工智能领域的一个重要的研究方向,它研究用计算机来处理、理解以及运用人类语言(如中文、英文等),达到人与计算机之间进行有效通讯。
在一般情况下,用户可能不熟悉机器语言,所以自然语言处理技术可以帮助这样的用户使用自然语言和机器交流。从建模的角度看,为了方便计算机处理,自然语言可以被定义为一组规则或符号的集合,我们组合集合中的符号来传递各种信息。
自然语言处理研究表示语言能力、语言应用的模型,通过建立计算机框架来实现这样的语言模型,并且不断完善这样的语言模型,还需要根据该语言模型来设计各种实用的系统,并且探讨这些实用技术的评测技术。
从自然语言的角度出发,如图1所示, NLP 基本可以分为两个部分:自然语言理解以及自然语言生成。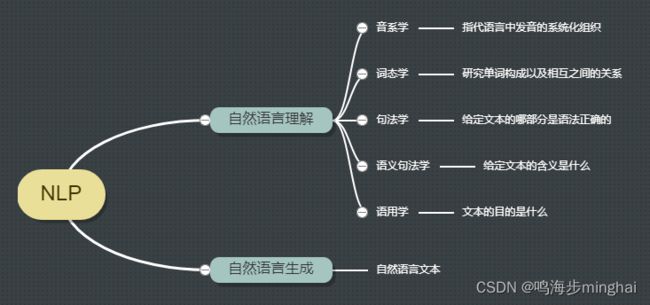
其中,自然语言理解是个综合的系统工程,它包含很多细分学科:
- 代表声音的音系学;
- 代表构词法的词态学;
- 代表语句结构的句法学;
- 代表理解的语义句法学和语用学。
自然语言生成则从结构化数据中以读取的方式自动生成文本。该过程主要包含三个阶段:
- 1、文本规划:完成结构化数据中的基础内容规划;
- 2、语句规划:从结构化数据中组合语句来表达信息流;
- 3、实现:产生语法通顺的语句来表达文本。
NLP 的研究任务
NLP 可以被应用于很多领域,大概可以总结出以下几种通用的应用:
1、机器翻译
机器翻译是自然语言处理中最为人所熟知的场景,主要研究计算机具备将一种语言翻译成另一种语言的能力。国内外有很多比较成熟的机器翻译产品,比如百度翻译、 Google 翻译等,还有提供支持语音输入的多国语言互译的产品(比如科大讯飞的翻译机)。
2、情感分析
情感分析主要研究计算机能够准确判断用户评论是否积极。情感分析在一些评论网站比较有用,比如某餐饮网站的评论中会有非常多客人的评价,如果一眼扫过去满眼都是又贵又难吃,那谁还想去呢?另外有些商家为了获取大量的客户不惜雇佣水军灌水,那就可以通过自然语言处理来做水军识别。此外,情感分析可以用来分析用户的评价是积极的还是消极的。
3、智能问答
智慧问答主要关注于计算机能否正确回答输入的问题。智能问答在一些电商网站有非常实际的价值,比如代替人工充当客服角色,有很多基本而且重复的问题,其实并不需要人工客服来解决,通过智能问答系统可以筛选掉大量重复的问题,使得人工座席能更好地服务客户。
4、文摘生成
文摘生成主要研究计算机能够准确归纳、总结并产生文本摘要的能力。文摘生成利用计算机自动地从原始文献中摘取文摘,全面准确地反映某一文献的中心内容。这个技术可以帮助人们节省大量的时间成本,而且效率更高。
5、文本分类
文本分类指的是计算机能够采集各种文章,进行主题分析,从而进行自动分类。具体是指机器对文本按照一定的分类体系自动标注类别的过程。
6、舆论分析
舆论分析主要关注计算机能够判断目前舆论的导向。可以帮助分析哪些话题是目前的热点,分析传播路径以及发展趋势,对于不好的舆论导向可以进行有效的控制。
7、知识图谱
知识图谱主要研究知识点相互连接而成的语义网络。具体是指用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
NLP 的发展历程
如图2所示,自然语言处理的发展大致经历了3个阶段:1956年以前的萌芽期、1980年~1999年的快速发展期和21世纪的突飞猛进期。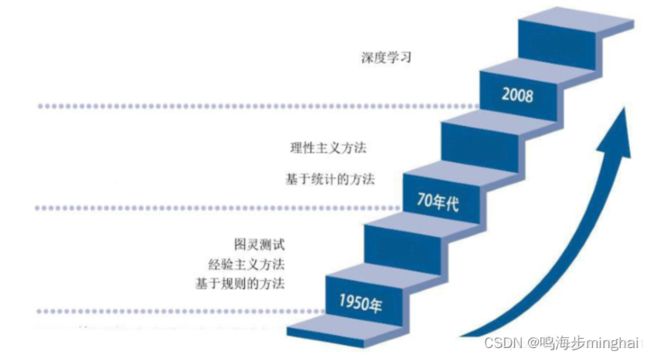
1、萌芽期(1956年以前)
1956年以前,可以看作自然语言处理的基础研究阶段。由于来自机器翻译的社会需求,这一时期进行了许多自然语言处理的基础研究,诞生了一个叫做“形式语言理论”的新领域。这一时期,虽然诸如贝叶斯方法、隐马尔可夫、最大熵、支持冋量机等经典理论和算法也均有提出,但自然语言处理领域的主流仍是基于规则的理性主义方法。
2、快速发展期
从20世纪90年代未到21世纪初,人们逐渐认识到,仅用基于规则或统计的方法是无法成功进行自然语言处理的。基于统计、基于实例和基于规则的语料库技术在这一时期开始蓬勃发展,各种处理技术开始融合自然语言处理的硏究再次繁荣。
3、突飞猛进期(2000年至今)
进入21世纪以后,自然语言处理又有了突飞猛进的变化。2006年,以 Hinton 为首的几位科学家历经近20年的努力,终于成功设计出第一个多层神经网络算法——深度学习。这是一种将原始数据通过一些简单但是非线性的模型转变成更高层次、更加抽象表达的特征学习方法,一定程度上解决了人类处理“抽象概念”这个亘古难题。目前,深度学习在机器翻译、问答系统等多个自然语言处理任务中均取得了不错的成果,相关技术也被成功应用于商业化平台中。