大数据开发超高频面试题!大厂面试必看!包含Hadoop、zookeeper、Hive、flume、kafka、Hbase、flink、spark、数仓等
大数据开发面试题
包含Hadoop、zookeeper、Hive、flume、kafka、Hbase、flink、spark、数仓等高频面试题。
数据来自原博主爬虫获取!
文章目录
- 大数据开发面试题
- **Hadoop**
-
- **一、HDFS文件写入和读取过程**
-
- **HDFS写数据流程**
- **HDFS读数据流程**
- **HDFS写数据流程**
- **HDFS读数据流程**
- **二、MapReduce工作原理**
- **Zookeeper**
-
- **Zookeeper的选举机制**
- **Hive**
-
- **Hive的内部表和外部表的区别**
- **Flume**
-
- **Flume的source、channel、sink分别都有哪些**
- **Kafka**
-
- **Kafka是如何实现高吞吐的**
- **HBase**
-
- **HBase的rowkey设计原则**
- **Spark**
-
- **Spark数据倾斜问题+解决方案**
- **说下RDD的宽依赖和窄依赖**
- **Flink**
-
- **Flink的Exactly Once语义怎么保证**
- **数据仓库**
-
- **数据仓库分层(层级划分),每层做什么**
- **Saprk Streaming和Flink的区别**
Hadoop
一、HDFS文件写入和读取过程
可灵活回答 :
1)HDFS读写原理(流程)
2)HDFS上传下载流程
3)讲讲(介绍下)HDFS
4)HDFS存储机制
回答这个问题之前,我们先来看下机架感知 机制,也就是HDFS上副本存储结点的选择。
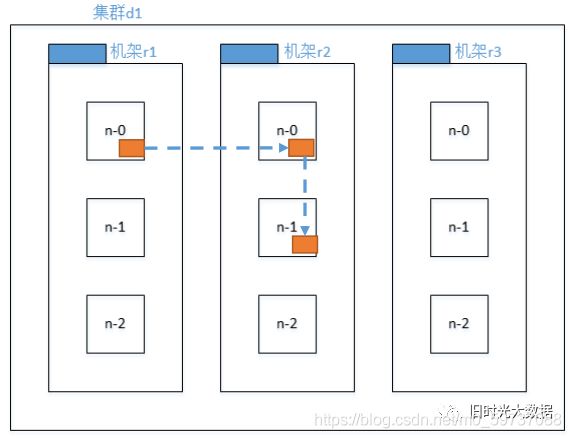
Hadoop3.x副本结点选择:
由上图可知,第一个副本在Client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本在另一个机架的随机一个节点。
第三个副本在第二个副本所在机架的随机节点。
关于HDFS读写流程,这里还是给出两个版本,有助于理解
第一个版本:简洁版
HDFS写数据流程

1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)NameNode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个block传输完成之后,客户端再次请求NameNode上传第二个block的服务器。(重复执行3-7步)。
HDFS读数据流程

1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
第二个版本:详细版,有助于理解
HDFS写数据流程
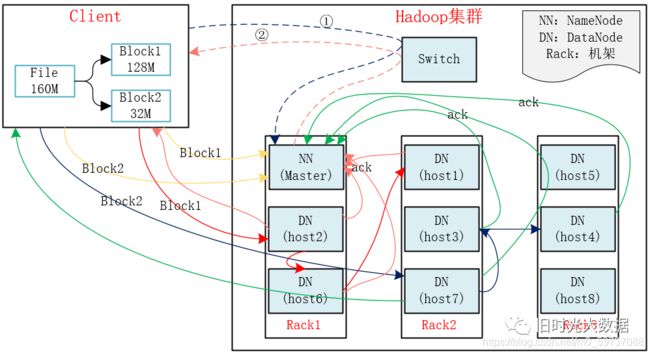
1)Client将FileA按128M分块。分成两块,block1和Block2;
2)Client向nameNode发送写数据请求,如图蓝色虚线①------>。
3)NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②------->。
Block1: host2,host1,host6
Block2: host7,host3,host4
4)client向DataNode发送block1;发送过程是以流式写入。
流式写入过程:
(1)将64M的block1按64k的package划分;
(2)然后将第一个package发送给host2;
(3)host2接收完后,将第一个package发送给host1,同时client向host2发送第二个package;
(4)host1接收完第一个package后,发送给host6,同时接收host2发来的第二个package。
(5)以此类推,如图红线实线所示,直到将block1发送完毕。
(6)host2,host1,host6向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
(7)client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就完成了。如图黄色粗实线。
(8)发送完block1后,再向host7,host3,host4发送block2,如图蓝色实线所示。
(9)发送完block2后,host7,host3,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
(10)client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。
HDFS读数据流程
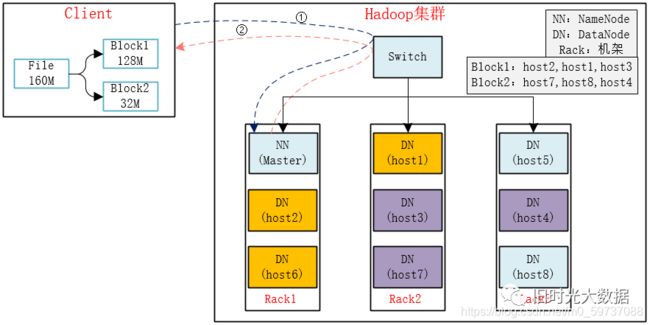
1)client向namenode发送读请求。
