决策树(3)-sklearn实现及可视化画图
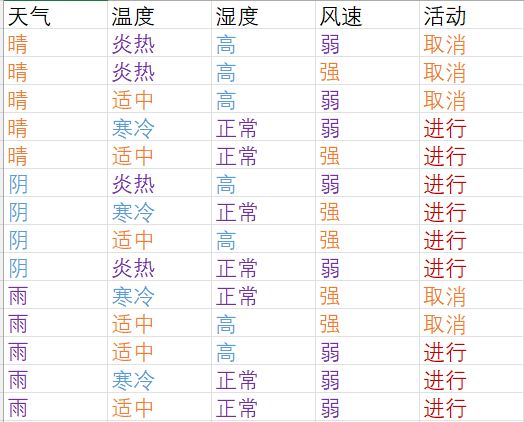
仍然使用之前得数据
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn import preprocessing
import csv
import numpy as np
源代码:
read=csv.reader(open('data1.csv','r'))
报错:
'gbk' codec can't decode byte 0x94 in position 8: illegal multibyte sequence
修改:
read=csv.reader(open('data1.csv','r',encoding='utf-8'))
出现问题:
'\ufeff天气', '温度', '湿度', '风]
当我们读取的文件或者写入文件时有时候会出现"\ufeff"非法字符,这个时候需要改变编码方式‘UTF-8‘为‘UTF-8-sig‘
#读入数据
read=csv.reader(open('/root/jupyter_projects/data/data1.csv','r',encoding='utf-8-sig'))#不加编码方式会报错
#获取第一行数据
headers=read.__next__()
print(headers)
#定义两个列表
featureList=[]
labelList=[]
for row in read:
labelList.append(row[-1])
rowDict={}
for i in range(0,len(row)-1):
rowDict[headers[i]]=row[i]
#建立一个数据字典
#把字典存入列表
featureList.append(rowDict)
print(featureList)
['天气', '温度', '湿度', '风速', '活动']
[{'天气': '晴', '温度': '炎热', '湿度': '高', '风速': '弱'}, {'天气': '晴', '温度': '炎热', '湿度': '高', '风速': '强'}, {'天气': '晴', '温度': '适中', '湿度': '高', '风速': '弱'}, {'天气': '晴', '温度': '寒冷', '湿度': '正常', '风速': '弱'}, {'天气': '晴', '温度': '适中', '湿度': '正常', '风速': '强'}, {'天气': '阴', '温度': '炎热', '湿度': '高', '风速': '弱'}, {'天气': '阴', '温度': '寒冷', '湿度': '正常', '风速': '强'}, {'天气': '阴', '温度': '适中', '湿度': '高', '风速': '强'}, {'天气': '阴', '温度': '炎热', '湿度': '正常', '风速': '弱'}, {'天气': '雨', '温度': '寒冷', '湿度': '正常', '风速': '强'}, {'天气': '雨', '温度': '适中', '湿度': '高', '风速': '强'}, {'天气': '雨', '温度': '适中', '湿度': '高', '风速': '弱'}, {'天气': '雨', '温度': '寒冷', '湿度': '正常', '风速': '弱'}, {'天气': '雨', '温度': '适中', '湿度': '正常', '风速': '弱'}]
#把数据转换成01表示
vec=DictVectorizer()
x_data=vec.fit_transform(featureList).toarray()
print(x_data)
print(vec.get_feature_names_out())
#10列即时把每个特征的每个取值都作为一列
[[1. 0. 0. 0. 1. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1. 0. 0. 1. 0. 1.]
[1. 0. 0. 0. 0. 1. 0. 1. 1. 0.]
[1. 0. 0. 1. 0. 0. 1. 0. 1. 0.]
[1. 0. 0. 0. 0. 1. 1. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[0. 1. 0. 0. 0. 1. 0. 1. 0. 1.]
[0. 1. 0. 0. 1. 0. 1. 0. 1. 0.]
[0. 0. 1. 1. 0. 0. 1. 0. 0. 1.]
[0. 0. 1. 0. 0. 1. 0. 1. 0. 1.]
[0. 0. 1. 0. 0. 1. 0. 1. 1. 0.]
[0. 0. 1. 1. 0. 0. 1. 0. 1. 0.]
[0. 0. 1. 0. 0. 1. 1. 0. 1. 0.]]
['天气=晴' '天气=阴' '天气=雨' '温度=寒冷' '温度=炎热' '温度=适中' '湿度=正常' '湿度=高' '风速=弱' '风速=强']
lb=preprocessing.LabelBinarizer()
y_data=lb.fit_transform(labelList)
print(y_data)
[[0]
[0]
[0]
[1]
[1]
[1]
[1]
[1]
[1]
[0]
[0]
[1]
[1]
[1]]
model=tree.DecisionTreeClassifier(criterion='entropy')
model.fit(x_data,y_data)#训练模型
对应该函数得参数可以看这篇博客:scikit-learn决策树算法类库使用小结
DecisionTreeClassifier(criterion='entropy')
x_test=np.array([1,0,0,0,0,1,0,1,0,1])
predict=model.predict(x_test.reshape(1,-1))
print(predict)#做预测
[0]
安装决策树画图工具
①安装grahpviz包
[root@iZbp173czfyjpvvdm6k4amZ data] pip3.8 install graphviz
②安装graphvia工具(linux)
到官网找到对应系统版本下载 http://www.graphviz.org/download/
下面是Linux下的直接用yum安装
[root@iZbp173czfyjpvvdm6k4amZ data]# yum install graphviz
Invalid configuration value: failovermethod=priority in /etc/yum.repos.d/CentOS-epel.repo; Configuration: OptionBinding with id "failovermethod" does not exist
Repository epel is listed more than once in the configuration
Last metadata expiration check: 3:05:35 ago on Tue 18 Jan 2022 08:42:01 AM CST.
Package graphviz-2.40.1-43.el8.x86_64 is already installed.
Dependencies resolved.
Nothing to do.
Complete!
windows需要将 graphviz 安装目录下的 bin 文件夹路径添加到环境变量中
import graphviz
dot_data=tree.export_graphviz(model,
out_file=None,
feature_names=vec.get_feature_names_out(),
class_names=lb.classes_,
filled=True,
rounded=True,
special_characters=True)
graph=graphviz.Source(dot_data)
graph.render('computer')
'computer.pdf'
graph#画图
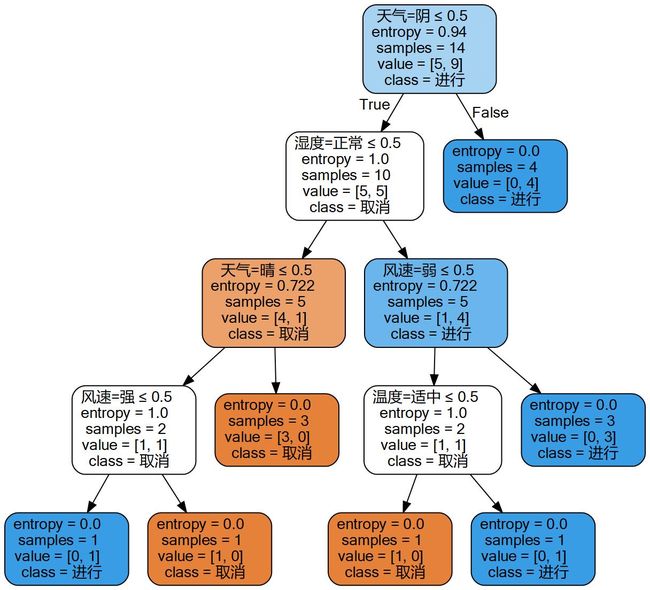
画出的决策树看起来与我们自己构造出来的决策树不太一样,这里只有2各分支,其实决策树算法慢慢发展,决策树一般都做成了二叉树,每个节点只有两个分支,左边全部都默认为true,右边为false
那么这个决策树是怎么看的呢?
首先来看最上边的那个结点,第一行是判断条件,即天气=阴 是否小于0.5,根据上面可以知道,天气=阴的时候为1,所以是false,直接看右边。第二行为信息熵。第三行是所有样本最终结果的各个取值值得实例个数,即活动取消和进行得个数,第4行时说如果没有下面得结点得话就跟随实列数目最多得那个类别。接下来看第二行得,由于天气=阴为1,为假来到右边,所有当天气=阴时活动都会进行下去。当天气=晴或者雨时,为真来到左边。继续按第一行得结点得判断方法进行判断。