深度学习入门理论(结合情绪识别)
文章目录
-
- 1.人工智能的历史
- 表情识别的意义和基本流程
- 机器学习和卷积神经网络
- 3维数据的卷积运算
- 池化层
- CNN的可视化
- 2.卷积神经网路和循环神经网络的区别
- 3.注意力机制的概念
-
-
- 准确率和召回率:
-
- 参考文献:
1.人工智能的历史
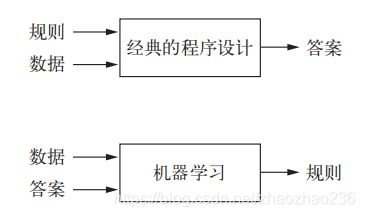
- 早期的国际象棋仅包含程序员精心编写的硬编码规则,并不属于机器学习,这种方法称为符号主义人工智能。
- 机器学习是一种新的方法,来代替符号主义的人工智能。传统的人工智能(符号主义人工智能),人输入的是规则,输出的是答案,而机器学习,人输入的是数据和从这些数据中预期得到的答案,系统输出的是规则,将这些规则应用于新的数据,并使计算机自动生成答案。
2.深度学习的三个要素
- 输入数据点:如果是语音识别,可能是音频,图像处理话数据点可能就是图像。
- 预期输出示例:预期输出可能是 “猫” “狗”之类的标签。
- 衡量方法:计算算法的输出和我们预期输出的差距。衡量结果是一种反馈信号,用来调整算法。
表情识别的意义和基本流程
1.表情识别的意义
美国加州大学教授Albert Mehrabian把人的感情表达效果总结了一个公式:感情的表达= 7%的语言+ 38%的声音+ 55%的表情。可见表情在人类所有感情的外在表达中占据的重要位置。
2.表情分类:
我们的模型也依据由Ekman和Friesen定义的人类的七种基本表情:高兴(happy)、生气(angry)、吃惊(surprise)、恐惧(fear)、厌恶(disgust)、悲伤(sad)和中立(neutral)。
3.完整的FER系统分为三个阶段:(facial expression recognition)
1.人脸的检测与定位;
2.面部表情特征的提取;
3.训练一个分类器(如svm)来用于分类提取到的特征;
4.人脸识别系统的具体流程图:

零均值化(中心化)和归一化(标准化):
在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表征的。比如在预测房价的问题中,影响房价的因素有房子面积、卧室数量等,我们得到的样本数据就是这样一些样本点,这里的、又被称为特征。很显然,这些特征的量纲和数值得量级都是不一样的,在预测房价时,如果直接使用原始的数据值,那么他们对房价的影响程度将是不一样的,而通过标准化处理,可以使得不同的特征具有相同的尺度,
下边是个例子:直观上的感觉,先中心化,然后再标准化
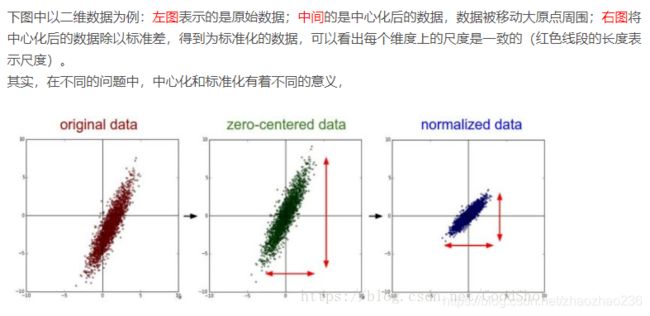
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
数据的归一化是把数变为(0,1)之间的小数主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
归一化和标准化有利于模型的收缩,详细将参考文献3标准化和归一化
5.基于传统方法和基于深度学习的方法的不同:
基于手工特征分类的方法主包括选取不同的特征,在搭配以不同的分类算法; 而基于深度学习的方法,主要是包括如何搭建和训练不同的网路模型;
基于深度学习的方法:

神经网络的巨大优势,就是把传统的机器学习的 “特征+分类” 两步合二为一。输入是原始数据,输出就是目标种类的标签
机器学习和卷积神经网络
6.机器学习的引言
十年前,训练神经网路一个非常复杂的问题,因为他庞大的计算力和计算时间,还有训练时常容易陷入局部最优化导致的模型泛化能力不强。但是最近十年,随着 GPU 和 并行计算的普及,以及新的训练模型方法的出现;
神经网络的结构
- 输入层 : 神经网路的第一层;
- 隐藏层: 隐藏层越多,非线性就越显著;
- 输出层: 神经网路的最后一层,输出最终的分裂结果;
卷积神经网络(CNN)
通过卷积和空间采样操作,卷积网路能充分发挥二维数据(如图片和声音)的优势,同时克服了传统前反馈神经网络在高维度输入模型参数过多,计算困难的缺点,通过参数共享的方式大大降低了模型的复杂度。
- 如果相邻层的所有神经元之间都有连接,成为全连接
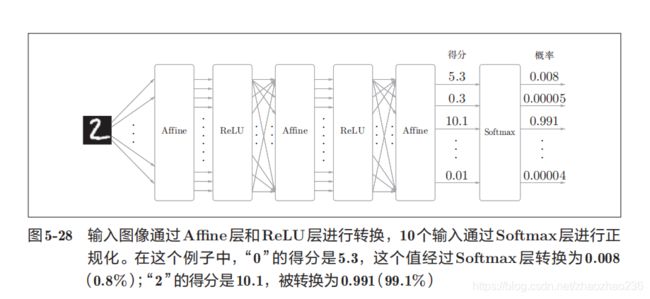
- 传统的神经网络用Affine层实现了全连接(Affine层就是通过权重加偏移进行运算)。后边紧跟着 ReLU (大于0时候直接传输,小于0的时候直接舍弃)或者 Sigmoid 层。。。下面的图由四层 “Affine—ReLU” 层组合,第五层是 Affine 层,最后通过 Softmax 层输出。

softmax层的概念
卷积神经网路,就相当于。在新增了 Convolution 层和 Pooling 层,CNN的连接顺序是 “Convolution-ReLU-(Pooling)” ,有时候 Pooling 层会被省略。。。还有最接近输出层使用了 “Affine-ReLu” 组合,最后的输出层使用了 “Affine-Softmax” 组合。这回事一般的CNN中最常见的结构。

全连接层存在的问题:
全连接层把数据的形状给忽略了,通常的图像是 3 维的形状,但是在向全连接层输入的时候,却被拉成一维的了。。本来RBG的各个通道中间有密切的联系,这些在全连接层都会别忽略。。。。。而CNN中可以保持形状不变,以 3 维的数据形式接收输入的数据,同样以 3 维的数据形式输出至下一层。
卷积神经网路的相关术语
卷积层的输入称为输入特征图;
卷积层的输出称为输出特征图;
卷积运算 卷积层进行的处理就是卷积运算。卷积运算相当于图像处理中的 “滤波运算”。卷积运算是以一定的间隔滑动滤波器。将各个位置上过滤器的元素和输入的对应元素相乘,然后再求和输出。;
滤波器上的参数对应神经网路中的权重,并且滤波器也存在权重。
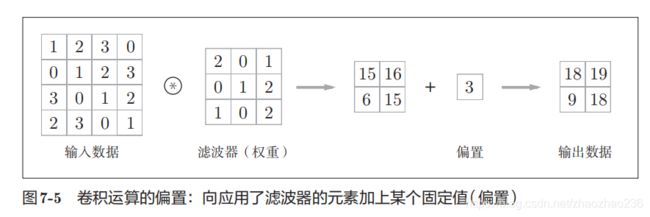
有时要向输入数据的周围,填入固定的数据,这称为填充:
通过填充,原本大小为(4,4)的变成了(6, 6)的形状;
填充是为了调整输出的大小。比如,对(4,4)的输入特征图,应用(3,3)的特征图,最后的输出会变成(2, 2),这样进行多次卷积运算,最后的结果有可能会变成1,导致再也无法应用卷积神经网络,比如刚才的例子,将填充的幅度设为1,那么相对于输入大小(4,4),输出大小是(4, 4),这样卷积运算就可以保持空间大小不变的情况下将数据传给下一层。

