pandas数据分析方法
利用pthon进行数据分析-pandas
- 环境配置
-
- 安装pandas、numpy、xlrd
- 数据的读取
-
- 创建文件
- 读写csv或txt数据
- 读写mysql数据
- 读取与修改excel数据
- -*- coding:utf-8 -*-
- Pandas数据结构
-
- Series
- DataFrame
- DateFrame连接
- 列之间计算
- 数据清洗
- 数据替换
- 分箱操作
- 字符串操作
- excel文件拆分合并
- 分组聚合Groupby
- 数据处理三板斧
- Pandas计算差值、同比、环比
- 时间序列
- 分享案例
环境配置
安装pandas、numpy、xlrd
1.使用cmd pip install pandas
2.安装xlrd,否则打不开excel文件
3. 使用这个路径下载模块https://pypi.tuna.tsinghua.edu.cn/simple
数据的读取
创建文件
excel文件并写数据,to_csv同理,to_sql则需要连接数据库操作
import pandas as pd
路径=r'D:\pandas测试\张绍林.xlsx'
data1={'num':[1,2,3,4,5],'name':['tom','jerry','geroge','apple','pear'],'age':[12,23,24,25,26]}
data=pd.DataFrame(data1)
data=data.set_index('num') #重新设置索引,不设置的话会新增一列索引列,从0开始
data.to_excel(路径)
print('success')
读写csv或txt数据
dataframe描述数据集方法
read_csv(方法)()
①sep=‘’ 默认逗号分隔
②header=None/0 列名的行号,默认0第一行,设置为None后为无列名,自增数字为列
③names=[]自定义设置列名,与header=None配合,不一定数量保持一致
④index_col=[]设置索引列,可以是多个,检索df[‘列名’][‘索引名’]实现数据查找
⑤skiprows[]需要跳过行的列表
⑥encoding=‘utf-8’ /‘gbk’编码规则
⑦nrows=3 代表读取前几行
⑧chunksize=1000,代表可以每一千行读取数据,然后分步处理
⑨parse_dates 直接设置为datetime
import pandas as pd
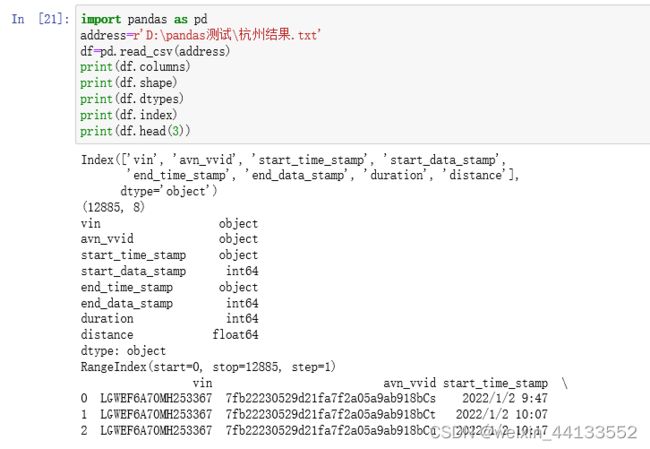
address=r'D:\pandas测试\杭州结果.txt'
data=pd.read_csv(address,sep=',',header=None,names=['a','b','c','d','e','f','h','j'],index_col=['a','b'])
data
读写mysql数据
使用read_sql函数,返回dataframe数据
import MySQLdb
mysql_cn= MySQLdb.connect(host='xxxxx',
port=3306,user='root', passwd='123456',
db='xxxxxx')
tables= pd.read_sql('show tables;', con=mysql_cn)
读取与修改excel数据
报错第一行增加
-- coding:utf-8 --
read_xlsx()
①sheet_name=1 读取第二个sheet
②header=None/0 列名的行号,默认0第一行,设置为None后为无列名,自增数字为列
③names=[1,2,3,4]自定义设置列名,与header=None配合,不一定数量保持一致
④index_col=0,第一列设置为索引[]设置索引列,可以是多个,检索df[‘列名’][‘索引名’]实现数据查找
⑤usecols = [1,2,3]设定读取第几列
⑥skiprows[]需要跳过行的列表
import pandas as pd
df=pd.read_excel(r'D:\pandas测试\数据码表.xlsx',sheet_name='vehicle',index_col=0,usecols=[1,2,3])
to_excel()
多个sheet写数据,使用for循环
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy.types import CHAR,INT
import MySQLdb
array = list(tables['Tables_in_gwm_pubdm_gbd'])
writer = pd.ExcelWriter(r'D:\pandas测试\数据码表.xlsx')
for i in array:
print(i)
j='show full columns from gwm_pubdm_gbd.'+str(i)
df_mysql = pd.read_sql(j, con=mysql_cn)
df_mysql.to_excel(writer,sheet_name=i)
print(df_mysql)
writer.save()
writer.close()
to_sql
to_sql(name='battery_date', con=sql_engine, if_exists='append', index=False)
name为表名,con为链接信息,if_exists为插入方式,replace为替换,append为追加,index为索引是否存在,false
to_csv
empty.to_csv(r'C:\Users\新能源PHEV预警\py_result.csv',index=0,encoding='gbk')
