基于长短期记忆神经网络和卷积神经网络(convLSTM)的股票涨跌预测模型(附代码)
基于长短期记忆神经网络和卷积神经网络convLSTM的股票涨跌预测模型(附代码)
- 一、 研究背景与意义
- 二、 问题描述
- 三、 数据获取
- 四、 行情特征工程
- 五、 数据清洗
- 六、 模型算法设计
- 1. 模型选择
- 2. 模型构建
- 3. 最终模型
- 七、 实验分析与模型效果评价
- 八、 预测结果分析
- 九、 后续改进方向
- python代码
- 参考文献
作者:tushare会员409417
一、 研究背景与意义
作为证券投资市场最为热门的投资对象之一,股票已经成为了很多普通人的投资渠道,但是与储蓄类金融产品相比,股市的投资技术性很强,发掘股市规律,掌握股票买卖的时机是在股市中取得高回报的关键。随着我国经济的发展和人均可支配收入的提高,股票市场和股民的规模越来越大,市场透明度也越来越高,导致了股市发展的不确定性因素更多,对股票价格的预测更加困难。一个通用准确的股票预测方法模型对于股票投资交易有着非常重要的意义。
近年来,随着人工智能学科的推进和计算机硬件水平的提升,机器学习方法在很多传统行业中大方异彩,越来越多的投资者尝试使用机器学习对股票市场中浩如烟海的信息进行量化分析,对其中蕴含的规律进行挖掘,由此对股票的走势进行预测。众多实践表明,通过机器学习来辅助交易决策可以在很大程度上提高决策的准确性。考虑到股票特征众多有效特征不易选取和股票数据呈现时间相关的特点,本实验主要基于LSTM长短期记忆神经网络模型,并引入CNN卷积神经网络模型提取有效特征,融合两种深度学习模型进行研究。
二、 问题描述
使用tushare提供的API获取上证50ETF的行情数据,利用talib库对数据进行加工处理得到行情指标,然后对行情指标进行特征工程,构建深度学习所需要的数据集,使用tensorflow.keras库构建数据挖掘神经网络模型,用均方差、均方根差、平均绝对误差和确定系数评价模型,不断调整相关参数训练模型使得模型的预测效果最优。在实际中应用模型,预测未来上证50ETF的涨跌。
三、 数据获取
- 使用tushare提供的fund_daily接口,获取上证50ETF的每日行情数据:
| 名称 | trade_date | close | open | high | low | vol |
|---|---|---|---|---|---|---|
| 含义 | 交易日期 | 收盘价 | 开盘价 | 最高价 | 最低价 | 成交量 |
- 根据炒股经验和实践经验,将上证指数的每日行情引入到数据集中有利于提高模型的准确度,因此使用tushare提供的index_daily接口,获取上证指数的每日行情数据,其数据格式与上证50ETF相同,此处不再赘述。
- 根据炒股经验和实践经验,股票的资金流向对于股票分析预测有着重要的意义,大单流入流出反应了庄家的资金流向,小单的流入流出反应了散户的资金流向,通过分析股票的资金流向可以判断股票中多方势力的意图与分歧,有助于判断股票的急拉急跌。对于上证50ETF而言,由于其属于蓝筹指数基金,并没有现成的接口供我们获取它的资金流向。但我们可以由构成上证50ETF的50支样本股的资金流向间接地得到上证50ETF的资金流向。设某只样本股的某种资金流向为fi手,该样本股的总股本为Vi亿股,指数权重为ri,则上证50ETF的资金流向F可由公式:
F = ∑ i = 1 50 r i f i V i \ F=\sum_{i=1}^{50} r_i \cfrac{f_i}{V_i} F=∑i=150riVifi
得到。由于50支样本股的停盘时间可能与50ETF的停盘时间不一致,甚至会出现“中国北车”这样合并停盘的情况,所以50支样本股的资金流向并非全部可用。经过实践可知:‘中信证券’, ‘伊利股份’, ‘保利地产’, ‘北京银行’, ‘中国重工’, ‘中国神华’, ‘招商证券’, ‘方正证券’, ‘中国联通’, ‘包钢股份’, ‘特变电工’, ‘国金证券’, ‘上港集团’, ‘中国北车’, ‘青岛海尔’, ‘广汇能源’, ‘中国船舶’, ‘百 视 通’, ‘康美药业’, ‘东方明珠’, ‘国电南瑞’, ‘中航电子’, ‘白 云 山’, ‘海南橡胶’:这些样本股的资金流向不可用,最终使用到的样本股的权值为70.25,依然能够代表上证50ETF的资金流向。最终的数据格式如下:
| 名称 | buy_sm_vol | sell_sm_vol | buy_md_vol | sell_md_vol | buy_lg_vol | sell_lg_vol | buy_elg_vol | sell_elg_vol |
|---|---|---|---|---|---|---|---|---|
| 含义 | 小单买入量 | 小单卖出量 | 中单买入量 | 中单卖出量 | 大单买入量 | 大单卖出量 | 特大单买入量 | 特大单卖出量 |
四、 行情特征工程
使用talib库函数构造行情指标,使用到的指标如下:
| 名称 | 含义 |
|---|---|
| BBANDS | 布林线指标,其利用统计原理,求出股价的标准差及其信赖区间,从而确定股价的波动范围及未来走势,利用波带显示股价的安全高低价位。 |
| MA | 移动平均线,Moving Average,简称MA,原本的意思是移动平均,由于我们将其制作成线形,所以一般称之为移动平均线,简称均线。它是将某一段时间的收盘价之和除以该周期。 比如日线MA5指5天内的收盘价除以5 。 |
| HT_TRENDLINE | 希尔伯特瞬时变换,对价格收盘价进行算术平均,并根据计算结果来进行分析,用于判断价格未来走势的变动趋势。能够识别趋势和价格周期,是一款非常高效的趋势过滤器,对于滤网交易者和波段交易者来说,该指标非常有用。 |
| MIDPOINT | 中期点 |
| MIDPRICE | 中期价格 |
