计算机视觉(CV)-生成模型:GAN(Generative Adversarial Network对抗生成网络)【Generator(RNN/CNN)+Discriminator(CNN)】
人工智能-深度学习-生成模型:GAN(Generative Adversarial Network对抗生成网络)【Generator(RNN/CNN)+Discriminator(CNN)】
- 一、GAN概述
-
- 1、GAN基本思想
- 2、原始GAN解释
- 3、GAN的优点
- 二、GAN训练过程
-
- 1、算法解释
- 2、【生成模型】的最大似然估计
- 3、分步优化【判别器】、【生成器】的损失函数
- 3.1 【判别器】的损失函数
- 3.2 【生成器】的损失函数
- 四、原始GAN模型的问题
-
- 1、Mode Collapse(模式坍塌)
- 2、Mode Dropping
- 3、Mode Collapse、Mode Dropping 原因分析
-
- 3.1 数据的本质原因
- 3.2 我们是近似采样,并不能对原始数据全部采样
- 3.3 从原始GAN的目标函数分析
- 3.4 从判别器的sigmoid函数来讲,通俗的理解
- 4、Mode Collapse、Mode Dropping 的解决办法
- GAN的应用
-
- 1、Editing Photes
- 2、Image super resolution
- 3、Image Completion
- Evaluate GAN的结果
一、GAN概述
生成对抗网络(英语:Generative Adversarial Network,简称GAN)是生成模型的一种,生成模型就是用机器学习去生成我们想要的数据,正规的说法是,获取训练样本并训练一个模型,该模型能按照我们定义的目标数据分布去生成数据。
- 生成对抗网络(英语:Generative Adversarial Network,简称GAN)是通过让两个神经网络(【生成器】与【判别器】)相互博弈的方式进行学习。
- 生成对抗网络由一个【生成器】与一个【判别器】组成。
- 【生成器】从潜在空间(latent space)中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。
- 【判别器】的输入则为真实样本或生成网络的输出,其目的是将【生成器】的输出从真实样本中尽可能分辨出来。而【生成器】则要尽可能地欺骗【判别器】。
- 两个网络相互对抗、不断调整参数,最终目的是使【判别器】无法判断【生成器】的输出结果是否真实。

1、GAN基本思想
GAN 的核心思想源于博弈论的纳什均衡。
- 设定参与游戏的双方分别为一个生成器(Generator)和一个判别器(Discriminator),
- 生成器捕捉真实数据样本的潜在分布, 并生成新的数据样本;
- 判别器是一个二分类器, 判别输入是真实数据还是生成的样本。
- 为了取得游戏胜利, 这两个游戏参与者需要不断优化, 各自提高自己的生成能力和判别能力,
- 这个学习优化过程就是寻找二者之间的一个纳什均衡。
- GAN是一种二人零和博弈思想(two-player game),博弈双方的利益之和是一个常数。

- GAN的计算流程与结构如上图所示。
- 其中的生成器和判别器可以用任意可微分的函数,这里我们用可微分函数 D D D 和 G G G 来分别表示判别器和生成器,
- 【判别模型】 D D D 的输入为真实数据 x \textbf{x} x
- 【生成模型】 G G G 的输入为随机变量 z \textbf{z} z。
- G ( z ) G(\textbf{z}) G(z) 为由 G G G 生成的尽量服从真实数据分布 p d a t a p_{data} pdata 的样本。
- 如果判别器的输入来自真实数据 x \textbf{x} x,则标注为1;如果输入样本为 G ( z ) G(\textbf{z}) G(z), 标注为0。
- 这里 D D D 的目标是实现对数据来源的二分类判别: 真(来源于真实数据 x \textbf{x} x 的分布)或者伪(来源于生成器的伪数据 G ( z ) G(\textbf{z}) G(z))。
- 而 G G G 的目标是使自己生成的伪数据 G ( z ) G(\textbf{z}) G(z) 在 D D D 上的表现 D ( G ( z ) ) D(G(\textbf{z})) D(G(z)) 和真实数据 x \textbf{x} x 在 D D D 上的表现 D ( x ) D(\textbf{x}) D(x) 一致。
2、原始GAN解释

- 生成器和判别器都采用神经网络。
- 这个栗子中,我们有的只是真实采集而来的人脸样本数据集,值得一提的是我们连人脸数据集的类标签都没有,也就是我们不知道那个人脸对应的是谁。
- 最原始的GAN目的是想通过输入一个噪声,模拟得到一个人脸图像,这个图像可以非常逼真以至于以假乱真。(不同的任务想得到的东西不一样)
- 上图右半部分的【判别模型】是一个简单的神经网络结构,输入一幅图像,输出是一个概率值,用于判断真假使用(概率值大于0.5那就是真,小于0.5那就是假,人们定义的概率)
- 上图左半部分的【生成模型】也是神经网络结构,输入是随机数 z \textbf{z} z,输出是一个图像,不再是一个数值。
- 从图中可以看到,会存在两个数据集,一个是真实数据集,另一个是假的数据集(由生成网络生成的数据集)。
- 【判别模型】的目的:能判别出来输入的一张图它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接近1,输入的是假样本,网络输出接近0。
- 【生成模型】的目的:使得自己生成样本的能力尽可能强,强到判别网络没法判断自己生成的样本是真还是假。
- 由此可见,生成模型与判别模型的目的正好相反,一个说我能判别得好,一个说我让你判别不好,所以叫做对抗,叫做博弈。
- 而最后的结果到底是谁赢,就要归结于模型设计者希望谁赢了。作为设计者的我们,如果是要得到以假乱真的样本,那么就希望生成模型赢,希望生成的样本很真,判别模型能力不足以区分真假样本。
3、GAN的优点
GAN能够有效地解决很多生成式方法的缺点,主要包括:
- 并行产生samples;
- 生成式函数的限制少,比如无需合适马尔科夫采样的数据分布(Boltzmann machines),生成式函数无需可逆、latent code无需与sample同维度(nonlinear ICA);
- 无需马尔科夫链的方法(Boltzmann machines, GSNs);
- 相对于VAE的方法,无需variational bound;
- GAN比其他方法一般来说性能更好。
二、GAN训练过程
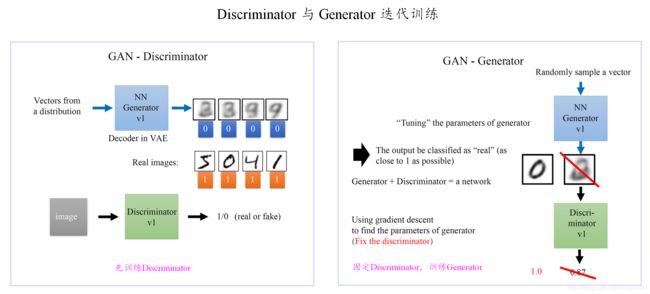
- 在噪声数据分布中随机采样,采样数据为 z \textbf{z} z,将 z \textbf{z} z 输入生成模型 G G G,得到一组假数据,记为 G ( z ) = x ~ G(\textbf{z})=\tilde{\textbf{x}} G(z)=x~;
- 在真实数据分布中随机采样,作为真实数据,记做 x ^ \hat{\textbf{x}} x^;
- 将 x ^ \hat{\textbf{x}} x^、 G ( z ) G(\textbf{z}) G(z) 作为【判别器】的输入(因此判别模型的输入为两类数据,真/假),【判别器】的输出值为该输入属于真实数据的概率,real为1,fake为0。
- 然后根据得到的概率值计算损失函数;
- 根据判别模型和生成模型的损失函数,可以利用反向传播算法,更新模型的参数。(先更新【判别模型】的参数,然后固定【判别模型】的参数,通过再采样得到的噪声数据更新【生成模型】的参数)。
