Improved Unsupervised Lexical Simplification with Pretrained Encoders 论文精读
Improved Unsupervised Lexical Simplification with Pretrained Encoders 论文精读
- Information
- Abstract
- 1 Introduction
- 2 System Description
-
- 2.1 Simplification Candidate Generation
- 2.2 Substitution Ranking
- 2.3 Obtaining Equivalence Scores
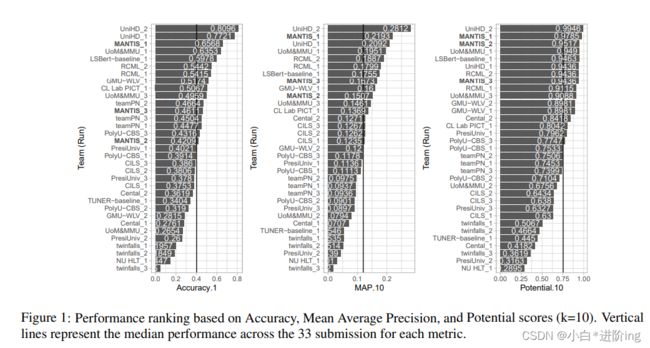
- 3 End-to-end System Performance
- References[^1]
- 自结
Information
标题: MANTIS at TSAR-2022上的共享任务: 用预先训练的编码器改进无监督词语简化
时间: 19 December, 2022
会议: EMNLP
作者: Xiaofei Li1, Daniel Wiechmann2, Yu Qiao1, Elma Kerz1
链接: https://arxiv.org/pdf/2212.09855.pdf
Abstract
在本文中,我们介绍了我们对EMNLP 2022研讨会关于文本简化、可访问性和可读性的词汇简化的MANTIS at TSAR-2022共享任务的贡献。我们的方法以以下方式建立并扩展了具有强等人 (2020) 中引入的预训练编码器 (LSBert) 系统的无监督词语简化系统:对于简化候选选择的子任务,它利用RoBERTa transformer语言模型并扩展了生成的候选列表的大小。对于后续替换排序,它引入了一种新的特征加权方案,并采用了基于文本包含的候选过滤方法,以最大化目标词之间的语义相似性及其简化。 我们的最佳性能系统通过5.9% 的准确性提高了LSBert,并在33个排名的解决方案中获得第二名。
1 Introduction
词语简化(LS)是一项自然语言处理(NLP)任务,涉及自动降低给定文本的词汇复杂性,同时保留其原始含义(Shardlow,2014;Paetzold and Specia,2017b)。 由于LS具有很高的社会效益和提高许多人的社会包容性的潜力,它在NLP社区中引起了越来越多的关注(štajner,2021)。 LS系统通常由三个主要步骤组成(Paetzold和Specia,2017a):(1)复杂词识别(CWI)、(2)替换词生成(SG)和(3)替换词排序(SR),其中CWI通常被视为一个独立的任务。
本文介绍了我们对TSAR-2022共享任务LS(Saggion et al.,2022)英文轨道的贡献。 在上述步骤(2)和(3)中,任务定义如下:给定一个包含复杂单词的句子,系统应该返回一个有序的列表,其中包含复杂单词在其原始上下文中的“更简单的”有效替换词。 系统返回的简单单词列表(最多10个)应根据系统对其预测的置信度排序(最好的预测优先)。有序列表不能包含捆绑。这项任务使用了一个新的基准数据集来简化英语、西班牙语和(巴西)葡萄牙语的词汇。 黄金注释由众包工作人员建议的所有更简单的替代词组成,并由至少一名以各自语言为母语的计算语言学家检查质量(详情见štajner et al.(2022))。 贡献团队提供了一个带有黄金标准注释的小样本作为试验数据集。 对于英语,这个试验数据集包括一个句子的10个实例,一个目标复杂词和一个候选替换列表。 英语测试数据集由373个句子/复杂词对实例组成。 根据10个性能指标对提交进行评估,这些指标分为三组:
(1)MAP@k(mean平均精度@k),k=1,3,5,10个候选词。 该度量根据用于评估的黄金标准注释集评估匹配(相关)和不匹配(无关)术语的预测候选词的排序列表。
(2)Potential@k:k=1,3,5,10。 潜在分数量化了预测的替换中至少有一个出现在黄金注释集合中的实例的百分比和
(3)Accuracy@k@top1:k=1,2,3。 精确度分数表示其中至少一个k最高的预测候选与注释候选的黄金列表中最频繁建议的同义词/S匹配的实例比率。
2 System Description
我们对TSAR共享任务的贡献建立并扩展了Qiang等人所描述的使用预先训练的编码器LSBert的无监督词语简化方法(2020)与强等(2021年)。 该方法利用预先训练的Transformer语言模型生成复杂词的上下文简化。 LSbert简化算法解决了LS的三个主要子任务中的两个:简化候选生成和替换排序。
我们的方法在以下几个方面扩展了LSBert:(1)利用Roberta Transformer语言模型来简化候选列表的生成,并扩大了生成的候选列表的大小。 (2)引入了新的替换排序方法,包括(i)对LSBert使用的排序特征进行重新加权;(ii)采用基于文本蕴涵的等价分数来最大化目标词之间的语义相似度及其简化。 在提交(运行)2和3中,我们进一步探讨了基于众包和基于语料库的词流行度度量在替代排名中的效用。 本文中描述的三个提交项的简化算法如算法1所示。 在下文中,我们详细描述了简化候选生成(2.1)、替换排序(2.2)和获得等价分数(2.3)。

2.1 Simplification Candidate Generation
在候选序列生成过程中,对于每一对句子S和复数词W,LSbert算法首先生成新的序列S,其中W被屏蔽。 然后将两个句子S和S串联起来,送入预先训练的Transformer语言模型(PTLM)中,得到能够填充掩蔽位置的词汇量的概率分布P(·S,S{W})。 从这个分布中选出的前10个单词被认为是简化候选词。1 我们的简化候选生成方法与LSBert中的方法有两个不同之处:(1)PTLM的选择和(2)候选列表的大小。 强等(2021)用三个Bert模型进行实验:(i)基于Bert的,未定义的:12层,768隐藏,12头,110M参数。 (ii)BertLarge,Uncased:24层,1024隐藏,16头,340M参数,和(iii)BertLarge,Uncased,全词掩盖(WWM):24层,1024隐藏,16头,340M参数。 实验结果表明,WWM模型具有较高的准确度和精度。 在这里,我们扩展了这些PTLM实验,包括Roberta模型(Liu et al.,2019),并实验了Bert和Roberta的联合使用,以扩大替代候选列表。 实验结果表明,利用Roberta-md得到了最佳结果:12层、768隐藏、12头、125M参数。 为了最大限度地在基于语义标准的严格过滤后获得至少十个合适的替换候选(见下文),我们将这一步中生成的候选列表的大小从10个增加到30个。
2.2 Substitution Ranking
在LSBert中,候选替换根据四个特征进行排序,每一个特征都被设计来捕捉候选词替换复杂词的适用性的一个方面。 这些特征是基于四个分数的候选替换的排序:(1)“预训练LM(PTLM)预测”(BPTLM(sc),在LSbert中,PTLM=bert),表示从PTLM导出的候选替换词sc在给定句子其余部分的掩蔽位置出现的概率。 (2)“语言模型特征”(LPLM(sc))表示sc的上下文的平均损失,Wm-m=(W-m,W-m+1,…,W0,…,Wm-1,WM),其中W0=sc。 (3)语义相似度(S(sc))表示为原词的FastText向量与sc的FastText向量之间的余弦相似度。 (4)从维基百科和儿童读物测试中心的前1200万篇文章中估计出的“词频”(F(sc))。2在LSbert中,sc的排列R(sc)是基于这四个特征的综合权重,如方程(1)和(2)所示。

在我们对共享任务的三次提交中,我们考虑了三种不同的策略来获得上面的分数(Sc):在第一次提交中(Mantis_1),我们采用了如公式(3)所示的排序方法。cf是特征f的特征权重,CBroberta=cF=1,cS=3。

该排序方法引入了特征的重新加权,以(i)增加目标词w和替代候选词sc之间语义相似度的相对重要性,以及(ii)降低基于概率的PTLM预测的相对重要性。 对于前者,对应于排序余弦相似度的S(sc)值增加了3倍,以惩罚与目标词相似度较低的候选词。 对于后者,我们决定删除语言模型特征LPTLM(sc),因为它与BPTLM(sc)的相关性将产生对sc出现在掩蔽位置的概率的重要性赋权。
在第二次和第三次提交中(Mantis_2和Mantis_3),我们对替代排序的替代特征进行了实验:为此,我们首先使用77个指标为每个替代候选项计算试验数据中句子的词汇复杂度得分(见附录中的表2)。 所有分数都是使用我们小组开发的自动文本分析系统获得的(关于其最近的应用,见例如Wiechmann et al.(2022)或Kerz et al.(2022))。 使用Stanford CorenLP(Manning et al.,2014)进行标记化、句子拆分、词性标注、引理化和句法PCFG解析。


然后,我们使用每个特征来获得替换候选的等级顺序,并将到达等级与试验数据中提供的替换候选的等级顺序相关联。 选择与黄金标准排序相关最大的前2个词汇特征,分别对Mantis_2和Mantis_3进行替代排序。 这两个词汇特征都涉及单词流行率(WP),即它们指的是知道这个单词的人数:WPcrowd基于一项涉及超过22万人的众包研究,估计知道给定单词的人口比例(Brysbaert et al.,2019)。 WPcorp.SDBP是一个基于语料库的对一个词出现在书中的数量的估计(Johns et al.,2020)。 相应的排名如方程式(4)和(5)所示:

除了这些WP特征外,运行2和运行3中的替代排序由一个语义特征决定,称为“等价分数”Eq(sc)(见2.3节)。 这一评分是基于这样一个考虑而产生的,即用嵌入的余弦相似度来衡量语义相似度不够具有表现力(Kim et al.,2016):在相似上下文中频繁使用的任意两个词,其嵌入之间的余弦相似度都很低。 因此,余弦相似往往不能识别反义词,如“快”和“慢”。 下一节将提供更多关于等价分数是如何获得的细节。
2.3 Obtaining Equivalence Scores
词语简化需要保留目标词的原意。 由于嵌入向量之间的余弦相似度太大,我们引入了一个基于文本蕴涵的更严格的准则。 为了实现这一点,我们使用了一个语言模型,明确地训练自然语言推理(NLI)任务评估句子之间的逻辑联系。 中心思想是为每个替换词sc计算一个分数,该分数量化了原始句子s及其包含sc的变体s’的文本蕴涵。 文本蕴涵是文本片断之间的一种方向性关系,当一个文本片断的真理从另一个文本中得到时,这种关系就成立了。 引申语篇和被引申语篇分别称为前提§和假设(H)。 P和H之间的关系可以是蕴涵关系、矛盾关系或中性关系(既非蕴涵关系也非矛盾关系)。 在p和h相互包含的范围内,它们被认为是等价的。 3 Roberta-Large-MNLI是一个Roberta-Large-MNLI模型,在多体裁自然语言推理语料库上使用一个掩码语言建模目标(Williams et al.,2018)进行优化(Williams et al.,2018)。 蕴涵得分定义为p蕴涵H的概率:

其中θ为训练Robertalarge-MNLI的参数。 我们将两个句子的等价程度(等价分数)量化为两个方向的蕴涵分数的乘积。 对于给定的句子S和对应的简化句子S’,等价得分定义为:
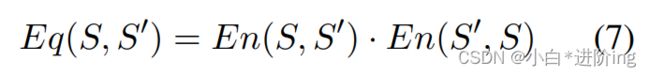
除了在Mantis_2和Mantis_3的替换排序中使用它们之外,在Mantis_1的后处理步骤中也使用等效分数:这里,通过删除等效分数小于所有候选人平均等效分数的候选词,在排序后修剪替换候选列表。
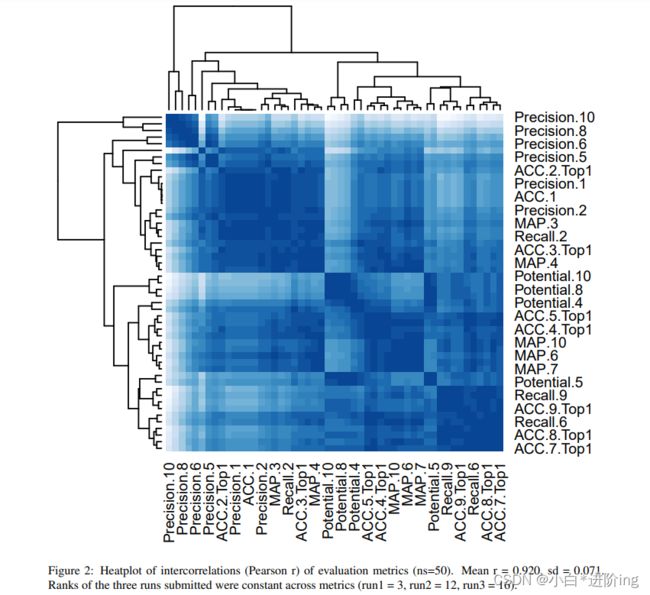
3 End-to-end System Performance
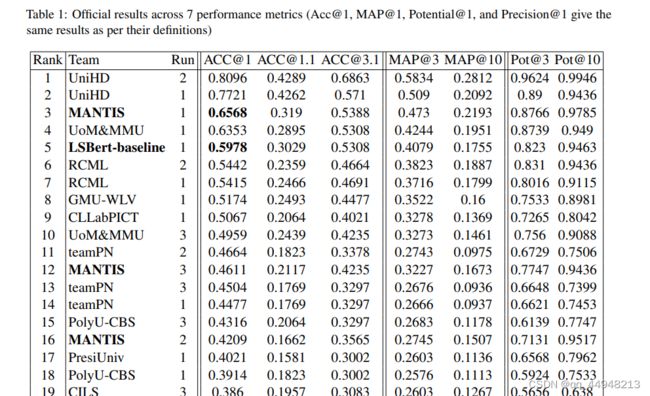
七个性能指标4的正式结果载于附录表1(详情见Saggion et al.(2022))。 由于性能指标之间存在很强的相关性(所有指标的平均相关性=0.920,SD=0.071,参见附录中的图2),所以我们在这里的讨论集中在以下三组中每组的一个指标的结果上:(1)精确度1,(2)Map.10和(3)潜力.10(参见图1)。 我们最好的系统是’Mantis_1’。 该系统在Map.10和Potential.10上都达到了第2级,在精度上达到了第3级。 Mantis_1在精确度上比中位数提高了+25.56%,+24.13%的电位10和+9.93%的地图10。 它比LSbert基线高出+5.9%的精确度、+4.38Map.10和3.49%的潜在性。 这两个系统的替代排名完全基于词的流行率和等价分数落后于LSBERT基线,这表明我们的系统对LSBERT的改进主要是由于更好的替代排名,而不是候选选择。 然而,Mantis2在电位。10指标上优于LSbert,表明包含词的流行率可以有效地用于改进LS系统。 F:在今后的工作中,我们打算探讨这些和其他的词汇复杂度指标在替代排序中的作用。
References1
Marc Brysbaert, Paweł Mandera, Samantha F McCormick, and Emmanuel Keuleers. 2019. Word prevalence norms for 62,000 english lemmas. Behavior research methods, 51(2):467–479.
Mark Davies. 2008. The Corpus of Contemporary American English (COCA): 560 million words, 1990-present.
Brendan T Johns, Melody Dye, and Michael N Jones. 2020. Estimating the prevalence and diversity of words in written language. Quarterly Journal ofExperimental Psychology, 73(6):841–855.
Elma Kerz, Yu Qiao, Sourabh Zanwar, and Daniel Wiechmann. 2022. Pushing on personality detection from verbal behavior: A transformer meets text contours of psycholinguistic features. In Proceedings of the 12th Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis, pages 182–194, Dublin, Ireland. Association for Computational Linguistics.
Joo-Kyung Kim, Gokhan Tur, Asli Celikyilmaz, Bin Cao, and Ye-Yi Wang. 2016. Intent detection using semantically enriched word embeddings. In 2016 IEEE spoken language technology workshop (SLT), pages 414–419. IEEE.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
Christopher D Manning, Mihai Surdeanu, John Bauer, Jenny Rose Finkel, Steven Bethard, and David McClosky. 2014. The stanford corenlp natural language processing toolkit. In Proceedings of 52nd annual meeting ofthe association for computational linguistics: system demonstrations, pages 55–60.
Gustavo Paetzold and Lucia Specia. 2017a. Lexical simplification with neural ranking. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pages 34–40.
Gustavo H Paetzold and Lucia Specia. 2017b. A survey on lexical simplification. Journal of Artificial Intelligence Research, 60:549–593.
Jipeng Qiang, Yun Li, Yi Zhu, Yunhao Yuan, Yang Shi, and Xindong Wu. 2021. Lsbert: Lexical simplification based on bert. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3064– 3076.
Jipeng Qiang, Yun Li, Yi Zhu, Yunhao Yuan, and Xindong Wu. 2020. Lexical simplification with pretrained encoders. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8649–8656.
Horacio Saggion, Sanja Štajner, Daniel Ferrés, Kim Cheng Sheang, Matthew Shardlow, Kai North, and Marcos Zampieri. 2022. Findings of the tsar2022 shared task on multilingual lexical simplification. In Proceedings ofTSAR workshop held in conjunction with EMNLP 2022.
Matthew Shardlow. 2014. A survey of automated text simplification. International Journal of Advanced Computer Science and Applications, 4(1):58–70.
Sanja Štajner. 2021. Automatic text simplification for social good: Progress and challenges. Findings of the Association for Computational Linguistics: ACLIJCNLP 2021, pages 2637–2652.
Sanja Štajner, Daniel Ferrés, Matthew Shardlow, Kai North, Marcos Zampieri, and Horacio Saggion. 2022. Lexical simplification benchmarks for English, Portuguese, and Spanish. Frontiers in Artificial Intelligence, 5.
Daniel Wiechmann, Yu Qiao, Elma Kerz, and Justus Mattern. 2022. Measuring the impact of (psycho-) linguistic and readability features and their spill over effects on the prediction of eye movement patterns. arXiv preprint arXiv:2203.08085.
Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122. Association for Computational Linguistics.
自结
总的来说本文基于Qiang(2020)(2021)的工作进行扩展。贡献如下:(1)词语简化模型调整为Roberta模型,候选词扩为30个(2)替换词排序,引入新的特征加权方案Cf+WP(单词流行率)+Eq(等效分数)。替代排名有效改进LS系统,WP也可以改进LS系统,有待进一步研究。
扬州大学研一在读学生,本篇笔记仅以帮助自己更好理解论文,也方便日后复查学习。 ↩︎