步幅:滤波器的间隔称为步幅。(详细看下图)

增大步幅以后,输出的大小会变小,增大填充以后,输出的大小会变大。他们两个的具体关系如下:(这种算法只能应用于可以出尽的情况,如果输无法除尽,就要下去报错等措施)
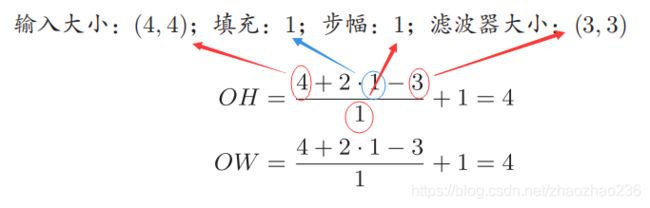
3维数据的卷积运算
之前的卷积运算的例子,都是只有高和长的2维图像,但是,图像是3维图像。下边是图,可以发现纵深方向(即 通道方向)上的特征图增加了,通道方向上有多个特征图时,会按照通道进行卷积运算,最后将结果相加,得到输出。(输入数据和滤波器的通道数要设为相同的值)
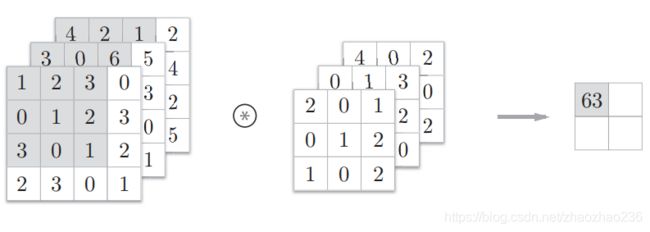
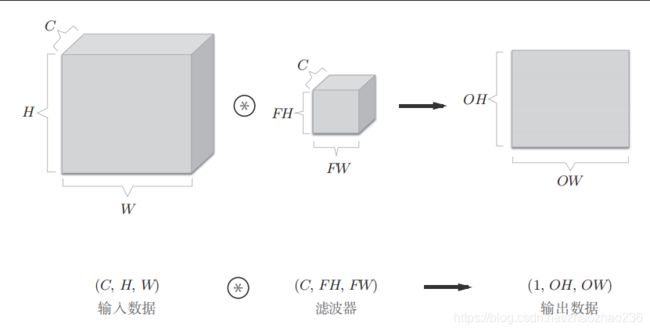
通道数,长宽高的书写顺序如下:(这个例子中,数据输出是一张特征图,换句话说就是通道数为1的特征图)
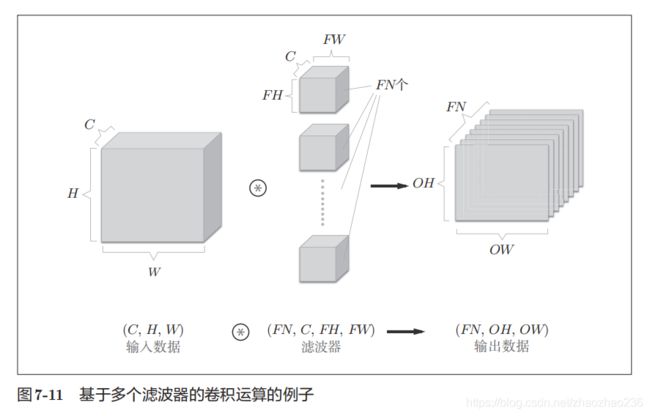
如果要在多个通道方向上也拥有卷积运算,就要用到多个滤波器,图如下:
池化层
池化是缩小高,长方向上的空间运算。
Max 池化是获得最大值的运算,具体的运算结果如下图
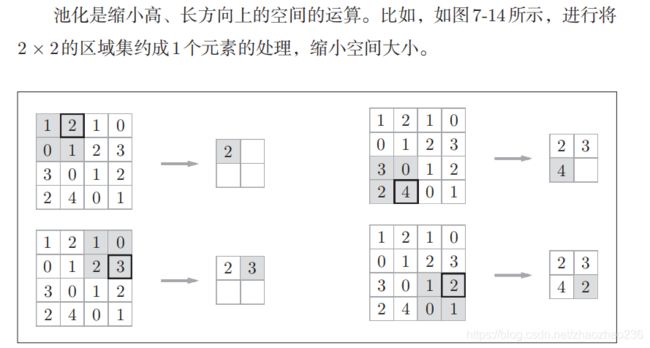
另外,一般的,池化层窗口的大小,会和步幅设定成同样的值。除了max 池化以外,还有 Average 池化层(求平均值)。但是在图像识别领域,主要使用Max池化。
池化层具有的特点:
- 池化只是从目标区域中取最大值,所以不存在要学习的参数
- 对微小的位置具有鲁棒性(健壮)
- 经过池化运算,输入数据和输出数据的通道数是不会发生改变的。这和卷积层明显的不同。