1、算法解释

- 这里需要注意的是:生成模型与对抗模型是完全独立的两个模型,他们之间没有什么联系。那么训练采用的大原则是单独交替迭代训练。

- 因为是2个网络,不方便一起训练,所以才交替迭代训练。
- 先是【判别模型】:
- 初始化,给初始化的【生成模型】(此时的生成模型当然效果不好)一堆随机向量 z \textbf{z} z,就会得到一堆假的样本集 x ~ 0 \tilde{\textbf{x}}^0 x~0(因为【生成模型】是初始化的模型,生成的样本肯定不好,很容易就被判别网络判别为假)。
- 非初始化时,将初始化时的随机向量 z \textbf{z} z 喂给优化后的【生成模型】,得到一堆假的样本集 x ~ \tilde{\textbf{x}} x~(因为【生成模型】不再是初始化时的模型,所以 x ~ \tilde{\textbf{x}} x~会比 x ~ 0 \tilde{\textbf{x}}^0 x~0的效果好一些,但是此时的【生成模型】仍然不是最终的生成模型,所以现在的【生成模型】仍然处于劣势,导致生成的样本 x ~ \tilde{\textbf{x}} x~ 与真实样本 x ^ \hat{\textbf{x}} x^ 相比还是不太好,很容易就被【判别模型】判别为假)。
- 现在有了假样本集 x ~ \tilde{\textbf{x}} x~(真样本集 x ^ \hat{\textbf{x}} x^一直都有),我们再人为地定义真假样本集的标签,很明显,这里我们默认真样本集的类标签为1,而假样本集的类标签为0,因为我们希望真样本集的输出尽可能为1,假样本集为0。
- 现在有了真样本集 x ^ \hat{\textbf{x}} x^ 以及它们的label(都是1)、假样本集 x ~ \tilde{\textbf{x}} x~ 以及它们的label(都是0)。这样一来,单就判别网络来说,问题变成了有监督的二分类问题了,直接送进神经网络中训练就好。
- 判别网络训练完了。
- 继续来看【生成模型】:
- 对于【生成器】,我们的目的是生成尽可能逼真的样本。
- 而单独的【生成器】生成的样本的真实程度只能通过【判别器】才知道,所以在训练【生成模型】时,需要将【生成器】与【判别器】联合起来才能达到【生成模型】训练的目的。即:【生成模型】=【生成器】+【判别器】
- 所以【生成模型】的训练其实是对【生成器】+【判别器】串接的训练,像上图显示的那样。因为如果只使用生成网络,那么无法得到误差,也就无法训练。
- 当初始化的噪声向量 z \textbf{z} z 通过单独的【生成器】生成了假样本 x ~ \tilde{\textbf{x}} x~ 后,把这些假样本 x ~ \tilde{\textbf{x}} x~ 的标签都设置为1,即认为这些假样本 x ~ \tilde{\textbf{x}} x~ 在【生成模型】中训练的时候是真样本。因为此时是通过【判别器】来生成误差的,而误差回传的目的是使得【生成器】生成的假样本 x ~ \tilde{\textbf{x}} x~ 逐渐逼近为真样本 x ^ \hat{\textbf{x}} x^(当假样本 x ~ \tilde{\textbf{x}} x~ 不真实,标签却为1时,【判别器】给出的误差会很大,这就迫使【生成器】进行很大的调整;反之,当假样本 x ~ \tilde{\textbf{x}} x~ 足够真实,标签为1时,【判别器】给出的误差就会减小,这就完成了假样本 x ~ \tilde{\textbf{x}} x~ 向真样本 x ^ \hat{\textbf{x}} x^ 逐渐逼近的过程),起到迷惑【判别器】的目的。
- 现在对于【生成器】的训练,有了样本集(只有假样本集 x ~ \tilde{\textbf{x}} x~,没有真样本集),有了对应的label(全为1),有了误差,就可以开始训练了。
- 在训练这个【生成模型】时,一个很重要的操作是固定【判别器】的参数,不让【判别器】的参数 θ d θ_d θd 更新,只是让【判别器】将误差传到【生成器】,更新【生成器】的参数 θ g θ_g θg ,所以每轮迭代时,【生成模型】只更新一次,而且步幅也不能太大,以保证 θ d t ≈ θ d t + 1 θ^t_d≈θ^{t+1}_d θdt≈θdt+1。
- 在【生成器】训练完后,用新的【生成器】对先前的噪声向量 z \textbf{z} z 生成新的假样本 x ~ \tilde{\textbf{x}} x~,不出意外,这次生成的假样本 x ~ \tilde{\textbf{x}} x~ 会更真实。
- 有了新的真&假样本集 x ^ \hat{\textbf{x}} x^ & x ~ \tilde{\textbf{x}} x~(其实只有假样本集 x ~ \tilde{\textbf{x}} x~更新了),就又可以重复上述过程了。
- 整个过程就叫单独交替训练。可以定义一个迭代次数,交替迭代到一定次数后停止即可。不出意外,这时噪声 z \textbf{z} z 生成的假样本 x ~ \tilde{\textbf{x}} x~ 就会很真实了。
- GAN设计的巧妙处之一,在于假样本在训练过程中的真假变换,这也是博弈得以进行的关键之处。
2、【生成模型】的最大似然估计
- 【生成模型】=【生成器】+【判别模型】
- 上面提到,我们想要将一个随机高斯噪声 z \textbf{z} z 通过一个【生成器】 G \textbf{G} G 得到一个和真的数据分布 P d a t a ( x ) P_{data}(\textbf{x}) Pdata(x) 差不多的生成分布 P G ( x ; θ G ) P_G(\textbf{x};\textbf{θ}_G) PG(x;θG),其中的参数 θ G \textbf{θ}_G θG 是网络的参数决定的,我们希望找到 θ G \textbf{θ}_G θG 使得 P G ( x ; θ G ) P_G(\textbf{x};\textbf{θ}_G) PG(x;θG) 和 P d a t a ( x ) P_{data}(\textbf{x}) Pdata(x) 尽可能接近。
- 我们从真实数据分布 P d a t a ( x ) P_{data}(\textbf{x}) Pdata(x) 中取样 m m m 个点: { x ^ 1 , x ^ 2 , ⋯ , x ^ m } \{\hat{\textbf{x}}_1,\hat{\textbf{x}}_2,⋯,\hat{\textbf{x}}_m\} {x^1,x^2,⋯,x^m};
- 根据给定的【生成器】的参数 θ G \textbf{θ}_G θG 我们可以计算如下的概率 P G ( x i ; θ G ) P_G(\textbf{x}_i;\textbf{θ}_G) PG(xi;θG),那么通过【生成器】生成 { x ^ 1 , x ^ 2 , ⋯ , x ^ m } \{\hat{\textbf{x}}_1,\hat{\textbf{x}}_2,⋯,\hat{\textbf{x}}_m\} {x^1,x^2,⋯,x^m} 这 m m m 个真实样本数据的似然概率(likelihood)就是: L = ∏ i = 1 m P G ( x ^ i ; θ G ) L=\prod^m_{i=1} P_G(\hat{\textbf{x}}_i;\textbf{θ}_G) L=i=1∏mPG(x^i;θG)
- 我们要做的就是找到 θ G ∗ \textbf{θ}_G^* θG∗ 来最大化这个似然估计。
θ G ∗ = arg max θ G ∏ i = 1 m P G ( x ^ i ; θ G ) ( 公式 01 ) − m a x i m i z e t h e l i k e l i h o o d = arg max θ G l n [ ∏ i = 1 m P G ( x ^ i ; θ G ) ] = arg max θ G ∑ i = 1 m l n [ P G ( x ^ i ; θ G ) ] { x ^ 1 , x ^ 2 , ⋯ , x ^ m } f r o m P d a t a ( x ^ ) ≈ arg max θ G E x ^ ∼ P d a t a { l n [ P G ( x ^ ; θ G ) ] } = arg max θ G ∫ x ^ P d a t a ( x ^ ) l n [ P G ( x ^ ; θ G ) ] d x ^ = arg max θ G ∫ x ^ P d a t a ( x ^ ) l n [ P G ( x ^ ; θ G ) ] d x ^ − 0 = arg max θ G ∫ x ^ P d a t a ( x ^ ) l n [ P G ( x ^ ; θ G ) ] d x ^ − ∫ x ^ P d a t a ( x ^ ) l n [ P d a t a ( x ^ ; θ G ) ] d x ^ = arg max θ G ∫ x ^ P d a t a ( x ^ ) l n P G ( x ^ ; θ G ) P d a t a ( x ^ ; θ G ) d x ^ = arg max θ G [ − ∫ x ^ P d a t a ( x ^ ) l n P d a t a ( x ^ ; θ G ) P G ( x ^ ; θ G ) d x ^ ] = arg min θ G ∫ x ^ P d a t a ( x ^ ) l n P d a t a ( x ^ ; θ G ) P G ( x ^ ; θ G ) d x ^ = arg min θ G K L ( P d a t a ( x ^ ) ∣ ∣ P G ( x ^ ; θ G ) ) K L − d i v e r g e n c e b e t w e e n d i s t r i b u t i o n s P d a t a ( x ^ ) a n d P G ( x ^ ; θ G ) \begin{aligned} \textbf{θ}_G^*&=\arg \max_{\textbf{θ}_G}\prod^m_{i=1}P_G(\hat{\textbf{x}}_i;\textbf{θ}_G) \quad (公式01)-\color{blue}{maximize\ the\ likelihood}\\ &=\arg \max_{\textbf{θ}_G}ln\left[\prod^m_{i=1}P_G(\hat{\textbf{x}}_i;\textbf{θ}_G)\right]\\ &=\arg \max_{\textbf{θ}_G}\sum^m_{i=1}ln\left[P_G(\hat{\textbf{x}}_i;\textbf{θ}_G)\right] \qquad \{\hat{\textbf{x}}_1,\hat{\textbf{x}}_2,⋯,\hat{\textbf{x}}_m\}\ from\ P_{data}(\hat{\textbf{x}})\\ &\color{violet}{≈\arg \max_{\textbf{θ}_G}E_{\hat{\textbf{x}} \sim P_{data}}\{ln\left[P_G(\hat{\textbf{x}};\textbf{θ}_G)\right]\}}\\ &=\arg \max_{\textbf{θ}_G}\int_{\hat{\textbf{x}}} P_{data}(\hat{\textbf{x}})ln\left[P_G(\hat{\textbf{x}};\textbf{θ}_G)\right]d\hat{\textbf{x}}\\ &=\arg \max_{\textbf{θ}_G}\int_{\hat{\textbf{x}}} P_{data}(\hat{\textbf{x}})ln\left[P_G(\hat{\textbf{x}};\textbf{θ}_G)\right]d\hat{\textbf{x}}-\color{violet}{0}\\ &=\arg \max_{\textbf{θ}_G}\int_{\hat{\textbf{x}}} P_{data}(\hat{\textbf{x}})ln\left[P_G(\hat{\textbf{x}};\textbf{θ}_G)\right]d\hat{\textbf{x}}-\color{violet}{\int_{\hat{\textbf{x}}} P_{data}(\hat{\textbf{x}})ln\left[P_{data}(\hat{\textbf{x}};\textbf{θ}_G)\right]d\hat{\textbf{x}}}\\ &=\arg \max_{\textbf{θ}_G}\int_{\hat{\textbf{x}}} P_{data}(\hat{\textbf{x}})ln\cfrac{P_G(\hat{\textbf{x}};\textbf{θ}_G)}{P_{data}(\hat{\textbf{x}};\textbf{θ}_G)}d\hat{\textbf{x}}\\ &=\arg \max_{\textbf{θ}_G}\left[-\int_{\hat{\textbf{x}}} P_{data}(\hat{\textbf{x}})ln\cfrac{P_{data}(\hat{\textbf{x}};\textbf{θ}_G)}{P_G(\hat{\textbf{x}};\textbf{θ}_G)}d\hat{\textbf{x}}\right]\\ &=\arg \min_{\textbf{θ}_G} \int_{\hat{\textbf{x}}} P_{data}(\hat{\textbf{x}})ln\cfrac{P_{data}(\hat{\textbf{x}};\textbf{θ}_G)}{P_G(\hat{\textbf{x}};\textbf{θ}_G)}d\hat{\textbf{x}}\\ &=\arg \min_{\textbf{θ}_G}KL(P_{data}(\hat{\textbf{x}})||P_G(\hat{\textbf{x}};\textbf{θ}_G)) \quad \color{blue}{KL-divergence\ between\ distributions\ P_{data}(\hat{\textbf{x}})\ and\ P_G(\hat{\textbf{x}};\textbf{θ}_G)}\\ \end{aligned} θG∗=argθGmaxi=1∏mPG(x^i;θG)(公式01)−maximize the likelihood=argθGmaxln[i=1∏mPG(x^i;θG)]=argθGmaxi=1∑mln[PG(x^i;θG)]{x^1,x^2,⋯,x^m} from Pdata(x^)≈argθGmaxEx^∼Pdata{ln[PG(x^;θG)]}=argθGmax∫x^Pdata(x^)ln[PG(x^;θG)]dx^=argθGmax∫x^Pdata(x^)ln[PG(x^;θG)]dx^−0=argθGmax∫x^Pdata(x^)ln[PG(x^;θG)]dx^−∫x^Pdata(x^)ln[Pdata(x^;θG)]dx^=argθGmax∫x^Pdata(x^)lnPdata(x^;θG)PG(x^;θG)dx^=argθGmax[−∫x^Pdata(x^)lnPG(x^;θG)Pdata(x^;θG)dx^]=argθGmin∫x^Pdata(x^)lnPG(x^;θG)Pdata(x^;θG)dx^=argθGminKL(Pdata(x^)∣∣PG(x^;θG))KL−divergence between distributions Pdata(x^) and PG(x^;θG) - ∵ \textbf{∵} ∵ P d a t a ( x ^ ) P_{data}(\hat{\textbf{x}}) Pdata(x^)、 P G ( x ^ ; θ ) P_G(\hat{\textbf{x}};\textbf{θ}) PG(x^;θ) 根本没办法被直接求出; ∴ \textbf{∴} ∴ 无法直接通过整体模型来求【生成器】的参数 θ G \textbf{θ}_G θG
