pytorch预训练模型加载与使用(以AlexNet为例)
目录
- 1. 概况
- 2. 代码讲解
-
- 2.1 加载必要的包
- 2.2 设置GPU和transform
- 2.3 数据预处理
- 2.4 引入模型
- 2.5 训练模型
- 2.6 测试模型
- 2.7 保存模型
- 3. 完整代码
- 4. 结果
本文主要是提供过程,不要在意结果。
1. 概况
pytorch 中有许多已经训练好的模型提供给我们使用,一下以AlexNet为例说明pytorch中的模型怎么用。
如下:
import torchvision.models as models
# pretrained=True:加载网络结构和预训练参数
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet_v2 = models.mobilenet_v2(pretrained=True)
mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True)
mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)
数据来源:请点击我
也可以在CSDN中下载:请点击我
2. 代码讲解
2.1 加载必要的包
import os.path
from os import listdir
import numpy as np
import pandas as pd
from PIL import Image
import torch
from torch.utils.data.sampler import SubsetRandomSampler
from torch.utils.data import Dataset
import torchvision.transforms as transforms
from sklearn.model_selection import train_test_split
import torch.nn
import torchvision.models as models # 模型都在这里
2.2 设置GPU和transform
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
transform = transforms.Compose([transforms.ToTensor(), normalize]) # 转换
2.3 数据预处理
# img_paths:图片路径;img_labels:图片标签;size_of_images:图片大小
class DogDataset(Dataset):
def __init__(self, img_paths, img_labels, size_of_images):
self.img_paths = img_paths
self.img_labels = img_labels
self.size_of_images = size_of_images
def __len__(self):
return len(self.img_paths)
def __getitem__(self, index):
PIL_IMAGE = Image.open(self.img_paths[index]).resize(self.size_of_images)
TENSOR_IMAGE = transform(PIL_IMAGE)
label = self.img_labels[index]
return TENSOR_IMAGE, label
print(len(listdir(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\train')))
print(len(pd.read_csv(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\labels.csv')))
print(len(listdir(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\test')))
train_paths = []
test_paths = []
labels = []
train_paths_lir = r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\train'
for path in listdir(train_paths_lir):
train_paths.append(os.path.join(train_paths_lir, path))
labels_data = pd.read_csv(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\labels.csv')
labels_data = pd.DataFrame(labels_data)
# 把字符标签离散化,因为数据有120种狗,不离散化后面把数据给模型时会报错:字符标签过多。把字符标签从0-119编号
size_mapping = {}
value = 0
# print(len(labels_data['breed'].value_counts()))
# print(labels_data['breed'].value_counts())
size_mapping = dict(labels_data['breed'].value_counts())
for kay in size_mapping:
size_mapping[kay] = value
value += 1
labels = labels_data['breed'].map(size_mapping)
labels = list(labels)
print(len(labels))
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(train_paths, labels, test_size=0.2)
# X_train:数据,y_train:数据标签,(224, 224):重新定义图片大小
train_set = DogDataset(X_train, y_train, (224, 224))
test_set = DogDataset(X_test, y_test, (224, 224))
# 批量归一化
train_loader = torch.utils.data.DataLoader(train_set, batch_size=64)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=64)
2.4 引入模型
# 引入预训练好的模型模型
alexnet = models.alexnet(pretrained=True)
# 修改最后一层全连接层输出的种类:120
num_fc = alexnet.classifier[6].in_features
alexnet.classifier[6] = torch.nn.Linear(in_features=num_fc, out_features=120)
alexnet = alexnet.to(device)
# 对于模型的每个权重,使其不进行反向传播,即固定参数
for param in alexnet.parameters():
param.requires_grad = False
# 但是参数全部固定了,也没法进行学习,所以我们不固定最后一层,即全连接层
for param in alexnet.classifier[6].parameters():
param.requires_grad = True
# 定义自己的优化器
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(alexnet.parameters(), lr=0.001)
2.5 训练模型
def train(epoch):
alexnet.train()
epoch_loss = 0.0
correct = 0.0
for data, label in train_loader:
data = data.to(device)
label = label.to(device)
train_output = alexnet(data)
loss = criterion(train_output, label)
epoch_loss = epoch_loss + loss
pred = torch.max(train_output, 1)[1]
train_correct = (pred == label).sum()
correct += train_correct.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch: ', epoch, 'Train_loss: ', epoch_loss / len(train_set), 'Train acc: ', correct / len(train_set))
2.6 测试模型
def test():
alexnet.eval()
correct = 0.0
test_loss = 0.0
for data, label in test_loader:
data = data.to(device)
label = label.to(device)
test_out = alexnet(data)
loss = criterion(test_out, label)
test_loss = test_loss + loss.item()
pred = torch.max(test_out, 1)[1]
test_correct = (pred == label).sum()
correct = correct + test_correct.item()
print('Test_loss: ', test_loss / len(test_set), 'Test acc: ', correct / len(test_set))
2.7 保存模型
PATH = r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Project'
torch.save(alexnet, PATH)
3. 完整代码
import os.path
from os import listdir
import numpy as np
import pandas as pd
from PIL import Image
import torch
from torch.utils.data.sampler import SubsetRandomSampler
from torch.utils.data import Dataset
import torchvision.transforms as transforms
from sklearn.model_selection import train_test_split
import torch.nn
import torchvision.models as models
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
transform = transforms.Compose([transforms.ToTensor(), normalize]) # 转换
class DogDataset(Dataset):
def __init__(self, img_paths, img_labels, size_of_images):
self.img_paths = img_paths
self.img_labels = img_labels
self.size_of_images = size_of_images
def __len__(self):
return len(self.img_paths)
def __getitem__(self, index):
PIL_IMAGE = Image.open(self.img_paths[index]).resize(self.size_of_images)
TENSOR_IMAGE = transform(PIL_IMAGE)
label = self.img_labels[index]
return TENSOR_IMAGE, label
print(len(listdir(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\train')))
print(len(pd.read_csv(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\labels.csv')))
print(len(listdir(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\test')))
train_paths = []
test_paths = []
labels = []
train_paths_lir = r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\train'
for path in listdir(train_paths_lir):
train_paths.append(os.path.join(train_paths_lir, path))
labels_data = pd.read_csv(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\labels.csv')
labels_data = pd.DataFrame(labels_data)
size_mapping = {}
value = 0
size_mapping = dict(labels_data['breed'].value_counts())
for kay in size_mapping:
size_mapping[kay] = value
value += 1
labels = labels_data['breed'].map(size_mapping)
labels = list(labels)
# print(labels)
print(len(labels))
X_train, X_test, y_train, y_test = train_test_split(train_paths, labels, test_size=0.2)
'''print(len(X_train))
print(len(y_train))'''
train_set = DogDataset(X_train, y_train, (224, 224))
test_set = DogDataset(X_test, y_test, (224, 224))
train_loader = torch.utils.data.DataLoader(train_set, batch_size=64)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=64)
# 引入预训练好的模型模型
alexnet = models.alexnet(pretrained=True)
num_fc = alexnet.classifier[6].in_features
alexnet.classifier[6] = torch.nn.Linear(in_features=num_fc, out_features=120)
alexnet = alexnet.to(device)
# 对于模型的每个权重,使其不进行反向传播,即固定参数
for param in alexnet.parameters():
param.requires_grad = False
# 但是参数全部固定了,也没法进行学习,所以我们不固定最后一层,即全连接层
for param in alexnet.classifier[6].parameters():
param.requires_grad = True
# 定义自己的优化器
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(alexnet.parameters(), lr=0.001)
def train(epoch):
alexnet.train()
epoch_loss = 0.0
correct = 0.0
for data, label in train_loader:
data = data.to(device)
label = label.to(device)
train_output = alexnet(data)
loss = criterion(train_output, label)
epoch_loss = epoch_loss + loss
pred = torch.max(train_output, 1)[1]
train_correct = (pred == label).sum()
correct += train_correct.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch: ', epoch, 'Train_loss: ', epoch_loss / len(train_set), 'Train correct: ', correct / len(train_set))
def test():
alexnet.eval()
correct = 0.0
test_loss = 0.0
for data, label in test_loader:
data = data.to(device)
label = label.to(device)
test_out = alexnet(data)
loss = criterion(test_out, label)
test_loss = test_loss + loss.item()
pred = torch.max(test_out, 1)[1]
test_correct = (pred == label).sum()
correct = correct + test_correct.item()
print('Test_loss: ', test_loss / len(test_set), 'Test correct: ', correct / len(test_set))
epoch = 5
for n_epoch in range(epoch):
train(n_epoch)
test()
# 保存模型
PATH = r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Project'
torch.save(alexnet, PATH)
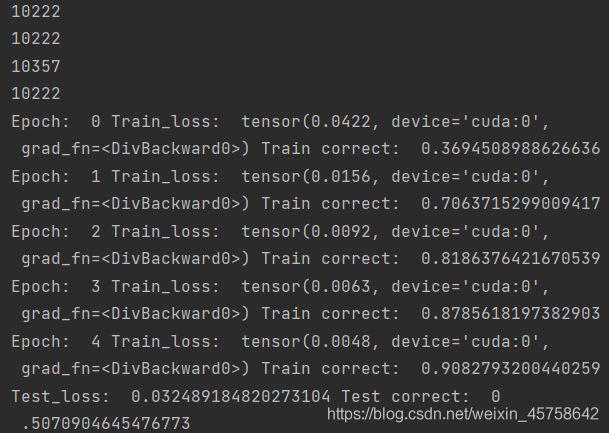
4. 结果