python---pandas详解
python—pandas详解
文章目录
-
- python---pandas详解
- pandas介绍
- pandas的数据结构介绍
-
- Series
- DataFrame
- 索引对象
- 基本功能
-
- 重新索引
- 丢弃指定轴上的项
- 索引、选取和过滤
- ⽤loc和iloc进⾏选取
- 算术运算和数据对齐
- DataFrame和Series之间的运算
- 函数应⽤和映射
- 排序和排名
- 带有重复标签的轴索引
- 汇总和计算描述统计
pandas介绍
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
pandas经常和其它⼯具⼀同使⽤,如数值计算⼯具NumPy和SciPy,分析库statsmodels和scikitlearn和数据可视化库matplotlib
pandas的数据结构介绍
pandas两大主要数据结构:Series和DateFrame
Series
Series是⼀种类似于⼀维数组的对象,它由⼀组数据(各种NumPy数据类型)以及⼀组与之相关的数据标签(即索引)组成。仅由⼀组数据即可产⽣最简单的Series:
例如:
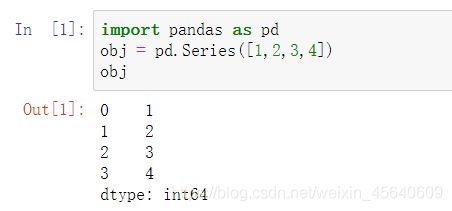
Series的字符串表现形式为:索引在左边,值在右边,如果未指定索引,就会自动生成。也可以自己指定索引:
例如:

当创建好pandas数组后,可以通过values和index属性获取数组的值和索引。
例如:

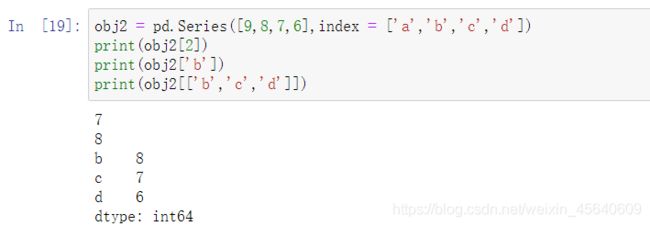
与numpy数组不同的是,pandas数组可以通过索引的方式选取Series中的单个或一组值:
例如:
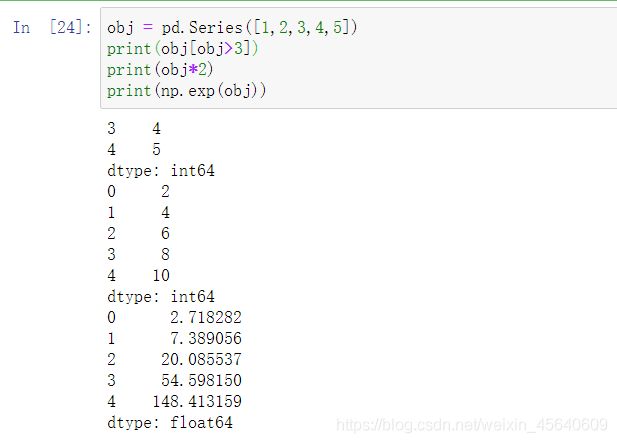
当对pandas数组进行一些数学运算或者逻辑运算时,它返回的都是带索引的。
例如:
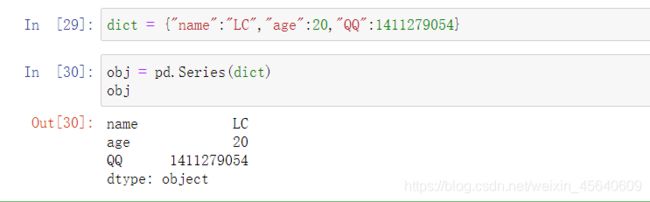
另外,你可以通过python字典来创建一个Series
例如:
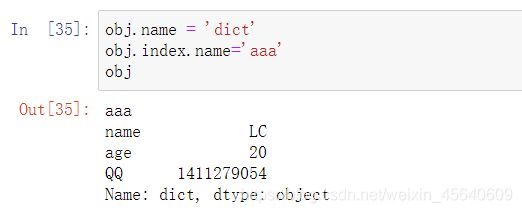
 另外:Series对象本身及其索引都有⼀个name属性
另外:Series对象本身及其索引都有⼀个name属性
例如:
DataFrame
DataFrame是⼀个表格型的数据结构,它含有⼀组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有⾏索引也有列索引,它可以被看做由Series组成的字典(共⽤同⼀个索引)。
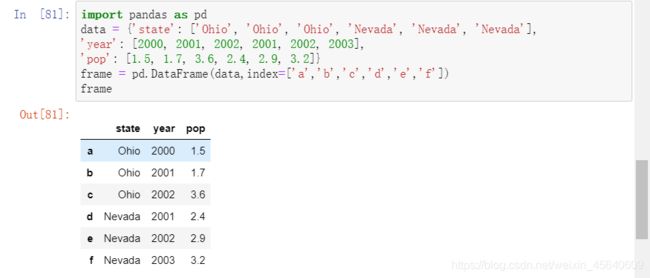
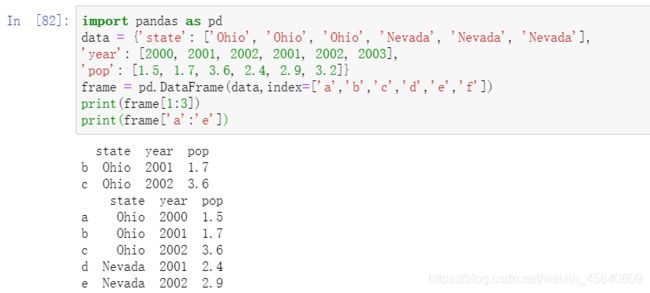
建DataFrame的办法有很多,最常⽤的⼀种是直接传⼊⼀个由等⻓列表或NumPy数组组成的字典:

如果指定了了列序列,则DataFrame的列就会按照指定顺序进行排序:
例如上面的例子, 这里指定第一列为’year’,第二列为‘state’,第三列为’pop’.

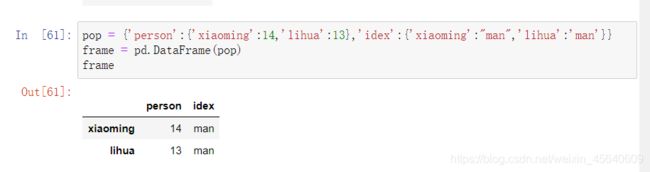
另外,还可以通过嵌套字典的方式创建DataFrame,如果嵌套字典传给DataFrame,pandas就会被解释为:外层字典的键作为列,内层键则作为⾏索引:
例如:
对于特别大的DataFrame,head方法会选取前五行:
例如:

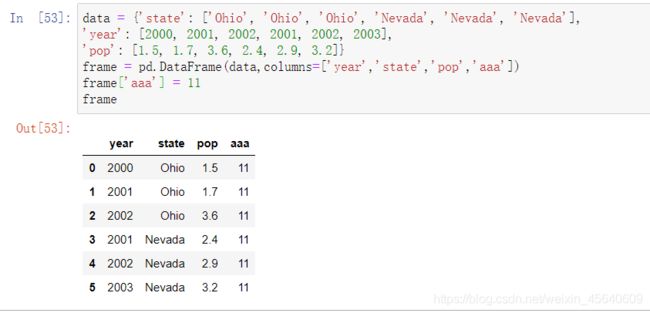
如果传入的列在数据中找不到,就会在结果中产生缺失值:

通过类似字典标记的⽅式或属性的⽅式,可以将DataFrame的列获取为⼀个Series:
例如:

列可以通过赋值的⽅式进⾏修改。
例如:
将列表或数组赋值给某个列时,其⻓度必须跟DataFrame的⻓度相匹配。如果赋值的是⼀个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值:
例如,这里把原本aaa列都是NaN类型的数据,通过Series数组改变了相应的索引数据:
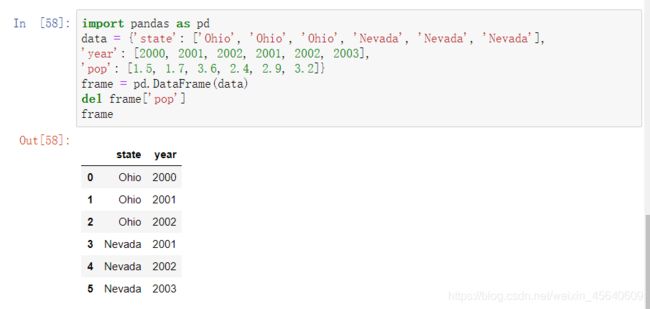
DataFrame的del⽅法可以⽤来删除相应的列:
例如,这里通过del方法把pop列删除了:
另外,可以通过Numpy的数组方法, 对DataFrame进行转置(arr.T):