#index=0代表不存储索引
Pandas数据结构
Series
series创建
①列表创建
df=pd.Series([1,2,3,4,5,6,None,None],index=(range(8)))
df1=df.sort_values(ascending=False)
import pandas as pd
a=[1,2,3,4,5]
c=['z','c','d','g','h']
df=pd.Series(a,index=c)
②字典创建
import pandas as pd
df=pd.Series({'a':1,'b':4,'c':6,})
print(df[['a','b']]['a']) #多个值返回类型为series,单个索引返回值
series方法
①查询,排序
import pandas as pd
df=pd.read_excel(r'D:\pandas测试\数据码表.xlsx',sheet_name='vehicle',index_col=None,usecols=[1,2,3,4])
df
print(df['Type'].values)#取值返回列表
a=data.values[:,2]#取某一列返回列表与上面相等
print(df['Type'].index)#返回索引列表
print(df['Type'].sort_values)#按照值进行排序
df2=df1.sort_values(ascending=False) #赋新值返回
print(df['Type'].sort_index())#按照索引进行排序正序
print(df['Type'].sort_index(ascending=False))#按照索引进行排序倒序
print(df[['a','b']]['a']) #多个值返回类型为series,单个索引返回值
②判断空值
df=pd.Series([1,2,3,4,5,6,None,None],index=(range(8)))
df1=df.isnull()
非空值
empty=empty[empty['time'].notnull()]
返回布尔值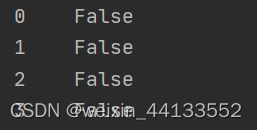
DataFrame
jupyter notebook显示所有行列
pd.set_option('max_columns',1000)
pd.set_option('max_row',300)
dataframe的创建
①字典创建
dict={'name':['zsl','ysy','zb','zy'],'age':[20,30,40,50],'gender':['男','女','男','女']}
df=pd.DataFrame(dict)
取数据
print(df[['name','age']])#输出两列的dataframe
print(df.loc[1]) # 输出第二行
print(df.loc[-5:,''] #输出后五行
print(df.loc[0:3][['name','age']]) #前三行,两列
print(df.iloc[0:3][1:3])#前三行,中间两列
②series创建
res=Nowcoder.Level.mode()
print(pd.DataFrame(res,columns=['Level']))
dataframe描述(类型,列名,索引,shape,排序)
df.describe() 对数值进行统计,包含最大最小中值等
df[‘lon’].describe()单列的数据描述
df.info()统计数据类型和非空值数量
df.dtypes
import pandas as pd
import numpy as np
dict={'name':['zsl','ysy','zb',np.nan],'age':[20,np.nan,40,50],'gender':['男','女','男','女']}
df=pd.DataFrame(dict)
#数据的描述
print(df.shape) #形状行数列数
print(df.columns) #df的列名,返回列表
print(df.index)#df的索引,返回列表
print(df.values)#df的值返回列表嵌套式 [['zsl' 20.0 '男']['ysy' nan '女']['zb' 40.0 '男'][nan 50.0 '女']]
print(df.head(2))#默认为前5行
print(df.tail(2))#默认为后两行
print(df.reset_index(drop=True,inplace=True))#原索引变为列,生成新索引,需要重新赋值,才能生效,drop将索引删除,不设置为数据列
print(df.fillna(1)) #填充空值为1,需要重新赋值
print(df.dropna()) #有空值的直接删除行,需要重新赋值
df=df.sort_index(ascending=False,inplace=True)#按照索引排序,正序、倒序
df.sort_values(by='age',ascending=False,inplace=True)#按照值排序,inplace替换本体
print(df)
#列名的排序
columns=sorted([i for i in data.columns]) #sorted对序列进行排序生成新的list
data=data[columns] #也可以直接自定义列名,直接写列名
#统计某个字段有多少个值/值个数
print(len(Nowcoder['Language'].unique()))
或print(Nowcoder.Language.nunique())
26
print(Nowcoder['Language'].unique())或