2)namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host6
block2:host7,host3,host4
3)block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取。
二、MapReduce工作原理
可灵活回答:
1)MapReduce执行流程
2)对MapReduce的理解
3)MapReduce过程
4)MapReduce的详细过程
5)MapTask和ReduceTask工作机制
6)MapReduce中有没有涉及到排序

1)准备一个200M的文件,submit中对原始数据进行切片;
2)客户端向YARN提交信息,YARN开启一个MrAppmaster,MrAppmaster读取客户端对应的信息,主要是job.split,然后根据切片个数(这里2个)开启对应数量的MapTask(2个);
3)MapTask通过InputFormat去读取数据(默认按行读取),K是偏移量,V是一行内容,数据读取后交给Mapper,然后根据用户的业务需求对数据进行处理;
4)数据处理之后输出到环型缓冲区(默认100M),环型缓冲区一边是存数据,一边存的是索引(描述数据的元数据)。环型缓冲区存储数据到达80%后进行反向溢写,并对数据进行分区、排序;
5)再对分区且区内有序的文件进行归并排序 ,然后存储到磁盘;
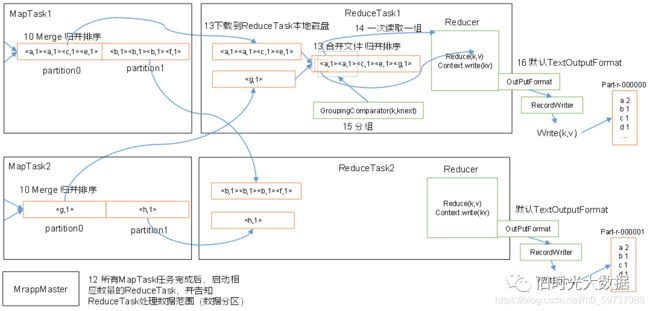
6)当所有MapTask任务完成后,启动相应数量的ReduceTask,并告知ReduceTask处理数据范围(数据分区)。注意:不是必须等到所有MapTask结束后才开始,可以自行配置。
7)ReduceTask开启后,ReduceTask主动从MapTask对应的分区拉取数据;
8)再对ReduceTask拉取过来的数据进行一个全局合并排序;
9)顺序读取数据,按key分,key相同的数据进入同一个Reducer,一次读取一组数据;
10)Reducer处理完数据,通过OutPutFormat往外写数据,形成对应文件。
简洁版:面试可手写

Zookeeper
Zookeeper的选举机制
可灵活回答:
1)Zookeeper的选举策略
2)Zookeeper的选举过程
3)Zookeeper的Leader选举是如何实现的
1)半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
2)Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
3)选举过程
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。
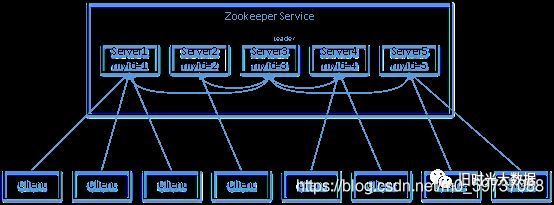
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的ID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
Hive
Hive的内部表和外部表的区别
内部表 (managed table):未被external修饰
外部表 (external table):被external修饰
区别:
1)内部表数据由Hive自身管理,外部表数据由HDFS管理;
2)内部表的数据存储位置是hive.metastore.warehouse.dir,默认位置:/user/hive/warehouse,外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
3)删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
4)对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
Flume
Flume的source、channel、sink分别都有哪些
可灵活回答:
1)Flume的source、channel、sink分别用的什么类型的?
2)Flume的Kafka sink
3)Flume分为哪几块?
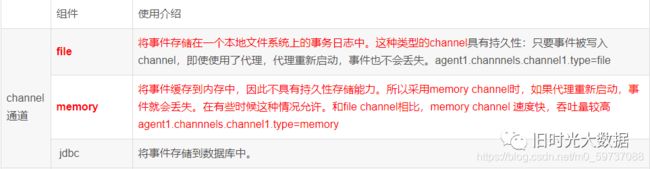
4)channel的类型

Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。
Agent主要由Source、Channel、Sink3个部分组成。
Source
Source是负责接收数据到Flume Agent的组件。

Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。

Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Kafka
Kafka是如何实现高吞吐的
可灵活回答:
1)Kafka为什么低延迟高吞吐?
2)Kafka高吞吐的原因
3)Kafka为什么高可用、高吞吐?
4)Kafka如何保证高吞吐量?