| SAR | 抛物线指标。停损点转向,利用抛物线方式,随时调整停损点位置以观察买卖点。 由于停损点(又称转向点SAR)以弧形的方式移动,故称之为抛物线转向指标 。 |
| MACD | 平滑异同移动平均线,利用收盘价的短期(常用为12日)指数移动平均线与长期(常用为26日)指数移动平均线之间的聚合与分离状况,对买进、卖出时机作出研判的技术指标 |
| STOCH | Stochastic KDJ指标中的KD指标 |
| 各种模式识别 | 包括:CDL2CROWS两只乌鸦,CDL3BLACKCROWS三只乌鸦,CDL3INSIDE三内部上涨和下跌,CDL3LINESTRIKE三线打击等 |
此外实际中发现,直接使用资金流向的效果并不好,将各种资金的买入量与卖出量的差值作为特征的效果会更好。
五、 数据清洗
- 特征筛选:经过查阅相关文献并经过实际验证可知,加入每日开盘价的特征会导致模型的预测准确率下降,陈泽均在其文献中解释道:加入开盘价指标后可能会引入一些不必要的噪声,而且当日开盘价指标本身就受到了历史数据的影响,在不通过与其他指标混合一起进行PCA降维就引入作为模型特征的话,可能会产生严重的多重共线性问题,从而导致神经网络比指标少时更容易达到过拟合状态。 因此我将上证50ETF的每日开盘价和大盘指数的每日开盘价从特征集中移除。
- 特征拼接:将上证50ETF的各项特征序列拼接为一整块二维向量,向量的第一个维度是构造出的各个特征,第二个维度是交易日时间。
- 数据规范化:从二维数据集中构造特征序列。每次从二维数据集中提取长度为timestep的特征序列,用MinMaxScaler函数归一化特征序列,提取特征序列的下一天数据用相同的放缩方式将其收盘价等比放缩,成为这一特征序列样本的标签。重复以上操作直到构建好三维的数据集及其标签。
- 缺失值处理:由于使用talib库构建的某些特征需要以前若干天的数据作为基础,所以二维数据集总的某些特征在前几个交易日会出现空值Nan,我采取的办法是直接丢弃含有空值的样本。
- 异常值处理:由于所有数据来自于tushare平台,因此数据的正确性可以保证,不需要对异常值进行处理。
六、 模型算法设计
1. 模型选择
本实验选取深度学习模型是因为股票的价格走势与时间序列相关,因此比较适合用循环神经网络进行分析,相较于RNN循环神经网络,LSTM神经网络模型更加适合对股票预测的研究,一方面LSTM模型是对RNN的改良,LSTM神经网络解决了RNN模型由于输入序列过长而产生的梯度消失的问题,能够更加准确地对记忆性序列数据进行操作,另一方面,LSTM模型能够支持具有“长期依赖”特点的数据。因此本实验主要基于LSTM神经网络模型。
此外本实验还融合了CNN模型,通过卷积提取需要的特征,将CNN网络融入到模型中有助于发挥两种神经网络各自的优势,提升模型的准确率。
经过实验验证发现,构建回归模型后间接对股票涨跌进行预测得到的准确率要高于直接构建二分类模型对股票涨跌进行预测的准确率,因此本实验将股票预测问题转化为了回归问题。
2. 模型构建
模型选用keras提供的顺序模型,首先构建三层LSTM神经网络,主要的可调参数为神经元个数,神经元个数偏少将无法提取完整的数据特征,个数过多则容易出现过拟合。经过反复测试我选择200作为隐层的神经元个数。为了进一步防止过拟合,在每一层LSTM之间加入了Dropout层,随机断开神经元的连接,抛弃阈值设定为0.2。之后构建两层一维卷积层,卷积核大小各为256个,卷积核大小为3,因为训练过程中涉及到较多的参数,所以选取Relu激活函数,对过拟合进行控制,在每一次卷积后还加入了池化层,对卷积结果下采样,对特征进行压缩,去除冗余信息。最后加入了4层全连接层,综合各组特征,输出预测结果。
损失函数为mae均方误差,优化器采用Adam。Adam算法是一种自适应学习率的方法,它利用梯度的一阶矩阵估计和二阶矩阵估计动态调整每个参数的学习率。学习率参数设定为0.001。
3. 最终模型
Layer (type) Output Shape Param #
lstm_6 (LSTM) (None,35,200) 189600
dropout_16 (Dropout) (None,35,200) 0
lstm_7 (LSTM) (None,35,200) 320800
dropout_17 (Dropout) (None,35,200) 0
lstm_8 (LSTM) (None,35,200) 320800
dropout_18 (Dropout) (None,35,200) 0
conv1d_4 (Conv1D) (None,35,256) 153856
average_pooling1d_4 (Average (None,34,256) 0
dropout_19 (Dropout) (None,34,256) 0
conv1d_5 (Conv1D) (None,34,256) 196864
average_pooling1d_5 (Average (None,33,256) 0
dropout_20 (Dropout) (None,33,256) 0
flatten_2 (Flatten) (None,8448) 0
dense_8 (Dense) (None,256) 2162944
dropout_21 (Dropout) (None,256) 0
dense_9 (Dense) (None,256) 65792
dropout_22 (Dropout) (None,256) 0
dense_10 (Dense) (None,128) 32896
dropout_23 (Dropout) (None,128) 0
dense_11 (Dense) (None,1) 129
七、 实验分析与模型效果评价
