机器学习算法基础(二)
降维:把特征的数量减少
1、特征选择
2、主成分分析
1、特征选择
特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后可以改变值、也不改变值,但是选择后的特征维数肯定比选择前小,毕竟我们只选择了其中的一部分特征。
主要方法(三大武器):Filter(过滤式):VarianceThreshold
Embedded(嵌入式):正则化、决策树
Wrapper(包裹式)
主要讲Filter:variance threshold
方差过滤式
从方差大小的角度,考虑特征的所有样本,过滤掉相似的,冗余的特征。
特征选择,过滤式的API
sklearn.feature_selection.VarianceThreshold
def var():
"""
特征选择-删除低方差的特征
:return: None
"""
var = VarianceThreshold(threshold=1)
data = var.fit_transform([[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]])
print(data)
return None
if __name__=='__main__':
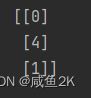
var()删除了低方差的特征,threshoud参数为0~9不等,并且没有一个理论上是最估值 ,需要看实际情况决定。
结果:留下了方差大的那些特征
其他的特征选择方法
神经网络
(后面具体介绍)
主成分分析
本质:PCA是一种分析、简化数据集的技术。
目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
作用:可以削减回归分析或者聚类分析中特征的数量
PCA:特征数量达到上百的时候,就需要考虑PCA去简化特征。
数量量会改变,特征也会减少。
主成分分析,要把维度降低,但反应事实不能减少。
高维度数据出现 的问题:特征容易出现相关。特征之间通常是线性相关的
PCA的目的,是找到一种方法,让数据信息得到最小的损失,并得到最大的特征反应。

n_components:是一个小数,保留在90%~95%之间会较好,经验。
语法:
PCA流程:1、初始化PCA,指定减少后的维度,2、调用fit_transform
def pca():
"""
主成分分析进行特征降维
:return: None
"""
pca = PCA(n_components=0.9)
data = pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])
print(data)
return None
if __name__=='__main__':
pca()
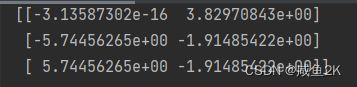
结果:只管相信最后的数值
案例:instacart:把用户分成几个类别
#1、导入相关库
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.metrics import silhouette_score
#2、读取CSV表
prior = pd.read_csv(r"F:\学习文件\拜师数据分析学习\3142_机器学习算法基础(基础机器学习课程)\Data explorer\order_products__prior.csv")
products = pd.read_csv(r"F:\学习文件\拜师数据分析学习\3142_机器学习算法基础(基础机器学习课程)\Data explorer\products.csv")
orders = pd.read_csv(r"F:\学习文件\拜师数据分析学习\3142_机器学习算法基础(基础机器学习课程)\Data explorer\orders.csv")
aisles = pd.read_csv(r"F:\学习文件\拜师数据分析学习\3142_机器学习算法基础(基础机器学习课程)\Data explorer\aisles.csv")
#3、合并四张表到一张表 (用户-物品类别)
_mg = pd.merge(prior, products, on=['product_id', 'product_id'])
_mg = pd.merge(_mg, orders, on=['order_id', 'order_id'])
mt = pd.merge(_mg, aisles, on=['aisle_id', 'aisle_id'])
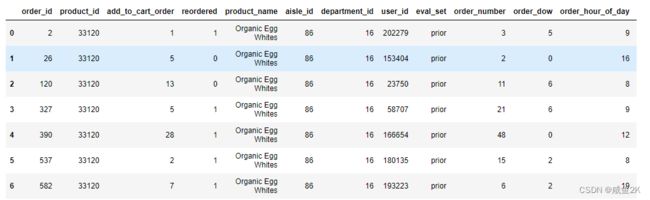
#查看前10个数据
mt.head(10)
# 4、进行交叉表处理。交叉表(特殊的分组工具)----交叉表就是普通的Excel中的表,具体用法:https://blog.csdn.net/fendouaini/article/details/109126352?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166502196716782414947877%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166502196716782414947877&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-109126352-null-null.142^v51^control_1,201^v3^control&utm_term=crosstab&spm=1018.2226.3001.4187
cross = pd.crosstab(mt['user_id'], mt['aisle'])
#查看前10个数据
mt.head(10)
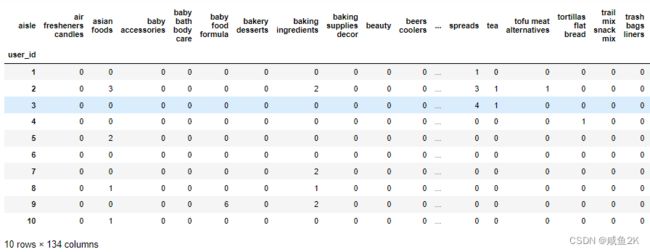
10*134,冗余数据太多
# 5、进行主成分分析
pca = PCA(n_components=0.9)
data = pca.fit_transform(cross)
data

data.shape
![]()
206209行,27列
比原来134列要少很多。
(二)机器学习基础
1、机器学习开发流程
2、机器学习模型是什么
3、机器学习算法分类
(1)算法是核心,数据和计算是基础
(2)找准定位
大部分复杂模型的算法设计都是算法工程师在做,而我们
•分析很多的数据
•分析具体的业务
应用常见的算法
•特征工程、调参数、优化
弄懂算法的应用条件,并会拿来使用就行。原理不一定需要搞懂。并学会利用库或者框架解决问题
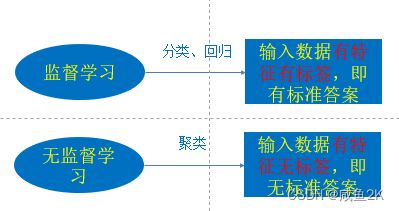
机器学习算法分类
随机森林、逻辑回归、神经网络
分类:目标值离散型
回归:目标值连续型
机器学习的开发流程

建立模型(算法+数据)根据数据类型划分应用种类
1.原始数据
明确问题要做什么
2.数据基本处理:
pd处理数据(缺失值、合并报表等)
3.特征工程
对数据特征进行处理(重要)
4.找到合适算法进行预测
分类/回归/聚类?
5.模型的评估,判定效果
没有合格,则换算法,换参数,再进行特征工程
6.上线使用,以API的形式提供