Redis从部署群集到ASK路由
目录
数据库简介
一、数据库分类
二、Redis重要特性
三、redis应用场景
安装redis
redis基本命令
redis持久化
redis主从复制
redis集群
群集实施
配置节点发现
Redis Cluster 通讯流程
Redis Cluster手动分配槽位
Redis Cluster ASK路由介绍
模拟故障转移
自动搭建部署Redis Cluster
工具扩容节点
工具收缩节点
Redis常用命令(扩展内容)
数据库简介
一、数据库分类
关系型: mysql oracle sqlserver db2 postgresql
非关系型:redis(缓存) mongodb(列表菜单) Elasticsearch(购物网站搜索引擎)
二、Redis重要特性
1. 速度快(去掉了安全性机制)
c语言写的
代码优雅
单线程架构
2. 支持多种数据结构
字符串,哈希,列表,集合,有序集合
3. 丰富的功能
天然计数器
健过期功能
消息队列(解决上游程序和下游程序的交接问题)
4. 支持客户端语言多
php、java、python
5. 数据持久化
所有的数据都运行在内存中
支持2种格式持久化数据AOF RDB AOF&RDB
6. 自带多种高可用架构
主从(在主上写任何数据,从服务器都会同步数据)
哨兵(监控主服务器,如果主服务器死掉,从服务器变为主服务器)
集群(将主从和哨兵融合,形成6个节点三对主从关系,注意永远是三主三从的结构)
集群功能实现,将访问效率低的一张大表拆成分片分散在每个集群中,从而提高访问效率)
三、redis应用场景
主要负责”热数据“的处理
1. 缓存-键过期时间
把session会话存在redis,过期删除
缓存用户信息,缓存Mysql部分数据,用户先访问redis,redis没有再访问mysql
商城优惠卷过期时间
2. 排行榜-列表&有序集合
热度/点击数排行榜
直播间礼物积分排行
3. 计数器-天然支持计数器
帖子浏览数
视频播放数
评论数
点赞/踩
4. 社交网络-集合
粉丝
共同好友
兴趣爱好
标签
5. 消息队列-发布订阅
配合ELK缓存收集来的日志
安装redis
1. 准备安装和数据目录
[root@redis1 ~]# mkdir -p /opt/redis_cluster/redis_6379/{conf,logs,pid}
[root@redis1 ~]# mkdir -p /data/soft2.下载redis安装包
[root@redis1 ~]# cd /data/soft
[root@redis1 ~]# wget http://download.redis.io/releases/redis-5.0.7.tar.gz3. 解压redis到/opt/redis_cluster/
[root@redis1 soft]# tar zxf redis-5.0.7.tar.gz -C /opt/redis_cluster/
[root@redis1 soft]# ln -s /opt/redis_cluster/redis-5.0.7/ /opt/redis_cluster/redis4. 切换目录安装redis
[root@redis1 soft]# cd /opt/redis_cluster/redis
[root@redis1 redis]# make && make install5.编写配置文件
[root@redis1 redis]# cd /opt/redis_cluster/redis_6379/conf/
[root@redis1 conf]# vim 6379.conf
bind 127.0.0.1 192.168.1.4
port 6379
daemonize yes
pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid
logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log
databases 16
dbfilename redis.rdb
dir /opt/redis_cluster/redis_6379注释:
databases 16 默认创建16个子数据库
dbfilename 表示持久化保存在硬盘的文件名
6. 启动当前redis服务
[root@redis1 conf]# redis-server 6379.conf关闭redis服务
redis-cli shutdown7. 登录redis
[root@redis1 conf]# redis-cli
redis基本命令
1. 全局命令
KEYS * #列出所有键值名,但在企业环境禁止使用
DBSIZE #查看有多少键值数
EXISTS #查看键值是否存在
EXPIRE k2 20 #设置K2过期时间为20秒,20秒后k2自动取消
PERSIST k2 #取消k2的过期时间
TTL k2 #查看k2的生命周期
TYPE #查看数据类型
2. 字符串类型:string
SET k3 3 #创建键值
GET k3 #查看键值
DEL k2 #删除键值
INCR k3 #键值k3为整数,递增加1
INCRBY k3 10 #递增k3的量值10
MSET k4 v4 k5 v5 k6 v6 k7 v7 #批量创建键值
MGET k4 k5 k6 k7 #批量查看键值
3. 列表:list
RPUSH list1 1 2 3 4 #创建列表list1,值为1 2 3 4
RPUSH list1 5 6 7 8 #在list1右侧添加5 6 7 8
LPUSH list1 0 #在list1左侧添加0
LRANGE list1 0 -1 #查看list1所有值
RPOP list1 #删除右侧最后一个值
LPOP list1 #删除左侧第一个值
LTRIM list1 0 2 #仅保留前3位,其他值删除
4. 哈希:hash
HMSET user:1000 username zhangsan age 17 job it #创建hash键值user:1000
HGET user:1000 username #查看键值中username参数
HGET user:1000 age #查看键值中age参数
HGET user:1000 job #查看键值中job参数
HMSET user:1000 tel 18866668888 #添加值tel
5. 集合:set
SADD set1 1 2 3 #创建集合set1
SMEMBERS set1 #查看集合set1
SADD set1 1 4 #为集合set1添加值1 4 ,但集合特性是去除重复,所以1无法再添加
SREM set1 1 4 #删除集合的值1 4
sadd set2 1 4 5 #创建第二个集合set2
SDIFF set1 set2 #求差集
SINTER set1 set2 #求合集(交集)
SUNION set1 set2 #求并集
redis持久化
1. 当redis重启时,之前的键值将不复存在,这种情况是不行的。此时需要配置持久化功能,当redis重启后,之前的键值还会存在。
RDB:生成时间点快照,保存于硬盘
优点:速度快,适合做备份,能做主从复制,单开子进程进行rdb操作不影响主业务。
缺点:会有部分数据丢失。
AOF:记录所有写操作命令,通过再次执行这些命令还原数据。
优点:最大程度保证数据不丢失。
缺点:日志记录量太大。
2. RDB配置
[root@redis1 ~]# redis-cli //登录redis
127.0.0.1:6379> bgsave //rdb保存命令
Background saving started
127.0.0.1:6379> exit //退出
[root@redis1 ~]# vim /opt/redis_cluster/redis_6379/conf/6379.conf
//添加三行内容
save 900 1 //在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照
save 300 10 //在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照
save 60 10000 //在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照3. AOF配置
[root@redis1 ~]# vim /opt/redis_cluster/redis_6379/conf/6379.conf
//添加三行内容
appendonly yes //启用AOF持久化
appendfilename "redis.aof" //指定AOF文件名
appendfsync everysec //每秒同步一次4. 重启redis
[root@redis1 ~]# redis-cli shutdown
[root@redis1 ~]# redis-server /opt/redis_cluster/redis_6379/conf/6379.conf此时可以使用redis基本命令来测试创建一些键值,重启后查看键值应还存在。
redis主从复制
1. 环境如下:主redis1,从redis2。
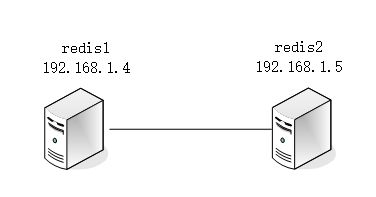
为解决单点故障把数据复制到一个或多个副本副本服务器(从服务器),实现故障恢复和负载均衡。
2. 开启第二台服务器,安装redis
(1)经过上面的安装,此时需要开启第二台虚拟机,把第一台服务器的redis安装目录,scp到第二台服务器上。
[root@redis1 ~]# scp -rp /opt/redis_cluster/ [email protected]:/opt(2)在第二台服务器上,make install安装redis
[root@redis2 ~]# cd /opt/redis_cluster/redis
[root@redis2 redis]# make install
[root@redis2 redis]# vim /opt/redis_cluster/redis_6379/conf/6379.conf
//编辑下面两行内容,绑定IP为本机地址(第二台),指定主为第一台(192.168.1.4)
bind 127.0.0.1 192.168.1.5
slaveof 192.168.1.4 6379(3)启动服务
[root@redis2 redis]# redis-server /opt/redis_cluster/redis_6379/conf/6379.conf(4)主服务器上新建键值,测试从服务器自动同步
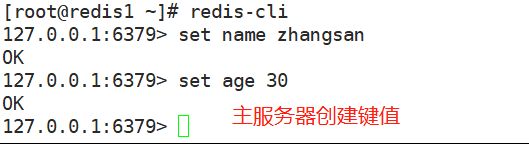

(5)从服务器在同步过程中,只能复制主数据库的数据,不能手动添加修改数据;如果从服务器非要修改数据,需要断开同步(注意:需要在从服务器上断开)。
[root@redis2 ~]# redis-cli slaveof no oneredis集群
Redis Cluster 是 redis的分布式解决方案,在3.0版本正式推出。
当遇到单机、内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡目的。
Redis Cluster之前的分布式方案有两种:
1)客户端分区方案: 优点分区逻辑可控,缺点是需要自己处理数据路由,高可用和故障转移等。
2)代理方案: 优点是简化客户端分布式逻辑和升级维护便利,缺点加重架构部署和性能消耗。
官方提供的 Redis Cluster集群方案,很好的解决了集群方面的问题。
1. 数据分布
分布式数据库首先要解决把整个数据库集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,
每个节点负责整体数据的一个子集,需要关注的是数据分片规则,Redis Cluster采用哈希分片规则。
2. 目录规划
# redis安装目录
/opt/redis_cluster/redis_{PORT}/{conf,logs,pid}
# redis数据目录
/data/redis_cluster/redis_{PORT}/redis_{PORT}.rdb
3. 集群拓扑图
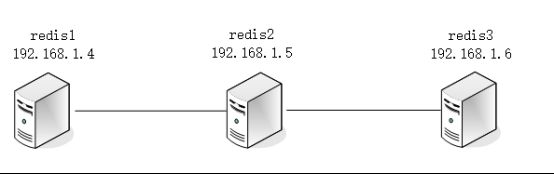
4. 手动搭建部署集群
思路:
先部署一台服务器上的2个集群节点,把文件发送到其他主机修改IP地址,启动服务。下面将从新创建两个端口。
群集实施
1. redis1部署
[root@redis1 ~]# mkdir -p /opt/redis_cluster/redis_{6380,6381}/{conf,logs,pid}
[root@redis1 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}安装redis具体步骤参考→安装redis
[root@redis1 ~]# vim /opt/redis_cluster/redis_6380/conf/redis_6380.conf
bind 192.168.1.4
port 6380
daemonize yes
pidfile "/opt/redis_cluster/redis_6380/pid/redis_6380.pid"
logfile "/opt/redis_cluster/redis_6380/logs/redis_6380.log"
dbfilename "redis_6380.rdb"
dir "/data/redis_cluster/redis_6380/"
cluster-enabled yes
cluster-config-file nodes_6380.conf
cluster-node-timeout 15000
[root@redis1 ~]# cd /opt/redis_cluster/
[root@redis1 redis_cluster]# cp redis_6380/conf/redis_6380.conf redis_6381/conf/redis_6381.conf
[root@redis1 redis_cluster]# sed -i 's/6380/6381/g' redis_6381/conf/redis_6381.conf
[root@redis1 redis_cluster]# redis-server /opt/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis1 redis_cluster]# redis-server /opt/redis_cluster/redis_6381/conf/redis_6381.conf2. 复制redis1的安装和数据目录到redis2、redis3
[root@redis1 ~]# scp -rp /opt/redis_cluster/ [email protected]:/opt
[root@redis1 ~]# scp -rp /opt/redis_cluster/ [email protected]:/opt3. redis2操作:
[root@redis2 ~]# cd /opt/redis_cluster/redis
[root@redis2 redis]# make install
[root@redis2 ~]# find /opt/redis_cluster/redis_638* -type f -name "*.conf" | xargs sed -i 's/192.168.1.4/192.168.1.5/g'
[root@redis2 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}
