论文阅读:Generative Adversarial Transformers
1 摘要
背景:
- 本文的核心思想来自于认知科学领域经常讨论的人类感知的两种互惠机制:自下而上(从视网膜到视觉皮层 - 局部元素和显着刺激分层组合在一起形成整体)处理和 自上而下(围绕全局上下文、选择性注意和先验知识为特定的解释提供信息)处理;
- 过去十年在计算机视觉领域取得巨大成功的卷积神经网络并没有反映视觉系统的这种双向性质。相反,它的前馈传播只是通过从原始感觉信号建立更高的抽象表示来模拟自下而上的处理;
- CNN 的局部感受野和刚性计算会使得 CNN 缺乏对全局上下文的理解,这样会导致许多问题:
- 模型难以建立和捕捉长期依赖关系;
- 缺乏对全局形状和结构形成整体理解的能力;
- 优化和训练稳定性问题,如 GAN 模型普遍存在难训练的问题,因为在生成图像的精细细节之间的协调存在着固有的困难。
- 需要新型模型来缓解上述问题。
核心思想:
针对上述 CNN 对生成图像任务存在的问题,作者借助 transformer 思想,提出了一个双向结构。将 GAN 网络生成的图像的信息和隐藏变量的信息来回传递,鼓励双方从对方那里学到知识,让场景和物体能组合出现。其本质上是将 StyleGAN 推广,加上了 transformer。StyleGAN 的信息只从隐藏空间流向图片,而借助 transformer 让信息反向传递,提高隐藏变量的解耦性和质量。隐藏变量反过来影响生成的图像,让其质量更高。
主要贡献:
- 作者将生成模型 GAN 和序列数据特征提取器 transformer 相结合提出了一种新型架构:Generative Adversarial Transformers,简称 GANformer。GANformer 是一种新颖高效的 transformer,一种以关系注意力和动态交互为中心的高度自适应网络模型,作者将其用于探索视觉生成建模的任务;
- 该网络模型使用了一种二段式结构:bipartite transformer,可以在图像上进行远程交互,同时保持线性效率的计算,很容易扩展到高分辨率合成。GANformer 将传统 transformer 的计算复杂度从 O ( n 2 ) O(n^2) O(n2) 降低至 O ( n ) O(n) O(n),成功将 transformer 应用到高分辨率图像合成任务和场景合成任务之中;
- 与传统的 transformer 相比,GANformer 利用乘性集成,允许灵活的基于区域的调制,因此 GANformer 可以看作是 StyleGAN 网络的推广。
2 方法
Generative Adversarial Transformer(GANformer)是 Generative Adversarial Network(GAN)的一种,GAN 在 2014 年被提出,GAN 网络由生成器 (Generator) 和判别器 (Discrimnator) 组成,生成器主要功能是将潜在向量映射到图像,而判别器的主要功能是对生成器生成的图像进行真伪判别,在训练过程中,两个网络通过极小极大博弈相互竞争,直到达到平衡。直至今日,GAN 已广泛被运用于各个领域。
传统的生成器和判别器由多个卷积层来构建,而对于 GANformer,它们由被称为 bipartite transformer 的一种新型双向架构来构建的。GANformer 生成的示例图像如下,带有注意力分布图。

2.1 bipartite fransformer
传统的 transformer 网络由交替的多头自注意力层和前馈层组成。GANformer 的作者将每对自注意力和前馈层称为一个 transformer 层,因此一个 transformer 可以被认为是几个 transformer 层的堆叠。自注意力机制是 transformer 的核心思想和结构,将输入元素之间的所有成对关系(例如句子中每个单词之间的关系)向量化,从而通过关注所有其他元素来更新每个元素。bipartite transformer 可以被认为是自注意力的推广,bipartite transformer 不考虑每个元素对的关系,而是在两组变量之间计算注意力,作者将这种注意力机制称作 bipartite attention。对于 GAN 网络来说,一组潜在特征和图像特征就可以被认为是这样的组。
在论文中,作者提出了 bipartite attention 的两种结构。首先作者提出了一个比较传统的单向结构(simplex attention),然后改进出了双向结构(duplex attention)。

2.1.1 simplex attention
在单向结构中,定义输入为 X n × d X^{n×d} Xn×d,对于图像而言, n n n 等于 W × H W × H W×H,即图像的每个通道被拉成了维度为 d d d 的一维向量。 Y m × d Y^{m×d} Ym×d 表示一组 m m m 个聚合器变量,对于生成器来说是潜在向量。两个向量组之间的注意力计算公式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d ) V a ( X , Y ) = A t t e n t i o n ( q ( X ) , k ( Y ) , v ( Y ) ) Attention(Q, K, V ) = softmax(\frac{QK^T} {\sqrt{d} })V\\ a(X, Y ) = Attention(q(X), k(Y ), v(Y )) Attention(Q,K,V)=softmax(dQKT)Va(X,Y)=Attention(q(X),k(Y),v(Y))
其中, q ( ⋅ ) , k ( ⋅ ) , v ( ⋅ ) q(\cdot),k(\cdot),v(\cdot) q(⋅),k(⋅),v(⋅) 将 X X X 和 Y Y Y 分别映射到 Q , K , V Q,K,V Q,K,V 矩阵,尺寸均为 d × d d \times d d×d,因此 X X X 和 Y Y Y 经过映射之后,维度不发生变化。作者还加入了位置编码,辅助模型确定图像中每个元素的位置。简单的推导后可知 a ( X , Y ) a(X, Y) a(X,Y) 的维度是 n × d n × d n×d。当 X X X 等于 Y Y Y 时,simplex attention 变成 self-attention。
得到 a ( X , Y ) a(X, Y) a(X,Y) 后,就要将注意力信息传回 X X X。传统的方法是直接让 X X X 和注意力相加然后进行归一化操作:
u a ( X , Y ) = L a y e r N o r m ( X + a ( X , Y ) ) u^a(X, Y ) = LayerN orm(X + a(X, Y )) ua(X,Y)=LayerNorm(X+a(X,Y))
GANformer 利用检索到的信息来控制元素的尺度和偏差,论文中沿用了 StyleGAN 的方法:
u s ( X , Y ) = γ ( a ( X , Y ) ) ⊙ ω ( X ) + β ( a ( X , Y ) ) u^s(X, Y ) = \gamma (a(X, Y ))\odotω(X) + \beta (a(X, Y )) us(X,Y)=γ(a(X,Y))⊙ω(X)+β(a(X,Y))
其中, γ ( ⋅ ) , β ( ⋅ ) \gamma(\cdot),\beta(\cdot) γ(⋅),β(⋅) 分别是乘法和加法因子,也就是缩放尺度和偏差的映射,维度均为 d × d d\times d d×d, w ( X ) = X − μ ( X ) σ ( X ) w(X) = \frac{X - \mu(X)} {\sigma(X)} w(X)=σ(X)X−μ(X),最终求得的 u s u^s us 的维度依然为 n × d n\times d n×d,这便是新的 X X X。通过对 X X X (生成器中的图像特征)进行标准化化,然后让 Y Y Y (潜在向量)控制 X X X 的统计趋势,从本质上实现了从 Y Y Y 到 X X X 的信息传播,直观地允许潜在者控制图像中空间关注区域的视觉生成,从而指导对象和实体的合成。而因为是单向结构,所以 Y Y Y 无任何变化。注意力图如下:

2.1.2 duplex attention
在 simplex attention 的基础之上。作者考虑 Y Y Y 拥有自己的键值结构: Y = ( K m × d , V m × d ) Y = (K^{m\times d}, V^{m\times d}) Y=(Km×d,Vm×d),其中 V V V 像以前一样存储 Y Y Y 的内容,即随机采样的潜在向量, K K K 由 K = a ( Y , X ) K = a(Y, X) K=a(Y,X) 计算得到,因此 K K K 为 X X X 和 Y Y Y 之间的注意力的质心,也即 X X X 中的元素加权求和的结果。基于上述分析,作者提出了一个新的注意力更新规则:
u d ( X , Y ) = γ ( A ( Q , K , V ) ⊙ ω ( X ) + β ( A ( Q , K , V ) ) u^d(X, Y) = \gamma (A(Q,K,V)\odot ω(X) + \beta(A(Q,K,V)) ud(X,Y)=γ(A(Q,K,V)⊙ω(X)+β(A(Q,K,V))
上述更新规则包括了两个注意力操作的组合:
- 通过 K = a ( Y , X ) K=a(Y,X) K=a(Y,X) 计算 X X X 和 Y Y Y 之间的注意力;
- 以 X X X 的质心也就是 K K K 为基础,通过 A ( X , K , V ) A(X, K, V) A(X,K,V) 来细化 X X X 和 Y Y Y 之间的注意力。
实验证明使用更新规则 u d u^d ud 比 u s u^s us 更加有效。为了支持 X X X 和 Y Y Y 之间的双向交互,作者将从 X X X 到 Y Y Y 和 从 Y Y Y 到 X X X 的 simplex attention 进行连接得到 duplex attention,其实就是交替计算 Y : = u a ( Y , X ) Y := u^a(Y, X) Y:=ua(Y,X) 和 X : = u d ( X , Y ) X := u^d(X, Y ) X:=ud(X,Y) 来更新 Y Y Y 和 X X X,达到同时获得自顶向下和自底向上的信息的效果。
2.1.3 整体架构
基于上述的 bipartite attention 机制,作者给出的 GANformer 的整体架构如下:

其中,左图表示 GANformer 层由 bipartite attention 机制组成,将信息从潜在空间传到图像空间,然后进行卷积和上采样操作。这些层被堆叠多次,并通过从 4 × 4 4\times 4 4×4 网格开始在不同层上细化,直至生成最终的高分辨率图像这是因为生成器网络是动态变化的,更详细可参考:https://arxiv.org/abs/1912.04958;右图表示潜在特征和图像特征相互关注以捕捉场景结构。StyleGAN 使用单个潜在值均匀地影响整个图像相比,但这样的话潜在向量的解耦性和灵活性依然受限,GANformer 将潜在向量 z z z 分成 k k k 份 { z 1 , z 2 , ⋯ , z k } \{z_1,z_2,\cdots,z_k\} {z1,z2,⋯,zk},这样不同潜在值会导致最终输出图像的不同语义的区域。
在 NLP 中的标准 transformer 中,每个 self-attention 层后面都有一个 FC 层,它独立处理每个元素(可以看作是 1 × 1 1\times 1 1×1 卷积,即降维)。而 GANformer 处理的是图像数据,为了是 transformer 有视觉适应性,作者在每个 bipartite attention 层后使用了大小为 k = ( 3 × 3 ) k = (3\times 3) k=(3×3) 的卷积核,每个卷积之后应用非线性激活函数 Leaky ReLU,然后生成器对图像进行上采样,判别器对输入图像进行下采样。为了让 transformer 知道图像中的特征位置,作者对视觉特征 X X X 加入了沿水平和垂直维度的正弦位置编码,同时也将位置信息嵌入潜在特征 Y Y Y 中。这种设计决策允许潜在特征和图像特征之间进行通信,从而实现了远距离像素之间的自适应远程交互。
对于计算效率,这种二段式架构使得 bipartite attention 的计算复杂度为 O ( m n ) O(mn) O(mn),而在实践中 m m m 一般的选择范围是 8 − 32 8 - 32 8−32,相比于 self-attention 的 O ( n 2 ) O(n^2) O(n2) 有很大优势。
2.2 生成器和判别器网络
GANformer 的设计主要依据于 StyleGAN,后者由于生成的图像质量高而在研究界广受欢迎。StyleGAN 的生成器网络通常由多个卷积层组成,这些卷积层将随机采样的潜在向量 z z z 到转换到图像。但是 StyleGAN 并没有直接使用 z z z 来生成图像,而是让 z z z 经过多层的 FC,解码成一个中间潜在向量 w w w。 w w w 利用 AdaIN模块,参与合成网络(synthesis network)中的每一层卷积后的图像的修改。
 )
)
这种方法可以将图像的视觉属性分解为不同的层,使得 StyleGAN 可以控制图片的全局效果,例如姿势、照明条件、相机位置或配色方案。即使这样,正如前面所说,因为 w w w 要管理每一层的风格,所以解耦性和灵活性依然受限,不能直接控制局部区域的图像生成。
针对上述问题,GANformer 的作者使用 bipartite fransformer 来构建生成器,让模型执行自适应区域调制。具体来说,GANformer 将潜在向量 z z z 分成 k k k 份 { z 1 , z 2 , ⋯ , z k } \{z_1,z_2,\cdots,z_k\} {z1,z2,⋯,zk},再将这 k k k 份向量分别输入同一个解耦网络,得到 k k k 个 w w w 向量作为 Y = ( y 1 , y 2 , ⋯ , y k ) Y = (y_1, y_2, \cdots, y_k) Y=(y1,y2,⋯,yk)。之后,在每一层卷积后,将得到的图片 X X X 和潜在变量 Y Y Y 输入注意力模块中,也即 bipartite attention 模块中进行双向信息传递。这种方法此允许在图像区域上进行灵活和动态的风格调整,这是因为软注意力倾向于根据元素的接近度和内容相似性对元素进行分组。
对于判别器,作者在每次卷积后都应用了 bipartite attention 模块,同时对潜在变量 Y Y Y 进行更新。在最后一层,作者将 Y Y Y 和最终的生成图像 X X X 进行拼接,跟原图像进行比较判断生成图像的真伪。
3 实验结果
论文比较了模型的训练速度,图像生成的质量和解缠性等属性,并在消融实验中探讨了 transformer 训练轮数对模型性能的影响。

FID 是图像保真度和多样性的可靠指标,其值越小越好,而在不同数据集上 GANformer 的 FID 均最小,也即生成图像的质量最好。
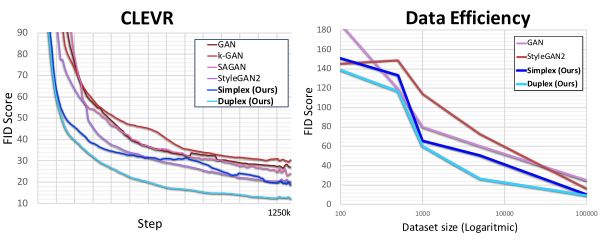
随着训练次数增多或数据规模增大,GANformer 的 FID 分数总是最低的,说明同样的训练规模,论文中的模型能取得更好的效果。

在生成场景中不同属性时,论文中的模型的卡方值也基本是最大的,因此 GANformer 对识别对象和语义分割有更强大的能力。
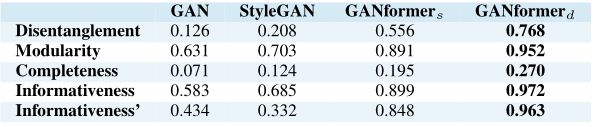
在上述的指标中,GANformer 均取得了最好的性能。
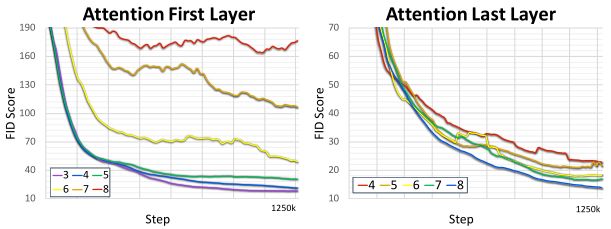
这里比较了最早使用注意力模块层数和最晚用注意力模块的层数。可以看出论文中的注意力模块十分有效,基本上越多越好,而且不能太晚才使用,在使用相同数量的情况下,越早使用越好。
4 结论
在论文中,作者成功将 GAN 和 Transformer 架构结合,并完成了场景生成任务。对该项工作总结如下:
- 将潜在向量分割成多份,能够使得生成的图像风格多元化,潜在向量的解耦性和灵活性得到提高;
- 二段式结构也即 bipartite structure 能够平衡模型的表达能力和效率,实现在保持线性计算成本的同时能建立数据间的长期依赖关系;
- 潜在特征和图像特征之间能够进行双向交互,允许以自下而上、自上而下的方式进行信息交换;
,潜在向量的解耦性和灵活性得到提高; - 二段式结构也即 bipartite structure 能够平衡模型的表达能力和效率,实现在保持线性计算成本的同时能建立数据间的长期依赖关系;
- 潜在特征和图像特征之间能够进行双向交互,允许以自下而上、自上而下的方式进行信息交换;
- 乘性集成的方法能够显著提高模型的性能。