skynet刚开始是单进程多线程的,它是由一个一个的服务组成的。在skynet上做开发,实际上就是在写服务。服务与服务之间通过消息队列进行通信。
做为核心功能,Skynet 仅解决一个问题:
把一个符合规范的 C 模块,从动态库(so 文件)中启动起来,绑定一个永不重复(即使模块退出)的数字 id 做为其 handle 。模块被称为服务(Service),服务间可以自由发送消息。每个模块可以向 Skynet 框架注册一个 callback 函数,用来接收发给它的消息。每个服务都是被一个个消息包驱动,当没有包到来的时候,它们就会处于挂起状态,对 CPU 资源零消耗。如果需要自主逻辑,则可以利用 Skynet 系统提供的 timeout 消息,定期触发。
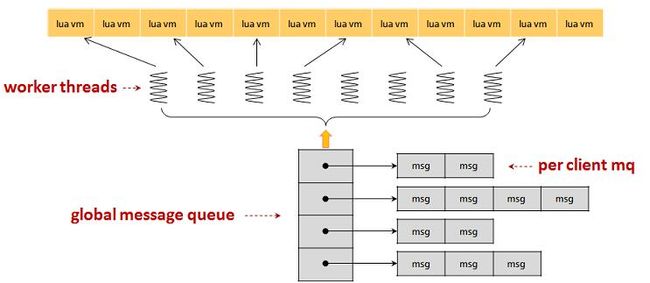
一个服务,默认不会执行任何逻辑,需要别人向它发出请求时,才会执行对应的逻辑(定时器也是通过消息队列,告诉指定服务,要执行定时事件),并在需要时返回结果给请求者。请求者往往也是其他服务。服务间的请求、响应和推送,并不是直接调用对方的api来执行,而是通过一个消息队列,也就是说,不论是请求、回应还是推送,都需要通过这个消息队列转发到另一个服务中。skynet的消息队列,分为两级,一个全局消息队列,他包含一个头尾指针,分别指向两个隶属于指定服务的次级消息队列。skynet中的每一个服务,都有一个唯一的、专属的次级消息队列。
skynet服务的本质
每个skynet服务都是一个lua state,也就是一个lua虚拟机实例。而且,每个服务都是隔离的,各自使用自己独立的内存空间,服务之间通过发消息来完成数据交换。
lua state本身没有多线程支持的,为了实现cpu的摊分,skynet实现上在一个线程运行多个lua state实例。而同一时间下,调度线程只运行一个服务实例。为了提高系统的并发性,skynet会启动一定数量的调度线程。同时,为了提高服务的并发性,就利用lua协程并发处理。
所以,skynet的并发性有3点:
1、多个调度线程并发
2、lua协程并发处理
3、服务调度的切换
skynet服务的设计基于Actor模型。有两个特点:
1. 每个Actor依次处理收到的消息
2. 不同的Actor可同时处理各自的消息
实现上,cpu会按照一定规则分摊给每个Actor,每个Actor不会独占cpu,在处理一定数量消息后主动让出cpu,给其他进程处理消息。
skynet的例子是怎么调用的
simpledb.lua: skynet.register “SIMPLEDB” 向skynet里注册一个服务
agent.lua: skynet.call(“SIMPLEDB”, “text”, text) 调用相应的服务
main.lua: skynet.newservice(“simpledb”) 启动一个服务
以上函数都在\lualib\skynet.lua 文件内
以下是几个写服务时经常要用到的函数。
uniqueservice(name, ...) 启动一个唯一服务,如果服务该服务已经启动,则返回已启动的服务地址。
queryservice(name) 查询一个由 uniqueservice 启动的唯一服务的地址,若该服务尚未启动则等待。
localname(name) 返回同一进程内,用 register 注册的具名服务的地址。
newservice可以在一个进程里启动多个服务,这适用于无状态的服务。
uniqueservice则是类似于设计模式中的单件(singleton),这适用于需要唯一性的服务。举个例子,比如写日志,只想写一份。或者是全局共享的数据。
skynet_handle.c实际上就做了两个核心的事情,一是给服务分配一个handle,二是把handle和name关联起来。
把handle和name关联起来比较容易懂,实际上使用一个数组,关联的时候使用二分查找到数组里查名字,如果名字不存在,就插入一个元素,然后把名字和handle关联起来。插入元素的时候,如果数组空间不足了,就扩容为原来的2倍。
而给服务分配handle稍复杂一些,实际上也是使用一个slot数组,数组下标使用的是一个hash,数组元素指向服务的上下文。这个hash的算法是比较简单粗暴的,就是看从handle_indx开始累计到slot_size,看中间有没有空闲的下标(也就是下标指向为null的),如果遍历完了还是没有,就把slot扩大一倍,还是没有就再扩大一倍,直到找到空位为止,或者是slot长度超出限制为止。