关于DataFrame构造器:
| 类型 | 说明 |
|---|---|
| 二维ndarray | 数据矩阵,还可以传入行标和列标 |
| 由数组、列表或元组组成的字典 | 每个序列会变成DataFrame的一列。所有序列的长度必须相同 |
| NumPy的结构化/记录数组 | 类似于“由数组组成的字典” |
| 由Series组成的字典 | 每个Series会成为一列。如果没有显式指定索引,则各Series的索引会被合并成结果的行索引 |
| 由字典组成的字典 | 各内层字典会成为一列。键会被合并成结果的行索引,跟“由Series组成的字典”的情况一样 |
| 字典或Series的列表 | 各项将会成为DataFrame的一行。字典键或Series素引的并集将会成为DataFrame的列标 |
| 由列表或元组组成的列表 | 类似于“二维ndarray” |
| 另一个DataFrame | 该DataFrame的索引将会被沿用,除非显式指定了其他索引 |
| NumPy的MaskedArray | 类似于“二维ndarray”的情况,只是掩码值在结果DataFrame会变成NA/缺失值 |
索引对象
构建Series或DataFrame时,所
⽤到的任何数组或其他序列的标签都会被转换成⼀个Index,而且index对象不可变,用户不能对它修改
(会抛出typeError的异常):

基本功能
重新索引
pandas对象的⼀个重要⽅法是reindex,其作⽤是创建⼀个新对象,它的数据符合新的索引。
例如:

丢弃指定轴上的项
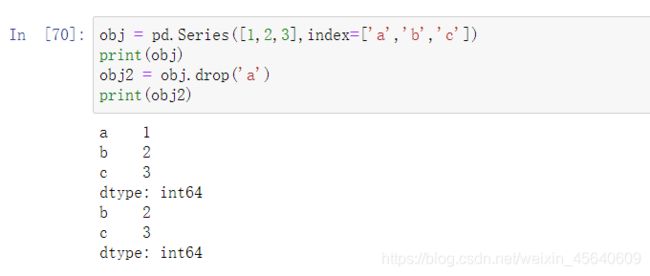
使用drop方法可以返回一个指定轴上删除了指定值的新对象:
例如(对于Series):
对于DataFrame,可以删除任意轴上的索引值。通过传递参数axis可以删除列的值:
例如:frame是什么都没有删除的,frame1删除了第0行,frame2通过axis=1指定了列,删除了state列

索引、选取和过滤
Series索引(obj[…])的⼯作⽅式类似于NumPy数组的索引,只不过Series的索引值不只是整数。
对于未指定索引的数组,会用默认的数字(0~N-1)索引, 例:

通过index属性指定索引:
切片操作:
这里演示了先用数字索引,再用标签索引
⽤loc和iloc进⾏选取
特殊的标签运算符loc和iloc。它们可以让你⽤类似NumPy的标记,使⽤轴标签(loc)或整数索引(iloc),从DataFrame选择⾏和列的⼦集。
例如(使用loc):

使用iloc(整数索引)

算术运算和数据对齐
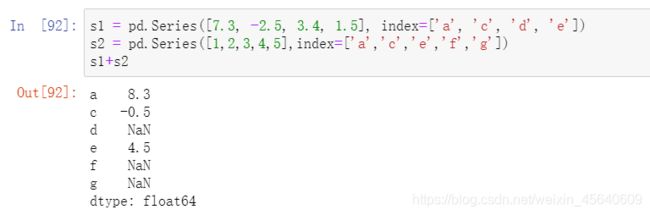
pandas最重要的⼀个功能是,它可以对不同索引的对象进⾏算术运算。在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集例如:
对于DataFrame,对齐操作会同时发生在行和列上:
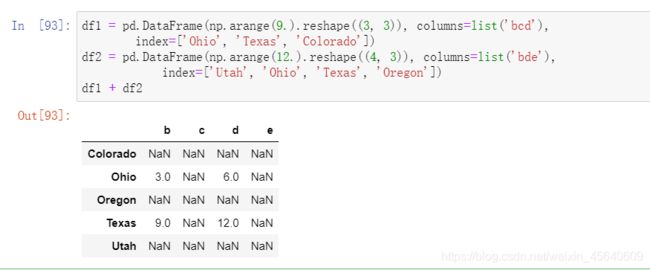
DataFrame和Series之间的运算
跟不同维度的NumPy数组⼀样,DataFrame和Series之间算术运算也是有明确规定的,
例如,当我们frame减去series时,对应frame每一行都会执行这个操作:(其实这叫做广播)

