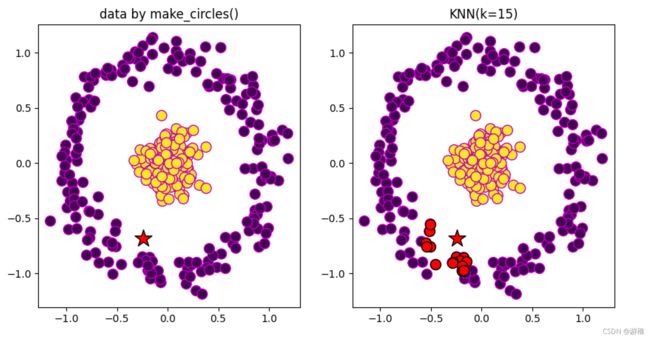
Sklearn中的make_circles方法生成训练样本,并随机生成测试样本,用KNN分类并可视化。
关于make_circles方法可查看:
Python 生成数据 make_circles 和 make_moons_游稚的博客-CSDN博客_make moon python
分析:使用KNN分类
①设定K值,代表需要得出距离测试样本最近的K个训练样本。
②生成训练样本和测试样本,并做区分性的散点图。(可视化)
③计算测试样本到所有训练样本的距离(采用欧式距离),并对距离进行排序,取前K个。
④使这K个训练样本的可视化与测试样本相同,达到分辨的效果。
⑤选取这K个样本中数量最多的标志作为该训练样本的标志。
代码:
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
#Sklearn中的make_circles方法生成训练样本
X_circle, Y_circle = make_circles(n_samples=400, noise=0.1, factor=0.1)
#随机生成测试样本
n=np.random.randint(0,10,size=1)
ran=random.random()
x=pow(-1,n)*ran
n=np.random.randint(0,10,size=1)
ran=random.random()
y=pow(-1,n)*ran
print(x,y)
#第一幅图
plt.subplot(1,2,1)
plt.scatter(X_circle[:, 0], X_circle[:, 1], s=100, marker="o", edgecolors='m', c=Y_circle)
# c=Y_circle划分两种标签数据的颜色
plt.title('data by make_circles()')
plt.scatter(x,y, s=300, marker="*", edgecolors='black', c='red')
#第二幅图
plt.subplot(1,2,2)
plt.scatter(X_circle[:, 0], X_circle[:, 1], s=100, marker="o", edgecolors='m', c=Y_circle)
plt.scatter(x,y, s=300, marker="*", edgecolors='black', c='red')
plt.title('KNN(k=15)')
#转化为DataFrame格式
data={'x坐标':X_circle[:,0],'y坐标':X_circle[:,1],}
olddata=pd.DataFrame(data,dtype='double')
#计算欧式距离,距离排序
new_x_y=[float(x),float(y)]
distance=(((olddata-new_x_y)**2).sum(1))**0.5#得到((x1-x2)^2+(y1-y2)^2)^0.5
#print(distance)
disdata=pd.DataFrame({'x坐标':X_circle[:,0],'y坐标':X_circle[:,1],'距离':distance},dtype='double').sort_values(by='距离')
#print((disdata))
#距离最短前k个
k=15
plt.scatter(disdata.iloc[:k,0],disdata.iloc[:k,1], s=100, marker="o",edgecolors='black', c='red')
plt.show()
效果图: