GNN学习笔记(六):Cluster-GCN:一种用于训练深度和大型图卷积网络的高效算法
引言
普通的基于SGD的图神经网络的训练方法,存在着以下问题:
问题1:计算成本较大问题。随着图神经网络层数增加,计算成本呈指数增长。
问题2:内存消耗巨大问题。保存整个图的信息和每一层每个节点的表征到内存(显存)而消耗巨大内存(显存)空间。
解决措施:
方法1:无需保存整个图的信息和每一层每个节点的表征到GPU内存(显存)的方法。
方法1存在的问题:可能会损失预测精度或者对提高内存的利用率并不明显。
方法2:论文Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Network提出了一种新的图神经网络的训练方法(简称为Cluster-GCN方法)。
本文着重介绍Cluster-GCN方法,这是一种适用于基于 SGD 的训练的新型 GCN 算法,它利用图聚类结构。Cluster-GCN 的工作原理如下:在每一步,它对与图聚类算法识别的密集子图相关联的节点块进行采样,并限制该子图中的邻域搜索。这种简单但有效的策略显着提高了内存和计算效率,同时能够实现与以前算法相当的测试精度。
为了测试Cluster-GCN算法的可扩展性,创建了一个具有 200 万个节点和 6100 万条边的新 Amazon2M 数据,比之前最大的公开可用数据集 (Reddit) 大 5 倍以上。为了在此数据上训练 3 层 GCN,Cluster-GCN 比之前最先进的 VR-GCN(1523 秒对 1961 秒)更快,并且使用更少的内存(2.2GB 对 11.2GB)。此外,为了在这些数据上训练 4 层 GCN,Cluster-GCN算法可以在大约 36 分钟内完成,而所有现有的 GCN 训练算法由于内存不足问题而无法训练。此外,Cluster-GCN 允许在没有太多时间和内存开销的情况下训练更深的 GCN,从而提高预测精度——使用 5 层 Cluster-GCN,在PPI 数据集,而之前的最佳结果是 [16] 的 98.71。
github链接:https://github.com/benedekrozemberczki/ClusterGCN (ClusterGCN,A PyTorch implementation)
Abstract
Cluster-GCN方法简单概括
为了解决普通训练方法无法训练超大图的问题,Cluster-GCN论文提出:利用图节点聚类算法将一个图的节点划分为个簇,每一次选择几个簇的节点和这些节点对应的边构成一个子图,然后对子图做训练。
优点:
(1)提高表征利用率、训练效率。由于是利用图节点聚类算法将节点划分为多个簇,所以簇内边的数量要比簇间边的数量多得多,所以可以提高表征利用率,并提高图神经网络的训练效率。(2)解决类别分布偏差过大的问题。每一次随机选择多个簇来组成一个batch,这样不会丢失簇间的边,同时也不会有batch内类别分布偏差过大的问题。(3)减少内存消耗,提高模型精度。基于小图进行训练,不会消耗很多内存空间,于是我们可以训练更深的神经网络,进而可以达到更高的精度。
原理:
在每个步骤中,它对与图聚类算法识别的稠密子图相关联的节点块进行采样,并限制在该子图中进行邻域搜索。在构建批量进行SGD更新时,没有只考虑一个簇,而是随机选择q个簇。
简单的Cluster-GCN方法

随机多簇方法
Cluster-GCN方法存在两个潜在问题:
1)图被分割后,一些边(公式(4)中的部分)被移除,性能可能因此会受到影响。2)图聚类算法倾向于将相似的节点聚集在一起。因此,单个簇中节点的类别分布可能与原始数据集不同,导致对梯度的估计有偏差。
问题:与随机划分相比,采用聚类划分得到的大多数簇熵值都很小,簇熵值小表明簇中节点的标签分布偏向于某一些类别,这意味着不同簇的标签分布有较大的差异,这将影响训练的收敛。类别分布熵越高意味着簇内类别分布越平衡,反之意味着簇内类别分布越不平衡。
解决方法:Cluster-GCN论文提出了一种随机多簇方法。
此方法的好处有,1)不会丢失簇间的边,2)不会有很大的batch内类别分布的偏差,3)以及不同的epoch使用的batch不同,这可以降低梯度估计的偏差。
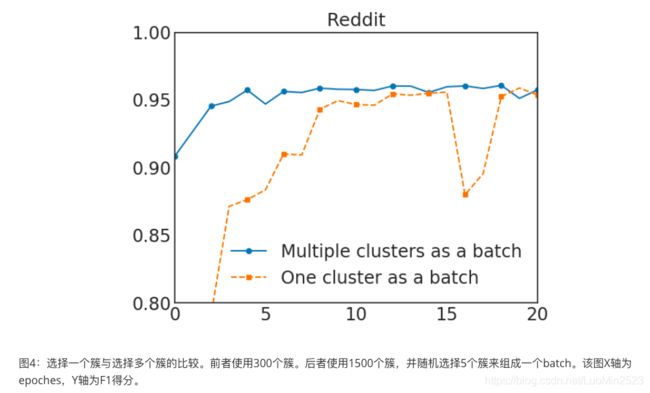
在图4中,我们可以观察到,使用多个簇来组成一个batch可以提高收敛性。最终的Cluster-GCN算法在算法1中呈现。

一种简单的技术来改善深层GCN神经网络的训练
在原始的GCN的设置里,每个节点都聚合邻接节点在上一层的表征。然而,在深层GCN的设置里,该策略可能不适合,因为它没有考虑到层数的问题。直观地说,近距离的邻接节点应该比远距离的的邻接节点贡献更大。因此,Cluster-GCN提出一种技术来更好地解决这个问题。其主要思想是放大GCN每一层中使用的邻接矩阵 的对角线部分。通过这种方式,我们在GCN的每一层的聚合中对来自上一层的表征赋予更大的权重。这可以通过给
的对角线部分。通过这种方式,我们在GCN的每一层的聚合中对来自上一层的表征赋予更大的权重。这可以通过给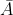 加上一个单位矩阵
加上一个单位矩阵 来实现,如下所示,
来实现,如下所示,


Cluster-GCN实践
数据集分析
from torch_geometric.datasets import Reddit
from torch_geometric.data import ClusterData, ClusterLoader, NeighborSampler
dataset = Reddit('../dataset/Reddit')
data = dataset[0]
print(dataset.num_classes)
print(data.num_nodes)
print(data.num_edges)
print(data.num_features)
# 41
# 232965
# 114615873
# 602可以看到该数据集包含41个分类任务,232,965个节点,114,615,873条边,节点维度为602维。
图节点聚类与数据加载器生成
cluster_data = ClusterData(data, num_parts=1500, recursive=False, save_dir=dataset.processed_dir)
train_loader = ClusterLoader(cluster_data, batch_size=20, shuffle=True, num_workers=12)
subgraph_loader = NeighborSampler(data.edge_index, sizes=[-1], batch_size=1024, shuffle=False, num_workers=12)train_loader,此数据加载器遵循Cluster-GCN提出的方法,图节点被聚类划分成多个簇,此数据加载器返回的一个batch由多个簇组成。
subgraph_loader,使用此数据加载器不对图节点聚类,计算一个batch中的节点的表征需要计算该batch中的所有节点的距离从O到L的邻居节点。
图神经网络的构建
class Net(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super(Net, self).__init__()
self.convs = ModuleList(
[SAGEConv(in_channels, 128),
SAGEConv(128, out_channels)])
def forward(self, x, edge_index):
for i, conv in enumerate(self.convs):
x = conv(x, edge_index)
if i != len(self.convs) - 1:
x = F.relu(x)
x = F.dropout(x, p=0.5, training=self.training)
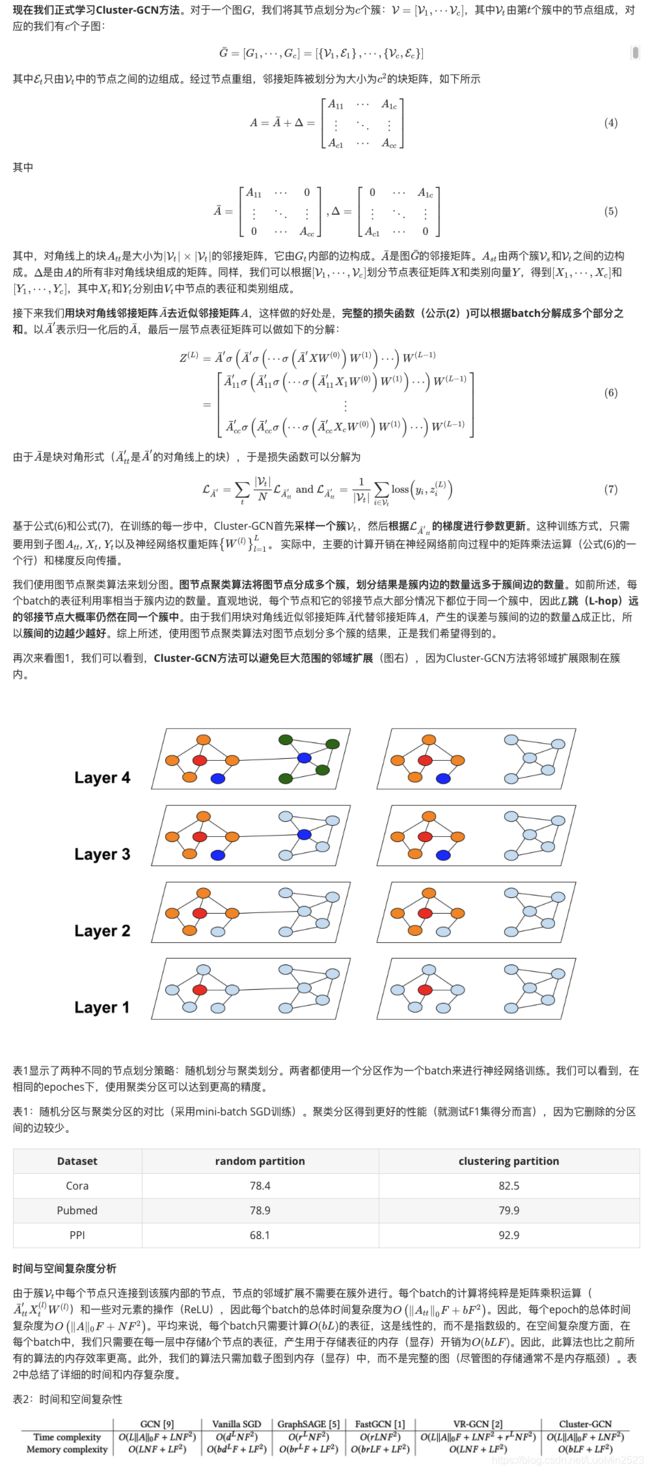
return F.log_softmax(x, dim=-1)
def inference(self, x_all):
pbar = tqdm(total=x_all.size(0) * len(self.convs))
pbar.set_description('Evaluating')
# Compute representations of nodes layer by layer, using *all*
# available edges. This leads to faster computation in contrast to
# immediately computing the final representations of each batch.
for i, conv in enumerate(self.convs):