Kafka是分布式消息系统,需要处理海量的消息,Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失。
kafka主要使用了以下几个方式实现了超高的吞吐率。
1)顺序读写
kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能,顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写。
Kafka官方给出了测试数据(Raid-5,7200rpm):
顺序 I/O: 600MB/s
随机 I/O: 100KB/s
2)零拷贝
先简单了解下文件系统的操作流程,例如一个程序要把文件内容发送到网络。
这个程序是工作在用户空间,文件和网络socket属于硬件资源,两者之间有一个内核空间。
在操作系统内部,整个过程为:
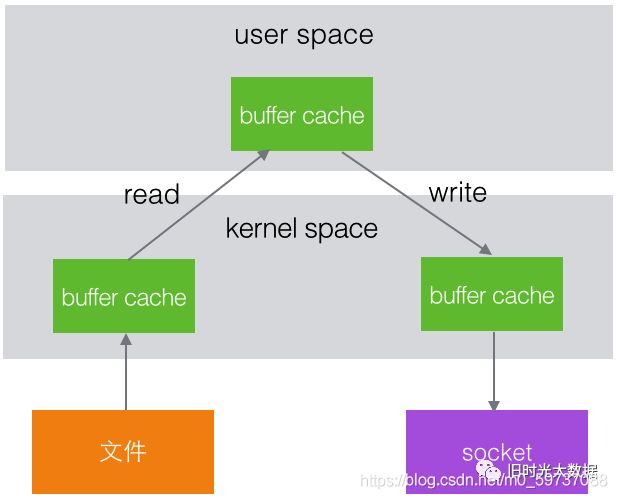
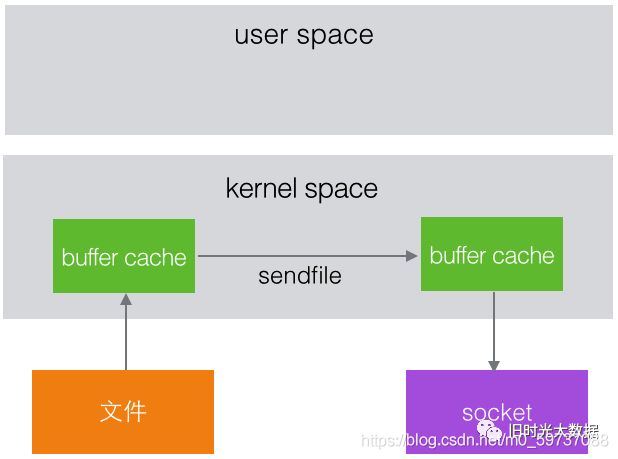
在 Linux kernel2.2 之后出现了一种叫做"零拷贝(zero-copy)"系统调用机制,就是跳过“用 户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区” 。
系统上下文切换减少为 2 次,可以提升一倍的性能。
3)文件分段
kafka的队列topic被分为了多个区partition,每个partition又分为多个段segment,所以一个队列中的消息实际上是保存在N多个片段文件中
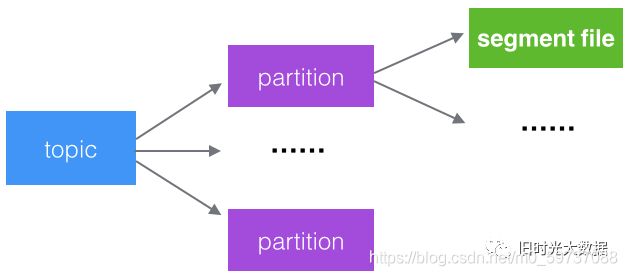
通过分段的方式,每次文件操作都是对一个小文件的操作,非常轻便,同时也增加了并 行处理能力
4)批量发送
Kafka允许进行批量发送消息,先将消息缓存在内存中,然后一次请求批量发送出去,比如可以指定缓存的消息达到某个量的时候就发出去,或者缓存了固定的时间后就发送出去 ,如100 条消息就发送,或者每5秒发送一次,这种策略将大大减少服务端的I/O次数
5)数据压缩
Kafka 还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩,压缩的好处就是减少传输的数据量,减轻对网络传输的压力,Producer压缩之后,在 Consumer需进行解压,虽然增加了CPU的工作,但在对大数据处理上,瓶颈在网络上而不是 CPU,所以这个成本很值得。
HBase
HBase的rowkey设计原则
可灵活回答:
1)HBase如何设计rowkey?
2)你HBase的rowkey为什么这么设计?有什么优缺点?
