基于R的金融收益的分析和预测
研究目的:根据上证综合指数历史收益率数据(2016.1.5-2018.4.4),对其收益进行分析和预测。
**分析思路:**读取数据—平稳性检验—白噪声检验(代码同上,此处不再赘述)–ARIMA模型拟合—序列预测。
预备知识1:ARIMA模型拟合指令arima(x,order=c(p,d,q),method=c(“ML”,“CSS”),include.mean)
其中:x—带估计序列;
Order—指定模型阶数;其中,P为自回归阶数;d为差分阶数,若为平稳序列,则不需要差分即d=0;q为移动平均阶数。
method—估计方法。method =CSS-ML,系统默认的是条件最小二乘估计和极大似然估计的混合方法;method =ML,极大似然估计;method =CSS,条件最小二乘估计;
include.mean—是否包含均值项,即估计结果中的intercept项。系统默认含有常数项。
本案例中的R语言代码:
(1)读取数据,画出时序图。
d=read.table("C:\\Users\\Administrator\\Desktop\\数据.txt",header=T) #导入数据
shouyi=ts(d) #转化为时间序列数据
plot(shouyi) #作时序图。通过时序图,发现该序列大致平稳时间序列。

(2)进一步的,对序列进行ADF单位根检验,判断其平稳性。
library(fBasics)
library(fUnitRoots)
#对序列进行ADF单位根检验。下载并安装“fUnitRoots”包,用library函数进行调用。该程序包中的adfTest函数可以很便捷的进行单位根检验。
for(i in 1:3)print(adfTest(shouyi,lag=i,type="nc"))
#对“shouyi”序列进行检验类型为类型1(无趋势,无常数项),延迟阶数分别取1,2,3的单位根检验。结果表明该序列为平稳时间序列。
(3)序列的白噪声检验
Box.test(shouyi, type="Ljung-Box",lag=6)
Box.test(shouyi, type="Ljung-Box",lag=12) #分别进行滞后期数为6和12期的纯随机性检验。检验结果表明,其统计量对应的P值都小于0.05,拒绝原假设,序列不是白噪声序列。
(4)收益率的ARMA建模
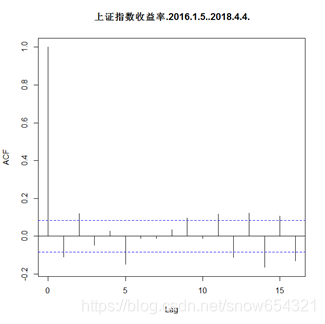
acf(shouyi,16) #作自相关图,且具有拖尾特性。
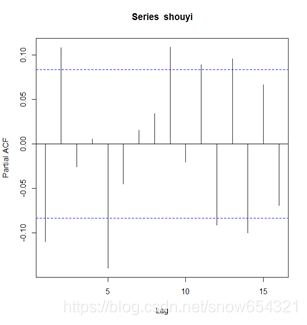
pacf(shouyi,16) #作偏自相关图,且具有拖尾特性。
`
```python
arima(shouyi, order = c(1,0,1),method="ML")

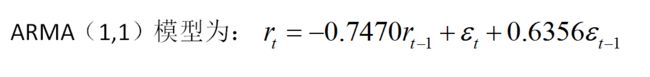
(5)模型的检验
(5.1)模型的显著性检验
a= arima(shouyi, order = c(1,0,1),method="ML") #把所有的拟合信息都存在一个叫“a”的文件(仓库)里。
r=a$residuals
#用r来保存残差
Box.test(r,type="Ljung-Box",lag=6,fitdf=2)
Box.test(r,type="Ljung-Box",lag=12,fitdf=2)
#对残差序列进行纯随机性检验。注意:fitdf的值等于(p+q)。当检验的序列是残差序列时,需要加上命令fitdf,表示减去的自由度。
R的结果:

表明,ARMA(1,1)模型的残差序列并不是一个白噪声序列,但序列中的相关信息已经充分提取了,这是由于残差序列存在异方差所造成的。这一点和Engle在1982年分析英国通货膨胀率序列时应用经典的ARIMA模型始终无法得到理想的拟合效果,而原因出在残差序列具有异方差性是一样的。所以,此时考虑用ARCH类模型对该序列进行分析。
(5.2)参数的显著性检验
p=pt(abs(-0.7470/0.0981),df=547,lower.tail = F)*2 #对ar1项的参数进行t检验。pt()为求t分布的p值的函数,第一项为参数估计值的t统计量的绝对值;df为自由度=数据个数-参数个数;lower.tail = F表示所求p值为P[T > t]即右侧概率;乘2表示p值是双侧的。
p=pt(abs(0.6356/0.1082),df=547,lower.tail = F)*2 #对ma1项的参数进行t检验。
两个参数的t检验的P值都小于0.05,结果表明ARMA(1,1)模型中的参数通过了显著性检验。
收益率拟合模型为:
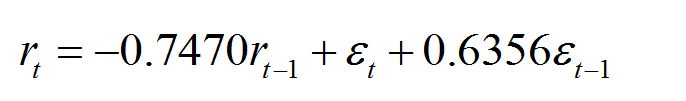
(6)收益率的预测
library(forecast) #用forecast函数完成预测。forecast(object,h=,level=),其中,object:拟合信息文件名;h:预测期数;level:置信区间的置信水平。不特殊指定的话,系统默认给出置信水平分别为80%和95%的双层置信区间。
shouyi.forecast=forecast(a,3,level=95) #用forecast函数完成未来3期的预测,置信度取95%。
shouyi.forecast