[root@redis2 ~]# redis-server /opt/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis2 ~]# redis-server /opt/redis_cluster/redis_6381/conf/redis_6381.conf4.redis3操作
[root@redis3 ~]# cd /opt/redis_cluster/redis
[root@redis3 redis]# make install
[root@redis3 redis]# find /opt/redis_cluster/redis_638* -type f -name "*.conf" | xargs sed -i 's/192.168.1.4/192.168.1.6/g'
[root@redis3 redis]# mkdir -p /data/redis_cluster/redis_{6380,6381}
[root@redis3 redis]# redis-server /opt/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis3 redis]# redis-server /opt/redis_cluster/redis_6381/conf/redis_6381.conf群集搭建完成后,需要加主机及端口号进行登录。
格式如下:redis-cli -h {群集IP} -p {端口号}

配置节点发现
当把所有节点都启动后查看进程会有cluster的字样。
但是登录后执行CLUSTER NODES命令会发现只有每个节点自己的ID,目前集群内的节点。
还没有互相发现,所以搭建redis集群我们第一步要做的就是让集群内的节点互相发现。
在执行节点发现命令之前我们先查看一下集群的数据目录会发现有生成集群的配置文件。
查看后发现只有自己的节点内容,等节点全部发现后会把所发现的节点ID写入这个文件。
集群模式的Redis除了原有的配置文件之外又加了一份集群配置文件。当集群内节点信息发生变化,如添加节点、节点下线、故障转移等,节点会自动保存集群状态到配置文件。需要注意的是,Redis自动维护集群配置文件,不需要手动修改,防止节点重启时产生错乱。
节点发现使用命令: CLUSTER MEET {IP} {PORT}
注意:在集群内任意一台机器执行此命令就可以
[root@redis1 ~]# redis-cli -h 192.168.1.4 -p 6380
192.168.1.4:6380> cluster meet 192.168.1.5 6380
OK
192.168.1.4:6380> cluster meet 192.168.1.6 6380
OK
192.168.1.4:6380> cluster meet 192.168.1.4 6381
OK
192.168.1.4:6380> cluster meet 192.168.1.5 6381
OK
192.168.1.4:6380> cluster meet 192.168.1.6 6381
OK
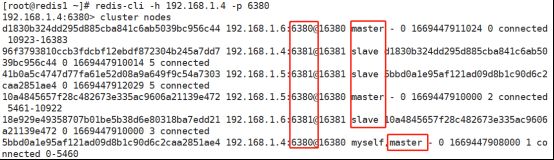
192.168.1.4:6380> cluster nodes
d1830b324dd295d885cba841c6ab5039bc956c44 192.168.1.6:6380@16380 master - 0 1669446325000 0 connected
96f3793810ccb3fdcbf12ebdf872304b245a7dd7 192.168.1.4:6381@16381 master - 0 1669446326273 4 connected
41b0a5c4747d77fa61e52d08a9a649f9c54a7303 192.168.1.5:6381@16381 master - 0 1669446325000 5 connected
10a4845657f28c482673e335ac9606a21139e472 192.168.1.5:6380@16380 master - 0 1669446323000 2 connected
18e929e49358707b01be5b38d6e80318ba7edd21 192.168.1.6:6381@16381 master - 0 1669446325266 3 connected
5bbd0a1e95af121ad09d8b1c90d6c2caa2851ae4 192.168.1.4:6380@16380 myself,master - 0 1669446325000 1 connected节点都发现完毕后我们再次查看集群配置文件,可以看到发现到的节点的ID也被写入到了集群的配置文件里。此时每个服务器的状态都是master,下面将指定主从关系。
Redis Cluster 通讯流程
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障灯状态信息,redis 集群采用 Gossip(流言)协议,Gossip 协议工作原理就是节点彼此不断交换信息,一段时间后所有的节点都会知道集群完整信息,这种方式类似流言传播。
1. 通信过程
1)集群中的每一个节点都会单独开辟一个 Tcp 通道,用于节点之间彼此通信,防火墙放行(端口号+10000).