3)Hbase rowKey设置讲究
HBase中,表会被划分为1…n个Region,被托管在RegionServer中。Region二个重要的属性:StartKey与EndKey表示这个Region维护的rowKey范围,当我们要读/写数据时,如果rowKey落在某个start-end key范围内,那么就会定位到目标region并且读/写到相关的数据。
那怎么快速精准的定位到我们想要操作的数据,就在于我们的rowkey的设计了。
设计原则如下:
1、rowkey长度原则
Rowkey是一个二进制码流,Rowkey的长度被很多开发者建议说设计在10~100个字节,不过建议是越短越好,不要超过16个字节。
原因如下:
1)数据的持久化文件HFile中是按照Key Value 存储的,如果Rowkey过长比如100个字节,1000万列数据光Rowkey就要占用100*1000 万=10亿个字节,将近1G数据,这会极大影响 HFile的存储效率;
2)MemStore将缓存部分数据到内存,如果 Rowkey字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。因此Rowkey的字节长度越短越好;
3)目前操作系统是都是64位系统,内存8字节对齐。控制在16个字节,8字节的整数倍利用操作系统的最佳特性。
2、rowkey散列原则
如果Rowkey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,将会提高数据均衡分布在每个Regionserver实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个 RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别 RegionServer,降低查询效率。
3、rowkey唯一原则
必须在设计上保证其唯一性。rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
Spark
Spark数据倾斜问题+解决方案
1、数据倾斜
数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于 其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈
数据倾斜俩大直接致命后果
1)数据倾斜直接会导致一种情况:Out Of Memory
2)运行速度慢
主要是发生在Shuffle阶段。同样Key的数据条数太多了。导致了某个key(下图中的80亿条)所在的Task数 据量太大了。远远超过其他Task所处理的数据量
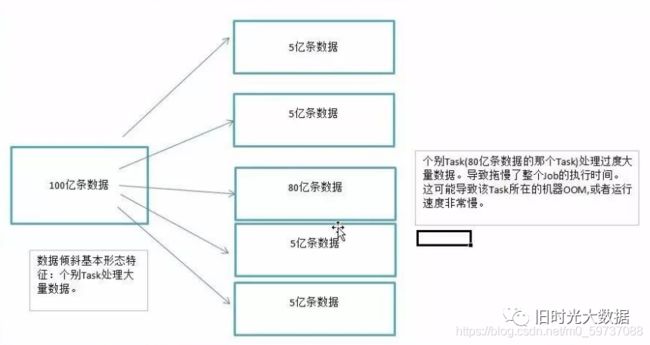
一个经验结论是:一般情况下,OOM的原因都是数据倾斜
2、如何定位数据倾斜
数据倾斜一般会发生在shuffle过程中。很大程度是使用可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。
查看任务->查看Stage->查看代码
也可从以下几种情况考虑:
1)是不是有OOM情况出现,一般是少数内存溢出的问题
2)是不是应用运行时间差异很大,总体时间很长
3)需要了解你所处理的数据Key的分布情况,如果有些Key有大量的条数,那么就要小心数据倾斜的问题
4)一般需要通过Spark Web UI和其他一些监控方式出现的异常来综合判断
5)看看代码里面是否有一些导致Shuffle的算子出现
3、数据倾斜的几种典型情况
3.1 数据源中的数据分布不均匀,Spark需要频繁交互
3.2 数据集中的不同Key由于分区方式,导致数据倾斜
3.3 JOIN操作中,一个数据集中的数据分布不均匀,另一个数据集较小(主要)
3.4 聚合操作中,数据集中的数据分布不均匀(主要)
3.5 JOIN操作中,两个数据集都比较大,其中只有几个Key的数据分布不均匀
3.6 JOIN操作中,两个数据集都比较大,有很多Key的数据分布不均匀
3.7 数据集中少数几个key数据量很大,不重要,其他数据均匀
4、数据倾斜的处理方法
4.1 数据源中的数据分布不均匀,Spark需要频繁交互
解决方案:避免数据源的数据倾斜
实现原理 :通过在Hive中对倾斜的数据进行预处理,以及在进行kafka数据分发时尽量进行平均分配。这种方案从根源上解决了数据倾斜,彻底避免了在Spark中执行shuffle类算子,那么肯定就不会有数据倾斜的问题了。
方案优点 :实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark作业的性能会大幅度提升。
方案缺点 :治标不治本,Hive或者Kafka中还是会发生数据倾斜。
适用情况 :在一些Java系统与Spark结合使用的项目中,会出现Java代码频繁调用Spark作业的场景,而且对Spark作业的执行性能要求很高,就比较适合使用这种方案。将数据倾斜提前到上游的Hive ETL,每天仅执行一次,只有那一次是比较慢的,而之后每次Java调用Spark作业时,执行速度都会很快,能够提供更好的用户体验。
总结 :前台的Java系统和Spark有很频繁的交互,这个时候如果Spark能够在最短的时间内处理数据,往往会给前端有非常好的体验。这个时候可以将数据倾斜的问题抛给数据源端,在数据源端进行数据倾斜的处理。但是这种方案没有真正的处理数据倾斜问题
4.2 数据集中的不同Key由于分区方式,导致数据倾斜
**解决方案1:**调整并行度
实现原理 :增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。
方案优点 :实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
方案缺点 :只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
实践经验 :该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万,那么无论你的task数量增加到多少,都无法处理。
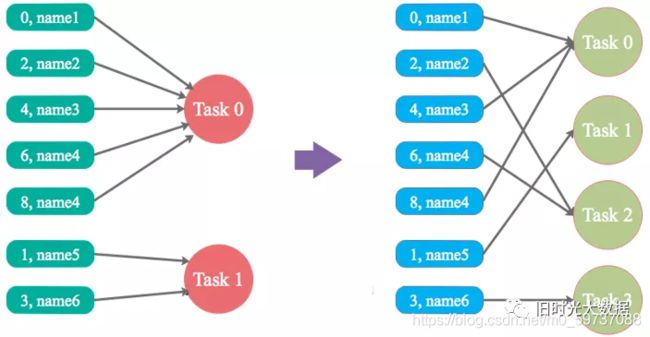
解决方案2:
自定义Partitioner(缓解数据倾斜)
适用场景 :大量不同的Key被分配到了相同的Task造成该Task数据量过大。
解决方案 :使用自定义的Partitioner实现类代替默认的HashPartitioner,尽量将所有不同的Key均匀分配到不同的Task中。
优势 :不影响原有的并行度设计。如果改变并行度,后续Stage的并行度也会默认改变,可能会影响后续Stage。
劣势 :适用场景有限,只能将不同Key分散开,对于同一Key对应数据集非常大的场景不适用。效果与调整并行度类似,只能缓解数据倾斜而不能完全消除数据倾斜。而且需要根据数据特点自定义专用的Partitioner,不够灵活。
4.3 JOIN操作中,一个数据集中的数据分布不均匀,另一个数据集较小(主要)
解决方案:
Reduce side Join转变为Map side Join
适用场景 :在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M),比较适用此方案。
实现原理 :普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。
优点 :对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
缺点 :适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。
4.4 聚合操作中,数据集中的数据分布不均匀(主要)
解决方案:两阶段聚合(局部聚合+全局聚合)
适用场景 :对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案
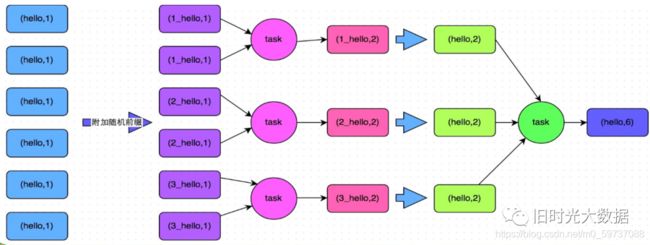
实现原理 :将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
优点 :对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
缺点 :仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案
将相同key的数据分拆处理
4.5 JOIN操作中,两个数据集都比较大,其中只有几个Key的数据分布不均匀
解决方案:为倾斜key增加随机前/后缀
适用场景 :两张表都比较大,无法使用Map侧Join。其中一个RDD有少数几个Key的数据量过大,另外一个RDD的Key分布较为均匀。
解决方案 :将有数据倾斜的RDD中倾斜Key对应的数据集单独抽取出来加上随机前缀,另外一个RDD每条数据分别与随机前缀结合形成新的RDD(笛卡尔积,相当于将其数据增到到原来的N倍,N即为随机前缀的总个数),然后将二者Join后去掉前缀。然后将不包含倾斜Key的剩余数据进行Join。最后将两次Join的结果集通过union合并,即可得到全部Join结果。
优势 :相对于Map侧Join,更能适应大数据集的Join。如果资源充足,倾斜部分数据集与非倾斜部分数据集可并行进行,效率提升明显。且只针对倾斜部分的数据做数据扩展,增加的资源消耗有限。
劣势 :如果倾斜Key非常多,则另一侧数据膨胀非常大,此方案不适用。而且此时对倾斜Key与非倾斜Key分开处理,需要扫描数据集两遍,增加了开销。
注意:具有倾斜Key的RDD数据集中,key的数量比较少
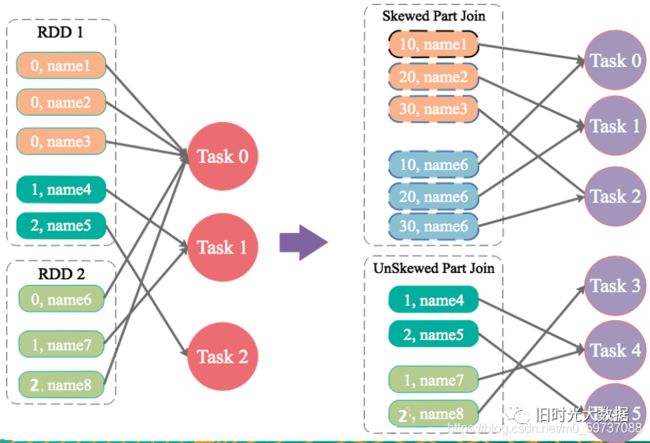
4.6 JOIN操作中,两个数据集都比较大,有很多Key的数据分布不均匀
解决方案 :随机前缀和扩容RDD进行join
适用场景 :如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没什么意义。
实现思路 :将该RDD的每条数据都打上一个n以内的随机前缀。同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个0~n的前缀。最后将两个处理后的RDD进行join即可。和上一种方案是尽量只对少数倾斜key对应的数据进行特殊处理,由于处理过程需要扩容RDD,因此上一种方案扩容RDD后对内存的占用并不大;而这一种方案是针对有大量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对内存资源要求很高。
优点 :对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
缺点 :该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个RDD进行扩容,对内存资源要求很高。
实践经验 :曾经开发一个数据需求的时候,发现一个join导致了数据倾斜。优化之前,作业的执行时间大约是60分钟左右;使用该方案优化之后,执行时间缩短到10分钟左右,性能提升了6倍。
注意 :将倾斜Key添加1-N的随机前缀,并将被Join的数据集相应的扩大N倍(需要将1-N数字添加到每一条数据上作为前缀)

4.7 数据集中少数几个key数据量很大,不重要,其他数据均匀
解决方案 :过滤少数倾斜Key
适用场景 :如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
优点 :实现简单,而且效果也很好,可以完全规避掉数据倾斜。
缺点 :适用场景不多,大多数情况下,导致倾斜的key还是很多的,并不是只有少数几个。
实践经验 :在项目中我们也采用过这种方案解决数据倾斜。有一次发现某一天Spark作业在运行的时候突然OOM了,追查之后发现,是Hive表中的某一个key在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个key之后,直接在程序中将那些key给过滤掉。
说下RDD的宽依赖和窄依赖
可灵活回答:
1)Spark的宽依赖和窄依赖,为什么要这么划分?
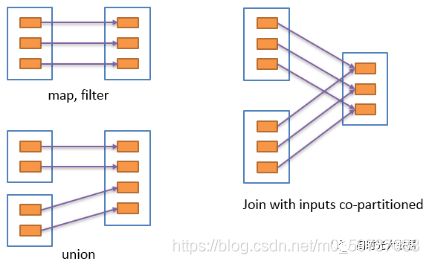
RDD和它依赖的parent RDD(s)的关系有两种不同的类型,窄依赖(narrow dependency)和宽依赖(wide dependency)
1)窄依赖指的是每一个parent RDD的Partition最多被子RDD的一个Partition使用
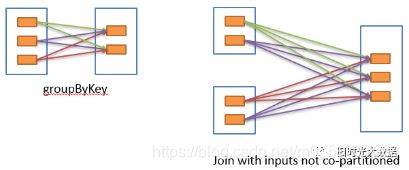
2)宽依赖指的是多个子RDD的Partition会依赖同一个parent RDD的Partition
Flink
Flink的Exactly Once语义怎么保证
可灵活回答:
1)Flink怎么保证精准一次消费?
2)Flink如何实现Exactly Once?
3)Flink如何保证仅一次语义?
4)Flink的端到端Exactly Once?
Flink跟其他的流计算引擎相比,最突出或者做的最好的就是状态的管理。什么是状态呢?比如我们在平时的开发中,需要对数据进行count,sum,max等操作,这些中间的结果(即是状态)是需要保存的,因为要不断的更新,这些值或者变量就可以理解为是一种状态,拿读取kafka为例,我们需要记录数据读取的位置(即是偏移量),并保存offest,这时offest也可以理解为是一种状态。
Flink是怎么保证容错恢复的时候保证数据没有丢失也没有数据的冗余呢?checkpoint是使Flink 能从故障恢复的一种内部机制。检查点是 Flink 应用状态的一个一致性副本,包括了输入的读取位点。在发生故障时,Flink 通过从检查点加载应用程序状态来恢复,并从恢复的读取位点继续处理,就好像什么事情都没发生一样。Flink的状态存储在Flink的内部,这样做的好处就是不再依赖外部系统,降低了对外部系统的依赖。在Flink的内部。通过自身的进程去访问状态变量。同时会定期的做checkpoint持久化。把checkpoint存储在一个分布式的持久化系统中。如果发生故障。就会从最近的一次checkpoint中将整个流的状态进行恢复。
下面通过Flink从Kafka中获取数据,来说下怎么管理offest实现exactly-once的。
Apache Flink中实现的Kafka消费者是一个有状态的算子(operator),它集成了Flink的检查点机制,它的状态是所有Kafka分区的读取偏移量。当一个检查点被触发时,每一个分区的偏移量都被存到了这个检查点中。Flink的检查点机制保证了所有operator task的存储状态都是一致的。这里的“一致的”是什么意思呢?意思是它们存储的状态都是基于相同的输入数据。当所有的operator task成功存储了它们的状态,一个检查点才算完成。因此,当从潜在的系统故障中恢复时,系统提供了excatly-once的状态更新语义。
下面我们将一步步地介绍Apache Flink中的 Kafka消费位点是如何做检查点的。在本文的例子中,数据被存在了Flink的JobMaster中。值得注意的是,在POC或生产用例下,这些数据最好是能存到一个外部文件系统(如HDFS或S3)中。
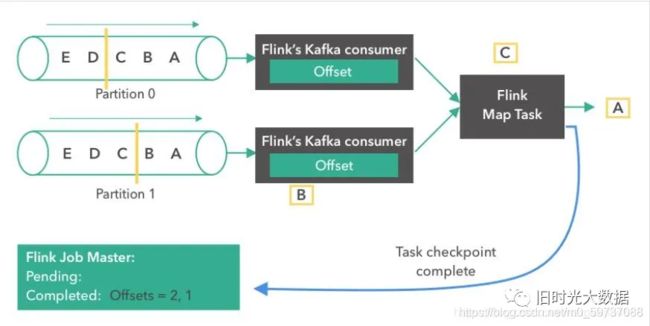
第一步: 如下所示,一个Kafka topic,有两个partition,每个partition都含有 “A”,“B”,“C”,”D”,“E”5条消息。我们将两个partition的偏移量(offset)都设置为0。
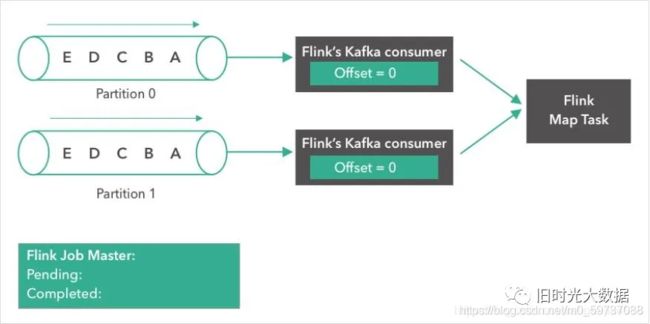
第二步: Kafka comsumer(消费者)开始从 partition 0 读取消息。消息“A”正在被处理,第一个 consumer 的 offset 变成了1。
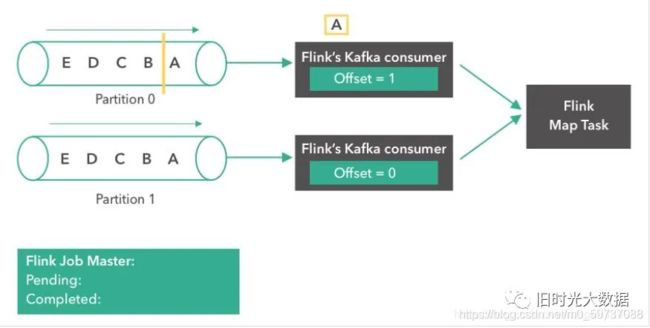
第三步: 消息“A”到达了Flink Map Task。两个 consumer都开始读取他们下一条消息(partition0读取“B”,partition1读取“A”)。各自将offset更新成2和1。同时,Flink的 JobMaster开始在source触发了一个检查点。
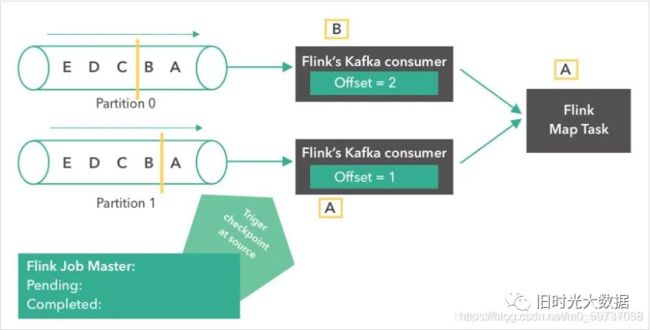
第四步: 接下来,由于source触发了检查点,Kafka consumer创建了它们状态的第一个快照(”offset = 2, 1”),并将快照存到了Flink的 JobMaster 中。Source 在消息“B”和“A”从partition 0 和 1 发出后,发了一个 checkpoint barrier。Checkopint barrier 用于各个 operator task 之间对齐检查点,保证了整个检查点的一致性。消息“A”到达了 Flink Map Task,而上面的 consumer 继续读取下一条消息(消息“C”)。

第五步:
Flink Map Task收齐了同一版本的全部 checkpoint barrier后,那么就会将它自己的状态也存储到JobMaster。同时,consumer会继续从Kafka读取消息。
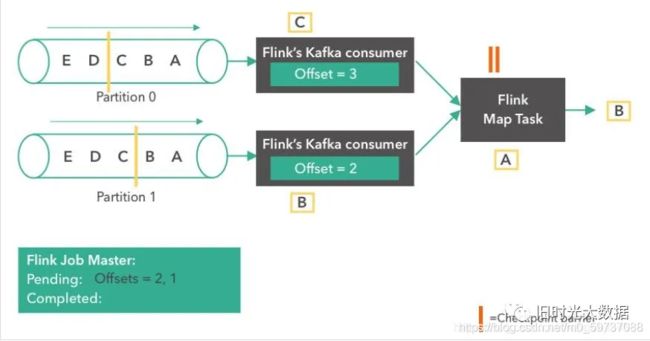
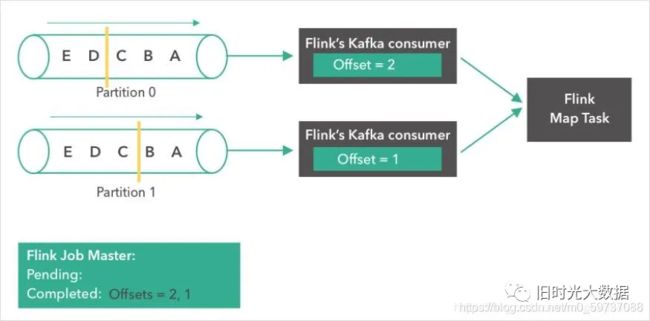
第六步: Flink Map Task完成了它自己状态的快照流程后,会向Flink JobMaster汇报它已经完成了这个checkpoint。当所有的task都报告完成了它们的状态checkpoint后,JobMaster就会将这个checkpoint标记为成功。从此刻开始,这个 checkpoint就可以用于故障恢复了。值得一提的是,Flink并不依赖Kafka offset从系统故障中恢复。
故障恢复 在发生故障时(比如,某个worker挂了),所有的operator task会被重启,而他们的状态会被重置到最近一次成功的checkpoint。Kafka source分别从offset 2和1重新开始读取消息(因为这是完成的checkpoint中存的offset)。当作业重启后,我们可以期待正常的系统操作,就好像之前没有发生故障一样。如下图所示:
Flink的checkpoint是基于Chandy-Lamport算法的分布式一致性快照,如果想更加深入的了解Flink的checkpoint可以去了解一下这个算法。
数据仓库
数据仓库分层(层级划分),每层做什么
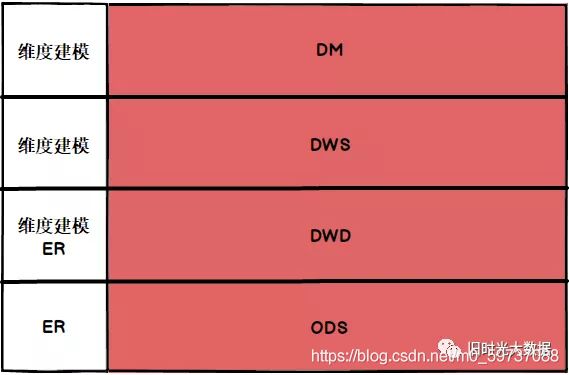