- 需要将 K L ( P d a t a ( x ^ ) ∣ ∣ P G ( x ^ ; θ ) ) KL(P_{data}(\hat{\textbf{x}})||P_G(\hat{\textbf{x}};\textbf{θ})) KL(Pdata(x^)∣∣PG(x^;θ)) 整体上做一个等价变换:分步求解,即先优化【判别器】得到 θ D ( 1 ) \textbf{θ}^{(1)}_D θD(1),然后基于 θ D ( 1 ) \textbf{θ}^{(1)}_D θD(1) 再优化【生成网络+判别网络】得到 θ G ( 1 ) \textbf{θ}^{(1)}_G θG(1),
- 然后再优化【判别器】得到 θ D ( 2 ) \textbf{θ}^{(2)}_D θD(2),然后基于 θ D ( 2 ) \textbf{θ}^{(2)}_D θD(2) 再优化【生成网络+判别网络】得到 θ G ( 2 ) \textbf{θ}^{(2)}_G θG(2)
- 迭代以上过程,最后即可得到最优化的 θ G ∗ \textbf{θ}^*_G θG∗
3、分步优化【判别器】、【生成器】的损失函数
- 下面公式中:
- θ D \textbf{θ}_D θD 、 D D D、 D ( x ) D(\textbf{x}) D(x)表示的含义一样,都是表示【判别器】;
- θ G \textbf{θ}_G θG 、 G G G、 G ( x ) G(\textbf{x}) G(x)表示的含义一样,都是表示【生成器】;
- 因为每个模型都是由组成它的参数唯一决定。

3.1 【判别器】的损失函数
- 虽然,我们不知道 P d a t a ( x ^ ) P_{data}(\hat{\textbf{x}}) Pdata(x^)、 P G ( x ^ ; θ ) P_G(\hat{\textbf{x}};\textbf{θ}) PG(x^;θ) 的 分布(distribution) 是什么样子的,但是我们可以从这两个 distributions 中分别随机取样,即:
- 从真实数据集 { x ^ 1 , x ^ 2 , ⋯ , x ^ m } \{\hat{\textbf{x}}_1,\hat{\textbf{x}}_2,⋯,\hat{\textbf{x}}_m\} {x^1,x^2,⋯,x^m} 中取样 { x ^ 1 , x ^ 2 , ⋯ , x ^ n } \{\hat{\textbf{x}}_1,\hat{\textbf{x}}_2,⋯,\hat{\textbf{x}}_n\} {x^1,x^2,⋯,x^n}
- 将一组随机高斯噪声 { z 1 , z 2 , . . . , z m } \{\textbf{z}_1,\textbf{z}_2,...,\textbf{z}_m\} {z1,z2,...,zm} 通过一个【生成器】 G \textbf{G} G 得到一组样本 { x ~ 1 , x ~ 2 , . . . , x ~ n } \{\tilde{\textbf{x}}_1,\tilde{\textbf{x}}_2,...,\tilde{\textbf{x}}_n\} {x~1,x~2,...,x~n}
- 通过这两组样本 { x ^ 1 , x ^ 2 , ⋯ , x ^ n } \{\hat{\textbf{x}}_1,\hat{\textbf{x}}_2,⋯,\hat{\textbf{x}}_n\} {x^1,x^2,⋯,x^n} 与 { x ~ 1 , x ~ 2 , . . . , x ~ n } \{\tilde{\textbf{x}}_1,\tilde{\textbf{x}}_2,...,\tilde{\textbf{x}}_n\} {x~1,x~2,...,x~n} 去训练一个【判别器】 D \textbf{D} D,给 { x ^ 1 , x ^ 2 , ⋯ , x ^ n } \{\hat{\textbf{x}}_1,\hat{\textbf{x}}_2,⋯,\hat{\textbf{x}}_n\} {x^1,x^2,⋯,x^n} 中的样本的分数越大越好,给 { x ~ 1 , x ~ 2 , . . . , x ~ n } \{\tilde{\textbf{x}}_1,\tilde{\textbf{x}}_2,...,\tilde{\textbf{x}}_n\} {x~1,x~2,...,x~n}中的样本的分数越小越好;
- 通过训练的结果就可以计算出来这两组样本 { x ^ 1 , x ^ 2 , ⋯ , x ^ n } \{\hat{\textbf{x}}_1,\hat{\textbf{x}}_2,⋯,\hat{\textbf{x}}_n\} {x^1,x^2,⋯,x^n} 与 { x ~ 1 , x ~ 2 , . . . , x ~ n } \{\tilde{\textbf{x}}_1,\tilde{\textbf{x}}_2,...,\tilde{\textbf{x}}_n\} {x~1,x~2,...,x~n}的 Divergence 的大小。
- ∵ \textbf{∵} ∵ 【判别器】 D \textbf{D} D 此时做的就是二分类问题,
- ∴ \textbf{∴} ∴ 【判别器】 D \textbf{D} D 做为二分类模型的损失函数为: J ( θ D ) = − ∑ i = 1 m [ y i l n y ^ i + ( 1 − y i ) l n ( 1 − y ^ i ) ] \begin{aligned}J(\textbf{θ}_D)&=-\sum_{i=1}^m[\textbf{y}_iln\hat{\textbf{y}}_i+(1-\textbf{y}_i)ln(1-\hat{\textbf{y}}_i)]\end{aligned} J(θD)=−i=1∑m[yilny^i+(1−yi)ln(1−y^i)]
- ∴ \textbf{∴} ∴ θ D ∗ = D ∗ = arg min θ D J ( θ D ) \textbf{θ}_D^*=D^*=\arg \min_{\textbf{θ}_D}J(\textbf{θ}_D) θD∗=D∗=argθDminJ(θD)
- 计算 J ( θ D ) J(\textbf{θ}_D) J(θD) 的极值:
− J ( θ D ) = ∑ i = 1 m [ y i l n y ^ i + ( 1 − y i ) l n ( 1 − y ^ i ) ] = ∑ i = 1 m y i l n y ^ i + ∑ i = 1 m [ ( 1 − y i ) l n ( 1 − y ^ i ) ] = ∑ i = 1 m y i l n D ( x ) + ∑ i = 1 m [ ( 1 − y i ) l n ( 1 − D ( x ) ] = E x ∼ P d a t a ( x ) [ l n D ( x ) ] + E x ∼ P G ( x ) [ l n ( 1 − D ( x ) ) ] = ∫ x P d a t a ( x ) l n D ( x ) d x + ∫ x P G ( x ) l n ( 1 − D ( x ) ) d x = ∫ x [ P d a t a ( x ) l n D ( x ) + P G ( x ) l n ( 1 − D ( x ) ) ] d x G i s f i x e d \begin{aligned}-J(\textbf{θ}_D)&=\sum_{i=1}^m[\textbf{y}_iln\hat{\textbf{y}}_i+(1-\textbf{y}_i)ln(1-\hat{\textbf{y}}_i)]\\[2ex] &=\sum_{i=1}^m\textbf{y}_iln\hat{\textbf{y}}_i+\sum_{i=1}^m[(1-\textbf{y}_i)ln(1-\hat{\textbf{y}}_i)]\\[2ex] &=\sum_{i=1}^m\textbf{y}_ilnD(\textbf{x})+\sum_{i=1}^m[(1-\textbf{y}_i)ln(1-D(\textbf{x})]\\[2ex] &=\color{violet}{E_{\textbf{x}\sim P_{data}(\textbf{x})}[lnD(\textbf{x})]+E_{\textbf{x}\sim P_G(\textbf{x})}[ln(1-D(\textbf{x}))]}\\ &=\int_\textbf{x}P_{data}(\textbf{x})lnD(\textbf{x})d\textbf{x}+\int_\textbf{x}P_G(\textbf{x})ln(1-D(\textbf{x}))d\textbf{x}\\ &=\int_\textbf{x}[P_{data}(\textbf{x})lnD(\textbf{x})+P_G(\textbf{x})ln(1-D(\textbf{x}))]d\textbf{x}\quad \color{violet}{G\ is\ fixed}\end{aligned} −J(θD)=i=1∑m[yilny^i+(1−yi)ln(1−y^i)]=i=1∑myilny^i+i=1∑m[(1−yi)ln(1−y^i)]=i=1∑myilnD(x)+i=1∑m[(1−yi)ln(1−D(x)]=Ex∼Pdata(x)[lnD(x)]+Ex∼PG(x)[ln(1−D(x))]=∫xPdata(x)lnD(x)dx+∫xPG(x)ln(1−D(x))dx=∫x[Pdata(x)lnD(x)+PG(x)ln(1−D(x))]dxG is fixed
- 上式中 l n D ( x ) lnD(\textbf{x}) lnD(x) 的含义是:如果 x \textbf{x} x 来自 P d a t a P_{data} Pdata,则 l n D ( x ) lnD(\textbf{x}) lnD(x) 越大越好; l n [ 1 − D ( x ) ] ln[1-D(\textbf{x})] ln[1−D(x)] 的含义是:如果 x \textbf{x} x 来自 P G P_G PG,则 l n D ( x ) lnD(\textbf{x}) lnD(x) 越小越好,等价于 l n [ 1 − D ( x ) ] ln[1-D(\textbf{x})] ln[1−D(x)]越大越好。
- 令 f [ D ( x ) ] = P d a t a ( x ) l n D ( x ) + P G ( x ) l n ( 1 − D ( x ) ) f[D(\textbf{x})]=P_{data}(\textbf{x})lnD(\textbf{x})+P_G(\textbf{x})ln(1-D(\textbf{x})) f[D(x)]=Pdata(x)lnD(x)+PG(x)ln(1−D(x)) ,
- 则: D ∗ = arg min D [ J ( θ D ) ] = arg max D [ − J ( θ D ) ] = arg max D f [ D ( x ) ] D^*=\arg \min_D[J(\textbf{θ}_D)]=\arg \max_D[-J(\textbf{θ}_D)]=\arg \max_Df[D(\textbf{x})] D∗=argDmin[J(θD)]=argDmax[−J(θD)]=argDmaxf[D(x)]
- f [ D ( x ) ] f[D(\textbf{x})] f[D(x)]对 D ( x ) D(\textbf{x}) D(x) 求导,令导数为0,就可求出 f [ D ( x ) ] f[D(\textbf{x})] f[D(x)] 最大时对应的 D ( x ) D(\textbf{x}) D(x) d f [ D ( x ) ] d D ( x ) = P d a t a ( x ) D ( x ) − P G ( x ) 1 − D ( x ) = 0 \cfrac{df[D(\textbf{x})]}{dD(\textbf{x})}=\cfrac{P_{data}(\textbf{x})}{D(\textbf{x})}-\cfrac{P_G(\textbf{x})}{1-D(\textbf{x})}=0 dD(x)df[D(x)]=D(x)Pdata(x)−1−D(x)PG(x)=0
- ∴ \textbf{∴} ∴
D ∗ ( x ) = P d a t a ( x ) P d a t a ( x ) + P G ( x ) D^*(\textbf{x})=\cfrac{P_{data}(\textbf{x})}{P_{data}(\textbf{x})+P_G(\textbf{x})} D∗(x)=Pdata(x)+PG(x)Pdata(x)
即:
θ D ∗ = D ∗ ( x ) = arg max D [ − J ( θ D ) ] = P d a t a ( x ) P d a t a ( x ) + P G ( x ) \textbf{θ}^*_D=D^*(\textbf{x})=\arg \max_D[-J(\textbf{θ}_D)]=\cfrac{P_{data}(\textbf{x})}{P_{data}(\textbf{x})+P_G(\textbf{x})} θD∗=D∗(x)=argDmax[−J(θD)]=Pdata(x)+PG(x)Pdata(x) - ∴ \textbf{∴} ∴ − J ( θ D ) -J(\textbf{θ}_D) −J(θD) 的极大值为:
− J ( θ D ∗ ) = E x ∼ P d a t a ( x ) [ l n D ∗ ( x ) ] + E x ∼ P G ( x ) [ l n ( 1 − D ∗ ( x ) ) ] = E x ∼ P d a t a ( x ) [ l n P d a t a ( x ) P d a t a ( x ) + P G ( x ) ] + E x ∼ P G ( x ) { l n [ 1 − P d a t a ( x ) P d a t a ( x ) + P G ( x ) ] } = E x ∼ P d a t a ( x ) [ l n P d a t a ( x ) P d a t a ( x ) + P G ( x ) ] + E x ∼ P G ( x ) [ l n P G ( x ) P d a t a ( x ) + P G ( x ) ] = ∫ x P d a t a ( x ) [ l n P d a t a ( x ) P d a t a ( x ) + P G ( x ) ] + ∫ x P G ( x ) [ l n P G ( x ) P d a t a ( x ) + P G ( x ) ] = ∫ x P d a t a ( x ) [ l n P d a t a ( x ) ( P d a t a ( x ) + P G ( x ) ) / 2 ] + ∫ x P G ( x ) [ l n P G ( x ) ( P d a t a ( x ) + P G ( x ) ) / 2 ] − 2 l n 2 = K L ( P d a t a ( x ) ∣ ∣ P d a t a ( x ) + P G ( x ) 2 ) + K L ( P G ( x ) ∣ ∣ P d a t a ( x ) + P G ( x ) 2 ) − 2 l n 2 = 2 J S [ P d a t a ( x ) ∣ ∣ P G ( x ) ] − 2 l n 2 J S − d i v e r g e n c e b e t w e e n d i s t r i b u t i o n s P d a t a ( x ^ ) a n d P G ( x ^ ; θ G ) \begin{aligned} -J(\textbf{θ}^*_D)&=E_{\textbf{x}\sim P_{data}(\textbf{x})}[lnD^*(\textbf{x})]+E_{\textbf{x}\sim P_G(\textbf{x})}[ln(1-D^*(\textbf{x}))]\\ &=E_{\textbf{x}\sim P_{data}(\textbf{x})}\left[ln\cfrac{P_{data}(\textbf{x})}{P_{data}(\textbf{x})+P_G(\textbf{x})}\right]+E_{\textbf{x}\sim P_G(\textbf{x})}\left\{ln\left[1-\cfrac{P_{data}(\textbf{x})}{P_{data}(\textbf{x})+P_G(\textbf{x})}\right]\right\}\\ &=E_{\textbf{x}\sim P_{data}(\textbf{x})}\left[ln\cfrac{P_{data}(\textbf{x})}{P_{data}(\textbf{x})+P_G(\textbf{x})}\right]+E_{\textbf{x}\sim P_G(\textbf{x})}\left[ln\cfrac{P_G(\textbf{x})}{P_{data}(\textbf{x})+P_G(\textbf{x})}\right]\\ &=\int_{\textbf{x}}P_{data}(\textbf{x})\left[ln\cfrac{P_{data}(\textbf{x})}{P_{data}(\textbf{x})+P_G(\textbf{x})}\right]+\int_{\textbf{x}}P_G(\textbf{x})\left[ln\cfrac{P_G(\textbf{x})}{P_{data}(\textbf{x})+P_G(\textbf{x})}\right]\\ &=\int_{\textbf{x}}P_{data}(\textbf{x})\left[ln\cfrac{P_{data}(\textbf{x})}{(P_{data}(\textbf{x})+P_G(\textbf{x}))/2}\right]+\int_{\textbf{x}}P_G(\textbf{x})\left[ln\cfrac{P_G(\textbf{x})}{(P_{data}(\textbf{x})+P_G(\textbf{x}))/2}\right]-2ln2\\ &=KL(P_{data}(\textbf{x})||\cfrac{P_{data}(\textbf{x})+P_G(\textbf{x})}{2})+KL(P_G(\textbf{x})||\cfrac{P_{data}(\textbf{x})+P_G(\textbf{x})}{2})-2ln2\\ &=2JS[P_{data}(\textbf{x})||P_G(\textbf{x})]-2ln2 \quad \color{blue}{JS-divergence\ between\ distributions\ P_{data}(\hat{\textbf{x}})\ and\ P_G(\hat{\textbf{x}};\textbf{θ}_G)} \end{aligned} −J(θD∗)=Ex∼Pdata(x)[lnD∗(x)]+Ex∼PG(x)[ln(1−D∗(x))]=Ex∼Pdata(x)[lnPdata(x)+PG(x)Pdata(x)]+Ex∼PG(x){ln[1−Pdata(x)+PG(x)Pdata(x)]}=Ex∼Pdata(x)[lnPdata(x)+PG(x)Pdata(x)]+Ex∼PG(x)[lnPdata(x)+PG(x)PG(x)]=∫xPdata(x)[lnPdata(x)+PG(x)Pdata(x)]+∫xPG(x)[lnPdata(x)+PG(x)PG(x)]=∫xPdata(x)[ln(Pdata(x)+PG(x))/2Pdata(x)]+∫xPG(x)[ln(Pdata(x)+PG(x))/2PG(x)]−2ln2=KL(Pdata(x)∣∣2Pdata(x)+PG(x))+KL(PG(x)∣∣2Pdata(x)+PG(x))−2ln2=2JS[Pdata(x)∣∣PG(x)]−2ln2JS−divergence between distributions Pdata(x^) and PG(x^;θG) - 可见: − J ( θ D ) -J(\textbf{θ}_D) −J(θD) 极大值 − J ( θ D ∗ ) -J(\textbf{θ}^*_D) −J(θD∗) 对应 P d a t a P_{data} Pdata分布与 P G P_G PG分布的JS-Divergence。
3.2 【生成器】的损失函数
- 【生成模型】=【生成器】+【判别器】
- 【生成模型】中的【判别器】使用刚刚优化过的【判别器】,所以【生成模型】中的【判别器】的最优损失函数为:
− J ( θ G , θ D ∗ ) = − J ( θ D ∗ ) = 2 J S [ P d a t a ( x ) ∣ ∣ P G ( x ) ] − 2 l n 2 \begin{aligned}-J(\textbf{θ}_G,\textbf{θ}^*_D)=-J(\textbf{θ}^*_D)=2JS[P_{data}(\textbf{x})||P_G(\textbf{x})]-2ln2 \end{aligned} −J(θG,θD∗)=−J(θD∗)=2JS[Pdata(x)∣∣PG(x)]−2ln2 - ∵ \textbf{∵} ∵ K L ⟺ J S KL\Longleftrightarrow JS KL⟺JS
- 由【生成模型】的最大似然估计(公式01)已计算得知: θ G ∗ = arg min θ G K L [ P d a t a ( x ^ ) ∣ ∣ P G ( x ^ ; θ G ) ] \begin{aligned} \textbf{θ}_G^*=\arg \min_{\textbf{θ}_G}KL[P_{data}(\hat{\textbf{x}})||P_G(\hat{\textbf{x}};\textbf{θ}_G)] \end{aligned} θG∗=argθGminKL[Pdata(x^)∣∣PG(x^;θG)]
