阅读笔记-2022-Enhancing Sequential Recommendation with Graph Contrastive Learning
阅读笔记-Enhancing Sequential Recommendation with Graph Contrastive Learning
- paper:[2205.14837] Enhancing Sequential Recommendation with Graph Contrastive Learning (arxiv.org)
Motivations
- 现有的方法将每个用户的交互序列进行建模,并且只利用了序列中的局部 (local) 上下文信息。这忽略了具有相似行为模式的用户之间的相关性;
- 用户行为数据非常稀疏,先前的方法通常只使用 item 预测任务来训练推荐模型。由于数据稀疏问题,这种方式不能学习适当的序列表示;
- 序列推荐模型通常基于隐式反馈序列建立,隐式反馈序列中可能包含噪声信息
Challenges
- 如何建模所有用户的交互信息从而获得全局上下文信息?
- 如何缓解数据稀疏性?
- 如何削弱噪声的影响?
Method
1. 问题定义
- item 集合: V \bold V V , 用户集合: U \bold U U , 交互序列: D \bold D D ;
- 对于每个用户 u ∈ U u\in \bold U u∈U, 使用 S = { v 1 , v 2 , . . . , v n } \bold S=\{v_1,v_2,...,v_n\} S={v1,v2,...,vn} 来表示它的交互序列,其中 v t v_t vt 表示用户 u u u 的第 t t t 个交互的 item, n n n 表示该用户交互了多少个item ;
- 嵌入表示:
- 用户 u u u 的embedding 表示为: P u ∈ R 1 × d \bold P_u\in R^{1\times d} Pu∈R1×d
- item i i i 的embedding 表示为: e i ∈ R 1 × d \bold e_i\in R^{1\times d} ei∈R1×d
- 序列 S \bold S S 的初始embedding 表示为: E S ( 0 ) ∈ R n × d \bold E_S^{(0)}\in R^{n\times d} ES(0)∈Rn×d , 其中 E S ( 0 ) \bold E_S^{(0)} ES(0) 中的第 t t t 行表示 S \bold S S 中的第 t t t 个节点的 embedding
- 所有item的embedding表示为: E ∈ R ∣ V ∣ × d \bold E\in R^{|\bold V|\times d} E∈R∣V∣×d
- 使用 D \bold D D 构建一个加权的 item transition 图 G \bold G G,提供了使用所有用户行为序列构建成的 item transition模式的全局视图,如下图所示:
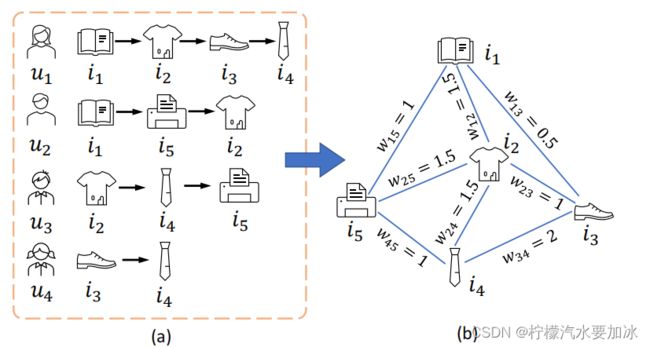 图1. 一个item transition图示例
图1. 一个item transition图示例
-
图 G \bold G G 的构建遵从以下策略,以序列 S \bold S S 为例:
- 对于每个 item v t ∈ S v_t\in \bold S vt∈S ,如果在图 G \bold G G 中 v t v_t vt 和 v ( t + k ) v_{(t+k)} v(t+k) 之间存在边,就更新该边的权重为: w ( v t , v ( t + k ) ) ← w ( v t , v ( t + k ) ) + 1 k w(v_t,v_{(t+k)})\leftarrow w(v_t,v_{(t+k)})+\frac1k w(vt,v(t+k))←w(vt,v(t+k))+k1 , 否则就将 v t v_t vt 和 v ( t + k ) v_{(t+k)} v(t+k) 之间的边权重设为 1 k , k ∈ { 1 , 2 , 3 } \frac 1k,\space k\in \{1,2,3\} k1, k∈{1,2,3}, 其中 1 k \frac 1k k1 表示目标节点 v t v_t vt 对于第 k k k 跳邻居 v t + k v_{t+k} vt+k 的重要性。[采取了何向南老师的lightgcn中的策略]
- 将图中的各条边上的权重进行归一化:
w ^ ( v t , v j ) = w ( v t , v j ) ( 1 d e g ( v i ) + 1 d e g ( v j ) ) \hat w(v_t,v_j)=w(v_t,v_j)(\frac 1 {deg(v_i)}+\frac 1{deg(v_j)}) w^(vt,vj)=w(vt,vj)(deg(vi)1+deg(vj)1)
其中 d e g ( . ) deg(.) deg(.) 表示图中节点的度,注意这里的图是无向图
2. 模型GCL4SR

-
Graph augmented sequence representation learning
-
Graph-based Augmentation
给定加权转移图 G \bold G G,通过数据增广为一个交互序列 S \bold S S 构造两个增广图视图。在这项工作中,使用的是[Hamilton et al., 2017] 中的高效邻域采样方法,从给定序列的大型过渡图生成增强图视图。具体来说,我们将每个节点v∈S作为中心节点,设置采样深度M为2,每步采样大小N为20,对G中的邻居进行交互采样。在抽样过程中,我们不考虑边的权重,对节点进行均匀抽样,然后在G中保留被抽样节点之间的边及其权重。
对于一个特定的序列S,采用基于图的增广后,我们可以得到两个增广图视图: G S ′ = ( V S ′ , E S ′ , A S ′ ) G_S^{'}=(V_S^{'},E_S^{'},A_S^{'}) GS′=(VS′,ES′,AS′) 和 G S " = ( V S " , E S " , A S " ) G_S^{"}=(V_S^{"},E_S^{"},A_S^{"}) GS"=(VS",ES",AS") , 其中 V S ′ , E S ′ , A S ′ V_S^{'},E_S^{'},A_S^{'} VS′,ES′,AS′ 分别表示节点的集合、边的集合和图 G S ′ G_S^{'} GS′ 的邻接矩阵,注意 G S ′ G_S^{'} GS′ 和 G S " G_S^{"} GS" 都是图 G G G 的子图, A S ′ , A S " A_S^{'},A_S^{"} AS′,AS" 存储式(1)中定义的边的归一化权值
-
Shared Graph Neural Networks
根据g [Hassani and Khasahmadi, 2020],使用两个具有共享参数的图神经网络对 G S ′ G_S^{'} GS′ 和 G S " G_S^{"} GS" 进行编码。以 G S ′ G_S^{'} GS′ 为例,在图神经网络的第 t t t 层的消息传递和聚合公式如下:
a v i ( t ) = A g g r e g a t e ( t ) ( { h v j ( t − 1 ) : v j ∈ N v i ′ } ) , h v i ( t ) = C o m b i n e ( t ) ( a v i ( t ) , h v i ( t − 1 ) ) a_{v_i}^{(t)}=Aggregate^{(t)}(\{h_{v_j}^{(t-1)}:v_j\in N_{v_i}^{'}\}), \\ h_{v_i}^{(t)}=Combine^{(t)}(a_{v_i}^{(t)},h_{v_i}^{(t-1)}) avi(t)=Aggregate(t)({hvj(t−1):vj∈Nvi′}),hvi(t)=Combine(t)(avi(t),hvi(t−1))
经过多层信息传播可以得到图 G S ′ G_S^{'} GS′ 和 G S " G_S^{"} GS" 的embedding H s ′ ∈ R n × d H_s^{'}\in R^{n\times d} Hs′∈Rn×d 和 H s " ∈ R n × d H_ s^{"}\in R^{n\times d} Hs"∈Rn×d
在本工作中,这两个gnn的实现如下。在第一层,使用图神经网络(GCN)利用增广图 的加权邻接矩阵融合节点信息。然后,进一步叠加一个GraphSage层,该层使用平 均池来聚合增广图中的高阶邻域信息。
- Graph Contrastive Learning Objective
-
使用以下目标函数来区分相同交互序列的增广表示与其他增广表示:
L G C L ( S ) = ∑ S ∈ D − l o g e x p ( c o s ( z S ′ , z S " ) / τ ) ∑ K ∈ D e x p ( c o s ( z S ′ , z S " ) / τ ) L_{GCL}(S)=\sum_{S\in D}-log \frac {exp(cos(z_S^{'},z_S^{"})/\tau)}{\sum_{K\in D} {exp(cos(z_S^{'},z_S^{"})/\tau)}} LGCL(S)=S∈D∑−log∑K∈Dexp(cos(zS′,zS")/τ)exp(cos(zS′,zS")/τ)
其中 z S ′ z_S^{'} zS′ 和 z S " z_S^{"} zS" 是经过pooling后的 H s ′ H_s^{'} Hs′ 和 H s " H_s^{"} Hs"。 c o s ( . ) cos(.) cos(.) 表示的是余弦相似度计算。 τ \tau τ 是 超参数,此处设置为0.5。
- User-specifific gating
由于每个用户可能只对 item 的某些特定属性感兴趣,因此全局上下文信息应该是特定于 用户的。根据g [Ma et al., 2019],设计了以下特定于用户的控制机制,以捕获根据用户 的个性化偏好定制的全局上下文信息:
Q S ′ = H S ′ ⊗ σ ( H S ′ W g 1 + W g 2 P u T ) \bold Q_S^{'} = \bold H_S^{'}\otimes \sigma(\bold H_S^{'}\bold W_{g_1}+\bold W_{g_2}\bold P_u^T) QS′=HS′⊗σ(HS′Wg1+Wg2PuT)
其中, W g 1 ∈ R d × 1 , W g 2 ∈ R L × d \bold W_{g_1}\in R^{d\times1}, \bold W_{g_2}\in R^{L\times d} Wg1∈Rd×1,Wg2∈RL×d, σ \sigma σ 是 sigmoid 函数, ⊗ \otimes ⊗ 是逐元素相乘, p u p_u pu 表示用户 的偏好。相似地,可以通过该公式计算 G s " G_s^{"} Gs"的全局上下文信息 Q S " \bold Q_S^{"} QS"
- Basic sequence encoder
除了序列的图增广表示外,我们还采用传统的序列模型对用户交互序列进行编码。选择SASRec [Kang and McAuley, 2018]作为骨干模型,它堆叠Transformer编码器[Vaswani等人,2017]来建模用户交互序列。给定第 ( l − 1 ) (l-1) (l−1)层的节点表示 H l − 1 H^{l-1} Hl−1,则第 l l l 层Transformer编码器的输出如下:
H l = F F N ( C o n c a t ( h e a d 1 , . . . , h e a d h ) W h ) h e a d i = A t t e n t i o n ( H l − 1 W i Q , H l − 1 W i K , H l − 1 W i V ) \bold H^l=FFN(Concat(head_1,...,head_h)\bold W^h) \\ head_i=Attention(\bold H^{l-1}\bold W_i^Q,\bold H^{l-1}\bold W_i^K,\bold H^{l-1}\bold W_i^V) Hl=FFN(Concat(head1,...,headh)Wh)headi=Attention(Hl−1WiQ,Hl−1WiK,Hl−1WiV)
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d ) V Attention(\bold Q,\bold K, \bold V)=softmax(\frac {\bold Q\bold K^T}{\sqrt d})\bold V Attention(Q,K,V)=softmax(dQKT)V
-
Prediction layer
我们将表示 Q s ′ \bold Q_s^{'} Qs′ 和 Q s " \bold Q_s^{"} Qs" 连接起来,Transformer编码器 H l \bold H^l Hl 的最后一层的embedding计算如下:
M = A t t N e t ( C o n c a t ( Q S ′ , Q S " , H l ) W T ) \bold M =AttNet(Concat(\bold Q_S^{'},\bold Q_S^{"},\bold H^l)\bold W^T) M=AttNet(Concat(QS′,QS",Hl)WT)
那么,给定长度为n的用户交互序列S,在(n+ 1)第一步,用户与物品的交互概率可以定 义为:
y ^ ( S ) = s o f t m a x ( M E T ) \hat y^{(S)}=softmax(\bold M\bold E^T) y^(S)=softmax(MET)
- Multi Task Learning
L m a i n = − ∑ S u ∈ D ∑ k = 1 ∣ S u ∣ − 1 l o g ( y ^ ( s u 1 : k ) ( v u k + 1 ) ) L_{main}=-\sum_{S_u\in D}\sum_{k=1}^{|S_u|-1}log(\hat y^{(s_u^{1:k})}(v_u^{k+1})) Lmain=−Su∈D∑k=1∑∣Su∣−1log(y^(su1:k)(vuk+1))
L = L m a i n + ∑ S u ∈ D ∑ k = 1 ∣ S u ∣ − 1 λ 1 L G C L ( s u 1 : k ) + λ 2 L M M ( s u 1 : k ) L=L_{main}+\sum_{S_u\in D}\sum_{k=1}^{|S_u|-1}\lambda_1L_{GCL}(s_u^{1:k})+\lambda_2L_{MM}(s_u^{1:k}) L=Lmain+Su∈D∑k=1∑∣Su∣−1λ1LGCL(su1:k)+λ2LMM(su1:k)
Result
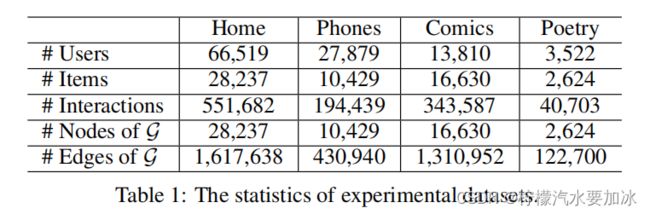
- 数据集
实验在Amazon评论数据集和Goodreads评论数据集上进行:
- 总体表现

-
消融实验
- 各个部分的重要性

- 参数敏感性研究
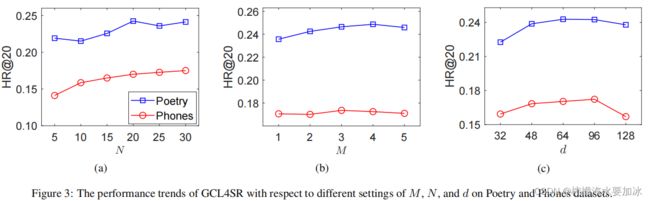
- 序列编码器的影响

References
[Hamilton et al., 2017] William L Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on large graphs. In NeurIPS’17, pages 1025–1035, 2017.
[Hassani and Khasahmadi, 2020] Kaveh Hassani and Amir Hosein Khasahmadi. Contrastive multi-view representation learning on graphs. In ICML’20, pages 4116–4126, 2020.