了解CV和RoboMaster视觉组(五)目标跟踪:基于深度学习的方法
文章目录
-
-
- 5.4.4.NN-Based
-
- 5.4.4.1.特征提取模块
- 5.4.4.2.候选区域生成
- 5.4.4.3.分类器/回归器(fine-tune)
- 5.4.4.4.端到端方法
-
5.4.4.NN-Based
这部分内容在我们前面介绍光流法的文章中已经看到了一些端倪,根据前面的知识我们应该可以轻松地得到一种基于CNN的跟踪器:输入前一帧图像和初始的位置还有当前帧图像,输出即为预测的bbox。当然,这只是CNN-based方法其中的一种。聪明的你应该可以分析得到,刚刚提到的pipeline代表了一种判别式的方法的端到端框架,我们利用深度网络提取深度特征生成滤波器(卷积核),然后再次利用深层的网络作为分类器和回归器对浅层网络滤得的特征进行判别并输出当前帧中的目标框。
一定要区分生成式模型和判别式模型的不同,如早期目标检测算法中常用的HOG/SIFT/ORB/LBP/SURF等就是先对模板/原图进行特征点提取和并根据特征点周围的特征制作特征描述子,随后在后续帧图像中再次运行相同的流程找到特征点及其对应的描述子随后对两帧之间的特征点根据描述子的相似程度进行匹配。因此生成模型的核心是特征提取+特征匹配,而判别模型则是对可能的候选目标进行分类或回归(打分)。在 5.5 中我们会以一种经典的特征点匹配算法为中心,详细介绍生成式模型和传统的目标检测以及其他拥有良好的尺度/亮度/旋转/平移不变性的特征。
在前面我们已经见识到网络强大的特征提取和表示以及对非线性映射的拟合能力,下面给出在目标跟踪中能用能用网络替代的模块(包括全网络的架构):
5.4.4.1.特征提取模块
传统跟踪算法中直接使用像素级特征的大有人在,也有使用HoG、HoColor这些稍稍高级一些的特征。他们的优点就是计算起来非常快,缺点也很明显:表达能力相对较差。而深度特征的表示能力在这几年来的飞跃式提升是大家有目共睹的,自然而然我们可以使用CNN对初始帧进行处理得到feature map。有改进者结合了深度特征和简单的梯度/颜色特征,加入一个置信度模块:对于简单的样本就直接利用速度最快的HOG等特征进行初步筛选,如果一看就是背景直接跳过即可;若出现置信度不高的情况,再进一步使用CNN进行提取。这也是很多级联方法的惯用trick,如经典的Haar人脸检测器就是利用这种方法避免让所有输入都通过整个流程。
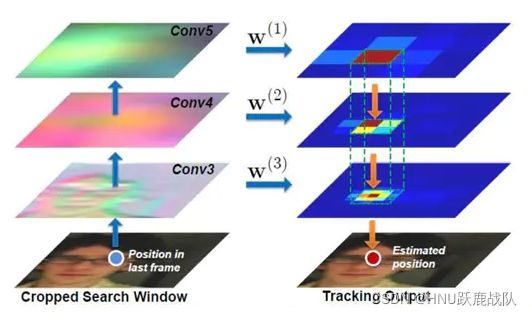
特征提取器有两种方法,离线和在线。离线的提取器一般就是在ImageNet等训练集上进行预训练,然后直接用于生成深度特征。而在线学习则是和其他传统方法一样,从前一帧的GT附近截取数个ROI并在其上进行在线训练。也可以采取中庸之道,使用pre-train+在线fine-tune的方法。
cnn的卷积操作应当为典型的空域卷积,前面介绍KCF的时候我们就知道频域中的许多性质可以帮助我们加速运算——卷积在频域变成了简单的乘法。其中,在线方法可以在频域利用傅里叶变换的性质(复矩阵对角化/循环矩阵对角化/FFT等)加速提取特征和训练。
针对目标尺度和角度的变化,可以采用多尺度训练/FPN等目标检测中常用的技巧来进行针对性优化。至于亮度/对比度等不变性,对于网络来说都是小菜一碟,只需要在训练时装入经过数据增强的样本即可。
5.4.4.2.候选区域生成
不同的跟踪方法有不同的候选区域生成策略,最简单粗暴的方法就是对整张图片都运行(这就没有任何”策略“可言了)。这一个步骤也可以对应到目标检测网络中的回归器。
