GPT-2之文本生成
BPE 算法原文中对 BPE 算法的实现:
import re
import collections
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i], symbols[i+1]] += freq # 计算字节对出现频率
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair)) # 将字节对中可解释为正则运算符的字符转义
p = re.compile(r'(? + bigram + r'(?!\S)') # 将要合并的字节对前后只能为空白字符
for word in v_in:
w_out = p.sub(''.join(pair), word) # 合并符合条件的字节对
v_out[w_out] = v_in[word]
return v_out
以上是BPE
vocab = {'l o w ': 5, 'l o w e r ': 2,
'n e w e s t ': 6, 'w i d e s t ': 3}
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get) # 选择频率最大的字节对
vocab = merge_vocab(best, vocab)
print(best)

代码测试
https://www.cnblogs.com/wwj99/p/12503545.html 过程来源
按照预训练模型从新训练,按照运行的顺序一步一步查看

import random
def select_top_k(predictions, k=10):
predicted_index = random.choice(
predictions[0, -1, :].sort(descending=True)[1][:10]).item()
return predicted_index
下面引入 GPT-2 模型,我们将使用在 PyTorch-Transformers 模型库中封装好的 GPT2Tokenizer() 和 GPT2LMHeadModel() 类来实际看一下 GPT-2 在预训练后的对下一个词预测的能力。首先,需要安装 PyTorch-Transformers。
使用 PyTorch-Transformers 模型库,先设置好准备输入模型的例子,使用 GPT2Tokenizer() 建立分词器对象对原句编码。
import torch
from pytorch_transformers import GPT2Tokenizer
import logging
logging.basicConfig(level=logging.INFO)
# 载入预训练模型的分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 使用 GPT2Tokenizer 对输入进行编码
text = "Yesterday, a man named Jack said he saw an alien,"
indexed_tokens = tokenizer.encode(text)
tokens_tensor = torch.tensor([indexed_tokens])
tokens_tensor.shape

!wget -nc "https://labfile.oss.aliyuncs.com/courses/1372/gpt2-shiyanlou.zip"
!unzip -o "gpt2-shiyanlou.zip"

from pytorch_transformers import GPT2LMHeadModel
# 读取 GPT-2 预训练模型
model = GPT2LMHeadModel.from_pretrained("./")
model.eval()
我很好奇下载的预训练模型都有什么,查看一下。

用上面的短文本测试一下文本书写:
total_predicted_text = text
n = 100 # 预测过程的循环次数
for _ in range(n):
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
predicted_index = select_top_k(predictions, k=10)
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
total_predicted_text += tokenizer.decode(predicted_index)
if '<|endoftext|>' in total_predicted_text:
# 如果出现文本结束标志,就结束文本生成
break
indexed_tokens += [predicted_index]
tokens_tensor = torch.tensor([indexed_tokens])
print(total_predicted_text)

运行结束后,我们观察一下模型生成的文本,可以看到,大致感觉上这好像是一段正常的文本,不过,仔细看就会发现语句中的逻辑问题,这也是之后研究人员会继续攻克的问题。
接下来,我们将使用一些戏剧剧本对 GPT-2 进行微调。由于 OpenAI 团队开源的 GPT-2 模型预训练参数为使用英文数据集预训练后得到的,虽然可以在微调时使用中文数据集,但需要大量数据和时间才会有好的效果,所以这里我们使用了英文数据集进行微调,从而更好地展现 GPT-2 模型的能力。
首先,下载训练数据集,这里使用了莎士比亚的戏剧作品《罗密欧与朱丽叶》作为训练样本。数据集我们已经提前下载好并放在蓝桥云课服务器中,可以通过以下命令下载。
!wget -nc "https://labfile.oss.aliyuncs.com/courses/1372/romeo_and_juliet.zip"
!unzip -o "romeo_and_juliet.zip"
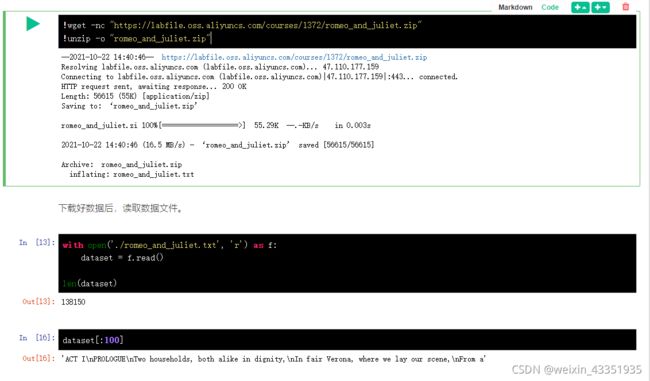

读取的数据集合是一个字符串。
预处理训练集,将训练集编码、分段。
indexed_text = tokenizer.encode(dataset)
del(dataset)
dataset_cut = []
for i in range(len(indexed_text)//512):
# 将字符串分段成长度为 512
dataset_cut.append(indexed_text[i*512:i*512+512])
del(indexed_text)
dataset_tensor = torch.tensor(dataset_cut)
dataset_tensor.shape
这里我分开运行测试
首先将字符tokenizer进行编码: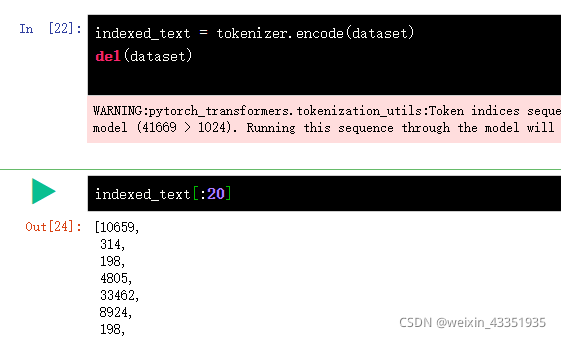
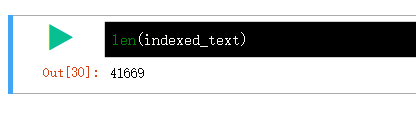
总计 41669 构造为了 81*512=41472 少了一些字符。
查看数据格式, 这里面应该没有完全将数据分割,最后没有整除的怎么搞?


将dataset_cut 转化为 pytorch 中的tensor 格式
这里使用 PyTorch 提供的 DataLoader() 构建训练集数据集表示,使用 TensorDataset() 构建训练集数据迭代器。
from torch.utils.data import DataLoader, TensorDataset
# 构建数据集和数据迭代器,设定 batch_size 大小为 2
train_set = TensorDataset(dataset_tensor,
dataset_tensor) # 标签与样本数据相同
train_loader = DataLoader(dataset=train_set,
batch_size=2,
shuffle=False)
train_loader
训练集数据 中的输入=输出,
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device

开始训练。
from torch import nn
from torch.autograd import Variable
import time
pre = time.time()
epoch = 30 # 循环学习 30 次
model.to(device)
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5) # 定义优化器
for i in range(epoch):
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(
target).to(device)
optimizer.zero_grad()
loss, logits, _ = model(data, labels=target)
total_loss += loss
loss.backward()
optimizer.step()
if batch_idx == len(train_loader)-1:
# 在每个 Epoch 的最后输出一下结果
print('average loss:', total_loss/len(train_loader))
print('训练时间:', time.time()-pre)


text = "From fairest creatures we desire" # 这里也可以输入不同的英文文本
indexed_tokens = tokenizer.encode(text)
tokens_tensor = torch.tensor([indexed_tokens])

model.eval()
total_predicted_text = text
# 使训练后的模型进行 500 次预测
for _ in range(500):
tokens_tensor = tokens_tensor.to('cuda')
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
predicted_index = select_top_k(predictions, k=10)
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
total_predicted_text += tokenizer.decode(predicted_index)
if '<|endoftext|>' in total_predicted_text:
# 如果出现文本结束标志,就结束文本生成
break
indexed_tokens += [predicted_index]
if len(indexed_tokens) > 1023:
# 模型最长输入长度为1024,如果长度过长则截断
indexed_tokens = indexed_tokens[-1023:]
tokens_tensor = torch.tensor([indexed_tokens])
print(total_predicted_text)
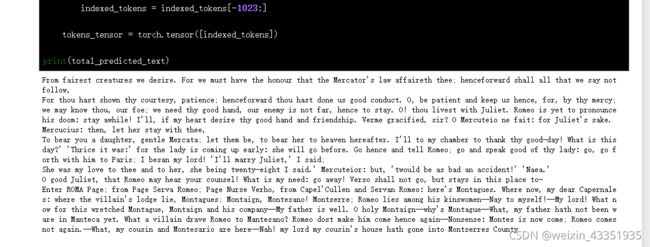
从生成结果可以看到,模型已经学习到了戏剧剧本的文本结构。但是仔细读起来会发现缺少逻辑和关联,这是因为由于时间和设备的限制,对模型的训练比较有限。如果有条件可以用更多的数据,训练更长的时间,这样模型也会有更好的表现。
https://openai.com/blog/better-language-models/