机器学习工具篇_sklearn_随机森林
1.集成算法概述
Q:随机森林
是一种集成算法
不是一种单独的机器 学习算法
Q:集成算法的目标
考虑多个评估器的建模结果,汇总之后 得到一个综合的结果,以此来获得更好的回归或者分类表现
Q:集成评估器
一个模型是一个评估器
多个模型成为集成评估器(ensemble estimator)
每个模型,或者叫单个评估器,都叫做基评估器(base estimator)
常用三类:装袋法(Bagging),提升法(Boosting)和stacking(?也许是堆栈法?)
Q:装袋法(Bagging)和提升法(Boosting)的区别
装袋法(Bagging)的每个模型相互独立.通过平均或者多数表决来决定评估器的结果.
代表是随机森林
提升法(Boosting)中的每个模型是相关的,并且是一一建立的。核心思想是,利用多个弱评估器的力量,一次次对难以评估的样本进行预测,最终形成一个强评估器.
代表是Adaboost和梯度提升树

2.重要参数
Q:n_estimators
表示树木的数量,也就是评估器的数量
评估器的数量越大,也就随机森林的模型效果也就越好.
但会到达一个边界后,就是波动不会再增加
并且,评估器的数量越大,占用的内存资源越多.
Q:决策树和随机森林的效果
随机森林的效果,远远好于决策树
随机森林属于袋装集成算法(bagging),对基评估器的预测结果取平均值 或者多数表决原则


import numpy as np
from scipy.special import comb #comb指的是数学中的组合
np.array([comb(25,i)*(0.2**i)*((1-0.2)**(25-i)) for i in range(13,26)]).sum()
#这个是用到了幂指数的算法**,
#用到了数组,对数组里面的元素相加时,用上sum
#熟悉这个循环的写法结果:0.00036904803455582827
说明,假定单个错误的概率是0.2的情况下,错误的概率很小
Q:随机森林中的重要属性:.estimator_
rfc=RandomForestClassifier(n_estimators=25)
rfc=rfc.fit(Xtrain,Ytrain)
rfc.estimators_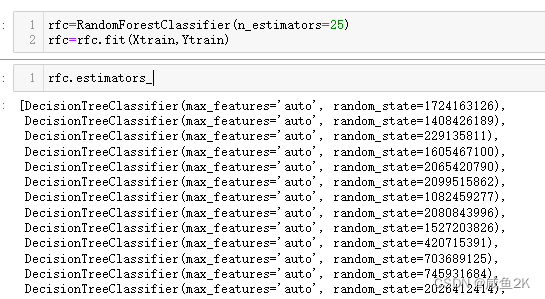
用estimator_属性,展示所有的基评估器

可以用序号,展示出第几个基评估器
可以用.random_state展示出具体的数值

Q:random_state在随机森林中的作用

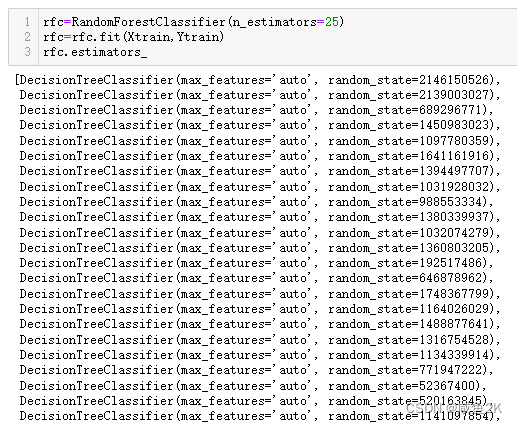
每运行一次都不同。而固定random_state的情况下,则每次都相同

Q:bootstrap的内涵
控制抽样技术的参数
默认为True,代表有放回的随机抽样技术



用的是一个倒推的方式,求出有放回的随机抽样,能够抽取到约63.2%的数据。
约36.8%的数据会被浪费掉,这些数据叫袋外数据。oob
Q:oob袋外数据的内涵
袋外数据,可以作为测试集。也就是说不用区分训练集和测试集,就可以训练模型,给模型打分。

rfc=RandomForestClassifier(n_estimators=25,oob_score=True)#袋外数据测试为真
rfc=rfc.fit(wine.data,wine.target)#使用袋外数据时,不用区分训练集或者测试集了#重要属性oob_score_,用这个属性来打分
rfc.oob_score_Out[39]:
0.9719101123595506
Q:接口的内涵?
接口可以理解为与模型的交互。
如fit,score,apply,predic,predic_proba都是重要的接口
feature_importance为属性,因为没有交互


predict_proba为概率,看起来更厉害
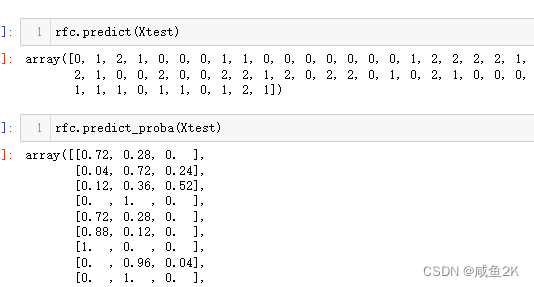
rfc.apply(Xtest)考虑zip函数


Q:使用随机森林时,样本的正确率保证?
至少50%
3.RandomForestRegressor随机森林回归
class sklearn.ensemble.RandomForestRegressor
(n_estimators=’warn’, criterion=’mse’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’,
max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False,
n_jobs=None, random_state=None, verbose=0, warm_start=False)
Q:criterion参数
默认为R2


根据公式,R2,最大为1,1是最好,负数越大,R2越大
Q:criterion参数的其他标准

mse为常用。mse为正数,但sklearn中用负数表示损失,所以为负数“neg_mean_squared_error”
Q:区别于RandomforestDecision的接口
共性:apply, fit, predict和score
差异:随机森林回归没有predict_proba接口
Q:sklearn的评估指标
当不记得用什么评估指标时,运行下列代码,默认是r2。
#sklearn当中的模型评估指标的列表
import sklearn
sorted(sklearn.metrics.SCORERS.keys())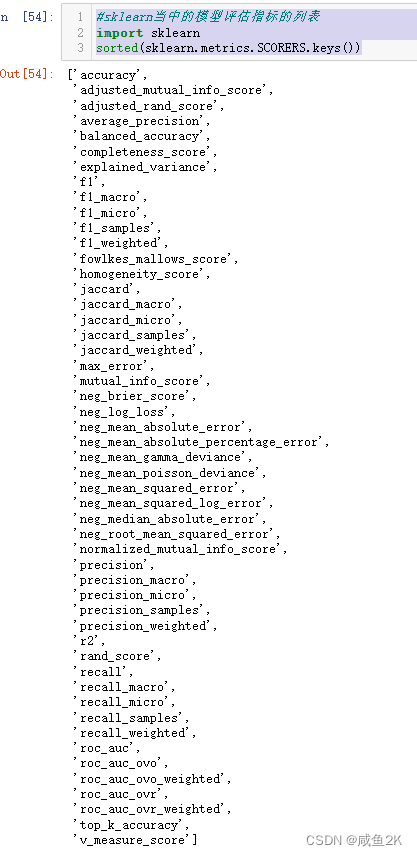
3.2实例:用随机森林回归填补缺失值
回归森林回归的一个重要应用。
sklearn.impute.SimpleImputer
5.使用随机森林填补缺失值
原理:
Q:如果是多个特征也有缺失值的情况

4.机器学习中的调参的基本思想
Step1:找目标
一般来说,目标是提升某个模型评估指标。
比如,对于随机森林,要提升的是模型在 未知数据上的准确率(由score或者obb_score来衡量)
进而,要思考:
模型在未知的数据上的准确率受到什么因素的影响。
在机器学习中,衡量模型在未知数据上的准确率的指标,叫泛化误差(Genelization error)

对于树模型来说,深度越深,枝叶越多,树越茂盛,模型就越复杂》》》》》》所以树模型是天生位于右上角的模型。
随机森林是树模型为基础,所以随机森林也是天生复杂高的模型。随机森林的调参,都向一个目标去:减少模型的复杂度,把模型往图像的左边移动,防止过拟合。
但也有天生处于图像左边的随机森林。具体问题得具体分析。
Q:关于泛化误差,需要记住的东西

只有一个目标:往泛化误差最低点移动
Q:随机森林参数的影响程度排序?
将对复杂程度影响大的参数挑选出来,研究单调性,然后专注调整那些能最大限度让复杂度降低的参数。——“单调性”
对于不单调的参数,或者反而让复杂度升高的参数,就视情况使用,或者退避。
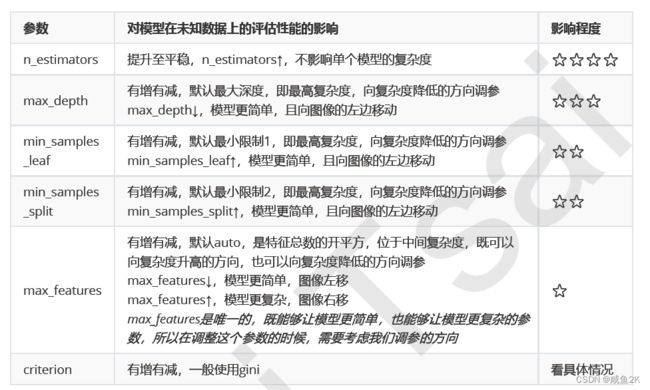
一些必要说明:
n_estimators是特殊参数,越大越好
max_depth相对另外两个枝叶更重要。
max_features一般默认就可以
critetion:使用时看情况,gini或者entrophy,只有这两个,都试试
5.实例:随机森林在乳腺癌数据上的调参