2)每个节点在固定周期内通过特定规则选择结构节点发送 ping 消息
3)接收到 ping 消息的节点用 pong 消息作为响应。集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,
只要这些节点彼此可以正常通信,最终他们会打成一致的状态,当节点出现故障,新节点加入,主从角色变化等,它能够给不断的ping/pong消息,从而达到同步目的。
2. 通讯消息类型
Gossip
Gossip 协议职责就是信息交换,信息交换的载体就是节点间彼此发送Gossip 消息。
常见 Gossip 消息分为:ping、 pong、 meet、 fail 等
meet
meet 消息:用于通知新节点加入,消息发送者通知接受者加入到当前集群,meet 消息通信正常完成后,接收节点会加入到集群中并进行ping、 pong 消息交换
ping
ping 消息:集群内交换最频繁的消息,集群内每个节点每秒想多个其他节点发送 ping 消息,用于检测节点是否在线和交换彼此信息。
pong
Pong 消息:当接收到 ping,meet 消息时,作为相应消息回复给发送方确认消息正常通信,节点也可以向集群内广播自身的 pong 消息来通知整个集群对自身状态进行更新。
fail
fail 消息:当节点判定集群内另一个节点下线时,回向集群内广播一个fail 消息,其他节点收到 fail 消息之后把对应节点更新为下线状态。
Redis Cluster手动分配槽位
虽然节点之间已经互相发现了,但是此时集群还是不可用的状态,因为并没有给节点分配槽位,而且必须是所有的槽位都分配完毕后整个集群才是可用的状态。反之,也就是说只要有一个槽位没有分配,那么整个集群就是不可用的。
测试命令如下:
[root@redis1 ~]# redis-cli -h 192.168.1.4 -p 6380
192.168.1.4:6380> set k1 v1
(error) CLUSTERDOWN Hash slot not served //此刻报错为正常
192.168.1.4:6380> cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_ping_sent:316
cluster_stats_messages_pong_sent:321
cluster_stats_messages_meet_sent:6
cluster_stats_messages_sent:643
cluster_stats_messages_ping_received:320
cluster_stats_messages_pong_received:322
cluster_stats_messages_meet_received:1
cluster_stats_messages_received:643前面说了,我们虽然有6个节点,但是真正负责数据写入的只有3个节点,其他3个节点只是作为主节点的从节点,也就是说,只需要分配其中三个主节点的槽位就可以了。
1. 分配槽位的方法:
分配槽位需要在每个主节点上来配置,此时有2种方法执行:
分别登录到每个主节点的客户端来执行命令。
在其中一台机器上用redis客户端远程登录到其他机器的主节点上执行命令。
每个节点执行命令:
[root@redis1 ~]# redis-cli -h 192.168.1.4 -p 6380 cluster addslots {0..5460}
OK
[root@redis1 ~]# redis-cli -h 192.168.1.5 -p 6380 cluster addslots {5461..10922}
OK
[root@redis1 ~]# redis-cli -h 192.168.1.6 -p 6380 cluster addslots {10923..16383}
OK分配完所有槽位之后我们再查看一下集群的节点状态和集群状态,可以看到三个节点都分配了槽位,而且集群的状态是OK的。
[root@redis1 ~]# redis-cli -h 192.168.1.4 -p 6380
192.168.1.4:6380> cluster info
cluster_state:ok
//省略部分内容2. 手动配置集群高可用
虽然这时候集群是可用的了,但是整个集群只要有一台机器坏掉了,那么整个集群都是不可用的。
所以这时候需要用到其他三个节点分别作为现在三个主节点的从节点,以应对集群主节点故障时可以进行自动切换以保证集群持续可用。
注意:
(1)不要让复制节点复制本机器的主节点,因为如果那样的话机器挂了集群还是不可用状态, 所以复制节点要复制其他服务器的主节点。
(2)使用redis-trid工具自动分配的时候会出现复制节点和主节点在同一台机器上的情况,需要注意。
3. 高可用配置命令
这一次我们采用在一台机器上使用redis客户端远程操作集群其他节点。
注意:
(1)需要执行命令的是每个服务器的从节点。
(2)注意主从的ID不要搞混了。
拓扑图如下:
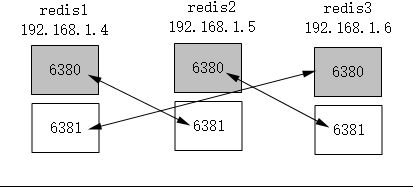
[root@redis1 ~]# redis-cli -h 192.168.1.4 -p 6381 cluster replicate d1830b324dd295d885cba841c6ab5039bc956c44 //第三台6380的id
OK
[root@redis1 ~]# redis-cli -h 192.168.1.5 -p 6381 cluster replicate 5bbd0a1e95af121ad09d8b1c90d6c2caa2851ae4 //第一台6380的id
OK
[root@redis1 ~]# redis-cli -h 192.168.1.6 -p 6381 cluster replicate 10a4845657f28c482673e335ac9606a21139e472 //第二台6380的id
OK下图中可以看到,6380全都是master,6381全都是slave,此刻主从关系就指定成功了。关于手动指定主从关系需要理解之间的关系,后面还会将学习自动指定关系,但之间的原理还是要了解的。
4. Redis Cluster测试集群
我们使用常规插入redis数据的方式往集群里写入数据,看看会发生什么?
[root@redis1 ~]# redis-cli -h 192.168.1.4 -p 6380 set k1 v1
(error) MOVED 12706 192.168.1.6:6380结果提示error, 但是给出了集群另一个节点的地址,那么这条数据到底有没有写入呢? 我们登录这两个节点分别查看。
[root@redis1 ~]# redis-cli -h 192.168.1.6 -p 6380 get k1
(nil)结果没有,这是因为使用集群后由于数据被分片了,所以并不是说在那台机器上写入数据就会在哪台机器的节点上写入,集群的数据写入和读取就涉及到了另外一个概念,ASK路由。
Redis Cluster ASK路由介绍
在集群模式下,Redis接受任何键相关命令时首先会计算键对应的槽,再根据槽找出所对应的节点。
如果节点是自身,则处理键命令;否则回复MOVED重定向错误,通知客户端请求正确的节点,这个过程称为Mover重定向。
知道了ask路由后,我们使用-c选项批量插入一些数据。
正确访问命令

创建一万个键值对测试。
[root@redis1 ~]# mkdir /sh
[root@redis1 ~]# vim /sh/input.key.sh
#!/bin/bash
for i in $(seq 1 10000)
do
redis-cli -c -h 192.168.1.4 -p 6380 set k_${i} v_${i} && echo "set k_${i} is ok"
done
[root@redis1 ~]# sh /sh/input.key.sh写入后执行脚本等待创建键值对,我们同样使用-c选项来读取刚才插入的键值,然后查看下redis会不会帮我们路由到正确的节点上。
[root@redis1 ~]# redis-cli -c -h 192.168.1.4 -p 6380
192.168.1.4:6380> get k_1
"v_1"
192.168.1.4:6380> get k_100
-> Redirected to slot [5541] located at 192.168.1.5:6380
"v_100"
192.168.1.5:6380> get k_1000
-> Redirected to slot [79] located at 192.168.1.4:6380
"v_1000"模拟故障转移
至此,我们已经手动的把一个redis高可用的集群部署完毕了,但是还没有模拟过故障
这里我们就模拟故障,停掉期中一台主机的redis节点,然后查看一下集群的变化。
我们使用暴力的kill -9(真实环境禁止使用,建议使用kill或pkill)杀掉 redis3上的redis集群节点,然后观察节点状态。
理想情况应该是redis1上的6381从节点升级为主节点,在redis1上查看集群节点状,虽然我们已经测试了故障切换的功能,但是节点修复后还是需要重新上线,所以这里测试节点重新上线后的操作。
重新启动redis3的6380,然后观察日志。
观察redis1上的日志。
这时假如我们想让修复后的节点重新上线,可以在想变成主库的从库执行CLUSTER FAILOVER命令。
这里我们在redis3的6380上执行
操作命令:
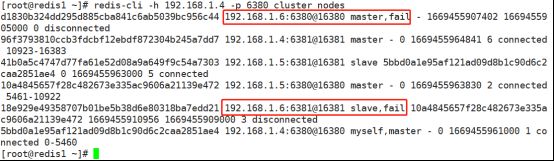
模拟redis3故障:(关掉redis3的服务)
[root@redis1 ~]# redis-cli -h 192.168.1.6 -p 6380 shutdown
[root@redis1 ~]# redis-cli -h 192.168.1.6 -p 6381 shutdown查看群集节点状态:
查看redis3的服务器状态全都是fail(失败)。
再启动redis3的服务:
[root@redis3 ~]# redis-server /opt/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis3 ~]# redis-server /opt/redis_cluster/redis_6381/conf/redis_6381.conf虽然启动了redis3的服务,但是状态始终是slave,需要指定6380重新回到master。

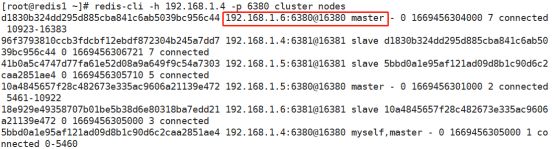
重回master:
[root@redis1 ~]# redis-cli -h 192.168.1.6 -p 6380 CLUSTER FAILOVER
OK执行命令后可以看到redis3的6380重新回到了master状态。
自动搭建部署Redis Cluster
手动搭建集群便于理解集群创建的流程和细节,不过手动搭建集群需要很多步骤,当集群节点众多时,必然会加大搭建集群的复杂度和运维成本,因此官方提供了 redis-trib.rb的工具方便我们快速搭建集群。redis-trib.rb是采用 Ruby 实现的 redis 集群管理工具,内部通过 Cluster相关命令帮我们简化集群创建、检查、槽迁移和均衡等常见运维操作,使用前要安装 ruby 依赖环境。
前提准备:
停掉所有的节点,然后清空数据,恢复成一个全新的集群,所有机器执行命令
前提条件需要根据上面的配置全部清空数据,恢复全新的群集状态,三台服务器都需要执行下面命令。这里以redis1为例,清空全部数据并启动。
