07组第三次作业 卷积神经网络
07组第三次作业 卷积神经网络
Part 1 视频学习
一、绪论
1.1 卷积神经网络
全连接在图象处理上会导致参数过多->可能导致过拟合
卷积神经网络,局部关连,参数共享
1.2 卷积神经网络的应用
分类、检索、检测、分割、人脸识别、图像生成、图像风格转化、自动驾驶
1.3 传统神经网络(全连接)VS卷积神经网络
1.3.1 深度学习三部曲:
Step1:搭建神经网络结构
Step2:找到一个合适的损失函数
Step3:找到一个合适的优化函数,更新参数
1.3.2 损失函数:
给定W,可以由像素映射到类目得分
损失函数是用来衡量吻合度的
可以调整参数/权重W,使得映射的结果和实际类别吻合
常用分类损失:交叉熵损失、hinge loss……
常用回归损失:均方误差、平均绝对值误差……
1.3.1 全连接网络处理图像的问题:
参数太多:权重矩阵的参数太多,会导致过拟合
卷积神经网络的解决方法:局部关联,参数共享
**局部关联:**卷积层的节点仅仅和其前一层的部分节点相连接,只用来学习局部特征
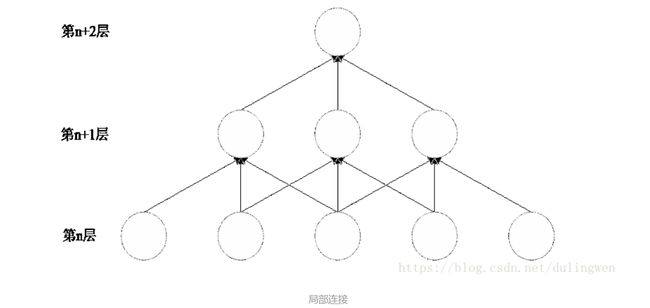
参数共享:输入图片的不同区域作卷积,来检测相同的特征

包含层:
CONV layer(卷积层)
ReLU layer(ReLU激活层)
POOL layer(池化层)
FC layer(全连接层)
二、基本组成结构
2.1 卷积(CONV layer)
卷积:卷积是对两个实变函数的一种数学操作
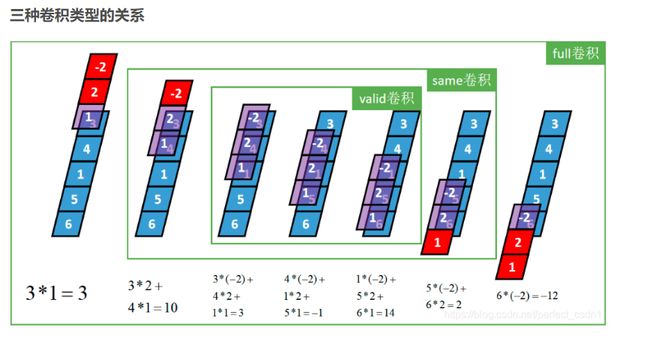
2.1 一维卷积
一维卷积分为:full卷积、same卷积和valid卷积
当前信息,等于当前接受到的信息,加上之前接受的信息×一个衰减率

举例:人的记忆,等于当前这天的记忆,加上昨天的记忆乘以一个衰减率在加上前天记忆乘以对于的衰减率…
2.2 二维卷积(处理图像)
图象以二维的形式传入,所以做一个二维卷积,就是n*n的矩阵内核

bias:偏置单元(属于filter的参数)
步长不够的话要进行零填充

未加padding时输出的特征图大小:(N-F)/stride+1
有padding时输出的特征图大小:(N+padding*2-F)/stride+1
2.2 池化(Pooling layer)
Pooling:
保留了主要特征的同时减少参数和计算器,防止过拟合,提高模型泛化能力
一般处于卷积层于卷积层之间,全连接层于全连接层之间
Pooling的类型:
Max pooling:最大值池化
Average pooling:平均池化

2.3 全连接(Fully Connected Layer)
全连接层/FC layer:
(1)两层之间所有神经元都有权重链接
(2)通常全连接层在卷积神经网络尾部
(3)全连接层参数量通常最大
三、卷积神经网络典型结构
3.1 AlexNet
3.1.1 特点:
1.AlexNet在激活函数上选取了非线性非饱和的ReLU函数,在训练阶段梯度衰减快慢方面,ReLU函数比传统神经网络所选取的非线性饱和函数(如sigmoid函数,tanh函数)要快许多。激活函数的更新:relu函数更容易计算,收敛了更快,在一定程度解决了梯度消失
2.AlexNet在双GPU上运行,每个GPU负责一半网络的运算
3.采用局部响应归一化(LRN)。对于非饱和函数ReLU来说,不需要对其输入进行标准化,但Alex等人发现,在ReLU层加入LRN,可形成某种形式的横向抑制,从而提高网络的泛华能力。
4.池化方式采用overlapping pooling。即池化窗口的大小大于步长,使得每次池化都有重叠的部分。(ps:这种重叠的池化方式比传统无重叠的池化方式有着更好的效果,且可以避免过拟合现象的发生)
3.1.2 激活函数:Sigmoid VS ReLU

3.1.3 避免过拟合的方法
DropOut(随机失活):训练时随机关闭部分神经元,测试时整合所有神经元
3.1.4 数据增强
平移、翻转、对称
改变RGB通道强度
3.1.5 AlexNet分层解析
第一次卷积:卷积—ReLU—优化
第二次卷积:卷积—ReLU—优化
第三次卷积:卷积—ReLU
第四次卷积:卷积—ReLU
第五次卷积:卷积—ReLU—优化
第六层:全连接—ReLU—DropOut

3.2 ZFNet
网络结构与AlexNet相同
将卷积层1中的感受野大小由11*11改为7*7,步长由4改为2
卷积层3,4,5中的滤波器个数由384,384,256改为512,512,1024
3.3 VGG(VGG16,VGG19)

3.4 GoogleNet
3.4.1 网络总体结构:
网络包含22个带参数的层(如果考虑pooling层就是27层),独立成块的层总共有约有100个
参数量大概是AlexNet的1/2
没有FC层
3.4.2
Naive Inception:
初衷:多卷积核增加特征多样性
问题:计算复杂度过高
Inception V2:
解决思路:插入1*1卷积核进行降维
Inception V3:
用小的卷积核代替大的卷积核
优点:
降低参数量
增加非线性激活函数:增加非线性激活函数使网络产生更多独立特征,表征能力更强,训练更快
4.1 GoogleNet
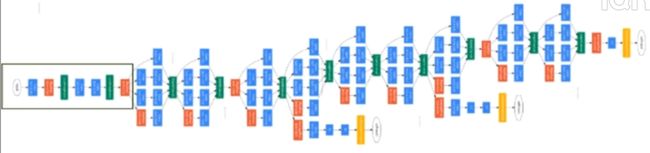
Stem部分(stem network):卷积—池化—卷积—卷积—池化

多个Inception结构堆叠

输出:没有额外的全连接层(除了最后的类别输出层)

辅助分类器:解决由于模型深度过深导致的梯度消失的问题
5.1 ResNet
残差学习网络
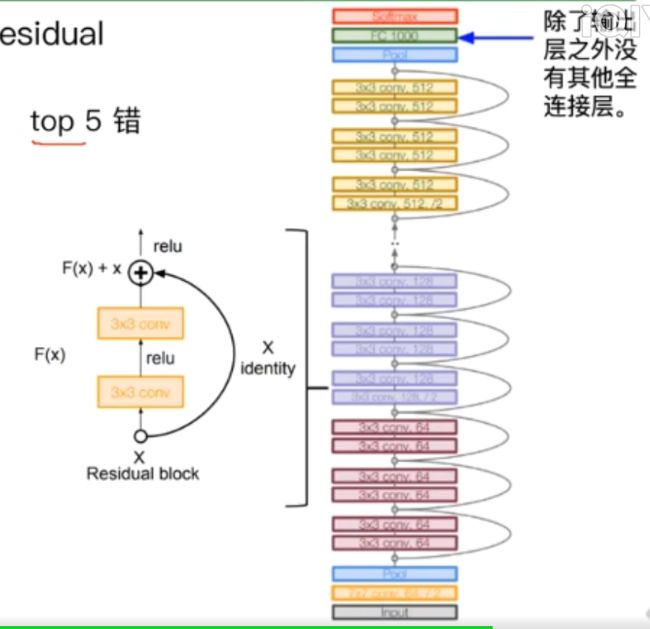
残差的思想:去掉相同的主体部分,从而突出微小的变化
可以被用来训练非常深的网络
Part 2 代码练习
一、 MNIST 数据集分类
构建简单的CNN对 mnist 数据集进行分类。同时,还会在实验中学习池化与卷积操作的基本作用。
colab_demo/05_01_ConvNet.ipynb at master · OUCTheoryGroup/colab_demo (github.com)
二、CIFAR10 数据集分类
使用 CNN 对 CIFAR10 数据集进行分类。
colab_demo/05_02_CNN_CIFAR10.ipynb at master · OUCTheoryGroup/colab_demo (github.com)
三、使用 VGG16 对 CIFAR10 分类。
colab_demo/05_03_VGG_CIFAR10.ipynb at master · OUCTheoryGroup/colab_demo (github.com)
Part 3 问题思考
一、dataloader 里面 shuffle 取不同值有什么区别?



当我们把shuffle从true改为false的时候 可以看出 精确度有明显的下降
二、transform 里,取了不同值,这个有什么区别?
首先transform.ToTensor()
是讲图像灰度到(0,1)这个区间
但是需要在(-1,1)这个区间
就需要transform.Normalize转换一下
公式是image=(image-mean)/std
里面是mean=0.5 std=0.5
可以那最小值算一下 (0-0.5)/0.5=-1
最大值1则变成(1-0.5)/0.5=1
第三个实验中的图像 因为 没有进行灰度
然后三个参数通过rgb算出来的 0-255
三、epoch 和 batch 的区别?
epoch是一个数据集整个训练完,每一个数据都可能对参数进行影响
batch是自己定义训练的次数,也就是训练一个batch然后就要更新一次参数
四、1x1的卷积和 FC 有什么区别?主要起什么作用?
全连接层和卷积层最大的区别就是输入尺寸是否可变,全连接层的输入尺寸是固定的,卷积层的输入尺寸是任意的1×1卷积核是对输入的每一个特征图进行线性组合,而全连接层是对输入的每一个数进行线性组合。
1×1卷积主要是起到了降维、加入非线性、channal 的变换的作用。
全连接层就是将最后一层卷积得到的特征图展开成一维向量,将卷积得到的局部特征连接起来,并为分类器提供输入。
五、residual leanring 为什么能够提升准确率?
ResNet的输出变为F(x)+x,求导后x变为1,有效解决了梯度消失或者梯度爆炸的问题,而且使用恒等映射直接将前一层输出传到后面(无损直达),可以用来训练更深的网络结构。
六、代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
激活函数不同,LeNet网络使用的是sigmoid激活函数,而AlexNet使用的是ReLU函数。二者的池化方式和网络模型构造也不尽相同。
七、代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
对输入做一个1×1卷积运算,使得其和输出的维度保持一致。
八、有什么方法可以进一步提升准确率?
-
优化网络结构模型
-
采用更好的激活函数
-
增加训练的数据集