CIF 层次架构(信息工厂)通过分层将不同的建模方案引入到不同的层次中,CIF 将数据仓库分为四层,如图所示:
这里再给一张项目里面的数仓分层架构
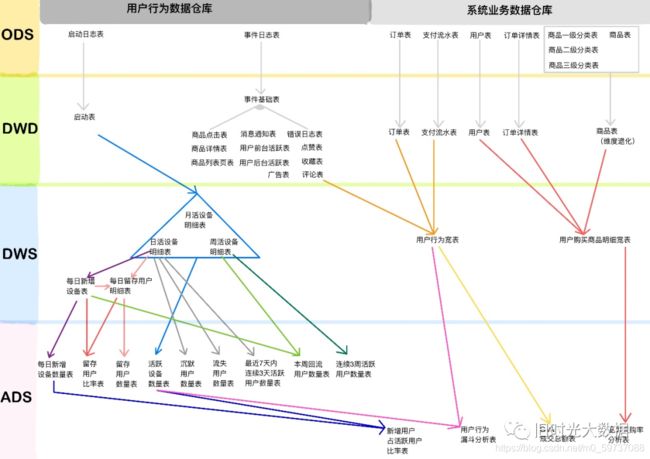
分层优点:复杂问题简单化、清晰数据结构(方便管理)、增加数据的复用性、隔离原始数据(解耦)
ODS(Operational Data Store):
操作数据存储层 ,往往是业务数据库表格的一对一映射,将业务数据库中的表格在 ODS 重新建立,数据完全一致;
DWD(Data Warehouse Detail):
数据明细层 ,在 DWD 进行数据的清洗、脱敏、统一化等操作,DWD 层的数据是干净并且具有良好一致性的数据;
DWS(Data Warehouse Service):
服务数据层(公共汇总层) ,在DWS层进行轻度汇总,为DM层中的不同主题提供公用的汇总数据;
DM(Data Market):
数据集市层 ,DM层针对不同的主题进行统计报表的生成。
其它类型
Saprk Streaming和Flink的区别
可灵活回答 :
1)Saprk和Flink的区别
2)Flink和Spark对于批处理的区别?
3)Spark Streaming相比Flink的优劣势
这个问题是一个非常宏观的问题,因为两个框架的不同点非常之多。但是在面试时有非常重要的一点一定要回答出来:Flink是标准的实时处理引擎,基于事件驱动。而Spark Streaming是微批(Micro-Batch)的模型。
下面我们就分几个方面介绍两个框架的主要区别:
1)从流处理的角度来讲 ,Spark基于微批量处理,把流数据看成是一个个小的批处理数据块分别处理,所以延迟性只能做到秒级。而Flink基于每个事件处理,每当有新的数据输入都会立刻处理,是真正的流式计算,支持毫秒级计算。由于相同的原因,Spark只支持基于时间的窗口操作(处理时间或者事件时间),而Flink支持的窗口操作则非常灵活,不仅支持时间窗口,还支持基于数据本身的窗口(另外还支持基于time、count、session,以及data-driven的窗口操作),开发者可以自由定义想要的窗口操作。
2)从SQL 功能的角度来讲 ,Spark和Flink分别提供SparkSQL和Table APl提供SQL
3)交互支持 。两者相比较,Spark对SQL支持更好,相应的优化、扩展和性能更好,而Flink在SQL支持方面还有很大提升空间。
4)从迭代计算的角度来讲 ,Spark对机器学习的支持很好,因为可以在内存中缓存中间计算结果来加速机器学习算法的运行。但是大部分机器学习算法其实是一个有环的数据流,在Spark中,却是用无环图来表示。而Flink支持在运行时间中的有环数据流,从而可以更有效的对机器学习算法进行运算。
5)从相应的生态系统角度来讲 ,Spark的社区无疑更加活跃。Spark可以说有着Apache旗下最多的开源贡献者,而且有很多不同的库来用在不同场景。而Flink由于较新,现阶段的开源社区不如Spark活跃,各种库的功能也不如Spark全面。但是Flink还在不断发展,各种功能也在逐渐完善。
基础转自 https://manor.blog.csdn.net/
原文链接:
https://mp.weixin.qq.com/s/2Dzv8uPlvEZz7d_jgB4WPg
侵删