[root@redis1 ~]# rm -rf /data/redis_cluster/redis_6380/*
[root@redis1 ~]# rm -rf /data/redis_cluster/redis_6381/*
[root@redis1 ~]# redis-server /opt/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis1 ~]# redis-server /opt/redis_cluster/redis_6381/conf/redis_6381.conf执行后查看群集,每个服务器端口都应成为下面的状态。下面将进行自动分配槽位及主从关系。
![]()
1. 安装命令:老版本需要安装,注意:新版本redis不需安装,直接采用步骤2。
yum makecache fast
yum install rubygems
gem sources --remove https://rubygems.org/
gem sources -a http://mirrors.aliyun.com/rubygems/
gem update –system
gem install redis -v 3.3.5
redis1执行创建集群命令
cd /opt/redis_cluster/redis/src/
./redis-trib.rb create --replicas 1 192.168.1.4:6380 192.168.1.5:6380 192.168.1.6:6380 192.168.1.4:6381 192.168.1.5:6381 192.168.1.6:6381
检查集群完整性
./redis-trib.rb check 192.168.1.4:6380
2. 直接使用redis-cli命令
创建群集:前面写主后面写从
[root@redis1 ~]# redis-cli --cluster create --cluster-replicas 1 192.168.1.4:6380 192.168.1.5:6380 192.168.1.6:6380 192.168.1.4:6381 192.168.1.5:6381 192.168.1.6:6381确定自动分配的槽位及master和slave输入"yes"。
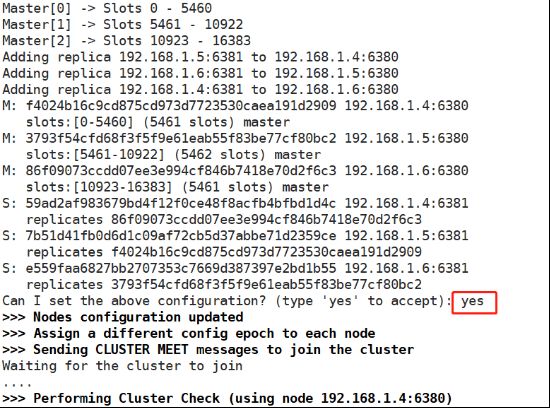
检查完整性:
[root@redis1 ~]# redis-cli --cluster check 192.168.1.4:6380工具扩容节点
Redis集群的扩容操作可分为以下几个步骤:
①准备新节点
②加入集群
③迁移槽和数据
1. 我们在redis1上创建2个新节点,分别为6390、6391。
[root@redis1 ~]# mkdir -p /opt/redis_cluster/redis_{6390,6391}/{conf,logs,pid}
6391.conf
[root@redis1 ~]# mkdir -p /data/redis_cluster/redis_{6390,6391}
[root@redis1 ~]# cd /opt/redis_cluster/
[root@redis1 redis_cluster]# cp redis_6380/conf/redis_6380.conf redis_6390/conf/redis_6390.conf
[root@redis1 redis_cluster]# cp redis_6380/conf/redis_6380.conf redis_6391/conf/redis_6391.conf
[root@redis1 redis_cluster]# sed -i 's#6380#6390#g' redis_6390/conf/redis_6390.conf
[root@redis1 redis_cluster]# sed -i 's#6380#6391#g' redis_6391/conf/redis_6391.conf2. 启动节点
[root@redis1 redis_cluster]# redis-server /opt/redis_cluster/redis_6390/conf/redis_6390.conf
[root@redis1 redis_cluster]# redis-server /opt/redis_cluster/redis_6391/conf/redis_6391.conf3. 发现节点
[root@redis1 redis_cluster]# redis-cli -c -h 192.168.1.4 -p 6380 cluster meet 192.168.1.4 6390
OK
[root@redis1 redis_cluster]# redis-cli -c -h 192.168.1.4 -p 6380 cluster meet 192.168.1.4 6391
OK4. 分配slots
[root@redis1 redis_cluster]# redis-cli --cluster reshard 192.168.1.4:6390①输入分配的slots数:4096
②再输入6390的id号
③再输入all