print(Nowcoder.Language.tolist())
['四川省' '广东省' '山东省']
print('\n数据缺失率')
print('{0}%'.format(round(empty.isna().sum() / empty.shape[0] * 100), 2))
#最小值为0的字段
print(df_info.loc['min',:].loc[df_info.loc['min',:]==0])
#返回每个字段是否包含空值,any就是包含一个TRUE就是true,代表一列存在空值,all代表就是全都为空才是true
print(df.isnull().any())
#结果
time_stamp False
data_args False
data_avn_speed True
dt.1 False
hr False
数据的查询行列、单元格
loc[][]后面第一个行号,可以是值也可以是范围[0:3]第二个是列,可以使列名[[‘name’,‘age’]],也可以是范围[0:3]
iloc只能填写数值,表示序号
dict={'name':['zsl','ysy','zb','zy'],'age':[20,30,40,50],'gender':['男','女','男','女']}
df=pd.DataFrame(dict)
#取数据
print(df[['name','age']])#输出两列的dataframe
print(df.loc[1]) # 输出第二行
print(df.loc[0:3][['name','age']]) #前三行,两列
print(df.loc[0:3,['name','age']])#查询前三行,两列
print(df.iloc[0:3][1:3])#前三行,中间两列
print(df.loc['LGWEF6A70MH253367',:])#代表选取所有列
#print(df.replace(20,'XX'))#值的替换,需要重新赋值
#print(df.describe()) #对所有数字列进行计算均值最大最小值
DateFrame连接
Merge
参数
on:通过哪个字段连接,可以传入列表支持多个字段[‘’,‘’]
left_on/right_on:确定左右表连接的字段,用于字段
left_index/right_index:连接的索引
suffixes:存在重复列名,定义规则(‘’,‘’)
how:连接方式 innner,outer,left,right
import pandas as pd
import numpy as np
df1=pd.DataFrame({'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3'],'KEY1':['k0','K0','K1','K1'],'KEY2':['K0','K1','K0','K1']
})
df2=pd.DataFrame({'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3'],'KEY1':['k0','K0','K2','K3'],'KEY2':['K0','K1','K0','K1']}
,index=[['A0','A1','A4','A3']])
print(df2)
print('*'*30)
print(df1)
df=pd.merge(df2,df1,how='left',right_on='A',left_index=True,suffixes=('_start','_end'))
如果使用带索引的df去关联key的df,会报错,原因未知
concat
支持dataframe和series横向纵向连接
objs:需要合并的对象,填充进列表
join:默认为outer,并集,交集是inner
axis:默认为0,代表纵向(按照列名对齐),1代表横向(按照索引对齐)
keys=[‘S1’,‘S2’]设置二级索引,代表数据来自哪个对象,纵向是索引区分,横向是列名区分
ignore_index=True 重置索引
df3=pd.concat([df2,df1],axis=0,keys=['S1','S2'],sort=False)
print(df3)
print(df3['A']['S1'][('A3',)])
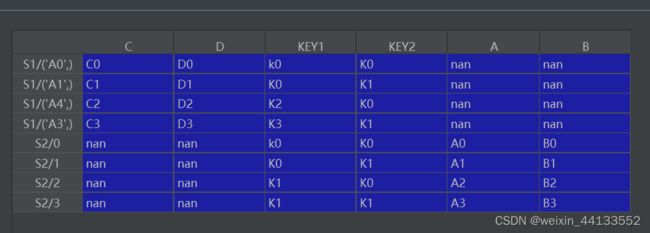
两个series合并重新命名
df1=df.iloc[:,1:].sum() --series
df2=df.iloc[:,1:].count() --series
df3=pd.concat([df1, df2], axis=1, ignore_index=False)
df3.rename(columns={0:'故障车辆数',1:'总车辆数'},inplace=True)
merge和concat区别
merge默认是横向,匹配的是值
concat默认是纵向,匹配的是字段名和索引
pandas中concat(), append(), merge()的区别和用法
列之间计算
使用apply实现横向axis=1,纵向axis=0默认计算,result_type设置
行计算
df=pd.DataFrame({'Name':['tom','jerry','kevin'],'gender':['men','female','men'],'score':[100,20,30]})
df['level']=df.apply(lambda x:x['score']**2 if x['gender']=='female' else x['score']/5,axis=1) #横向计算两列,生成新列,进行行计算
多行计算
df[['address','type','POI']]=df.apply(lambda x:get_location(x['data_avn_longitude'],x['data_avn_latitude']),axis=1,result_type="expand")
#重点是result_type参数,expand实现列表转为列
列计算
df1=df.apply(lambda x:np.square(x) if x.name==('score'or'level') else x)#纵向计算单列,识别name符合要求的,进行列计算
print(df1)
如果axis=0代表列计算 lambda x:x.name代表的就是列名
如果axis=1代表行计算lambda x:x.name代表的就是行号(索引)
日期和时间戳转换
字符串类型
df['time']=df['end_time_stamp'].apply(lambda x:int(time.mktime(time.strptime(x,'%Y/%m/%d %H:%M'))))
#2022/1/2 23:44 转换成时间戳
#time.strptime(shijian,"%Y-%m-%d %H:%M:%S")函数根据指定的格式把一个时间字符串解析为时间元组。
#time.mktime() 是将时间元组转为时间戳
#df['time']=df['data_stamp_time'].apply(lambda x :time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(x))) 时间戳转自定义日期
datetime类型
时间戳转日期
1652850237-》2022-05-18 13:03:57
df['time1']=df['data_stamp_time'].apply(lambda x:datetime.datetime.fromtimestamp(x))
#时间戳转日期datetime
df['month']=df['time1'].apply(lambda x :x.month)
字符日期转datetime
字符2022-05-18 13:03:57-》2022-05-18 13:03:57
# df['time1']=df['time'].apply(lambda x :datetime.datetime.strptime(str(x),'%Y-%m-%d %H:%M:%S'))
任意日期字符串转date_time
2022/01/20-》2022-01-20
Nowcoder['Last_submission_time'] = pd.to_datetime(Nowcoder['Last_submission_time'],format='%Y-%m-%d')
Json数据处理
import json
df['data_args1']=df['data_args'].apply(lambda x:(json.loads(x)))#object类型使用json.loads,转换成dict类型
i=(json.loads(y))['end_mode']
数据筛选
loc条件筛选
如果后面罗列列名,可以单独开数据框loc[][‘column1’,‘column2’],也可以写到一个数据框loc[,[‘column1’,‘column2’]]
df.loc[df['duration']>1000,'statues']='###' #前面执行条件判断,后面新增列标签传入参数
等价于df['statues']=df['duration'].apply(lambda x:'###'if x>1000 else '***')
loc条件过滤
df=df.loc[df['duration']<164,['distance','duration']] #前面通过条件筛选行
print(df.loc[(df['duration']>10 ) & (df['distance']>=60.0),['vin','duration','distance']])#多个条件使用&、|连接,不能缺少括号
df[(df['vin']=='LGWEEEA7641000024') & (df['travel_id']==1)]
#条件过滤,增加筛选条件
行数据筛选
通过行索引名/序号筛选符合条件的列
df_info=df.describe()
print(df_info.loc['min',:].loc[df_info.loc['min',:]==0])
索引名是min
结果如下:
bms_isolation_r_value_rm 0.0
mcu_inv_act_sts 0.0
print(df_info.loc['min'].loc[df_info.loc['min'] == 0])
query方法实现多个条件筛选
#实现空值的筛选,非空值为"vin==vin"
df=df.query("vin!=vin")
m="duration>10 and distance<60"
print(df.query(m))
m="duration in [17,18,19]"
print(df.query(m))
字符串匹配函数contains()
m=df['vin'].str.contains('WEF6A70MH')
print(df[m])#填写要包含的字段,支持正则表达式[a-cA-C]匹配包含小写大写字母的
类似sql in的函数
Nowcoder[Nowcoder['Language'].isin (['CPP','C','C#'])]
日期前后截取函数truncate()
①需要将日期设置为索引
②重新排序
③使用before(前所有行)、after(后所有行)设置前后
df=pd.read_csv(r'D:\pandas测试\杭州结果.txt',sep=',',parse_dates=['start_time_stamp'])
df=df.set_index('start_time_stamp')
df=df.sort_values('start_time_stamp')
df=df.truncate(before='2022-01-12')
多条日期筛选
使用query
df=pd.read_csv(r'D:\pandas测试\杭州结果.txt',sep=',',parse_dates=['start_time_stamp','end_time_stamp'])
#使用parse_dates 将字符串日期转换为datetime
m='@df.start_time_stamp.dt.day==12 @df.start_time_stamp.dt.hour==12'
#自定义条件,可以写多个参数
df=df.query(m)
df
datetime日期筛选
empty=empty[empty['tid']>'2022-06-09 23:29:37']
数据清洗
空值删除
drop支持删除行和列,通过axis区分
df.drop(labels=['start_time_stamp','end_time_stamp'],inplace=True,axis=1)#删除列
df.drop(labels=[1,3],inplace=True,axis=0)#删除行
df.dropna(axis=1,how='all',inplace=True)
#axis=0代表删除行,axis=1代表删除列,how代表删除方式any和all,inplace代表替换
df.dropna(axis=0,inplace=True,how='all',subset=['KEY1','KEY2'])
#支持设置筛选的列名,符合条件删除行
空值填充
自定义填充值
df=pd.DataFrame({'A':[1,2,3,5],'B':[500,None,56,None],'KEY1':[123,456,567,None],'KEY2':[22,34,None,None]
})
df.fillna({'A':'*','B':'$','KEY1':'@'},inplace=True)#使用字典对数据进行填充
df[['fl_tire_temp', 'ss_position']] = df[['fl_tire_temp', 'ss_position']].fillna(method='ffill', axis=0) # 轮胎温度填充
前后填充
df.fillna(axis=0,method='ffill',inplace=True)
#axis代表轴方向,method的方法为ffill从前往后填充、bfill从后往前填充
填充均值
df['2101001'].fillna(df['2101001'].astype('float64').mean(),inplace=True)#自定义填充的数据
数据去重
df['KEY1'].value_counts()#对某列的值进行计数
df.duplicated()
返回是重复行的布尔值,重复为True,不重复为false,可以配置keep为first/last/false,来展示第几行显示True
df.drop_duplicates(inplace=True,subset=['KEY1'],keep='last')
#subset填写需要的字段,keep保留哪行first、last
unique和nunique
eries和DataFrame的两种数据类型中都有nunique()和unique()方法
unique是返回不重复的值
nunique返回不重复值的个数
数据四舍五入
#两种方式
round(df['speed'],3)
df['speed'].round(3)
数据替换
使用replace函数,对于series和dataframe都适用
某个字段部分内容替换
df['导演']=df['导演'].str.replace(r'\n','')
全部替换
print(df.apply(lambda x:x.replace(1,'*',)))#全部替换
df.replace(1,'*',inplace=True)
行替换
print(df.apply(lambda x:x.replace(1,'*') if x.name==3 else x,axis=1)) #横向计算某行,axis为1代表横向,x.name代表行索引
列替换
print(df.apply(lambda x:x.replace(1,'*') if x.name=='KEY2'else x))
df['KEY2'].replace(1,'*',inplace=True)
多个值替换
df['KEY1'].replace([1,123],['*','&'],inplace=True)#多个值的替换,通过传输列表的形式
分箱操作
pd.cut共三个参数
①你需要格式化的列,传入series
②你需要分箱的范围,m
③你需要打的标签
df=pd.DataFrame({'A':[1,2,3,5],'B':[500,None,1,None],'KEY1':[123,323,567,200,],'KEY2':[1,34,1,None]
})
m=[100,200,300,400,600]
label=['小','中','大','超大']
df['statues']=pd.cut(df['KEY1'],m,labels=label)
使用pd.qcut(,q=4)实现等频分箱
数据重命名
can_data.rename(columns={'acquisition_time1':'time_stamp'},inplace=True)
数据模糊匹配
df = df[df["Creator"].str.contains("79",na=False)]
字符串操作
df[‘’].astype(‘str’)字符串类型的转换
excel文件拆分合并
文件夹多个文件合并,使用os.listdir()函数获取文件名
hebing=pd.DataFrame()
print(hebing)
for name in os.listdir(r'D:\pandas测试\课件025\课件025'):
df=pd.read_excel('D:\\pandas测试\\课件025\\课件025\\'+name)
print(df)
hebing=pd.concat([hebing,df])
多个sheet合并
hebing=pd.DataFrame()
df=pd.read_excel(r'D:\pandas测试\课件025\课件025-3\合并2.xlsx',None)
print(type(df))#返回的是字典,key是sheet名字
list=list(df.keys())
for i in list:
data=df[i]#获取字典中key下的值
hebing=pd.concat([hebing,data])
hebing.reset_index(inplace=True)
print(hebing)
写到多个sheet中
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy.types import CHAR,INT
import MySQLdb
array = list(tables['Tables_in_gwm_pubdm_gbd'])
writer = pd.ExcelWriter(r'D:\pandas测试\数据码表.xlsx')#首先创建一个writer对象,传入路径这个参数
for i in array:
print(i)
j='show full columns from gwm_pubdm_gbd.'+str(i)
df_mysql = pd.read_sql(j, con=mysql_cn)
df_mysql.to_excel(writer,sheet_name=i)
print(df_mysql)
writer.save() #数据保存
writer.close() #对象关闭
分组聚合Groupby
聚合方式有:
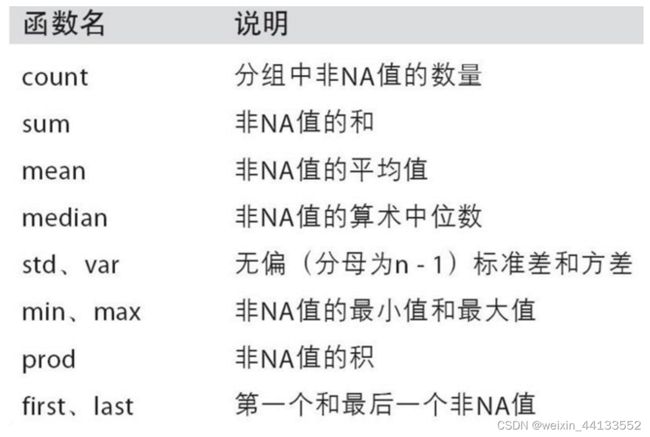
还有list,类似sql groupby_concat功能
基础知识
for (i,j),group in data.groupby(['',''])
print(i) #分组后行成dataframe,索引为分组字段,是一个元组,字段就是聚合后的结果
print(j)
print(list(group))
Pandas教程 | 超好用的Groupby用法详解
关于行的聚合,不同列不同方式
引入agg函数,后面添加字典,key为字段名,value为聚合方式
df=pd.read_excel(r'D:\pandas测试\课件026\分组聚合3.xlsx')
print(df)
df=df.groupby(['班级','性别']).agg({'语文':'count','数学':sum})
行+列的聚合
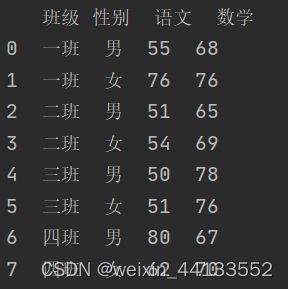
df=pd.read_excel(r'D:\pandas测试\课件026\分组聚合3.xlsx')
print(df)
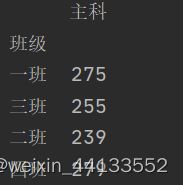
df=df.groupby('班级').agg({'语文':sum,'数学':sum})#按照行计算
m={'语文':'主科','数学':'主科'}#设置列的分组规则
df=df.groupby(m,axis=1)#axis为横向分组
print(df.sum())#进行求和
m=df.groupby('vin')['time_stamp1'].agg(lambda x :list(x))#将分组的结果进行合并成list
不同列对应不同的聚合规则
①apply传入不同的df
②自定义函数返回series
③计算聚合去重vin的数量,绝缘阻值的最小值,去重vin合并(list)
def agg_func(x):
'''将每个groupby后的df计算'''
return pd.Series({'数量':len(list(x['vin'].unique())),
'最小值':x['bms_isolation_r_value_rm'].min()
,'vin列举':','.join(x['vin'].unique())})
empty = empty.groupby(['dt', 'label']).apply(agg_func)
行多级索引聚合
不改变行数处理数据
类似于SQL窗口函数
df=pd.read_excel(r'D:\pandas测试\课件026\分组聚合3.xlsx')
print(df)
df['new1']=df.groupby('班级')['语文'].transform('first')
#分组后取语文第一个值,生成新列,所有符合分组索引的都会匹配对应的值
分组取第一行或者最小行
df_min=df.groupby(['vin','trip_id']).apply(lambda x:x[x.time_stamp==x.time_stamp.min()])
取最小行数据
df=df[df.a==df.a.max()]
数据处理三板斧
applymap:对dataframe中的每个单元格执行指定函数的操作
df1=df.applymap(lambda x:x**2)
apply
def change(x,num,num2):
x=(x+num)*num2
