【笔记】Attention Is All You Need 论文分析1:流程介绍
本文对注意力机制进行总结,参考论文为“Attention is All You Need”。
在介绍“Attention is All You Need”中提出的Transformer之前,先总结一下处理序列数据的模型的发展过程。
在RNN出现之前,卷积神经网络CNN和普通的算法大部分都是输入和输出的一一对应,也就是一个输入得到一个输出。不同的输入之间是没有联系的,但是对于处理序列数据,比如机器翻译等,前面的输入对后面应该是有影响的,因此提出RNN,用来处理「序列数据 – 一串相互依赖的数据流」的场景。
- RNN
RNN(Recurrent Neural Network)循环神经网络是一类用于处理序列数据的神经网络,传统神经网络的结构为:输入层 – 隐藏层 – 输出层,如图1。相比于之前的神经网络RNN最大的区别在于每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练。如图2:
图1 传统神经网络结构
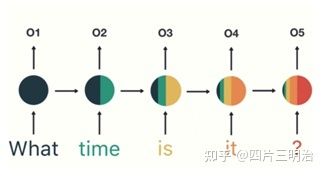
图2 RNN过程
RNN的基本结构:

图3 RNN基本结构
但是同时也可以看出RNN也存在一定的缺陷,短期的记忆影响较大(如图2中的橙色区域),但是长期的记忆影响就很小(如图2中黑色和绿色区域),这就是 RNN 存在的短期记忆问题,不适合处理长序列问题。同时在训练时会出现梯度消失或者梯度爆炸的问题。
- LSTM:长短期记忆网络
为了解决RNN中存在的梯度消失和梯度爆炸的问题,因为这个问题的存在,RNN没办法回忆起久远的记忆,因此在RNN基础上提出了LSTM,相比于普通的RNN,LSTM多出了三个控制器,分别是输入控制,输出控制和忘记控制,能更好的提取长期信息。
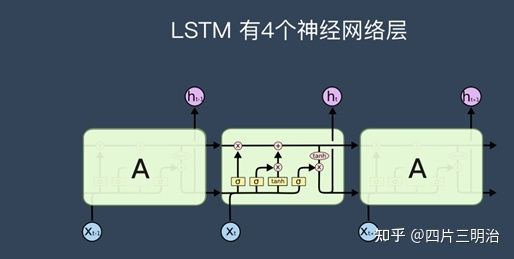
图4 LSTM基本结构
Gated Recurrent Unit (GRU)就是lstm的一个变体,它将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,是非常流行的LSTM的变体。
虽然模型在不断的改进,但是之前的模型依然存在一定的问题,RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片t的计算依赖t-1时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
而Transformer的提出解决了上面两个问题,突破了序列化模型的限制。
一、Transformer主要框架:
1. 输入数据:
通过Word2Vec等词嵌入方法将输入语料转化成特征向量,论文中使用的词嵌入的维度为512。
2. 基本结构:
Transformer的本质上是一个Encoder-Decoder的结构:
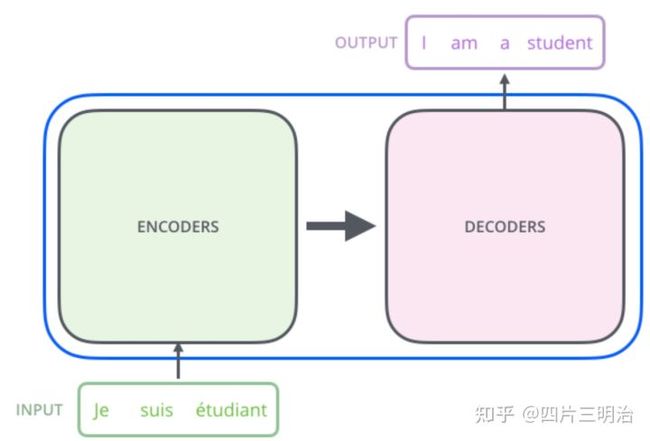
图5 Encoder-Decoder的结构
如论文中所设置的,编码器由6个编码block组成,同样解码器是6个解码block组成。与所有的生成模型相同的是,编码器的输出会作为解码器的输入:

图6 Encoder-Decoder的结构
进一步来看结构如下:

图7 Transformer模型的结构
二、详细分析
下面对transformer的结构进行详细分析:
Encoder:
以“我有一只猫”为例,整体的Encoder由6个下面基础的encoder模块构成:
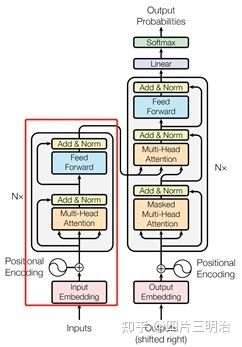
图8 Transformer模型的encoder部分的结构
1) 输入:
- 词嵌入方法得到的“我有一只猫”中每一个词的特征向量,维度为 dmodel=512.
- Position encoding:在self-attention中使用的是全局信息,没有考虑位置信息,但在翻译中位置信息十分重要。因此考虑加入Position encoding来加入这个部分信息,生成的向量维度和词的特征向量维度相同,在本文中为512。具体方法如下:

其中,pos 表示单词在句子中的位置, PE 的维度d与词 Embedding 一样,也是512,i 是每个维度,2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。记住 “奇数位:cos,偶数位:sin”。
举个例子:我 有 一只 猫
其中“一只”的pos=3,并且 dmodel=512 ,因此得到的位置的向量为:
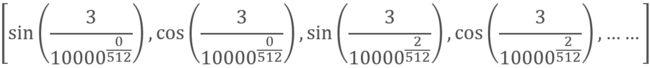
- 最后,将通过词嵌入方法得到的特征向量和Position encoding得到的向量求和得到最终的输入X。

图9 输入数据的构成
2) 注意力模块:
在Transformer的encoder中,输入数据首先会经过一个叫做“multi-head attention”的模块,它是由多个‘self-attention’的模块所构成的,因此先来研究‘self-attention’.
self-attention
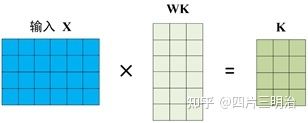
- Q,K,V的计算过程:
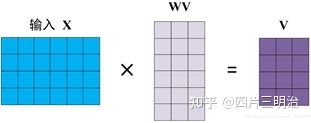
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量 Q ,Key向量 K 和Value向量 V ,长度均是64。它们是通过嵌入向量 X 乘以三个不同的权值矩阵 WQ,WK,WV 得到,其中三个矩阵的尺寸也是相同的。均是 512×64 ,注意 X, Q, K, V 的每一行都表示一个单词下图为计算过程的示意图:

在得到Q,K,V后,‘self-attention’经过计算最终得到一个特征向量Z,这个Z就是论文中公式1中的Attention(Q,K,V):
![]()
下面介绍一下具体的计算过程:
论文中的图:

图10 self-attention计算过程
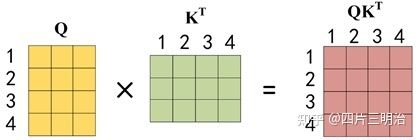
第一步:Q 乘以 K 的转置后,得到的这个矩阵可以表示单词之间的 attention 强度。下图为 Q 乘以 K 的转置,1234 表示的是句子中的单词。
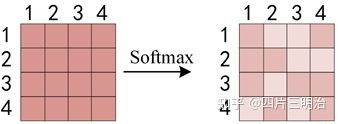
第二步:得到 QKT 之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1。
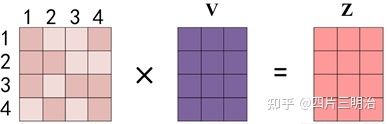
第三步: Softmax 矩阵之后可以和 V 相乘,得到最终的编码信息输出 Z。
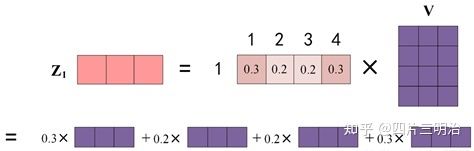
第四步:上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出 Z1 等于所有单词值 Vi 根据 attention 系数的比例加在一起得到,如下图所示:
这里要注意:
- Q,K,V的含义:
Query,Key,Value的概念取自于信息检索系统,举个简单的搜索的例子来说。当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容(Value)。在机器翻译中value和key是一个。
self-attention中的Q,K,V也是起着类似的作用,在矩阵计算中,内积是计算两个矩阵相似度的方法之一,因此式1中使用了 QKT 进行相似度的计算。接着便是根据相似度进行输出的匹配,这里使用了加权匹配的方式,而权值就是query与key的相似度。
- 键向量,查询向量,值向量维度:
键向量,查询向量,值向量维度一般比Embedding词向量低,在原论文中是输入单词Embedding维度的 1/8,(思考:为什么维度要变成Embedding词向量1/ 8,因为论文刚好建立了 8 个 自注意力机制,每个自注意力机制的 Q, K, V 维度就是(512 / 8), 最后再拼接这 8 个自注意了机制的结果,维度也能回到 512,然后再输入到下一个encoder模块中,保证每次输入的维度都是512).
multi-head attention
在论文中用到的是Multi-Head Attention,它相当于 h 个不同的self-attention的集成(ensemble),在这里我们以 h=8 举例说明。Multi-Head Attention的输出分成3步:
a) 将数据 X 分别输入到上图所示的8个self-attention中,得到8个加权后的特征矩阵 Zi,i=1…8 。
b) 将8个 Zi 按列拼成一个大的特征矩阵;
c) 特征矩阵经过一层全连接后得到输出 Z 。

图11 Multi-Head Attention计算过程
可以看到 Multi-Head Attention 输出的矩阵 Z 与其输入的矩阵 X 的维度是一样的,这也是键向量,查询向量,值向量维度设置为64的原因。
其中 Zi 拼接的方式为:

图12 Z的拼接方式
3) Add&Norm
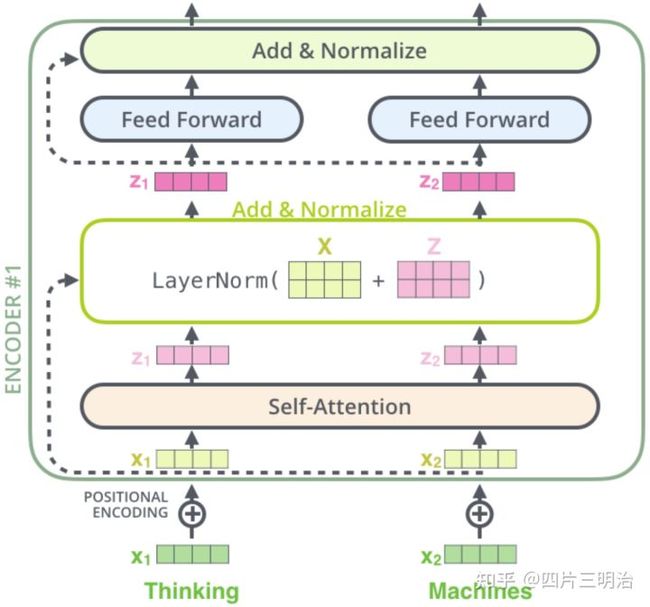
图13 Add&Norm计算过程
在Multi-Head Attention之后的Add&Norm计算公式为:
![]()
在Feed Forward之后的Add&Norm计算公式为:
![]()
Add就是残差连接,残差连接简单说就是:计算几层输出之后再把x加进来。残差网络可以有效的解决梯度消失的问题。
而norm是对向量进行层归一化,具体计算方法为:

图14 归一化计算方法
4) Feed Forward
这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为:
![]()
Feed Forward 最终得到的输出矩阵的维度与 X 一致,都是(m×512)。
5) Encoder部分的最终结果:
在encoder部分要经过6次上述的encoder模块,最终的输出结果为:维度为(m×512)的矩阵。
Decoder
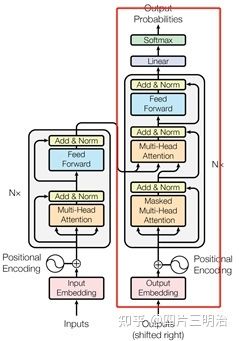
图15 Decoder部分结构
下面以 “我有一只猫” 翻译成 “I have a cat” 为例,
1) 输入:
输入分为两部分,第一部分为Masked Multi-Head Attention之前,“I have a cat”通过词嵌入方法得到的向量与位置向量的和X作为输入。第二部分为Multi-Head Attention前输入的encoder的结果。
2) Masked Multi-Head Attention:
和Multi-Head Attention的过程基本相同,但是采用了Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息,这样符合翻译的过程。
下面以 “我有一只猫” 翻译成 “I have a cat” 为例,了解一下 Masked 操作。具体的操作步骤如下:
用 0 1 2 3 4 5 分别表示 “< Begin > I have a cat < end >”。
第一步:Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 “< Begin > I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。

第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵 X 计算得到 Q, K, V 矩阵。然后计算 Q 和KT 的乘积 QKT 。
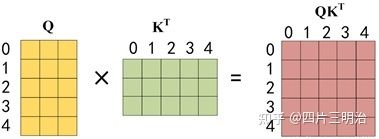
第三步:在得到 QKT 之后需要进行 Softmax,计算 attention score, 但我们在 Softmax 之前需要使用 Mask 矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
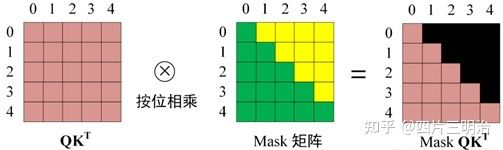
得到 Mask QKT 之后在 Mask QKT 上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0, 因为它们被遮盖住了,不需要关注。
第四步:使用 Mask QKT 与矩阵 V 相乘,得到输出 Z,则单词 1 的输出向量 z1 包含单词 0和单词1的信息。
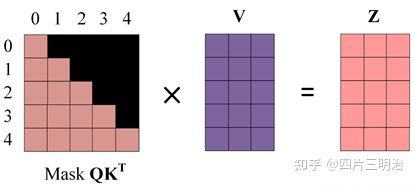
