【智能优化算法】遗传算法——轮盘赌选择(matlab实现)
文章目录
- 一、遗传算法的应用
- 二、遗传学基本概念与术语
- 三、遗传算法的基本思路
-
- 轮盘赌选择
- 四、一个简单的实例
-
- 1. 产生初始种群
- 2. 计算适应度
- 3. 选择
- 4. 交叉
- 5. 变异
- 6. 至下一代,适应度计算→选择→交叉→变异,直至满足终止条件
- 五、遗传算法应用
- 六、总结
-
- 遗传算法的特点
- 七、补充
- 八、matlab实例
一、遗传算法的应用
函数优化(遗传算法的经典应用领域);组合优化(实践证明,遗传算法对于组合优化中的NP完全问题,如0-1背包问题,TSP等,非常有效);自动控制;机器人智能控制;组合图像处理和模式识别;人工生命;遗传程序设计;
二、遗传学基本概念与术语
基因型(genotype):性状染色体的内部表现;
表现型(phenotype):染色体决定性状的外部表现,或者说,根据基因型形成的个体;
进化(evolution):逐渐适应生存环境,品质不断得到改良。生物的进化是以种群的形式进行的。
适应度(fitness):度量某个物种对于生存环境的适应程度。
选择(selection):以一定的概率从种群中选择若干个个体。一般,选择过程是一种基于适应度的优胜劣汰的过程。
复制(reproduction):细胞分裂时,遗传物质DNA通过复制而转移到新产生的细胞中,新细胞就继承了旧细胞的基因。
交叉(crossover):两个染色体的某一相同位置处DNA被切断,前后两串分别交叉组合形成两个新的染色体。也称基因重组或杂交;
变异(mutation):复制时可能(很小的概率)产生某些复制差错,变异产生新的染色体,表现出新的性状。
编码(coding):DNA中遗传信息在一个长链上按一定的模式排列。遗传编码可看作从表现型到基因型的映射。
解码(decoding):基因型到表现型的映射。
个体(individual):指染色体带有特征的实体;
种群(population):个体的集合,该集合内个体数称为种群的大小;

三、遗传算法的基本思路
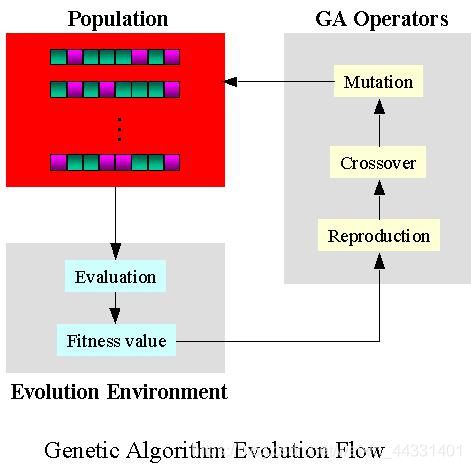
在开始介绍一个实例之前,有必要了解一下轮盘赌选择法,因为基本遗传算法就是用的这个选择策略。
轮盘赌选择
又称比例选择方法.其基本思想是:各个个体被选中的概率与其适应度大小成正比.
具体操作如下:
(1)计算出群体中每个个体的适应度f(i=1,2,…,M),M为群体大小;
(2)计算出每个个体被遗传到下一代群体中的概率;
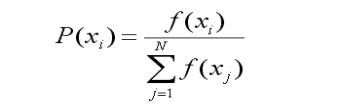
(3)计算出每个个体的累积概率;
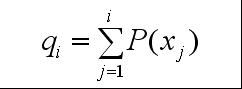
(q[i]称为染色体x[i] (i=1, 2, …, n)的积累概率)

(4)在[0,1]区间内产生一个均匀分布的伪随机数r;
(5)若r
注意:
个体排序顺序会影响“轮盘赌”法;
当适应性值相差不大的情况,该方法与随机选没有什么区别,此时难于控制进化方向和速度;
该方法是属于有放回的的选择,不适合不放回的情况
四、一个简单的实例
1. 产生初始种群
s1= 13 (01101)
s2= 24 (11000)
s3= 8 (01000)
s4= 19 (10011)
2. 计算适应度
假定适应度为f(s)=s^2 ,则
f (s1) = f(13) = 13^2 = 169
f (s2) = f(24) = 24^2 = 576
f (s3) = f(8) = 8^2 = 64
f (s4) = f(19) = 19^2 = 361
3. 选择
染色体的选择概率为:

染色体的累计概率为:

根据上面的式子,可得到:

例如设从区间[0, 1]中产生4个随机数:
r1 = 0.450126, r2 = 0.110347
r3 = 0.572496, r4 = 0.98503

4. 交叉
基本遗传算法(SGA)中交叉算子采用单点交叉算子。
单点交叉运算

5. 变异

6. 至下一代,适应度计算→选择→交叉→变异,直至满足终止条件
五、遗传算法应用
这里使用具体的应用例子:函数优化
-
问题的提出
一元函数求最大值:
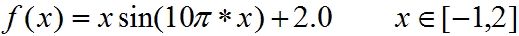

用微分法求取f(x)的最大值:

可求得最大值点:f(1.85)=3.85
-
- 编码
表现型:x
基因型:二进制编码(串长取决于求解精度)
串长与精度之间的关系:
若要求求解精度到6位小数,区间长度为2-(-1)=3,即需将区间分为3/0.000001=3×106等份。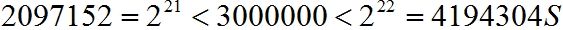
所以编码的二进制串长应为22位
- 编码
-
-
产生初始种群
产生的方式:随机
产生的结果:长度为22的二进制串
产生的数量:种群的大小(规模),如30,50,…
1111010011100001011000
1100110011101010101110
1010100011110010000100
1011110010011100111001
0001100101001100000011
0000011010010000000000
-
-
-
计算适应度
不同的问题有不同的适应度计算方法
本例:直接用目标函数作为适应度函数
①将某个体转化为[-1,2]区间的实数:
s=<1000101110110101000111> → x=0.637197
②计算x的函数值(适应度):
f(x)=xsin(10πx)+2.0=2.586345(0000000000000000000000)→-1
(1111111111111111111111)→2上面的①其实就是二进制与十进制之间的转换:
第一步,将一个二进制串(b21b20…b0)转化为10进制数:
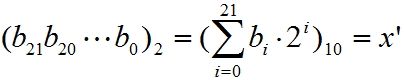
第二步,x’对应的区间[-1,2]内的实数

-
-
- 遗传操作
选择:轮盘赌选择法;
交叉:单点交叉;
变异:小概率变异
模拟结果
设置的参数:
种群大小50;交叉概率0.75;变异概率0.05;最大代数200。
得到的最佳个体:
smax=<1111001100111011111100>;
xmax=1.8506;
f(xmax)=3.8503;
运行结果





六、总结
-
编码原则
完备性(completeness):问题空间的所有解都能表示为所设计的基因型;
健全性(soundness):任何一个基因型都对应于一个可能解;
非冗余性(non-redundancy):问题空间和表达空间一一对应。 -
适应度函数的重要性
适应度函数的选取直接影响遗传算法的收敛速度以及能否找到最优解。
一般而言,适应度函数是由目标函数变换而成的,对目标函数值域的某种映射变换称为适应度的尺度变换(fitness scaling)。 -
适应度函数设计不当有可能出现欺骗问题:
(1)进化初期,个别超常个体控制选择过程;
(2)进化末期,个体差异太小导致陷入局部极值。 -
欺骗问题举例:
可以想象一下,假设地球像类似灾难电影《后天》一样,出现有毒的雾霾,喜马拉雅山脉下有100只猴子(种群大小),只有爬上珠穆朗玛峰顶端的猴子才能生存下来,
因为喜马拉雅山脉有很多山峰,我们以高度作为适应度,case(1):如果不在珠峰的猴子若比在珠峰半山腰的猴子要高,因为种群大小不变,在珠峰的猴子可能就会被淘汰;
case(2):100只猴子都不在珠峰;
-
选择的作用:优胜劣汰,适者生存;
-
交叉的作用:保证种群的稳定性,朝着最优解的方向进化;
-
变异的作用:保证种群的多样性,避免交叉可能产生的局部收敛;
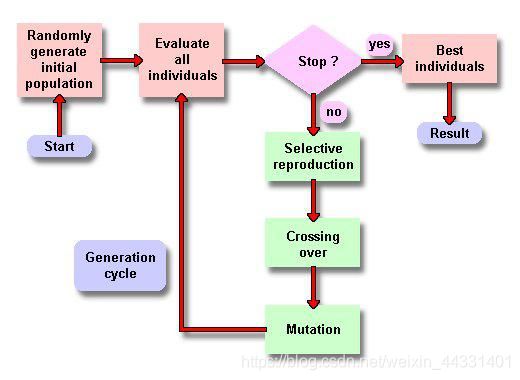
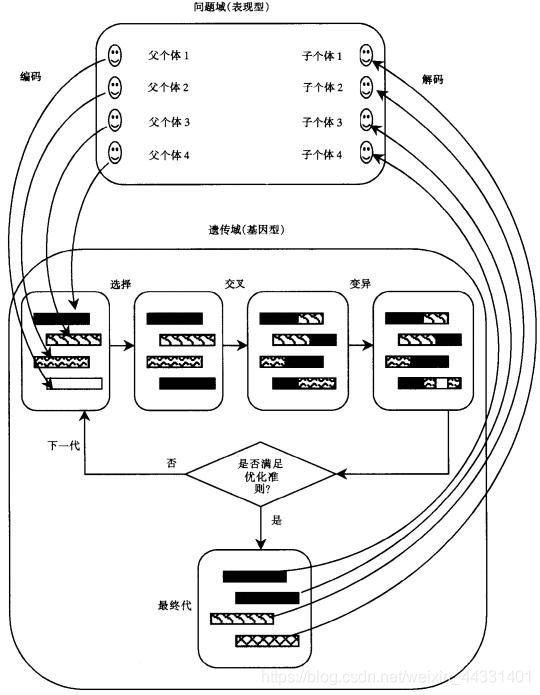
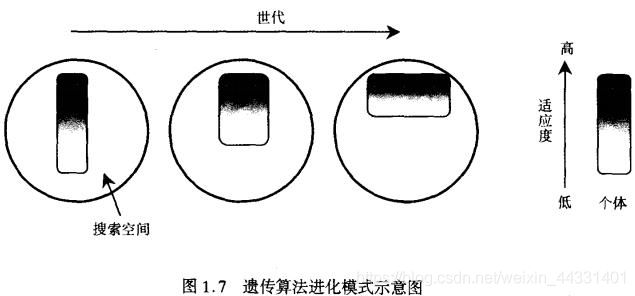
下图很好地表现了遗传算法的精髓。
遗传算法的特点
-
自组织、自适应和自学习性
在编码方案、适应度函数及遗传算子确定后,算法将利用进化过程中获得的信息自行组织搜索。 -
本质并行性
内在并行性与内含并行性 -
不需求导
只需目标函数和适应度函数 -
概率转换规则
强调概率转换规则,而不是确定的转换规则
七、补充
因为遗传算法的每个操作对不同的应用选择的策略各有优劣,所以具体情况,具体分析,在此附上:
- 选择
适应度计算:
按比例的适应度函数(proportional fitness assignment)
基于排序的适应度计算(Rank-based fitness assignment)
选择算法:
轮盘赌选择(roulette wheel selection)
随机遍历抽样(stochastic universal selection)
局部选择(local selection)
截断选择(truncation selection)
锦标赛选择(tournament selection)
- 交叉
因为编码分二进制和浮点数编码,所以交叉和变异都有两类;
实值重组(real valued recombination):
离散重组(discrete recombination)
中间重组(intermediate recombination)
线性重组(linear recombination)
扩展线性重组(extended linear recombination)
二进制交叉(binary valued crossover):
单点交叉(single-point crossover)
多点交叉(multiple-point crossover)
均匀交叉(uniform crossover)
洗牌交叉(shuffle crossover)
缩小代理交叉(crossover with reduced surrogate)
- 变异
实值变异
二进制变异
另外,遗传算法背后的理论支撑——模式定理,可以在对遗传算法有深入研究和优化的时候再详看。
八、matlab实例
用标准遗传算法求函数f(x)=x+10sin(5x)+7cos(4x)的最大值,其中x取值范围为[0,10]。这是一个有多个局部极值的函数

解:仿真过程如下:
(1)初始化种群数目为NP=50,染色体二进制编码长度为L=20,最大进化代数为G=100,交叉概率为Pc=0.8,变异概率为Pm=0.1
(2)产生初始种群,将二进制编码转换成十进制,计算个体适应度值,并进行归一化;采用基于轮盘赌的选择操作、基于概率的交叉和变异操作,产生新的种群,并把历代的最优个体保留在新种群中,进行下一步遗传操作。
(3)判断是否满足终止条件:若满足,则结束搜索过程,输出优化值;若不满足,则继续进行迭代优化。
%该文件为func1.m
%%%%%%%%%%%%%%%%%%%%%%%%%适应度函数%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function result=func1(x)
fit= x+10*sin(5*x)+7*cos(4*x);
result=fit;
%%
%该脚本是LU在随书源代码的基础上改动,20200915该脚本在matlabR2019a上成功运行
%%%%%%%%%%%%%%%%%%%%标准遗传算法求函数极值%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%初始化参数%%%%%%%%%%%%%%%%%%%%%%%%%%
clear all; %清除所有变量
close all; %清图
clc; %清屏
NP=50; %种群数量
L=20; %二进制数串长度
Pc=0.8; %交叉率
Pm=0.1; %变异率
G=100; %最大遗传代数
Xs=10; %上限
Xx=0; %下限
f=randi([0,1],NP,L); %LU20200915注:随机获得初始种群,储存为50行20列的矩阵,二进制编码所以加上[0,1]
%%
%20200915改动该行代码,将函数由大写改成小写
%X = randi(imax,n) 返回 n×n 矩阵,其中包含从区间 [1,imax] 的均匀离散分布中得到的伪随机整数。
%随书源代码为f=RANDI(NP,L); %随机获得初始种群
%%
%%%%%%%%%%%%%%%%%%%%%%%%%遗传算法循环%%%%%%%%%%%%%%%%%%%%%%%%
for k=1:G
%%%%%%%%%%%%将二进制解码为定义域范围内十进制%%%%%%%%%%%%%%
for i=1:NP
U=f(i,:); %LU20200915注:遍历种群的每个个体
m=0;
for j=1:L
m=U(j)*2^(j-1)+m; %LU20200915注:m即为二进制转换后的十进制数值,此m为第i个体对应的的十进制数值
end
x(i)=Xx+m*(Xs-Xx)/(2^L-1); %LU20200915注:将个体由十进制数值扩缩为,问题中的约束x取值范围[0,10]内
Fit(i)= func1(x(i)); %LU20200915注:计算个体的适应度
end
maxFit=max(Fit); %最大值
minFit=min(Fit); %最小值
rr=find(Fit==maxFit); %LU20200915注:find查找非零元素的索引和值,找到maxFit是哪一个个体并传给rr
fBest=f(rr(1,1),:); %历代最优个体
xBest=x(rr(1,1)); %LU20200915注:历代最优的x值
Fit=(Fit-minFit)/(maxFit-minFit); %归一化适应度值
%%%%%%%%%%%%%%%%%%基于轮盘赌的复制操作%%%%%%%%%%%%%%%%%%%
sum_Fit=sum(Fit);
fitvalue=Fit./sum_Fit; %LU20200915注:用fit矩阵的每个数值除以sum_Fit ,fitvalue即为个体被选取的概率
fitvalue=cumsum(fitvalue); %LU20200915注:cumsum(A) 从 A 中的第一个其大小不等于 1 的数组维度开始返回 A 的累积和
ms=sort(rand(NP,1)); %LU20200915注:rand均匀分布的随机数;由随机数组成的 NP×1 向量
fiti=1;
newi=1;
while newi<=NP
if (ms(newi))结果显示
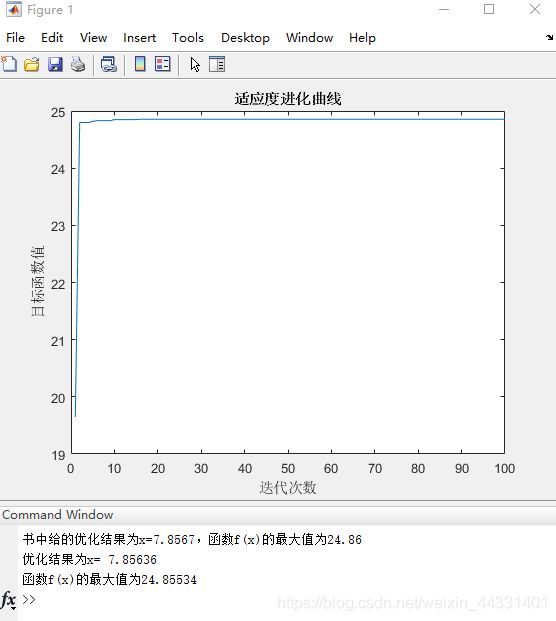
参考https://my.oschina.net/u/1412321/blog/192454
智能优化算法及其MATLAB实例(第二版)[包子阳,余继周][电子工业出版社][2018年01月]