④最后输入yes
配置6391 slave 6390:
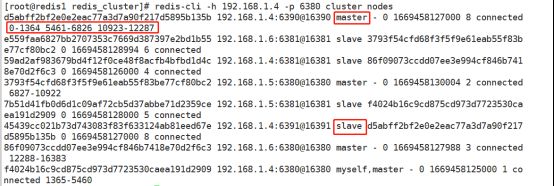
[root@redis1 redis_cluster]# redis-cli -h 192.168.1.4 -p 6391 cluster replicate d5abff2bf2e0e2eac77a3d7a90f217d5895b135b (输入6390的id)
OK通过命令查看,6390成为了master、6391成为了slave,而槽位分别从三个区域拿了一部分。
工具收缩节点
首先需要确定下线节点是否有负责的槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性。
当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭。
这里我们准备将刚才新添加的节点下线,也就是6390和6391。
收缩和扩容迁移的方向相反,6390变为源节点,其他节点变为目标节点,源节点把自己负责的4096个槽均匀的迁移到其他节点上。
下面请根据版本来选择收缩方法,我这里使用的新版本将直接使用第二个方法。
1. 旧版本
由于redis-trib..rb reshard命令只能有一个目标节点,因此需要执行3次reshard命令,分别迁移1365、1365、1366个槽。
操作命令:
cd /opt/redis_cluster/redis/src/
./redis-trib.rb reshard 192.168.1.4:6380
How many slots do you want to move (from 1 to 16384)? 1365
输入6380的id
输入6390的id
done
忘记节点
由于我们的集群是做了高可用的,所以当主节点下线的时候从节点也会顶上,所以最好我们先下线从节点,然后在下线主节点
cd /opt/redis_cluster/redis/src/
./redis-trib.rb del-node 192.168.1.4:6391 ID
./redis-trib.rb del-node 192.168.1.4:6390 ID
2. 新版本
移除下线节点的槽位:
[root@redis1 ~]# redis-cli --cluster reshard 192.168.1.4:6390案例中分三次移除:分别
1365(槽位) 给redis1的6380(输入id)
1366(槽位) 给redis2的6380(输入id)
1365(槽位) 给redis3的6380(输入id)

移除后遗忘下线节点:
[root@redis1 ~]# redis-cli -c -h 192.168.1.4 -p 6380 cluster forget d5abff2bf2e0e2eac77a3d7a90f217d5895b135b //(6390的ID)
OK
[root@redis1 ~]# redis-cli -c -h 192.168.1.4 -p 6380 cluster forget 45439cc021b73d743083f83f633124ab81eed67e //(6391的ID)
OK总结:经过节点扩容与收缩功能后,了解了如何给新增节点增加槽位,以及把指定的主机槽位给其他主机。
Redis常用命令(扩展内容)
集群(cluster)
CLUSTER INFO 打印集群的信息
CLUSTER NODES 列出集群当前已知的所有节点(node),以及这些节点的相关信息。
节点(node)
CLUSTER MEET
将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。 CLUSTER FORGET
从集群中移除 node_id 指定的节点。 CLUSTER REPLICATE
将当前节点设置为 node_id 指定的节点的从节点。 CLUSTER SAVECONFIG 将节点的配置文件保存到硬盘里面。
槽(slot)
CLUSTER ADDSLOTS
[slot ...] 将一个或多个槽(slot)指派(assign)给当前节点。 CLUSTER DELSLOTS
[slot ...] 移除一个或多个槽对当前节点的指派。 CLUSTER FLUSHSLOTS 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
CLUSTER SETSLOT
NODE 将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。 CLUSTER SETSLOT
MIGRATING 将本节点的槽 slot 迁移到 node_id 指定的节点中。 CLUSTER SETSLOT
IMPORTING 从 node_id 指定的节点中导入槽 slot 到本节点。 CLUSTER SETSLOT
STABLE 取消对槽 slot 的导入(import)或者迁移(migrate)。 键 (key)
CLUSTER KEYSLOT
计算键 key 应该被放置在哪个槽上。 CLUSTER COUNTKEYSINSLOT
返回槽 slot 目前包含的键值对数量。CLUSTER GETKEYSINSLOT 返回 count 个 slot 槽中的键。