xs = []
for batch_size, n_id, adj in subgraph_loader:
edge_index, _, size = adj.to(device)
x = x_all[n_id].to(device)
x_target = x[:size[1]]
x = conv((x, x_target), edge_index)
if i != len(self.convs) - 1:
x = F.relu(x)
xs.append(x.cpu())
pbar.update(batch_size)
x_all = torch.cat(xs, dim=0)
pbar.close()
return x_all可以看到此神经网络拥有forward和inference两个方法。forward函数的定义与普通的图神经网络并无区别。inference方法应用于推理阶段,为了获取更高的预测精度,所以使用subgraph_loader。
训练、验证与测试
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Net(dataset.num_features, dataset.num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)
def train():
model.train()
total_loss = total_nodes = 0
for batch in train_loader:
batch = batch.to(device)
optimizer.zero_grad()
out = model(batch.x, batch.edge_index)
loss = F.nll_loss(out[batch.train_mask], batch.y[batch.train_mask])
loss.backward()
optimizer.step()
nodes = batch.train_mask.sum().item()
total_loss += loss.item() * nodes
total_nodes += nodes
return total_loss / total_nodes
@torch.no_grad()
def test(): # Inference should be performed on the full graph.
model.eval()
out = model.inference(data.x)
y_pred = out.argmax(dim=-1)
accs = []
for mask in [data.train_mask, data.val_mask, data.test_mask]:
correct = y_pred[mask].eq(data.y[mask]).sum().item()
accs.append(correct / mask.sum().item())
return accs
for epoch in range(1, 31):
loss = train()
if epoch % 5 == 0:
train_acc, val_acc, test_acc = test()
print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}, Train: {train_acc:.4f}, '
f'Val: {val_acc:.4f}, test: {test_acc:.4f}')
else:
print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}')可见在训练过程中,我们使用train_loader获取batch,每次根据多个簇组成的batch进行神经网络的训练。但在验证阶段,我们使用subgraph_loader,在计算一个节点的表征时会计算该节点的距离从O到L的邻接节点,这么做可以更好地测试神经网络的性能。
参考资料:
https://arxiv.org/abs/1905.07953
Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In ICLR.
https://github.com/datawhalechina/team-learning-nlp/tree/master/GNN/Markdown版本