- 【生成模型】损失函数的最优参数:
- ∴ \textbf{∴} ∴
θ G ∗ = arg min θ G K L [ P d a t a ( x ^ ) ∣ ∣ P G ( x ^ ; θ G ) ] = arg min θ G J S [ P d a t a ( x ^ ) ∣ ∣ P G ( x ^ ; θ G ) ] = arg min θ G 2 J S [ P d a t a ( x ) ∣ ∣ P G ( x ) ] − 2 l n 2 = arg min θ G max θ D [ − J ( θ G , θ D ) ] = arg min θ G [ − J ( θ G , θ D ∗ ) ] \begin{aligned} \textbf{θ}_G^*&=\arg \min_{\textbf{θ}_G}\color{violet}{KL[P_{data}(\hat{\textbf{x}})||P_G(\hat{\textbf{x}};\textbf{θ}_G)]}\\ &=\arg \min_{\textbf{θ}_G}\color{violet}{JS[P_{data}(\hat{\textbf{x}})||P_G(\hat{\textbf{x}};\textbf{θ}_G)]}\\ &=\arg \min_{\textbf{θ}_G}\color{violet}{2JS[P_{data}(\textbf{x})||P_G(\textbf{x})]-2ln2}\\ &=\arg \min_{\textbf{θ}_G}\color{violet}{\max_{\textbf{θ}_D}[-J(\textbf{θ}_G,\textbf{θ}_D)]}\\ &=\arg \min_{\textbf{θ}_G}\color{violet}{[-J(\textbf{θ}_G,\textbf{θ}^*_D)]}\\ \end{aligned} θG∗=argθGminKL[Pdata(x^)∣∣PG(x^;θG)]=argθGminJS[Pdata(x^)∣∣PG(x^;θG)]=argθGmin2JS[Pdata(x)∣∣PG(x)]−2ln2=argθGminθDmax[−J(θG,θD)]=argθGmin[−J(θG,θD∗)] - 通过梯度下降法从 θ G t \textbf{θ}_G^t θGt 迭代到 θ G t + 1 \textbf{θ}_G^{t+1} θGt+1 时,是在 θ D ∗ = ( θ D t ) ∗ = ( θ D t + 1 ) ∗ \textbf{θ}^*_D=(\textbf{θ}^t_D)^*=(\textbf{θ}^{t+1}_D)^* θD∗=(θDt)∗=(θDt+1)∗ 的条件下进行的。
- 但是实际上有可能 ( θ D t ) ∗ ≠ ( θ D t + 1 ) ∗ (\textbf{θ}^t_D)^*≠(\textbf{θ}^{t+1}_D)^* (θDt)∗=(θDt+1)∗,如下图,如果从 θ G t \textbf{θ}_G^t θGt 迭代到 θ G t + 1 \textbf{θ}_G^{t+1} θGt+1 时,有更大的极值点 − J ( θ G , θ D ∗ ) -J(\textbf{θ}_G,\textbf{θ}^*_D) −J(θG,θD∗) 出现,则不能满足从 θ G t \textbf{θ}_G^t θGt 迭代到 θ G t + 1 \textbf{θ}_G^{t+1} θGt+1 的条件: θ D ∗ = ( θ D t ) ∗ = ( θ D t + 1 ) ∗ \textbf{θ}^*_D=(\textbf{θ}^t_D)^*=(\textbf{θ}^{t+1}_D)^* θD∗=(θDt)∗=(θDt+1)∗

- 所以,从 θ G t \textbf{θ}_G^t θGt 迭代到 θ G t + 1 \textbf{θ}_G^{t+1} θGt+1 时,每次更新时不能太大,来保证 从 θ G t \textbf{θ}_G^t θGt 求 θ G t + 1 \textbf{θ}_G^{t+1} θGt+1 时 ( θ D t ) ∗ ≈ ( θ D t + 1 ) ∗ (\textbf{θ}^t_D)^*≈(\textbf{θ}^{t+1}_D)^* (θDt)∗≈(θDt+1)∗
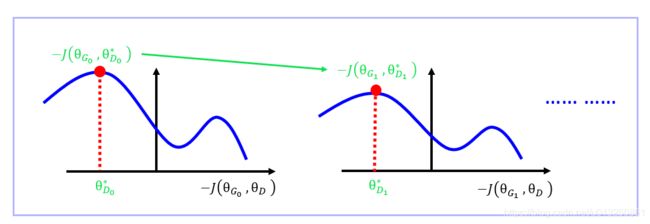
- 所以,每一轮交替更新【生成器】与【判别器】的时候,每一轮【生成器】只更新一次,【判别器】迭代无数次直到找到 θ D ∗ θ^*_D θD∗ 处的JS-Divergence,即 − J ( θ G , θ D ∗ ) -J(\textbf{θ}_G,\textbf{θ}^*_D) −J(θG,θD∗)。
四、原始GAN模型的问题
1、Mode Collapse(模式坍塌)
- mode collapse是指Gan产生的样本单一,其认为满足某一分布的结果为true,其他为False,导致以上结果。
- 先给一个直观的例子,这个是在我们训练GAN的时候经常出现的。

- 这就是所谓的Mode Collapse
- 但是实际中ModeCollapse不能像这个一样这么容易被发现(sample中出现完全一模一样的图片)
- 例如训练集有很多种类别(如猫狗牛羊),但是我们只能生成狗(或猫或牛或羊),虽然生成的狗的图片质量特别好,但是!整个【生成模型】就只能生成狗,根本没法生成猫牛羊,陷入一种训练结果不好的状态。这和我们对GAN的预期是相悖的。

- 如上图, P d a t a P_{data} Pdata是八个高斯分布的点,也就是8个mode。
- 我们希望给定一个随机高斯分布(中间列中的最左图),我们希望这一个随机高斯分布经过G最后可以映射到这8个高斯分布的mode上面去
- 但是最下面一列的图表明,我们不能映射到这8个高斯分布的mode上面,整个G只能生成同一个mode,由于G和D的对抗关系,G不断切换mode
- 在step10k的时候,G的位置在某一个 Gaussian所在位置,然后D发现G只是在这个Gaussian这里了,所以就把这个地方的所有data(无论real还是fake)都给判定为fake
- G发现在这个Gaussian待不下去了,只会被D永远判定为fake,所以就想着换到另一个地方。在step15k就跳到了另一个Gaussian上去
- 然后不断跳跳跳,不断重复上述两个过程,就像猫捉老鼠的过程一样,然后就没有办法停下来,没法达到我们理想中映射到8个不同的Gaussian上面去
2、Mode Dropping
训练了多次以后,生成的图片人脸分布都是一样的,只有色调的改变。
3、Mode Collapse、Mode Dropping 原因分析
- 出现Mode Collapse、Mode Dropping问题可能是因为散度函数没选好。但是实践中发现,即使换了散度函数,问题依旧存在。
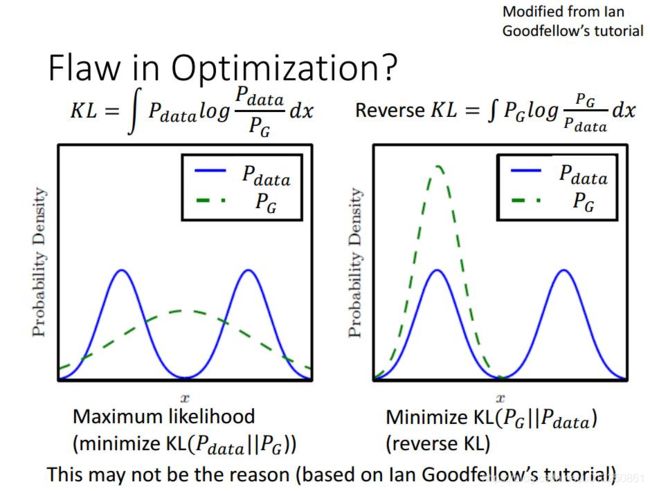

- 总的来说就是梯度消失问题,梯度消失我们的模型训练也就失去了方向,无法再进行下去了。在discriminator训练太好时往往会出现这个问题。
- 从以下几个角度来分析:
3.1 数据的本质原因
- 因为数据本身就是一种高维空间的低维流形表现,他们之间几乎没有重叠,因此,很容易导致JS divergence最大,loss为0,
- Both _ and _ are low-dim manifold in high-dim space. The overlap can be ignored.
- 如下图所示。
3.2 我们是近似采样,并不能对原始数据全部采样
- Loss如下:

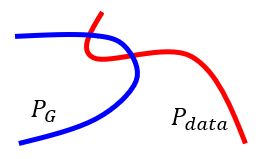
- 说明从两个分布采样的数据没有重合区域,但是其实两组数据之间有重合,只是判别器太强了,可以找到一条线将两组数据分开,如图所示。
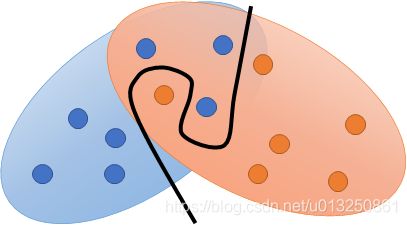
- 图上的点是两个分布的采样数据,因为我们并不知道分布,只能对分布采样,通过采样后的数据分布近似原始分布

- 通过对分布采样,总能找到一条线将两组数据分开,因此我们要削弱【判别器】的能力,但是同时,我们又想让【判别器】具有很强的能力来进行分类,所以很矛盾,不知道削弱多少【判别器】的能力才合适,很难控制。
- 早年还没有种种 tip 的时候,GAN 其实不太容易 train 起来,你 train 的时候通常就是你一边 update discriminator,然后你就一边吃饭,然后你就看他 output 的结果,每 10 个 iteration 就 output 一次结果,看它好不好,如果发现结果不好的话,就重做。
- 二分类【判别器】非常强,导致Loss都是0,不能引导【生成器】更新
3.3 从原始GAN的目标函数分析


- 以最优的D参数带入,最后生成器目标可以写成JS散度形式,根据JS散度的性质,如果当两个样本分布几乎没有重叠时,JS散度为一个常数,这也就出现了梯度为0的现象。
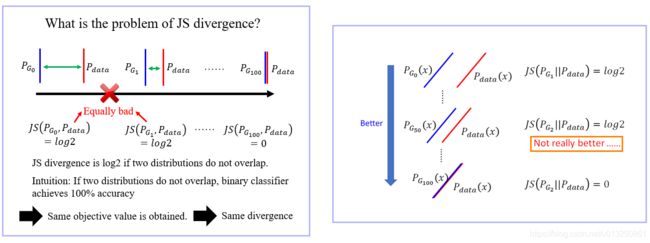
- 由上图可知,初始两个数据分布差别很大,我们想通过一定的迭代使得两个分布之间差别越来越小,最后重合,但是前面的JS divergence都是log2,即loss为0,并不会更新生成器的参数,因此并不会有效地引导越来越好的过程。也就是说 JS-Divergence不适合作为衡量标准。
3.4 从判别器的sigmoid函数来讲,通俗的理解
- 我们的最终目的是让蓝色点顺着判别器给的梯度移动到近似绿色点位置(即生成样本接近于真实样本),
- 如果我们把discriminator训练的非常好的话,蓝色的fake点(生成的样本)会很难移动,因为sigmoid的曲线在最低处几乎都是很平的,判别器无法给出合适的梯度。
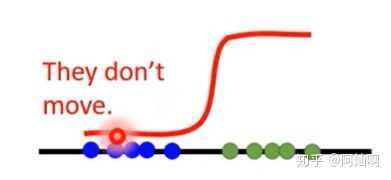
- 举个栗子,假设这条sigmoid曲线中间的横轴代表你考试的分数,纵轴代表老师的奖惩力度,中线部分代表考试分数80分,而整条曲线就代表着老师奖惩的制度。
- 那么你是一个开始不是很优秀的学生比如蓝点,那么如果你一开始是40分,老师按照制度给了你很严厉的惩罚,于是你觉得你要改变!但是你不可能一下改变很多分,下次你尝试考了50分,虽然进步了10分,但不出意外你又受到了和以前差不多严厉的惩罚,那你下次可能尝试我考个30试试,结果依旧严厉惩罚,你崩溃了,你已经不知道老师怎么才能满意了,类似这样生成器也就停滞不前了。

4、Mode Collapse、Mode Dropping 的解决办法
- 鼓励多样化:单独考虑独立样本无法产生多样化的结果,因此使用 batches of samples
- 提前估计:不是生成器学习欺骗当前的鉴别器,是它学会在有机会响应之后最大限度地欺骗鉴别器
- 通过每隔一段时间向判别器输入旧的假样本,最小化在模式之间来回跳转
- Ensemble(集成学习方法):训练多个GAN
GAN的应用
1、Editing Photes
2、Image super resolution
3、Image Completion
Evaluate GAN的结果
Inception Score
参考资料:
用变分推断统一理解生成模型(VAE、GAN、AAE、ALI)
转载 | 史上最全GAN综述2020版:算法、理论及应用
GAN 的Mode collapse(模式坍塌)
从泛化性到Mode Collapse:关于GAN的一些思考
Improved Techniques for Training GANs.
生成对抗网络(GAN,Generative Adversarial Networks) 学习笔记
生成对抗网络(GAN)简单梳理
原始GAN(生成对抗网络)详细解析
AI-Methods:Gan-Tutorial
用变分推断理解GAN
GAN、VAE原理学习 + 苏剑林《用变分推断统一理解生成模型》《变分自编码器》(更新中)
基于变分推断,我们对GAN有什么新的认识?