取到了handle以后呢,还要将harbor id附到handle的高8位。
每个服务分三个运行阶段:
首先是服务加载阶段,当服务的源文件被加载时,就会按 lua 的运行规则被执行到。这个阶段不可以调用任何有可能阻塞住该服务的 skynet api 。因为,在这个阶段中,和服务配套的 skynet 设置并没有初始化完毕。
然后是服务初始化阶段,由 skynet.start 这个 api 注册的初始化函数执行。这个初始化函数理论上可以调用任何 skynet api 了,但启动该服务的 skynet.newservice 这个 api 会一直等待到初始化函数结束才会返回。
最后是服务工作阶段,当你在初始化阶段注册了消息处理函数的话,只要有消息输入,就会触发注册的消息处理函数。这些消息都是 skynet 内部消息,外部的网络数据,定时器也会通过内部消息的形式表达出来。
从 skynet 底层框架来看,每个服务就是一个消息处理器。但在应用层看来并非如此。它是利用 lua 的 coroutine 工作的。当你的服务向另一个服务发送一个请求(即一个带 session 的消息)后,可以认为当前的消息已经处理完毕,服务会被 skynet 挂起。待对应服务收到请求并做出回应(发送一个回应类型的消息)后,服务会找到挂起的 coroutine ,把回应信息传入,延续之前未完的业务流程。从使用者角度看,更像是一个独立线程在处理这个业务流程,每个业务流程有自己独立的上下文,而不像 nodejs 等其它框架中使用的 callback 模式。
但框架已经提供了一个叫做 snlua 的用 C 开发的服务模块,它可以用来解析一段 Lua 脚本来实现业务逻辑。也就是说,你可以在 skynet 启动任意份 snlua 服务,只是它们承载的 Lua 脚本不同。这样,我们只使用 Lua 来进行开发就足够了。
ShareData
当你把业务拆分到多个服务中去后,数据如何共享,可能是最易面临的问题。
最简单粗暴的方法是通过消息传递数据。如果 A 服务需要 B 服务中的数据,可以由 B 服务发送一个消息,将数据打包携带过去。如果是一份数据,很多地方都需要获得它,那么用一个服务装下这组数据,提供一组查询接口即可。DataCenter 模块对此做了简单的封装。
datacenter 可用来在整个 skynet 网络做跨节点的数据共享。
如果你仅仅需要一组只读的结构信息分享给很多服务(比如一些配置数据),你可以把数据写到一个 lua 文件中,让不同的服务加载它。Cluster 的配置文件就是这样做的。注意:默认 skynet 使用自带的修改版 lua ,会缓存 lua 源文件。当一个 lua 文件通过 loadfile 加载后,磁盘上的修改不会影响下一次加载。所以你需要直接用 io.open 打开文件,再用 load 加载内存中的 string 。
另一个更好的方法是使用 sharedata 模块。
当大量的服务可能需要共享一大块并不太需要更新的结构化数据,每个服务却只使用其中一小部分。你可以设想成,这些数据在开发时就放在一个数据仓库中,各个服务按需要检索出需要的部分。
整个工程需要的数据仓库可能规模庞大,每个服务却只需要使用其中一小部分数据,如果每个服务都把所有数据加载进内存,服务数量很多时,就因为重复加载了大量不会触碰的数据而浪费了大量内存。在开发期,却很难把数据切分成更小的粒度,因为很难时刻根据需求的变化重新切分。
如果使用 DataCenter 这种中心式管理方案,却无法避免每次在检索数据时都要进行一次 RPC 调用,性能或许无法承受。
sharedata 模块正是为了解决这种需求而设计出来的。sharedata 只支持在同一节点内(同一进程下)共享数据,如果需要跨节点,需要自行同步处理。
skynet call的实现--服务与服务的交互
https://blog.csdn.net/zxm342698145/article/details/79786802
如果一个服务生产了大量数据,想传给您一个服务消费,在同一进程下,是不必经过序列化过程,而只需要通过消息传递内存地址指针即可。这个优化存在 O(1) 和 O(n) 的性能差别,不可以无视。
架构图
TimeOutCall
https://github.com/cloudwu/skynet/wiki/TimeOutCall
TinyService
https://github.com/cloudwu/skynet/wiki/TinyService
参考:
skynet教程(3)--服务的别名
skynet服务的本质与缺陷
GettingStarted