模型的epochs为100次,batch_size设定为32,shuffle置为True在训练过程中随机打乱输入样本的顺序,使用回调函数ModelCheckpoint,将在每个epoch后保存性能最好的模型到指定文件中。模型训练时的评价指标为mae均方误差,引入matplotlib库绘制出训练过程中训练集和验证集的损失率的变化曲线,从中分析模型的效果。为了说明将CNN融合入LSTM的合理性,分别考察不加入CNN的模型效果和加入CNN的模型效果。
不融合CNN模型后的训练结果如下:
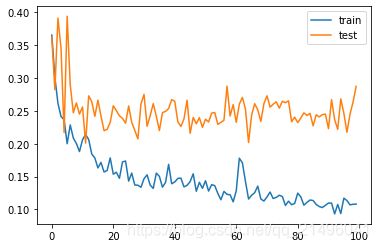
训练集损失:0.1081
验证集损失:0.2874
单次训练时间:32ms
融合CNN模型后训练结果如下:
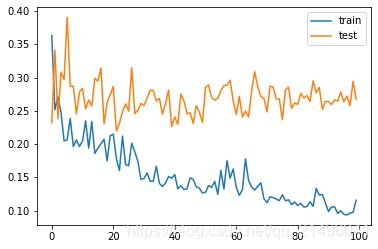
训练集损失:0.1156
验证集损失:0.2669
单次训练时间:39ms
通过对比可知,融合了CNN的模型的训练集损失更大,测试集损失更小,这表明融合CNN后缓解了模型的过拟合现象。因为加入CNN后模型变得更加复杂,因此单次训练的时间增加,但增加幅度仍然在可接受范围内。
八、 预测结果分析
由于本实验的目的是预测股票的涨跌,所以从数据集中划分出后20%的数据作为测试集输入训练好的模型(时间范围是2020-4-8至2020-12-31),引入matplotlib库绘制出真实股票曲线与预测股票曲线,求得测试集的均方误差、均方根误差、平均绝对误差和R_square,通过比较预测的股票涨跌趋势和实际的涨跌趋势间准确率,评判模型的实际应用效果。为了说明将CNN融合入LSTM的合理性,分别考察不加入CNN的模型效果和加入CNN的模型效果。
不融合CNN模型后的预测结果如下:
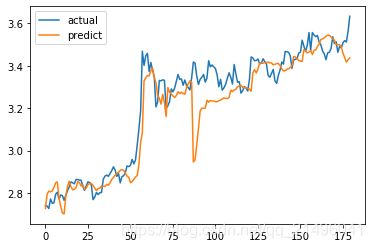
180个测试集共有112个预测正确,准确率为0.62,历史最高准确率可达0.65,平均准确率在0.59左右。均方误差: 0.008916,均方根误差: 0.094424,平均绝对误差: 0.063991,R_square: 0.929778。
通过以上结果可知,融合了CNN后模型的准确率有一个较大程度的提升,就拿以上两次测试来说,将预测走势和真实走势对比可以发现,融入CNN的模型的预测曲线与真实曲线更加契合,仅有一次较大的失误,而没有融合CNN的模型,其预测曲线与真实曲线经常相悖,有两次较大的预测失误。除此以外加入CNN的模型的测试结果的均方误差、均方根误差、平均绝对误差均比未加入时要小,确定系数R_square更大。
综上所述,融合了长短期记忆神经网络和卷积神经网络的股票预测模型对于股票的准确率可达0.6以上,这对于股票预测而言是一个较好的结果,事实上,对测试集的最后一个数据,也就是2020年12月31日的上证50ETF的测试数据,模型给出的预测结果是“下一个交易日收盘价下跌”,因为数据集中不包含下一个交易日的收盘情况,所以对这一预测是否正确无法判断。等到2021年1月4日收盘后,我惊奇地发现当日的收盘价确实是下跌,因此模型的测试准确率实际上要更高,这也从实际总验证了模型的使用价值。
九、 后续改进方向
本实验的模型还有一定的改进空间:例如,模型参数的调试是根据经验人工调试的,后续可以尝试网格搜索,遍历可能最优参数,进一步提升模型的效果;又如,可以给卷积层加入注意力机制,使得模型拥有了重视关键特征忽视无用特征的能力;还可以使用bagging并行式集成学习,集成多个LSTM分类器;还可以利用tushare提供的new新闻快讯接口,将文本转化为离散特征纳入到训练集中。
python代码
import tushare as ts
import talib as ta
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import pickle
import os
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score
from tensorflow.keras.models import Sequential,load_model
from tensorflow.keras.layers import LSTM, Dense, Dropout, Flatten, Conv1D, AveragePooling1D
from math import sqrt
#从tushare获取所需数据
def getDailyData(stockcode='603185.SH',startdate='20100101',enddate='20201210'):
ts.set_token('注册Tushare社区账号获取你的token(注意代码中的API对积分有一定要求)')
pro=ts.pro_api()
tsdata=pro.fund_daily(ts_code=stockcode,start_date=startdate,end_date=enddate,adj=None)
#上证50ETF的每日行情
data={
# 'ts_code':np.array(tsdata['ts_code'])[::-1],
'trade_date':np.array(tsdata['trade_date'])[::-1],
'close':np.array(tsdata['close'])[::-1],
'open':np.array(tsdata['open'])[::-1],
'high':np.array(tsdata['high'])[::-1],
'low':np.array(tsdata['low'])[::-1],
# 'pre_close':np.array(tsdata['pre_close'])[::-1],
# 'change':np.array(tsdata['change'])[::-1],
# 'pct_chg':np.array(tsdata['pct_chg'])[::-1],
'vol':np.array(tsdata['vol'])[::-1],