第五步:通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵 Zi ,然后和Encoder 类似,通过拼接多个输出 Zi ,然后计算得到第一个 Multi-Head Attention 的输出 Z,Z与输入 X 维度一样。
3) Add&Norm
添加残差连接,并进行归一化,同encoder中的公式一样。
4)Multi-Head Attention
计算方法和encoder中的一致,但是输入数据有差别,因此Q,K,V的计算也有差别,具体如下:输入的数据分为两部分,一部分是从Masked Multi-Head Attention经过归一化后的结果,一部分是encoder输出的结果Z,其中K, V 矩阵使用 Encoder 的编码信息矩阵 Z 进行计算(Encoder是使用输入X或前一个encoder的输出),而 Q 使用Masked Multi-Head Attention经过归一化后的矩阵进行计算。
5) Feed Forward
同encoder中的公式一样。
6) Linear和Softmax
经过6层的decoder后,结果进入Linear和Softmax,线性层将前面decorder模块输出的向量映射成词典维数的向量,然后经过Softmax层:
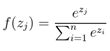
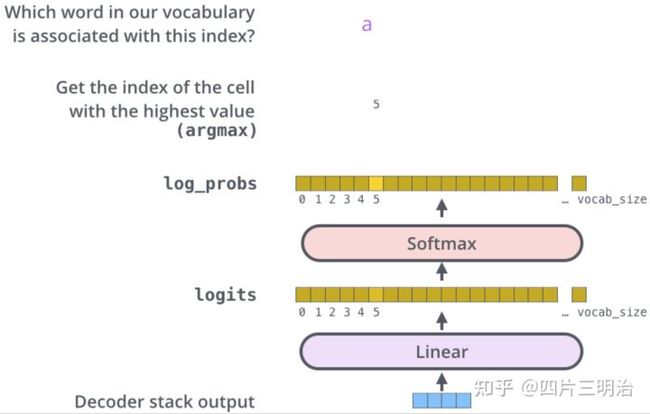
图16 翻译结果的输出过程
最后再来回顾一下整个过程:
第一步:获取输入句子的每一个单词的表示向量X,X由单词的 Embedding 和单词位置的 Embedding 相加得到。
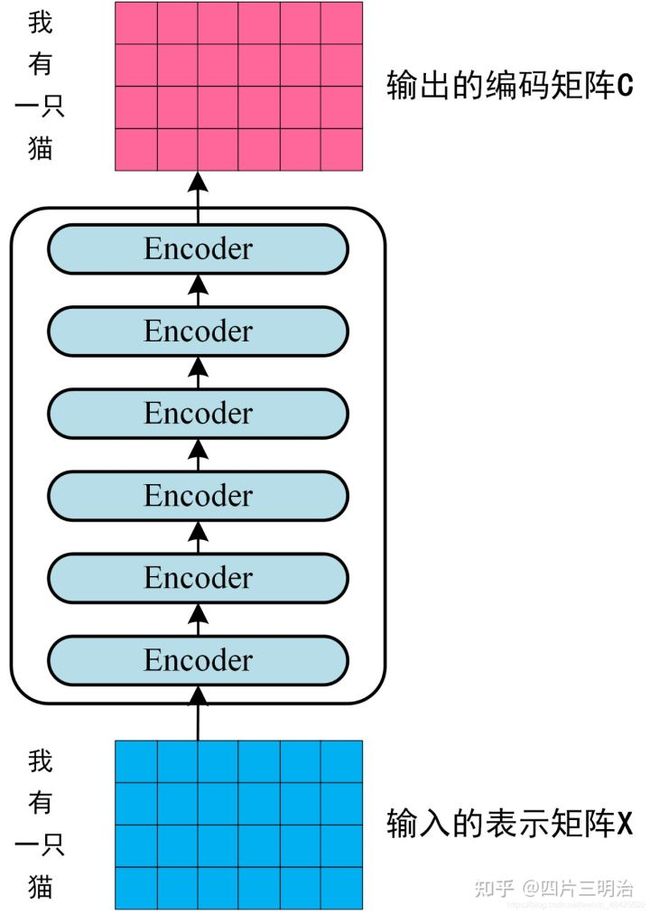
第二步:将得到的单词Embedding矩阵 (如:我有一只猫,矩阵每一行是一个单词的词向量表示 x) 传入编码器 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 Z,如下图。单词向量矩阵用 X(m×d) 表示,m是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
第三步:将 Encoder 输出的编码信息矩阵Z 传递到解码器中,编码器依次会根据当前翻译过的 1~ i 个单词,翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。

上图的解码器接收了 编码器的信息矩阵Z,然后先传入一个翻译开始符 “< Begin >”,预测第一个单词 “I”;然后传入翻译开始符 “< Begin >” 和单词 “I”,预测下一个单词 “have”,以此类推。
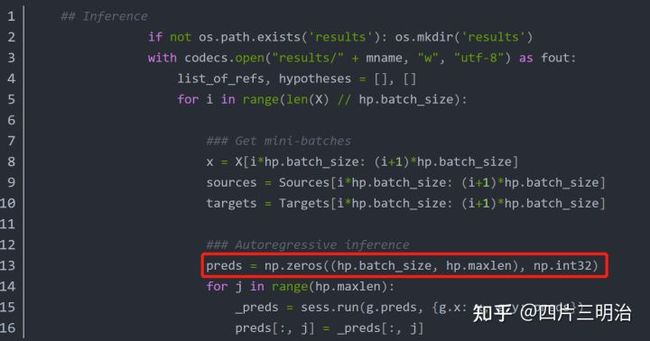
注意:
在利用模型进行预测时,decoder部分的输入是什么?
预测时decoderd部分的输入初始化翻译结果为int32类型的一个张量,初始值为0 ,shape为[hp.banch_size,hp.maxlen],代码如下图: