neo4j学习笔记(二)——python接口-查询
我按照我要用的轻重缓急来记录我要用的方法,查询优先。
2019-9-18
neo4j学习笔记(一)
neo4j学习笔记(二)——python接口-查询
neo4j学习笔记(三)——python接口-创建删除结点和关系
pip安装
python的连接主要使用py2neo库
先pip:
pip install py2neopython的使用
import
from py2neo import Graph, Node, Relationship, NodeMatcher 连接图数据库(Graph)
老规矩,先放代码:
graph = Graph('http://localhost:7474', username='neo4j', password='neo4j')再讲过程:
由于版本的改动,网上的增删改查的代码样例有很多直接不适用了,最新的v4版本直接删掉了data和find_one查询。
靠别人不如靠自己,以前公子讲话,shell命令不知道怎么用就 --help 一下,python的类不知道怎么用我们也help一下看看。
运行代码:
help(Graph)输出一大串,摘摘有用的:
构造连接
Graph(uri=None, **settings)使用示例:
| >>> from py2neo import Graph | >>> graph_1 = Graph() | >>> graph_2 = Graph(host="localhost") | >>> graph_3 = Graph("bolt://localhost:7687")
看代码可知,构造的时候Graph里面可以传一个参数uri,和一串settings,也可以都不传。
uri一般就是"bolt://localhost:7687"这个东西
对应一下之前看过的config,bolt的连接端口是7687,http的就是7474,同理https应该是7473
dbms.connector.bolt.enabled=true
dbms.connector.bolt.listen_address=:7687
dbms.connector.http.enabled=true
dbms.connector.http.listen_address=:7474
dbms.connector.https.enabled=true
dbms.connector.https.listen_address=:7473
然后setting里面可以放的参数,help里面给出了好长一串,记一点常用的:
用户名和密码的两种格式:
auth:一个tuple元组,('user', 'password')
user: 用户名
password : 密码
连接地址uri的另一种格式:
host:连接ip地址,在本机上可以用localhost
port:端口号,7687之类的
scheme:uri的那三个,bolt,http,https
其它:
user_agent:用户代理
max_connections:最大连接数
连接数据库代码:
graph = Graph('http://localhost:7474', username='neo4j', password='neo4j')另:
help(Graph) 看看我发现了什么!删库跑路必备哦同志们~

查询方法:
这个查询分了好几种,可以查询节点,也可以通过结点查询关系。一个个来。
我瞎创建了几个点和关系,长这样:
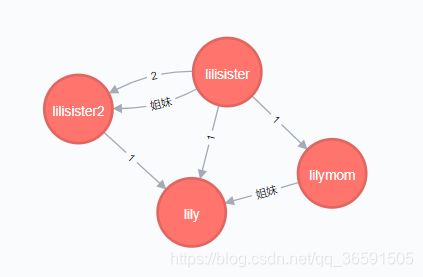
请不要吐槽我随意的节点和关系 
查询节点:
老规矩先说结论,上查询代码:
from py2neo import Graph, Node, Relationship,NodeMatcher
#连接图数据库
graph = Graph('http://localhost:7474', username='neo4j', password='neo4j')
#创建一个nodematcher,节点查询器
nodematcher= NodeMatcher(graph)
#按标签查询
match=nodematcher.match("Person")
#打印输出
for node in match:
print(node)
#也可以强制转换成list取值
print(list(match))输出结果,打印查询到的节点:
(_0:Person {age: 23, name: 'lilymom'}) (_1:Person {age: 23, name: 'lily'}) (_59:Person {age: 2, label: 'lalala', name: 'lilisister2'}) (_79:Person {age: 3, label: 'lalala', name: 'lilisister'}) [(_0:Person {age: 23, name: 'lilymom'}), (_1:Person {age: 23, name: 'lily'}), (_59:Person {age: 2, label: 'lalala', name: 'lilisister2'}), (_79:Person {age: 3, label: 'lalala', name: 'lilisister'})]
再讲方法:
查询节点这个类主要在 py2neo.matching. 文件下。所以执行
help(py2neo.matching)然后发现里面有四个类:

顾名思义,NodeMatcher肯定是节点查询器。
然后再运行 help(py2neo.matching.NodeMatcher) 查看NodeMatcher的方法。
NodeMatcher:
构造一个查询器:
nodematcher= NodeMatcher(graph)nodematcher包含方法:
get() 通过id查询节点,查不到返回null
match() match(self, *labels, **properties),通过标签和属性进行查询。
例:a=nodematcher.match("Person")
a=nodematcher.match(age=2)
NodeMatch
Nodematcher匹配到返回的是一个NodeMatch类型。
NodeMatch可以被想象成一个装了很多node的列表。可以用 len 查看大小,可以用 for 迭代取值。
包含方法:
first() 取第一个节点,返回Node类型
limit (amount) amount是一个数字,限制NodeMatch里面Node的最大数量。
order_by(*fields) 顾名思义应该是排序,我还没用过,用了再研究
skip(amount) 跳过前amount个节点
where(*conditions, **properties) 对NodeMatch里面的节点进行二次过滤,返回还是一个NodeMatch
查询关系:
和查询节点一样一样的
关系查询有两个入口,一个是RelationshipMatcher 里面的match方法,还有一个是Graph里面的match方法。
少废话上代码:
from py2neo import Graph, Node, Relationship,NodeMatcher ,RelationshipMatcher
#链接库
graph = Graph('http://localhost:7474', username='neo4j', password='neo4j')
#随便取一个结点,我取79是因为我这个图里79号关系比较多
nodematcher= NodeMatcher(graph)
node=nodematcher.get(79)
#之前都是一样的,这里开始两种写法
#方法1:Graph直接用
#为了方便看哪层是哪层我加了空格
list( graph.match( (node,) ) )
#[(lilisister)-[:2 {}]->(lilisister2), (lilisister)-[:1 {}]->(lilymom), (lilisister)-[:1 {}]->(lily), (lilisister)-[:姐妹 {}]->(lilisister2)]
list( graph.match( (node,) ,"1" ) )
#[(lilisister)-[:1 {}]->(lilymom), (lilisister)-[:1 {}]->(lily)]
#也可以随便取一条关系
graph.match_one()
#(lilymom)-[:姐妹 {}]->(lily)
#方法2:NodeMatcher
relationshipmatcher=RelationshipMatcher(graph)
relationshipmatcher.match((node,),"2")
#[(lilisister)-[:2 {}]->(lilisister2)]
#也可以根据id来找
relationshipmatcher.get(0)
#(lilisister)-[:姐妹 {}]->(lilisister2)
过程没啥可说的,包含方法在代码里都展示完了,跟nodematcher一样一样的。
啊还是说一点吧:
RelationshipMatcher里面:
get(id) 根据id找关系
match(nodes=None, r_type=None, **properties) nodes是Node的元组类型,r_type是关系的类型,最后一个是关系的属性,都可以作为查询条件
Graph里面:
match(nodes=None, r_type=None, limit=None) 同理,其中limit是查询数目的限制
RelationshipMatch
是RelationshipMatcher的返回类型。
包含方法同NodeMatch。
Graph里面其它函数一览:
| begin(self, autocommit=False) | create(self, subgraph) | delete(self, subgraph) | evaluate(self, cypher, parameters=None, **kwparameters) | exists(self, subgraph) #以上几个函数会创建一个Transaction对象再进行操作,具体的可以看运行help(Transaction)查看 #就是说我写上面那句话的时候还没看懂 #现在明白辽,下章用 | delete_all(self) #删掉数据库里面所有结点,不想死的话小心使用。
完啦~~