# 'amount':np.array(tsdata['amount'])[::-1]
}
shdata=pro.index_daily(ts_code='000001.SH',start_date=startdate,end_date=enddate)
#大盘指数的每日行情
indexdata={
# 'ts_code':np.array(shdata['ts_code'])[::-1],
# 'trade_date':np.array(shdata['trade_date'])[::-1],
'close':np.array(shdata['close'])[::-1],
'open':np.array(shdata['open'])[::-1],
'high':np.array(shdata['high'])[::-1],
'low':np.array(shdata['low'])[::-1],
#'pre_close':np.array(shdata['pre_close'])[::-1],
# 'change':np.array(shdata['change'])[::-1],
# 'pct_chg':np.array(shdata['pct_chg'])[::-1],
'vol':np.array(shdata['vol'])[::-1],
# 'amount':np.array(shdata['amount'])[::-1]
}
#上证50ETF的样本股资金流向
etf50=[
('601318.SH','中国平安',9.18,88.92),
('600016.SH','民生银行',7.57,341.53),
('600036.SH','招商银行',7.03,252.20),
('600030.SH','中信证券',6.85,110.17),
('600837.SH','海通证券',5.00,95.85),
('601166.SH','兴业银行',4.84,190.52),
('600000.SH','浦发银行',4.51,186.53),
('601668.SH','中国建筑',2.80,300.00),
('601328.SH','交通银行',2.74,742.63),
('601601.SH','中国太保',2.61,90.62),
('601818.SH','光大银行',2.49,466.79),
('601288.SH','农业银行',2.47,3,247.94),
('600887.SH','伊利股份',2.25,30.64),
('600519.SH','贵州茅台',2.22,11.42),
('601398.SH','工商银行',2.16,3,534.94),
('600104.SH','上汽集团',1.82,110.26),
('600048.SH','保利地产',1.79,107.30),
('601169.SH','北京银行',1.78,105.60),
('601688.SH','华泰证券',1.76,56.00),
('601989.SH','中国重工',1.74,183.62),
('601088.SH','中国神华',1.72,198.90),
('600999.SH','招商证券',1.69,58.08),
('601006.SH','大秦铁路',1.63,148.67),
('600015.SH','华夏银行',1.54,89.05),
('601901.SH','方正证券',1.49,82.32),
('601628.SH','中国人寿',1.32,282.65),
('600585.SH','海螺水泥',1.13,52.99),
('600050.SH','中国联通',1.08,211.97),
('601857.SH','中国石油',1.08,1,830.21),
('600111.SH','包钢稀土',0.97,24.22),
('600028.SH','中国石化',0.93,1,182.80),
('600010.SH','包钢股份',0.84,160.05),
('600089.SH','特变电工',0.82,32.40),
('600109.SH','国金证券',0.79,28.37),
('601766.SH','中国南车',0.77,138.03),
('600018.SH','上港集团',0.75,227.55),
('601299.SH','中国北车',0.74,122.60),
('600690.SH','青岛海尔',0.73,30.46),
('600256.SH','广汇能源',0.67,52.21),
('600150.SH','中国船舶',0.65,13.78),
('600637.SH','百 视 通',0.65,11.14),
('600196.SH','复星医药',0.62,23.12),
('600518.SH','康美药业',0.62,21.99),
('601998.SH','中信银行',0.62,467.87),
('600832.SH','东方明珠',0.57,31.86),
('600406.SH','国电南瑞',0.54,24.29),
('600703.SH','三安光电',0.44,23.93),
('600372.SH','中航电子',0.38,17.59),
('600332.SH','白 云 山',0.37,12.91),
('601118.SH','海南橡胶',0.26,39.31)
]
length=len(data['close'])
#上证50ETF的资金流向
flow={
'buy_sm_vol':np.array([0 for i in range(length)]),
'sell_sm_vol':np.array([0 for i in range(length)]),
'buy_md_vol':np.array([0 for i in range(length)]),
'sell_md_vol':np.array([0 for i in range(length)]),
'buy_lg_vol':np.array([0 for i in range(length)]),
'sell_lg_vol':np.array([0 for i in range(length)]),
'buy_elg_vol':np.array([0 for i in range(length)]),
'sell_elg_vol':np.array([0 for i in range(length)])
}
short=[]
valid=0.0
for tup in etf50:
mf=pro.moneyflow(ts_code=tup[0],start_date=startdate,end_date=enddate)
if len(mf['buy_sm_vol'])<len(flow['buy_sm_vol']):
short.append(tup[1])
continue
for label in flow.keys():
flow[label]=np.add(flow[label],np.multiply(np.divide(np.array(mf[label])[::-1],tup[3]),tup[2]))
print(tup[1],'添加完毕')
valid+=tup[2]
print('有效因子',valid)
print('无法添加',short)
return data,indexdata,flow
#使用talib库函数构造行情指标
def taAnalysis(input_arrays):
#length=len(input_arrays['close'])
#Overlap Studies
upper,middle,lower=ta.BBANDS(input_arrays['close'],matype=ta.MA_Type.T3)
ma=ta.MA(input_arrays['close'],matype=0)
ht=ta.HT_TRENDLINE(input_arrays['close'])
midpoint=ta.MIDPOINT(input_arrays['close'],timeperiod=14)
midpirce=ta.MIDPRICE(input_arrays['high'],input_arrays['low'],timeperiod=14)
sar=ta.SAR(input_arrays['high'],input_arrays['low'],acceleration=0.1,maximum=0.1)
OSlist={
'upper':upper,
'middle':middle,
'lower':lower,
'ma':ma,
'ht':ht,
'midpoint':midpoint,
'midpirce':midpirce,
'sar':sar
}
#Momentum Indicator
macd,macdsignal,macdhist=ta.MACD(input_arrays['close'],fastperiod=12,slowperiod=26,signalperiod=9)
slowk,slowd=ta.STOCH(input_arrays['high'],input_arrays['low'],input_arrays['close'],fastk_period=5,slowk_period=3,slowk_matype=0,slowd_period=3,slowd_matype=0)
MIlist={
'macd':macd,
'macdsignal':macdsignal,
'macdhist':macdhist,
'slowk':slowk,
'slowd':slowd
}
#Pattern Recognition
cdl2crows=ta.CDL2CROWS(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
cdl3crows=ta.CDL3BLACKCROWS(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
cdl3inside=ta.CDL3INSIDE(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
cdl3linestrike=ta.CDL3LINESTRIKE(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
cdl3outside=ta.CDL3OUTSIDE(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
cdl3starsinsouth=ta.CDL3STARSINSOUTH(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
cdl3whitesoldiers=ta.CDL3WHITESOLDIERS(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
cdlabandonedbaby=ta.CDLABANDONEDBABY(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
cdladvanceblock=ta.CDLADVANCEBLOCK(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
cdlbelthold=ta.CDLBELTHOLD(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
cdlbreakaway=ta.CDLBREAKAWAY(input_arrays['open'],input_arrays['high'],input_arrays['low'],input_arrays['close'])
PRlist={
'cdl2crows':cdl2crows,
'cdl3crows':cdl3crows,
'cdl3inside':cdl3inside,
'cdl3linestrike':cdl3linestrike,
'cdl3outside':cdl3outside,
'cdl3starsinsouth':cdl3starsinsouth,
'cdl3whitesoldiers':cdl3whitesoldiers,
'cdlabandonedbaby':cdlabandonedbaby,
'cdladvanceblock':cdladvanceblock,
'cdlbelthold':cdlbelthold,
'cdlbreakaway':cdlbreakaway
}
return OSlist,MIlist,PRlist
#数据清洗
def featureEngineering(data,OSlist,MIlist,PRlist,indexdata,flow,timesteps=3):
length=len(data['close'])
original=[]
#将上证50ETF的各项特征序列拼接为一整块二维向量
for i in range(length):
original.append([])
for key,value in data.items():
if key!='trade_date' and key!='open':
original[-1].append(value[i])
for key,value in OSlist.items():
original[-1].append(value[i])
for key,value in MIlist.items():
original[-1].append(value[i])
for key,value in PRlist.items():
original[-1].append(value[i])
for key,value in indexdata.items():
if key!='open':
original[-1].append(value[i])
original[-1].append(flow['buy_sm_vol'][i]-flow['sell_sm_vol'][i])
original[-1].append(flow['buy_md_vol'][i]-flow['sell_md_vol'][i])
original[-1].append(flow['buy_lg_vol'][i]-flow['sell_lg_vol'][i])
original[-1].append(flow['buy_elg_vol'][i]-flow['sell_elg_vol'][i])
#数据规范化,构造数据集
dataX,dataY,date,rate=[],[],[],[]
for i in range(length-timesteps+1):
adata=original[i:(i+timesteps)]
if np.any(np.isnan(np.array(adata))):
continue
bdata=MinMaxScaler(feature_range=(0, 1)).fit_transform(adata)
label=0
trate=[0,0]
if i+timesteps<length:
maxclose=np.amax(adata, axis=0)[0]
minclose=np.amin(adata, axis=0)[0]
trate=[maxclose,minclose]
label=((original[i+timesteps][0])-minclose)/(maxclose-minclose)
if bdata[-1][0]-(adata[-1][0]-minclose)/(maxclose-minclose)>0.01:
print('wrong')
dataX.append(bdata)
dataY.append(label)
date.append(data['trade_date'][i+timesteps-1])
rate.append(trate)
return dataX,dataY,date,rate
#模型训练
def train(dataX,dataY):
train_X=np.array(dataX)
train_Y=np.array(dataY)
model=Sequential()
'''
首先构建三层LSTM神经网络,主要的可调参数为神经元个数,
神经元个数偏少将无法提取完整的数据特征,个数过多则容易
出现过拟合。经过反复测试我选择200作为隐层的神经元个数。
为了进一步防止过拟合,在每一层LSTM之间加入了Dropout
层,随机断开神经元的连接,抛弃阈值设定为0.2。
'''
model.add(LSTM(units=200,return_sequences=True,input_shape=(train_X.shape[1],train_X.shape[2])))
model.add(Dropout(0.2))
model.add(LSTM(units=200,return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=200,return_sequences=True))