相关滤波方法一般是采样GT周围的ROI(例如KCF就是把GT扩展2.5倍,利用循环矩阵在频域良好的性质进行计算),生成式方法则是寻找数个特征点/群,将那些有较多成对匹配点的区域作为ROI。之前在 5.2.6.6 中介绍vision attention的时候提到有通道域和空间域的注意力,那么网络可以利用attention机制对ROI中的特定区域进行筛选,减小搜索空间。
再进一步就可以利用 5.3.2 中介绍的运动学建模和运动预测方法,利用历史的时间序列数据建模物体的运动,KF、PF、IMM等方法在目标跟踪中都是可用的,不过由于深度信息的缺失(仅仅在二维平面上估计运动,丢失了 z z z轴的信息),处于复杂运动状态下的物体很难用线性预测器预测。因此可以使用网络替代这些组件中的部分模块,用网络的输出提供协方差/噪声建模等信息,更好的建模非线性因素。
既然是序列信息,RNN/LSTM/Transformer必然也是可用的,并且可以增加时间注意力机制(对比通道域和空间域,在RNN中是另一个维度),建模历史不同时刻帧对于当前跟踪的重要性。

5.4.4.3.分类器/回归器(fine-tune)
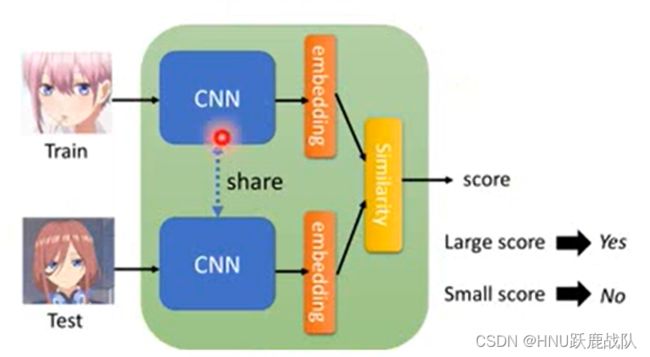
之前介绍的判别式算法,其滤波器(可以看作分类器)都是在线训练的,而对于由神经网络构造的判别器和回归其,更合适的方法是离线训练。对于分类器,较好的方法是参照人脸识别中常用的few-shot learning,设计一个判别函数,利用triplet损失或Siamese网络来进行训练。不了解这两者的同学可以参考吴恩达深度学习第四章-Siamese网络以及吴恩达深度学习第四章-Triplet损失。
对于Siamese(一般称作孪生网络),我们可以并行训练两个网络,分别用于提取gt和候选区域的特征。
一般来说就是在提取模块上再进一步,其实CNN的特征提取和映射很难分清界限,你可以认为前几层是在提取,后基层是在映射,这里我们暂且把他们直接拆分为2个部分即提取+映射。
然后,对cnn输出的最后一层特征进行embedding(再提一嘴,也可以直接当作最后输出的特征就已经是嵌入在某个空间中了),并利用一些尺度度量的手段如欧式距离、海明距离等等来计算两个向量的距离/估算相似度。最后输出一个分数,高分代表相似,低分代表不确定/不相似。许多时候我们也不需要直接训练两个网络,而是直接训练一个网络并在另一个网络上共享参数,即下图中的”share“所示的虚线。
在triplet loss中,我们期望相同的同类别样本的距离尽量小同时希望不同类别样本的距离尽量大,因此设计的损失函数如下:
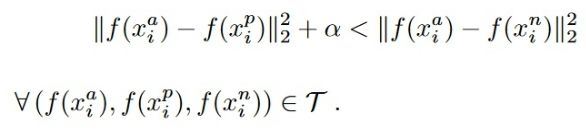
其中 x i a x^a_i xia是anchor即参考样本(正类), x i p x^p_i xip是正样本, x i n x^n_i xin是负样本, τ \tau τ就是所有成对的训练资料(在训练中可以取任一样本作为anchor,然后取另一和anchor同类的样本作为positive,最后取任意一个其他类的样本作为negative)。加入的 α \alpha α是一个极小的值用于正则化,防止网络”走捷径“:在最小化同类样本距离的同时却使得正样本和负样本的距离很接近零,即前一项损失几乎是零,第二项只要稍稍大于零就完成了训练目标。最后,网络输入两张图像(gt和ROI),输出他们之间的距离,根据这个距离进行判别即可。
对于回归器而言,其目的是输出当前帧跟踪框的位置。但是上面介绍的分类器都是运行在某个区域(ROI)上的,意思是我们要先确定用于提取特征和匹配的框,然后再运行分类器,然而一般可能的预测区域都是通过 5.4.2.2 中介绍的方法得到的。那么在这里,我们则是执行类似目标检测网络中two-stage的方法,候选区域生成作为“RPN”,后面再跟一个回归器用于对候选框的位置进行微调。不过对于判别式的跟踪而言,倘若回归器生成的bbox太过于贴合目标,有可能还会适得其反:不同于目标检测,目标跟踪中背景信息也是很重要的特征(特别是对于只提取上一帧 bbox中特征的方法 ),tracker应当很好地分离背景和前景,并且获取他们之间的差异,倘若完全没有提取到背景信息跟踪器将会很难区分下一帧的目标和背景。
5.4.4.4.端到端方法

-
学习过之前目标检测的同学应该对这个词语非常熟悉了。我们之所以这么执着于end2end,正是因为其框架和pipeline的简洁性和同一性。上图所示的就是SiamFC,一个端到端的跟踪网络。其实本质上是一个相关滤波的框架,只不过所有模块都使用CNN实现:上方的分支是特征提取器,将前一帧的bbox送入网络 φ \varphi φ进行卷积运算得到6x6x128的滤波器,下方则是输入当前帧整张图片,还是通过 φ \varphi φ提取特征(参数共享的思路),得到22x22x128的feature map;最后用第一个分支得到的滤波器对feature map进行卷积(也可以说是相关运算)运算,可以得到一个heat map代表原图上各个位置的响应,自然响应最大的地方就是我们要找的目标了。
参数共享和第一个分支中利用生成的特征作为判别式算法中的filter的思想是这个网络的最大特点。在SiamFC之后有大量工作顺着其思路进行扩展,但是都是基于相关滤波展开的,比如添加attention、增加响应之间的交互、更好的特征提取方法等。
-
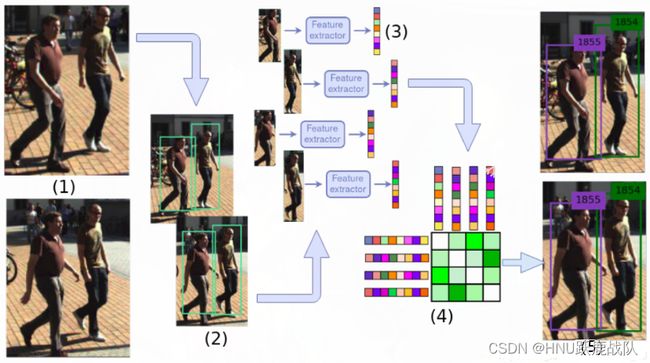
另一种思路是由SORT(simple online and realtime tracking)提出的tracking by detection,字如其名,利用目标检测实现跟踪。不过这个方法最开始其实算不上end2end。其框架包括一个用KF实现的预测器、一个目标检测网络和用匈牙利算法实现的匹配模块。这其实是为了解决多对多跟踪即MOT而提出的方法,不过其思路很值得借鉴故在此简单介绍,对于单目标跟踪同样可以使用该思路。
检测过程如下:首先用第一帧的目标初始化KF,随后在第二帧中通过检测网络得到当前帧中的数个目标,这时候就需要用匈牙利算法对检测网络输出的bbox和前一帧的gt基于cost最小的原则进行一对一匹配(可以参考5.2.6.8 中DETR的相关部分);完成匹配后利用两帧的差异更新滤波器的参数,至此完成一轮迭代。
显然,SORT的性能非常依赖检测网络的准确度,若检测框数量多余或少于前一帧,就需要进行特殊处理。而且其预测方法也过于简单,没有增加更多的先验,导致对快速物体的跟踪效果不是特别好。因此后续提出是DeepSORT对SORT进行了改进,引入了当前帧和前一帧的IoU、对物体运动更详细的建模、用于衡量两帧目标相似度的Siamese网络等方法改善SORT的性能。
当然DeepSORT也还是有很多问题,后续也提出了很多针对性的改进:
- Re-ID网络(即Siamese+KM)可以直接和检测网络融合,做到真正的端到端
- 若一个物体在很长一段时间都被很好的catching,应该可以给予其更大的权重
- 不单单使用tracking by detection的方法,追踪器可以弥补检测器的漏检
- 使用除KF外更好的运动模型,参见 5.3.2 的运动建模部分
对于RM比赛,由于目标较为稀疏并且我们的相机采样率极高,甚至可以直接使用tracking by IOU的方法,直接使用两帧之间目标的IOU来判断当前检测框内的物体是否是同一物体。