默认情况下,DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着⾏⼀直向下⼴播。
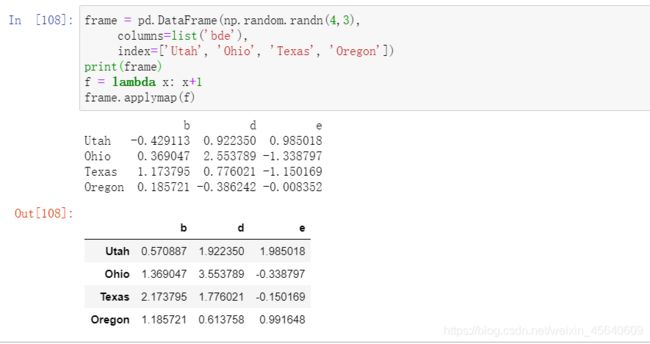
函数应⽤和映射
NumPy的ufuncs(元素级数组⽅法)也可⽤于操作pandas对象:
例如:

另⼀个常⻅的操作是,将函数应⽤到由各列或⾏所形成的⼀维数组上。DataFrame的apply⽅法即可实现此功能:
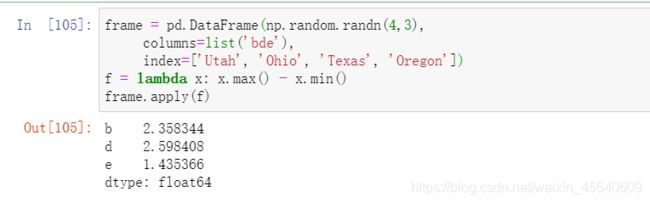
或者使用applymap进行每个元素操作:
这里对每一个元素加一
排序和排名
根据条件对数据集排序(sorting)也是⼀种重要的内置运算。要对⾏或列索引进⾏排序(按字典顺序),可使⽤sort_index⽅法,它将返回⼀个已排序的新对象。
对于Series数组:

对于DataFrame,则可以根据任意一个轴上的索引进行排序:

通过ascending属性可以使其降序:

带有重复标签的轴索引
如果有重复的索引,那么索引的is_unique属性可以告诉你它的值是否是唯⼀的


汇总和计算描述统计
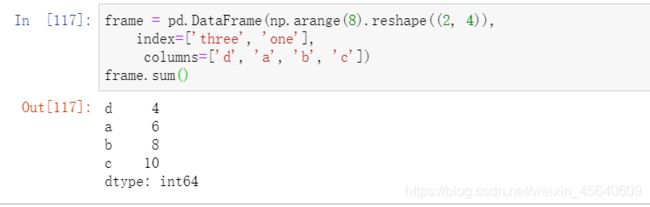
pandas对象拥有⼀组常⽤的数学和统计⽅法。它们⼤部分都属于约简和汇总统计,⽤于从Series中提取单个值(如sum或mean)或从DataFrame的⾏或列中提取⼀个Series。跟对应的NumPy数组⽅法相⽐,它们都是基于没有缺失数据的假设⽽构建的。
例如(sum方法):
mean方法:

idxmin获取最大值的索引(idxmin获取最小值索引):

| 方法 | 说明 |
|---|---|
| count | 非NA值的数量 |
| describe | 针对Series或各DataFrame列计算汇总统计 |
| min、max | 计算最小值和最大值 |
| argmin、argmax | 计算能够获取到最小值和最大值的索引位置(整数) |
| idxmin、idxmax | 计算能够获取到最小值和最大值的索引值 |
| quantile | 计算样本的分位数(0到1) |
| sum | 值的总和 |
| mean | 值的平均数 |
| median | 值的算术中位数(50%分位数) |
| mad | 根据平均值计算平均绝对离差 |
| var | 样本值的方差 |
| std | 样本值的标准差 |
| skew | 样本值的偏度(三阶矩) |
| kurt | 样本值的峰度(四阶矩) |
| cumsum | 样本值的累计和 |
| cummin、cummax | 样本值的累计最大值和累计最小值 |
| cumprod | 样本值的累计积 |
| diff | 计算一阶差分(对时间序列很有用) |
| pct_change | 计算百分数变化 |
参考书籍:《利用python进行数据分析》