model.add(Dropout(0.2))
'''
之后构建两层一维卷积层,卷积核大小各为256个,卷积核大
小为3,因为训练过程中涉及到较多的参数,所以选取Relu激
活函数,对过拟合进行控制,在每一次卷积后还加入了池化层,
对卷积结果下采样,对特征进行压缩,去除冗余信息。
'''
model.add(Conv1D(filters=256, kernel_size=3, activation='relu', strides=1, padding='same'))
model.add(AveragePooling1D(pool_size=2, strides=1))
model.add(Dropout(0.2))
model.add(Conv1D(filters=256, kernel_size=3, activation='relu', strides=1, padding='same'))
model.add(AveragePooling1D(pool_size=2, strides=1))
model.add(Dropout(0.2))
'''
最后加入了4层全连接层,综合各组特征,输出预测结果。
'''
model.add(Flatten())
model.add(Dense(units=256,activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(units=256,activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(units=128,activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(units=1,activation='relu'))
'''
损失函数为mae均方误差,优化器采用Adam。Adam算法是
一种自适应学习率的方法,它利用梯度的一阶矩阵估计和
二阶矩阵估计动态调整每个参数的学习率。学习率参数设
定为0.001。
'''
model.compile(loss='mae', optimizer=tf.keras.optimizers.Adam(0.001))
checkpoint_save_path = "./checkpoint/lstmconv_stock.ckpt"
if os.path.exists(checkpoint_save_path):
model.load_weights(checkpoint_save_path)
# 若成功加载前面保存的参数,输出下列信息
print("checkpoint_loaded")
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='val_loss')
'''
模型的epochs为100次,batch_size设定为32,shuffle
置为True在训练过程中随机打乱输入样本的顺序,使用回调
函数ModelCheckpoint,将在每个epoch后保存性能最好的
模型到指定文件中。模型训练时的评价指标为mae均方误差
'''
history = model.fit(train_X,
train_Y,
epochs=100,
batch_size=32,
validation_split=0.2,
verbose=1,
shuffle=True,
callbacks=[cp_callback])
model.summary()
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
return model
#模型使用与预测
def apply(model,testX,testY,date,rate):
#mode为0时比较明日预测值与当日真实值给出涨跌预测正确性判断
#mode为1时比较明日预测值与前一日预测的当日预测值给出涨跌预测正确性判断
mode=0
#将股票收盘价序列反归一化
testPredict = model.predict(np.array(testX))
for i in range(len(testPredict)):
testPredict[i]=testPredict[i]*(rate[i][0]-rate[i][1])+rate[i][1]
testY[i]=testY[i]*(rate[i][0]-rate[i][1])+rate[i][1]
# testX[i][-1][0]=testX[i][-1][0]*(testR[i][0]-testR[i][1])+testR[i][1]
if len(testY)>1:
plt.plot(testY[:-1],label='actual')
plt.plot(testPredict[:-1],label='predict')
plt.legend()
plt.show()
right=0
count=0
for i in range(len(testPredict)):
if testY[i]==0:
continue
count+=1
if mode:
ref_ans=testY[i-1]
ref_pre=testPredict[i-1]
else:
ref_ans=testY[i-1]
ref_pre=testY[i-1]
if (testY[i]>ref_ans and testPredict[i]>ref_pre) or (testY[i]<=ref_ans and testPredict[i]<=ref_pre):
right+=1
# calculate MSE 均方误差
mse=mean_squared_error(testY,testPredict)
# calculate RMSE 均方根误差
rmse = sqrt(mean_squared_error(testY,testPredict))
#calculate MAE 平均绝对误差
mae=mean_absolute_error(testY,testPredict)
#calculate R square
r_square=r2_score(testY,testPredict)
print('均方误差: %.6f' % mse)
print('均方根误差: %.6f' % rmse)
print('平均绝对误差: %.6f' % mae)
print('R_square: %.6f' % r_square)
for i in range(len(testPredict)):
print(date[i],end='\t')
if mode:
ref_ans=testY[i-1]
ref_pre=testPredict[i-1]
else:
ref_ans=testY[i-1]
ref_pre=testY[i-1]
if testPredict[i]>ref_pre:
print('↑',end='\t')
#数据集最后一个数据无法判断正确与否
if testY[i]==0:
print('?')
elif testY[i]>ref_ans:
print('\033[1;32m √ \033[0m')
else:
print('\033[1;31m × \033[0m')
elif testPredict[i]<=ref_pre:
print('↓',end='\t')
#数据集最后一个数据无法判断正确与否
if testY[i]==0:
print('?')
elif testY[i]<=ref_ans:
print('\033[1;32m √ \033[0m')
else:
print('\033[1;31m × \033[0m')
print(right,'-',count)
print(float(right)/float(count))
return testPredict[0],testY[0]
#完成整个实验过程
def function():
#可调参数:
###################
#基金代码
scode='510050.SH'
#时间序列长度
timesteps=35
#训练集占所有数据集的比例
train_rate=0.80
#是否制作新的数据集,如果选择否则使用保存的数据集,当更新数据集时间后要制作新的数据集
newdataset=False
#是否使用现有模型进行预测,如果要重新训练模型,该参数应该置为True
usemodel=False
###################
if newdataset:
data,indexdata,flow=getDailyData(stockcode=scode,startdate='20161125',enddate='20201231')
try:
f=open('dataset.dst','wb')
tup=(data,indexdata,flow)
pickle.dump(tup,f)
f.close()
except IOError as e:
print("error:caculate.write(data,indexdata,flow)",e)
else:
try:
f=open('dataset.dst','rb')
tup=pickle.load(f)
(data,indexdata,flow)=tup
except IOError as e:
print("error:caculate.read(dataset.dst)",e)
OSlist,MIlist,PRlist=taAnalysis(data)
dataX,dataY,date,rate=featureEngineering(data,OSlist,MIlist,PRlist,indexdata,flow,timesteps)
train_size=int(len(dataY)*train_rate)
if train_size==len(dataY) and dataY[-1]==0:
train_size-=1
trainX=dataX[:train_size]
trainY=dataY[:train_size]
testX=dataX[train_size:]
testY=dataY[train_size:]
testD=date[train_size:]
testR=rate[train_size:]
if not usemodel:
model=train(trainX,trainY)
model.save('LSTM模型')
else:
model=load_model('LSTM模型')
apply(model,testX,testY,testD,testR)
if __name__ == '__main__':
function()
参考文献
[1] 徐浩然,许波,徐可文.机器学习在股票预测中的应用综述[J].计算机工程与应用,2020,56(12):19-24.
[2] 赵红蕊,薛雷.基于LSTM-CNN-CBAM模型的股票预测研究[J/OL].计算机工程与应用:1-6[2021-01-10].http://kns.cnki.net/kcms/detail/11.2127.TP.20201120.1021.008.html.
[3] 陈泽均. 基于LSTM神经网络的标普500股票收益率预测研究[D].哈尔滨工业大学,2020.
[4] 杜睿. 基于GRU改进的LSTM门控制长短期记忆网络的股票交易策略设计[D].上海师范大学,2020.
[5] 陈伟斌,林奕真,王宗跃.股票信息挖掘与LSTM预测[J].集美大学学报(自然科学版),2020,25(05):385-391.