return x
df=pd.read_excel(r'D:\pandas测试\课件026\分组聚合3.xlsx')
df.set_index(['班级','性别'],inplace=True)
df['总和']=df['语文'].apply(change,args=(3,4)) #apply可以传入函数,args用来依次传入参数
Pandas计算差值、同比、环比
融合分组函数使用df-df.shift=df.diff
位移函数
df.set_index(['班级','性别'],inplace=True)
df['cha']=df.groupby('班级')['语文'].shift()
#shift(1)和shift(-1)正是向下移,负是向上移
计算差值
df['cha']=df.groupby('班级')['语文'].diff()
#diff(1)代表下减上,diff(-1)代表上减下
计算时间差值
df['diff2']=df.groupby('vin')['time_stamp1'].diff()
#timedelta类型0 days 00:00:07转成秒数,使用total_seconds方法,也可以时间戳减
df['diff2']=df['diff2'].apply(lambda x:x.total_seconds())
时间序列
生成连续精度在一秒的数据,使用date_range方法
import pandas as pd
df=pd.date_range(start='5/01/2022 00:00:00',end='5/30/2022 23:59:59',freq='S',name='timestamp')
df=pd.DataFrame(df)
分享案例
对数据进行分组填充
①自定义函数,分别筛选数据进行填充
②数据的融合
def filltemp(x):
'''分组对数据进行填充'''
vin=x['vin'].unique()
for i in vin:
print(i)
trip=x[x['vin']==i].hu_travel_id.unique()
for j in trip:
x[(x['vin']==i)&(x['hu_travel_id']==j)]=x[(x['vin']==i)&(x['hu_travel_id']==j)].fillna(method='ffill')
return x
df_all[['vin','hu_travel_id','fl_tire_temp','trip_id','cbn_temp','ss_position','ac_frnt_blwr_spd','start_time','end_time']]=filltemp(df_all.loc[:,('vin','hu_travel_id','fl_tire_temp','trip_id','cbn_temp','ss_position','ac_frnt_blwr_spd','start_time','end_time')])
方法二
def data_fillna(x):
x.sort_values(by=['vin','avn_vvid','time_stamp'], inplace=True)
x.fillna(method='ffill',inplace=True)
print(time.strftime('%H:%M:%S',time.localtime(time.time())))
return x
empty=empty.groupby(['vin','avn_vvid']).apply(lambda x:data_fillna(x)).reset_index(drop=True)
#注意需要reset_index否则会报错
众数计算及多个df的merge
df3 = df.groupby(['province', 'vin'])['cbn_temp'].agg(lambda x: stats.mode(x)[0][0]).reset_index()
#计算众数
dfs = [df1, df2, df3]
df_vin = reduce(lambda x, y: pd.merge(x, y, how='inner', on=['vin', 'province']), dfs)
使用reduce不断迭代列表中的df,x+y,结果+z
format用法(读取数据)
a=r'D:\pandas测试\课件025\课件025-3'
for i in os.listdir(a):
print('{0}\{1}'.format(a,i,sep='\t'))
数据格式转换
包含’-'值、空值、不同类型
df=df.applymap(lambda x:str(x))
df=df.applymap(lambda x:x.replace('-','0'))
df.fillna(0,inplace=True)
df=df.applymap(lambda x:float(x))
df.iloc[:,1:]=df.iloc[:,1:].applymap(lambda x:x if x==1.0 else 0)
日期处理
data['服务结束时间']=data['服务结束时间'].apply(lambda x :datetime.datetime.strptime(str(x),'%Y-%m-%d %H:%M:%S'))
data['Year'] = data['服务结束时间'].dt.year #取年
data['Month'] = data['服务结束时间'].dt.month #取月
data=data[data['Year']==2023]
data['服务结束时间']=data['服务结束时间'].str[:10]#针对日期格式不统一的进行字符串截取
pandas多进程处理数据