CNN的可视化
学习前的滤波器是随机进行初始化的,二学习后的滤波器就变成了有规律的图像,比如从黑到白渐变的滤波器,含有块状区域(称为 blob )的滤波器。

2.卷积神经网路和循环神经网络的区别
即 CNN 和 RNN 的区别:区别在于循环层上,卷积神经网络没有时序性的概念,输入直接和输出挂钩,循环神经网路具有时序性,当前决策和前一次决策有关。
举个例子,手写数字识别,我们并不在意前一个决策结果是什么,所以需要卷积神经网络,而自然语言处理时候,上一个词很大程度上影响了下一个词,所以需要用循环神经网络。
长短期记忆网络(LSTM) 和门控制循环单元(GRU),是最常用的两种循环神经网络结构。
3.注意力机制的概念
人的注意力机制
人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段
自注意力机制和注意力机制:
自注意力机制允许输入之间彼此交互,并找出他们应该给哪些对象更多的注意力。
准确率和召回率:
- 召回率:正样本中有多少被找出来了(召回多少)
- 精确率:你认为的正样本,有多少猜对了(猜的精确度如何)
举个例子:
准确率=(我觉得有故障中的真有故障的)/ 我觉得有故障的、
召回率=(我觉得有故障中的真故障)/ 真有故障的
前天参加了一场考试,一共100道题目(每题1分)因为考试太难而且时间紧张,最后只答了60道,剩下40题还没来得及写就交卷了,md完蛋了一周后老师公布分数,哇!只有20分!泪奔……老子答了60题只对20题,准确率只有33%!后来老师发下卷子,自己仔细看了一下,那40道没来得及做的题目里其中有30道,其实我是会做的!但居然没做!本来这场考试自己有机会拿50分…… (虽然20+30还是不及格,但如果该拿分的都拿了,就不遗憾!)可最后50里只拿20,召回率只有40%!
召回率可以这么理解:就像考试,给自己找理由,我TM 剩下的都会做,可是没来得及,剩下的我都会,我应该考80的。为了方便找借口,然后你就给你自己发明了一个新词 " 召回率 " 。
参考文献:
【1】浙江大学论文 基于卷积网络集成的面部表情识别方法
【2】CSDN 中心化和标准化
【3】标准化和归一化
【4】如何解释召回率与精确率? - scarlet.MP5的回答 - 知乎