RLChina强化学习笔记
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、机器学习
- 二、深度学习
- 二、机器学习中的优化理论和方法
-
- 2.1 优化算法
- 2.2 收敛性分析
- 2.3 图形模型与贝叶斯推理
- 2.4 贝叶斯优化
- 三、博弈论
-
- 3.1 Motivation and Normal-form Game
- 3.2 Extensive-form Game and Imperfect Information
- 3.3 Bayesian Game and Incomplete information
- 3.4 Nash Equiliburing
- 3.4 Repeat Game and Learning Methods
- 3.5交替解概念与演化博弈理论
- 四、机制设计与博弈复杂度
-
- 4.1 机制设计
- 4.2 博弈复杂性
- 五、强化学习
-
- 5.1 强化学习的值函数和策略方法
-
- 5.1.1 强化学习
- 5.1.2 MDP
- 5.1.4 值函数估计
- 5.1.5 无模型控制方法
- 5.2 规划与马尔科夫过程
- 5.3 在线强化学习中的样本效率
- 5.4 概率强化学习和贝叶斯大脑
-
- 5.4.1 learning in biological and computerised systems
- 5.5 离线强化学习
- 5.6 模仿学习
- 六、多智能体学习
-
- 6.1 算法博弈论:
- 6.2 智能体策略的学习和评估
- 6.3 多智能体强化学习算法
-
- 6.3.1 多智能体协作决策
- 6.3.2 多智能体挑战
- 6.3.3 非线性值分解
- 6.3.4
- 6.3.5 summary
- 6.4 平均场理论的多智能体起强化学习
-
- 6.4.1 平均场原理近似非协作游戏
- 6.4.2 平均场原理近似协作游戏
- 6.5 捉迷藏游戏策略和开放问题
- 6.6 深度学习求解大规模复杂博弈
- 七、专题报告
-
- 7.1 专题报告(一)强化学习训练系统
-
- 7.1.1 深度学习时代下的机器学习系统
- 7.1.2 深度(分布式)强化学习系统
- 7.1.3 多智能体学习系统的额外挑战
- 7.1.4 面向基于种群多智能体强化学习的并行训练框架
- 7.2 多智能体通信与协同中的博弈论与强化学习
-
- 7.2.1 Role of informats in security games
- 7.2.4 food rescue patform
- 7.3 强化学习和游戏AI:技术演进&商业价值探讨
- 7.4 深度强化学习的挑战和落地
-
- 7.4.2
- 7.3
- 7.4 应用:
前言
此篇主要记录RLChina强化学习的学习过程,如有错误,请不吝赐教。
一、机器学习
ANN网络?
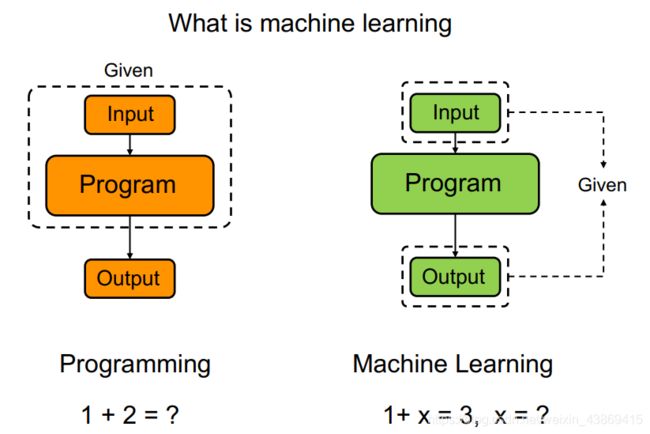
编程与机器学习的区别:
机器学习的整体流程:
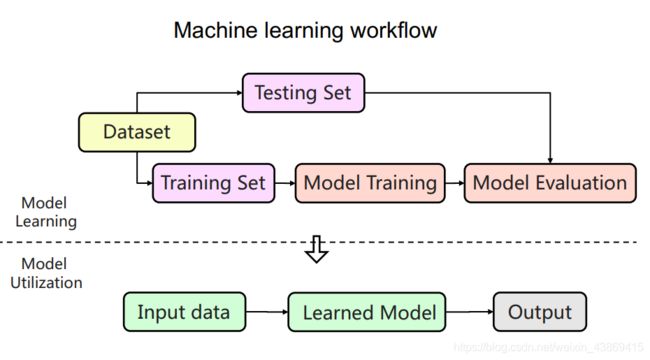 模型训练:模型选择和参数学习
模型训练:模型选择和参数学习
选择模型:
1.根据经验来选取
2.学习策略来选取
(贝叶斯模型选择,贝叶斯优化)
参数学习:
梯度下降(full,batch,stochastic)
模型评估:
1.人类评估(问卷,用户使用)
2.评估参数/指标 (F1,precision,recall,RMSE,MAE)
3.用其他模型来评估
监督学习:
回归问题(连续),分类问题(离散)
非监督学习:
聚类问题
回归问题:
1.线性回归
主要评估的指标:
 分类问题
分类问题
1.最近邻算法(启发式)
选择一个节点的k个邻居,然后来判断新的节点的标签。
距离函数:
 k值的选择(一般3-5)
k值的选择(一般3-5)
预测:
1.投票:
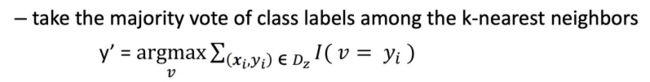 2.带权重的投票:
2.带权重的投票:
距离越小,权重越大

数据:
PAC learning ( probably approximate correct)
选择多少的数据量能够较好的反应真实的数据
定理:
 求n方法:
求n方法:
 (h能完美拟合dataset D)
(h能完美拟合dataset D)
 (完美拟合的假设h组成集合)
(完美拟合的假设h组成集合)
 (认为在SHD中的假设的train error较小,且true error 较小)
(认为在SHD中的假设的train error较小,且true error 较小)

通过学习得到的H不满足shd的概率小与|H|e…
当这个概率小与 时就能得到上述结论,
此时的m也就为对应的数据量。
补充,上述推导如下:

二、深度学习
neural networks

(可用于监督学习与非监督学习)
常用激活函数:
 DNN
DNN
RNN
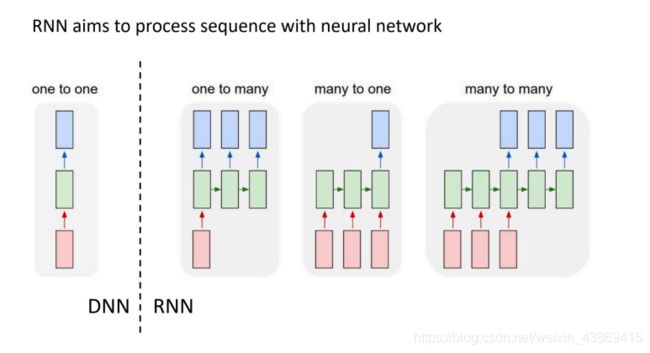
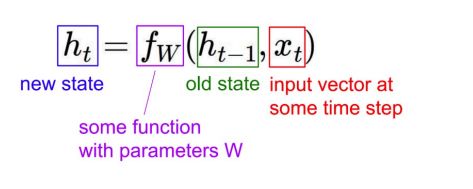
例子:LSTM
例子:GRU
补充: 独立同分布: 前后采样无干扰。
二、机器学习中的优化理论和方法
机器学习理论:

(泛化,函数类的表示能力,优化算法)
2.1 优化算法
连续优化问题:
 优化算法分类:
优化算法分类:
0th order(一个点一个点去尝试,只用到function val):griding ,Sampling
易于实现但是运行缓慢
1th order(用到gradient和function val)SGD,Adagrad,ADAM
具体如下:
与backprop配合得很好
 Higher Order:牛顿法
Higher Order:牛顿法
大量计算,在低维度的问题上表现良好,且收敛更快
2.2 收敛性分析
1.SGD:
非凸函数
度量收敛:
分析算法收敛的步骤:
图模型降低计算复杂度
分析优化的主要:

补充: 对于经验风险最小化,理论上更快设计了算法(如SAG、SAGA、SVRG、Spider)。但是实际性能与预期有一定差距。
2.3 图形模型与贝叶斯推理
图形模型描述联合分布中的结构(稀疏性、独立性、分区)

主要分为以下两类:
1.undirected graph
2.directed graph
MCMC Algorithm(?)
 可能得到概率小的对应主题
可能得到概率小的对应主题
2.4 贝叶斯优化
设置:
•假设f(x)是从高斯过程中采样的。
•我们希望找到仅使用有限函数使f(x)最大化的x价值呼叫。
通过迭代寻找观测点来不断最大化fx。
其观测点为有着最大提升希望的点。
详细流程:
 如何找到这个最有希望的点?
如何找到这个最有希望的点?
1.根据最有可能提升的点来选择
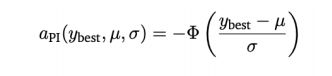 2.提升最多的点
2.提升最多的点
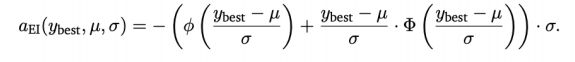 对于贝叶斯优化的子过程:
对于贝叶斯优化的子过程:
我们考虑在每一步中进行优化,利用梯度下降和重复初始化来完成
补充:考虑到子过程的存在,贝叶斯优化的复杂性有以下两个方面:
1.取样复杂性(query number)
2.计算复杂性(查询数子过程计算的成本) 在最坏情况下会受到维度灾难的影响。
参考书籍: introduce to convex optimization
三、博弈论
3.1 Motivation and Normal-form Game
单回合,多回合
有无隐藏信息
 (玩家,策略,收益)
(玩家,策略,收益)
正则化表示:
 博弈论中假设玩家具有理性。(追求自己的利益)
博弈论中假设玩家具有理性。(追求自己的利益)
纯策略和混合策略
纯策略(以100%选择其中一个动作)
混合策略(以一定概率选择一个动作)
一些经典博弈:

3.2 Extensive-form Game and Imperfect Information
博弈树:
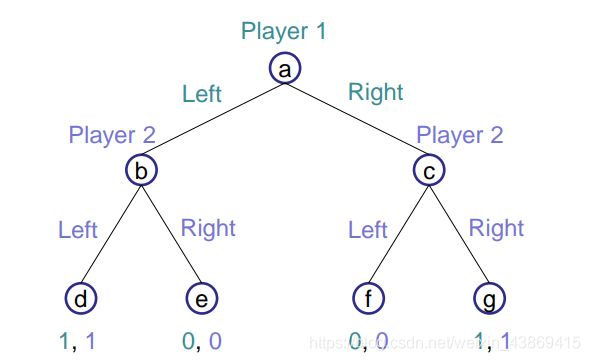 两个玩家先后做选择。
两个玩家先后做选择。
叶节点为玩家所得收益。
决策空间:
 对应的正则式表达:
对应的正则式表达:

不完美信息
认为某些玩家的历史动作不可见(非完美)
此时产生信息集
如下例子:
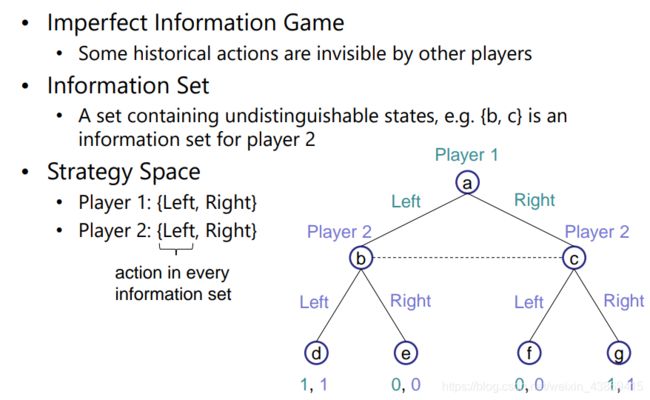 (b,c)信息集
(b,c)信息集
Markov Game
状态可重复到达,每个状态下都可得到reward
如下图:
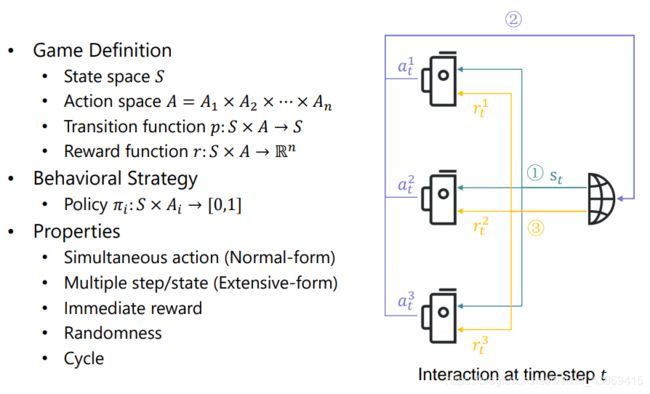 行为策略。(给定状态随机选择动作)
行为策略。(给定状态随机选择动作)
总结:

3.3 Bayesian Game and Incomplete information
非完全信息具体定义:

贝叶斯博弈:
 知道用户的类型的种类,且知道type的概率。
知道用户的类型的种类,且知道type的概率。
动态贝叶斯博弈:
类似于非完美信息的拓展。
 玩家以知道自已以一定概率处于某个状态。
玩家以知道自已以一定概率处于某个状态。
总结:

不完全:开始信息不完全可见
不完美:历史行为不可见
Harsanyi 转换:
将非完全信息转换为非完美信息
引入一个上帝玩家去确定开局的所有信息(将这个决定认为是一个玩家的动作),此时就转为了不完美信息。
3.4 Nash Equiliburing
最佳应对策略:在给定其他玩家的决策时,对于自己最好的策略。
占优策略:对于任何其他人的决策都是对自己而言最好的
例如:
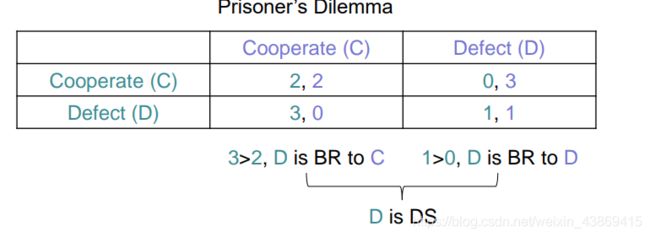 NASH均衡:
NASH均衡:
对于每个玩家都没有动力去改变自己的策略。
Pareto Optimality Nash Equilibrium 两者无关系。
Pareto Optimality(没有一个点使得所有人都至少不变差)
混合策略的Nash均衡
例如:

扩展式博弈的Nash均衡:
不可置信的威胁
例如:
此时玩家2会说谎也提高自己的收益

子博弈Nash均衡:
对于决策,在所有的子博弈中都是Nash均衡
贝叶斯博弈Nash平衡:
定义类似于普通的Nash均衡。
动态贝叶斯博弈Nash均衡(完美贝叶斯均衡):
添加了一个对于状态的概率(考虑信息集)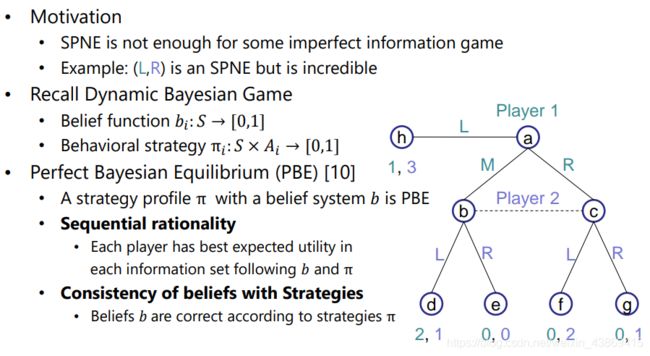 总结:
总结:

3.4 Repeat Game and Learning Methods
Repeat game :重复玩游戏。(学习过程)
记忆
不同的策略:
1.tit-for-tat
2.Win-stay,lost-shift
Folk Theorem(多记忆的情况下)
所有的取值都可以在某个Nash均衡得到。
Fictitious Play(应对Folk Theorem)
认为对手的下一个动作符合历史动作的概率分布。
如果所以都采用该策略,那么会收敛到Nash均衡
No-regret Learning
举例:
对于之前的历史,如果全部采用某个动作,那么会得到更好的收益,此时就会后悔,对于下一个操作就会采取后悔值最高的动作。
3.5交替解概念与演化博弈理论
Stackelberg Equilibrium:
又先后顺序。(分先后得到更好的收益)(协同)
Correlated Equilibrium:
例如:

演化博弈论(?)
策略是与生俱来的,玩家不能自己选择策略
高回报的玩家有更多的机会被复制
补充:如果种群中几乎每一个成员都遵循一种策略,那么没有突变体(即采用新策略的个体)能够成功入侵
总结:

四、机制设计与博弈复杂度
4.1 机制设计
考虑如何与战略参与者一起设计系统并且有良好的性能保证。
例子:单物品拍卖问题
模型如下:

private value vi是每个人私有的。
拍卖形式如下:

不同的机制
1.first-price

2.second-price
 可知无论如何,用户给出心里的价格能够得到最大化的预期收益。
可知无论如何,用户给出心里的价格能够得到最大化的预期收益。
DSIC
如果真实竞价始终占主导地位,则拍卖为DSIC
对于每个投标人的策略,它可以帮助他们获得非负效用。

可知second-price是理想的。
1.计算效率高
2.是DSIC的
3.社会福利最高
例2:

GSP策略:

不是一个Trufulness
例子如下:
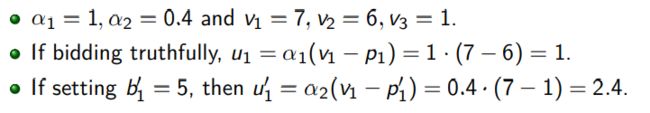
可知非诚信会获得更高的收获。
组合拍卖:
VCG Mechanism(?)
每个一般环境都有一个属于DSIC的福利最大化机制
4.2 博弈复杂性

 上述算法都不是p算法。
上述算法都不是p算法。
FNP:搜索解。且能在多项式内检查。
TFNP:对于所有的问题都存在一个解。

问题:END-OF-A-LINE
在电路中每个点的出度入度最多为1,给定起始点,我们需要找到出度入度不等的点。
(该问题一定有解,所以属于TFNP)
我们认为能够归约到上述问题的问题称为PPAD。
(end-of-a-line 归约到二人博弈Nash平衡求解问题)
证明步骤如下:
 部分步骤证明:
部分步骤证明:
1.变为平面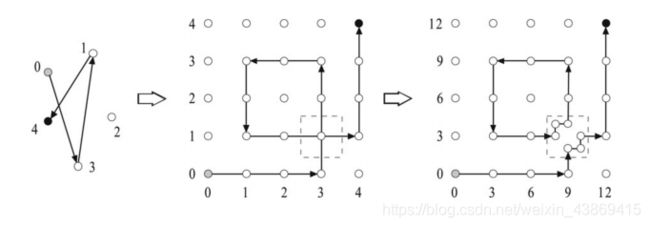 我们将其放到平面上,我们通过改造来使其不交叉。
我们将其放到平面上,我们通过改造来使其不交叉。
2.改为找Banachi不动点问题
4…Generalized circuits
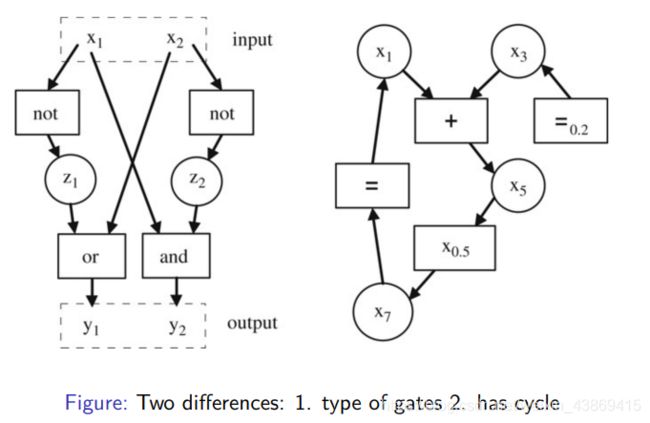 4.我们要通过博弈来表示每一个门
4.我们要通过博弈来表示每一个门
5.组成大的电路后归约完成。
证明参考文献:
1Chen, X. and Deng, X., 2007. Recent development in computational
complexity characterization of Nash equilibrium. Computer Science Review,1(2), pp.88-99.
参考文献:
1 Algorithmic Game Theory
2 Twenty Lectures on Algorithmic Game Theory
总结:

了解部分:

五、强化学习
5.1 强化学习的值函数和策略方法
5.1.1 强化学习
 决策亲自改变世界
决策亲自改变世界
预测辅助别人改变世界
只要是序列决策问题都能用强化学习求解。
可知有监督。无监督学习在一个固定的数据集
强化学习根据不同的智能体(agent)会得到不同的数据集
5.1.2 MDP
MP:下一个状态只取决于当前的状态。
(当前状态是未来的充分统计量)
MDP:受制于决策者的控制。
 MDP:
MDP:
1.环境完全可观测
2.当前状态可以完全表征过程
MDP表示:




刻画了策略的改变导致对应的占用率的改变即数据的改变。
随着t的增长,在状态s取得动作a的累计概率


分母是访问到的s的概率,分子是访问sa的概率
具体推道:

 (加权不为1)
(加权不为1)



对于价值迭代:
 当vs不变化时收敛(更新过程不对应任何策略,只有收敛才对应一个策略)
当vs不变化时收敛(更新过程不对应任何策略,只有收敛才对应一个策略)
策略迭代:
 总结:
总结:

5.1.4 值函数估计
上述部分实际是动态规划。
模型无关的强化学习:


蒙特卡洛方法(MC):(大数定律,不断逼近真实值)

 (经验均值累计奖励)
(经验均值累计奖励)
具体:
 (不断采样轨迹)
(不断采样轨迹)
 这里可以增量更新:
这里可以增量更新:
 时序查分学习:
时序查分学习:


(MC 需要到结束位置才能更新,td看到一步奖励就可以更新)
例子:



即td是不完美更新(所以是有偏差)
而mc是多步随机,所以导致他的方差较大。
5.1.5 无模型控制方法
动作值函数Q
 即无模型没有P概率转移矩阵,此时需要动作来控制转移。
即无模型没有P概率转移矩阵,此时需要动作来控制转移。
SARSA算法:
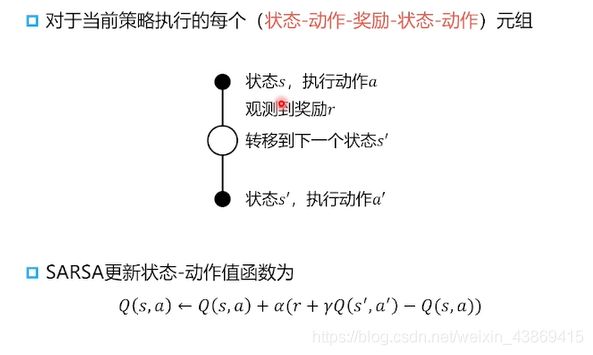 公式:增量更新动作价值函数。
公式:增量更新动作价值函数。
伪代码:

Qlearning:(off-policy)

 借助老数据来进行更新。他要求得到一个四元组,他就不需要重采样来更新了(用老的policy来选择,而不是当前的策略policy)。
借助老数据来进行更新。他要求得到一个四元组,他就不需要重采样来更新了(用老的policy来选择,而不是当前的策略policy)。
5.2 规划与马尔科夫过程
多臂老虎机问题:
简单方法:
对于每个armi进行n次测试得到期望值。
证明公式:
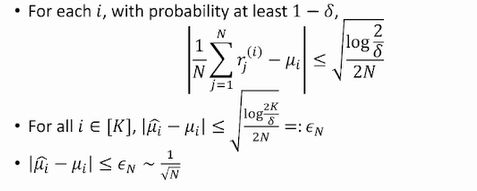 误差小于某个值。N越大,误差越小。
误差小于某个值。N越大,误差越小。
可得估计得到的最大期望与真实最大期望的差:
 可以通过历史信息来选择下一次的决策(老虎机中发现某个arm非常差,那么就不需要再选择这个)(局部最优)
可以通过历史信息来选择下一次的决策(老虎机中发现某个arm非常差,那么就不需要再选择这个)(局部最优)
避免局部最优:1。s-greedy
2.置信上限
Regret:懊悔值
 期望(最好的决策-选择的决策)
期望(最好的决策-选择的决策)
详见强化笔记(二)
马尔科夫过程多状态
未来有效的步数
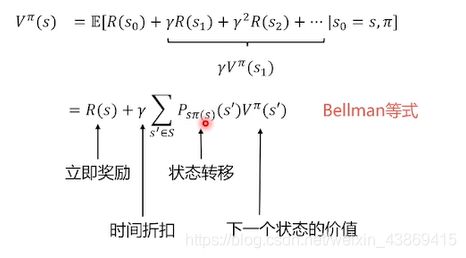
 价值函数:
价值函数:
![]()
 (矩阵计算)
(矩阵计算)
Policy:Stationary Policy
Policy+MDP=MRP

对于最优策略:
 最优策略:
最优策略:

MDP变种:
 衰减为1,同时定义行动次数。
衰减为1,同时定义行动次数。
此时得到的policy 不一定是最优策略,需要考虑步数。
补充:
 Generative Model
Generative Model
可是从任何一个状态动作开始,对应的p矩阵未知。
可以通过模拟去训练。
样本复杂度:
算法1:
 分析:
分析:
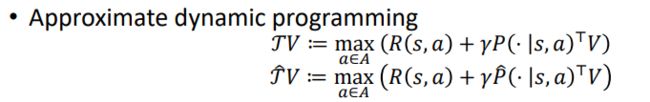
得到对应的误差:

可知要误差较小时,样本量应该为如下:
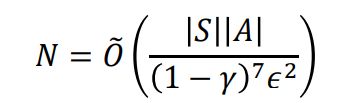
最新结论:
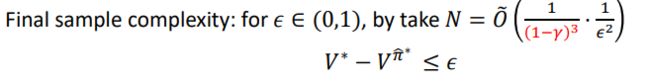 下界:由于下界为如下:
下界:由于下界为如下:

补充:model对于找到一个好的policy是具有冗余的。
参考文献:
Yang, L., & Wang, M. (2019, May). Sample-optimal parametric Q-learning using linearly additive features. In International Conference on Machine Learning (pp. 6995-7004). PMLR.
• Jin, C., Yang, Z., Wang, Z., & Jordan, M. I. (2020, July). Provably efficient reinforcement learning with linear function approximation. In Conference on Learning Theory (pp. 2137-2143).
PMLR.
• Cai, Q., Yang, Z., Jin, C., & Wang, Z. (2020, November). Provably efficient exploration in policy optimization. In International Conference on Machine Learning (pp. 1283-1294). PMLR.
• Du, S. S., Kakade, S. M., Wang, R., & Yang, L. F. (2019). Is a good representation sufficient for sample efficient reinforcement learning?. arXiv preprint arXiv:1910.03016.
• Lattimore, T., Szepesvari, C., & Weisz, G. (2020, November). Learning with good feature representations in bandits and in rl with a generative model. In International Conference on
Machine Learning (pp. 5662-5670). PMLR.
• Duan, Y., Jia, Z., & Wang, M. (2020, November). Minimax-optimal off-policy evaluation with linear function approximation. In International Conference on Machine Learning (pp. 2701-
2709). PMLR.
• Zhou, D., He, J., & Gu, Q. (2021, July). Provably efficient reinforcement learning for discounted mdps with feature mapping. In International Conference on Machine Learning (pp.
12793-12802). PMLR.
• Agarwal, A., Kakade, S., Krishnamurthy, A., & Sun, W. (2020). Flambe: Structural complexity and representation learning of low rank mdps. arXiv preprint arXiv:2006.10814.
• Modi, A., Jiang, N., Tewari, A., & Singh, S. (2020, June). Sample complexity of reinforcement learning using linearly combined model ensembles. In International Conference on Artificial
Intelligence and Statistics (pp. 2010-2020). PMLR.
• Zhang, Z., Ji, X., & Du, S. S. (2021). Is reinforcement learning more difficult than bandits? a near-optimal algorithm escaping the curse of horizon. Proceedings of Machine Learning
Research vol, 134, 1-28.
• Agarwal, A., Kakade, S. M., Lee, J. D., & Mahajan, G. (2021). On the theory of policy gradient methods: Optimality, approximation, and distribution shift. Journal of Machine Learning
Research, 22(98), 1-76.
• Wang, R., Salakhutdinov, R., & Yang, L. F. (2020). Reinforcement learning with general value function approximation: Provably efficient approach via bounded eluder dimension. arXiv
preprint arXiv:2005.10804.
• Wang, R., Du, S. S., Yang, L. F., & Salakhutdinov, R. (2020). On reward-free reinforcement learning with linear function approximation. arXiv preprint arXiv:2006.11274.
• Kong, D., Salakhutdinov, R., Wang, R., & Yang, L. F. (2021). Online Sub-Sampling for Reinforcement Learning with General Function Approximation. arXiv preprint arXiv:2106.07203.
• Feng, Fei, et al. “Provably correct optimization and exploration with non-linear policies.” arXiv preprint arXiv:2103.11559 (2021).
5.3 在线强化学习中的样本效率
动机:深度强化学习中的样本复杂性挑战
深度RL中的挑战:
1.需要庞大的数据
2.大量的计算
可证明有效的RL算法
样本效率:需要多少数据点?
计算效率:需要多少计算?
函数近似:允许无穷多的观测值?
背景:
片段马尔科夫决策过程(建模稀疏reward):
agent 与环境的交互为H有限步。
策略对于每个h都不同:故而有H个策略
具体如下:
 例子上下文老虎机:
例子上下文老虎机:
H=1
具体如下:

1.生成状态(Generative model)
能够查询reward,状态,对于任意的s,a对
2.offline setting
只依赖于数据来找到最优策略(不需要交互)
3.online setting:
通过环境交互来得到最优策略。(考虑T次交互即T次轨迹,每次轨迹为H步)
 最快找到最优策略。
最快找到最优策略。
 忏悔(regret)刻画样本复杂性
忏悔(regret)刻画样本复杂性
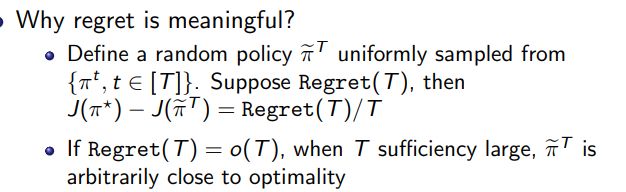

 刻画不确定性,确定乐观估计来执行动作可以平衡探索和利用。
刻画不确定性,确定乐观估计来执行动作可以平衡探索和利用。
岭回归(ridge regression)?
LinUCB algorithm:
 相关复杂度:
相关复杂度:


Deep Exploration
函数逼近最优策略。
线性假设。

另一种假设(贝尔曼算子):
 算法
算法
LSVI-UCB

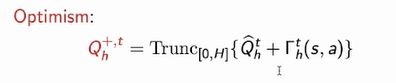 相应的复杂度:
相应的复杂度:
时间和空间与状态无关。
可证明该算法的regret为如下:

总结:
LSVI-UCB 线性回归来实现价值迭代。
通过不确定性分析与Bonus来平衡探索和利用。
(将不确定性以较大的h步向后传播到1)
它是样本有效和多项式可解的优势函数逼近在线RL。
补充:
on-policy off-policy 估计与评估的policy是否是同一个 但两者都是off line
5.4 概率强化学习和贝叶斯大脑
5.4.1 learning in biological and computerised systems
输入信息导致商检
qs表示自己去估计,逼近感知
preference 是外界给的
5.5 离线强化学习
在线学习(On-line RL)
1.off policy
对于采样的到的数据放入到buffer中,能够再度学习使用。
2.on-policy
对于采样得到的数据学习后丢弃。
在这里插入图片描述
离线学习:只在数据上进行学习。

可以通过监督学习来学习policy(丢掉奖励),但offline rl能够比监督学习更好。
强化学习可以组合好的action。
直接使用离线学习会导致如下问题:
1.对于Q函数的overestimated
2.对于数据量的增大表现并未更好
对于不出现在数据中的点那么会有可能过高估计。
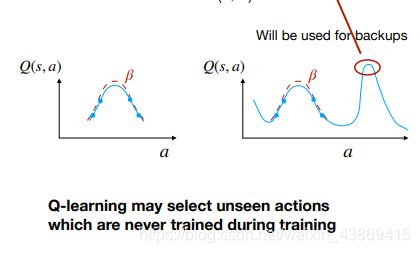 (如果预估的动作未出现在对应的训练的数据中,就有可能出现过高估计)
(如果预估的动作未出现在对应的训练的数据中,就有可能出现过高估计)
在在线学习中,这个问题也会发生,但是探索会一定程度解决这个问题。
对于离线学习:
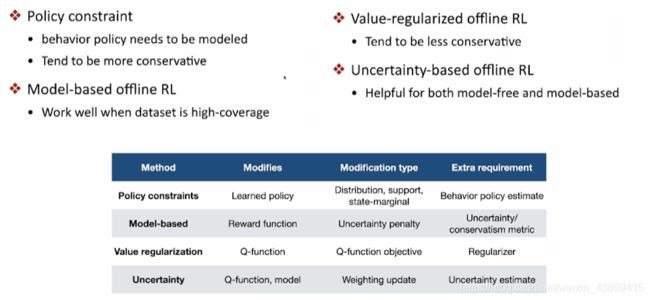
1.解决:policy constraint(避免那些未曾见过的可能过高估计的点)
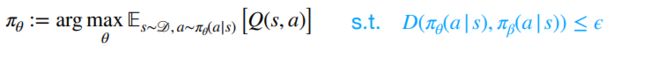

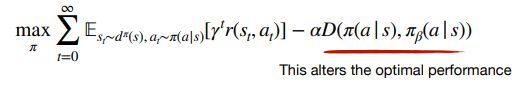 相关效果:
相关效果:

policy constraint 缺点:

由于policy constraint 通过避免。。。,但这会导致学习效率的降低。
另一种方式针对OverEstimate
conservative methods
他有两种实现方式:基于模型和模型无关
基于model:
可以对于未学习的区域进行reward的修改。以鼓励在区域内学习。
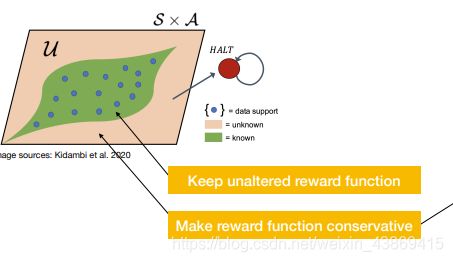
 一些具体实现:
一些具体实现:

其他方法:
function regularization
 CQL希望提高见过动作的价值,降低其他的。(过保守)
CQL希望提高见过动作的价值,降低其他的。(过保守)
进行修改:

 在r上加一个正则化。
在r上加一个正则化。
![]()
Model Free offLine RL
1.Random Ensemble Mixture

2.Monto Carl dropout

总结:
多智能体 离线学习:

参考文献:
Levine, Kumar, Tucker, Fu (2020). Offline Reinforcement Learning: Tutorial, Survey and Perspectives on Open Problems
• Kumar et al. (2019) Stabilizing Off-Policy Reinforcement Learning via Bootstrapping Error Reduction. NeurIPS 2019
• Fujimoto et al. (2019) Off-Policy Reinforcement Learning without Exploration. ICML 2019
• Wu et al. (2019). Behavior Regularized Offline Reinforcement Learning
• Peng et al. (2019). Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
• Nachum and Dai (2019) Reinforcement Learning via Fenchel-Rockafeller Duality
• Wang et al. (2020). Critic-regularized Regression. NeurIPS 2020
• Kidambi et al. (2020) MOReL: Model-Based Offline Reinforcement Learning. NeurIPS 2020.
• Yu et al. (2020) MOPO: Model-based Offline Policy Optimization. NeurIPS 2020.
• Kumar et al. (2020) Conservative Q-Learning for Offline RL. NeurIPS 2020.
• Yu et al. (2021) COMBO: Conservative Offline Model-Based Policy Optimization
• Agarwal et al. (2020) An Optimistic Perspective on Offline Reinforcement Learning, ICML 2020
• Wu et al. (2021) Uncertainty Weighted Actor-Critic for Offline Reinforcement Learning, ICML 2021
• Fu et al. D4RL: Datasets for Deep Data-Driven RL.
• Jiang and Lu (2021), Offline Decentralized Multi-Agent Reinforcement Learning.
5.6 模仿学习

监督学习:训练数据分布与现实数据独立同分布。(泛化效果)
无监督学习:
自监督学习:
将自己的输入作为样本输出。?
消减对于环境的交互(问题)快速学习
行为克隆(behavior cloning):
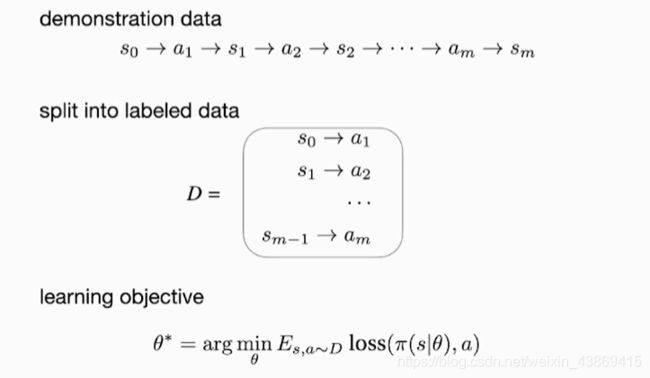 转换数据为有标签。(动作为专家给与)
转换数据为有标签。(动作为专家给与)
例子:


此时误差为泛化误差
走固定步数T时


如果是带折扣的无穷多步:


在最坏情况下就是(无法与环境进行交互)

算法
DAgger:

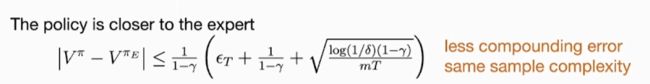

考虑专家的reward函数。



3.拷贝分布


六、多智能体学习
资源:

6.1 算法博弈论:
计算均衡点
在有限个玩家,nash均衡一定存在。
双人零和博弈:
可用动态规划求解。
Fitctitious Play:

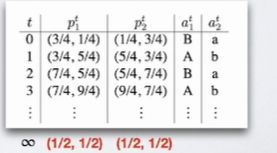

Double Oracle
别人玩过的策略,算一个小的子问题的Nash均衡。

Policy Space Response Oracle
Lemke-Howson Method

![]()
 打上标签是为了验证属于哪一种情况。
打上标签是为了验证属于哪一种情况。
下标为player,上标为action
然后找能够覆盖所有标签的点。这就是Nash均衡点。
Potential Games
![]() Harmonic Game=零和博弈
Harmonic Game=零和博弈
![]()

两种方法的对比:

6.2 智能体策略的学习和评估
 (多个玩家做决策,动作和奖励依赖其他的动作)
(多个玩家做决策,动作和奖励依赖其他的动作)
不同的类型划分:

博弈假设状态转移函数和reward是已知的
Rl只能接受环境给与的状态s
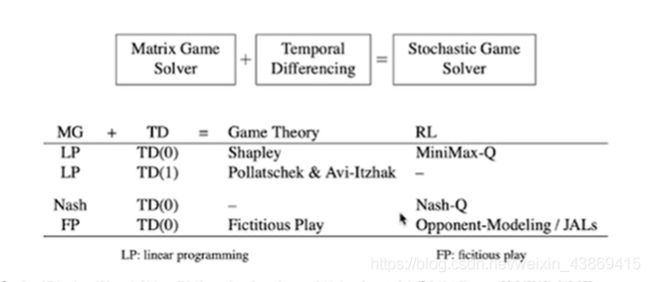
SG:(零和博弈)

在强化学习中:


Nash-Q 多玩家:
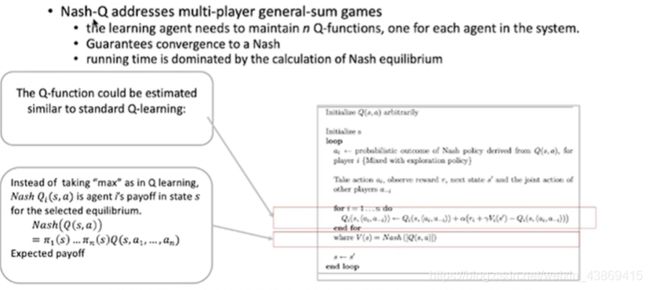 对每个玩家维护一个Q函数
对每个玩家维护一个Q函数
Joint Action learners(JALs)

(在对手的策略取期望下的策略,对于每个玩家都进行策略的估计)
Opponent Modelling:
所有的其他玩家的动作做一个联合的统计。

总结:
 (都是对对手的策略做一个好的response
(都是对对手的策略做一个好的response
OM/JAL是对于对手的策略进行估计
)
评估:

对于多玩家的评估:
Transitive games:
Elo Rating for Chess
思想:


Glicko Rating System
对于胜率预测的修改。
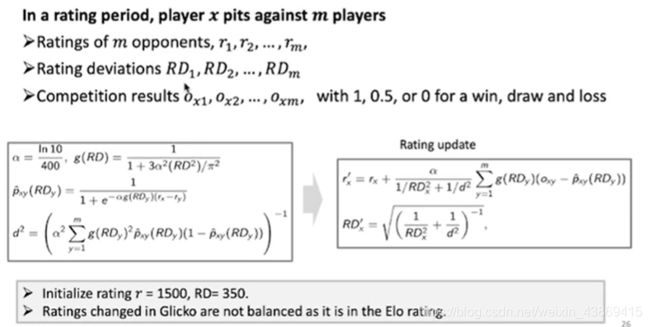 RD:比赛的多样性(控制更新量)
RD:比赛的多样性(控制更新量)
TrueSkill:
 根据比赛结果排序,来学习玩家的Skill
根据比赛结果排序,来学习玩家的Skill
可以处理队伍对队伍的比赛进行学习(更新单个玩家的水平)
在石头剪刀布的游戏中,ELO Rating 无法准确预测胜率。
考虑 Elo rating 的适用性:
![]() 满足
满足
 elo rating适用。
elo rating适用。
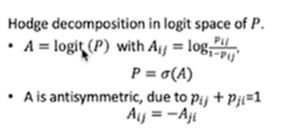
改进后的算法
mElo2k

Nash Averaging:
对于反对称矩阵A的对称Nash策略。
α-rank(多个玩家):

OptEval(考虑采样复杂度)
 想法:
想法:

采样估计:

总结:

6.3 多智能体强化学习算法
(学习在复杂环境中协作)
在大多数情况下智能决策都在多智能体的环境。
多智能体系统分类:
1.协作多智能体
2.竞争多智能体

3.混合

6.3.1 多智能体协作决策
找到一个策略使得团队的收益最大。
模型:

 联合及时回报共用
联合及时回报共用
具体模型:

action为联合动作。
目标找到策略最大化团队报酬。
 通过历史来做决策。
通过历史来做决策。
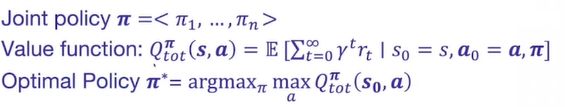 价值:当前状态下基于策略的期望报酬
价值:当前状态下基于策略的期望报酬
策略:最大化系统的期望累计报酬
 (NEXP 难于np)
(NEXP 难于np)
强化学习主要思想如下:

多智能体强化学习:
多智能体之间的交互,协作
6.3.2 多智能体挑战
1.(scalability)智能体的大规模数量
2.(credit assignment)每个智能体对于团体的贡献
3.(Uncertainty)局部和噪声观测
4.(Heterogeneity)智能体的不同策略
5.(Exploration)主体间的协同探索
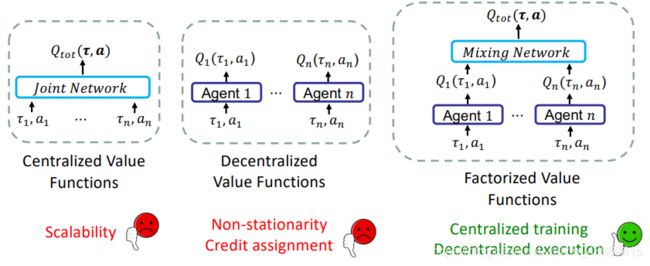 centralize 将多智能体看做一个个体,动作认为一个联合分布。(动作规模大)
centralize 将多智能体看做一个个体,动作认为一个联合分布。(动作规模大)
Decentralized: 将智能体作为一个单体,每个个体学习自己的策略。(受到其他智能体的影响)
Factorized:通过值分解结合前两种的优势
具体如下:
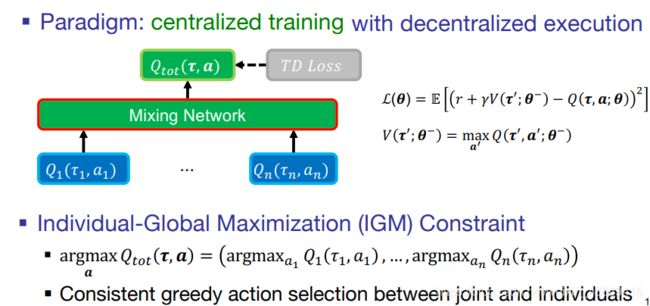 (IGM性质)对于联合价值函数Qmax,就等于对于每个个体的q进行max。(mix network)
(IGM性质)对于联合价值函数Qmax,就等于对于每个个体的q进行max。(mix network)
如何设计 mixing network
1.线性值分解:
 (最大化每个Qi)
(最大化每个Qi)
每个agent的参数可以共享(参数变为单智能体的参数)
对应的credit assignment:
 相当于考虑自己采取当前策略与采取之前策略的差别。
相当于考虑自己采取当前策略与采取之前策略的差别。
引入到Policy Gradient


限制:
1.表达有限(线性函数无法覆盖指数大的空间)
2
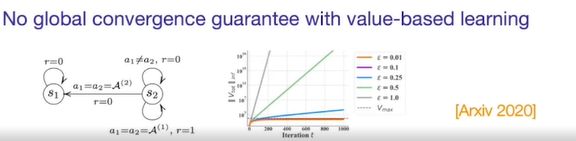
6.3.3 非线性值分解
QPLEX:
主要思想:拟合最大值并补偿其余值
具体:
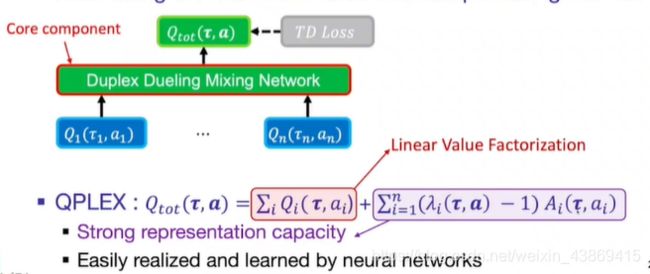 在理论上:
在理论上:

6.3.4
智能体封闭式的学习可能会导致miscoordination
解决方法:Communication
NDQ:


reference:
Wang, T., Wang, J., Zheng, C. and Zhang, C., 2019. Learning nearly decomposable value functions via communication minimization. ICLR 2020
2.Role-based learning
agent的diverse behaviors


当智能体扮演same role时,可以采取相同的behaviors
通过推理对应的agent role来判断是否可以share policy
reference:
[1] Rashid, et. al. QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. (ICML 2018)
[2] Vinyals, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. (Nature 2019)
[3] Baker, et al. Emergent tool use from multi-agent autocurricula. (ICLR 2020)
[4] Lowe, et al. Multi-agent actor-critic for mixed cooperative-competitive environments. (NeurIPS 2017)
6.3.5 summary


6.4 平均场理论的多智能体起强化学习
个体相似时可以考虑使用平均场来减小计算量。
reference:

6.4.1 平均场原理近似非协作游戏
在Agent非常多的时候,可以用model base 方法来解决。
 另一种想法:采用平均场原理
另一种想法:采用平均场原理
决策时个体因素的影响较小。

平均场对于模型的要求:
Nplay的模型:
 1.我们需要假设agent是同分布的。
1.我们需要假设agent是同分布的。
2.play i 有自己的policy
3.通过经验测量,玩家i依赖于其他代理(?)
 可以让相同的agent形成一个group,group之间可以有些许不同。
可以让相同的agent形成一个group,group之间可以有些许不同。
MeanField Game

存在唯一解的条件:

找到NE:
 考虑使用Qlearning是其他的agent不动
考虑使用Qlearning是其他的agent不动
具体如下:

不稳定,不收敛
对应的问题:

收敛的算法 GMFG

参考文献:


6.4.2 平均场原理近似协作游戏
对应的Copperative MARL

central controller(直接用qlearning 计算量非常高)
我们考虑一个更小的MARL模型中
如下:
 平均场的使用条件:
平均场的使用条件:

DPP(Dynamic Programming Principle)

通过贝尔曼方程来设计Q函数


平均场理论对于机器学习:
6.5 捉迷藏游戏策略和开放问题
 考虑得到多样的策略,然后放到intuition中进行模拟评估。
考虑得到多样的策略,然后放到intuition中进行模拟评估。
(Reward Randomization for stag-Hunt)




6.6 深度学习求解大规模复杂博弈
求解Nash

补充:
虚拟遗憾最小化(CFR)
博弈论对于安全性:



七、专题报告
7.1 专题报告(一)强化学习训练系统
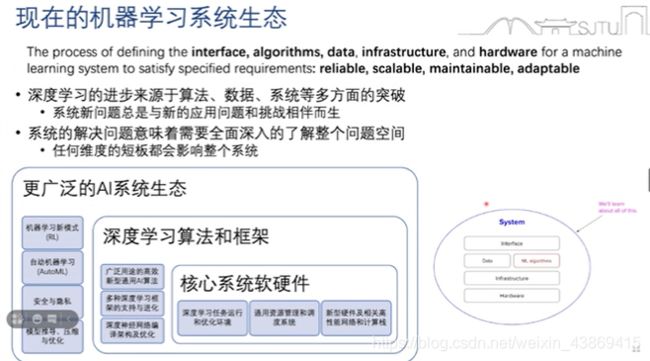
7.1.1 深度学习时代下的机器学习系统
深度学习成功的核心三要素:数据,算法,算力
深度学习+系统的进步:编程语言,优化,计算机体系结构,并行计算和分布式系统

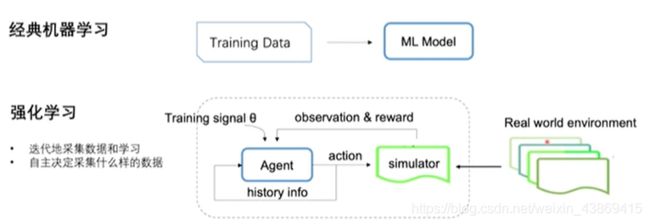 强化学习与机器学习的区别:强化学习需要实时采集数据
强化学习与机器学习的区别:强化学习需要实时采集数据
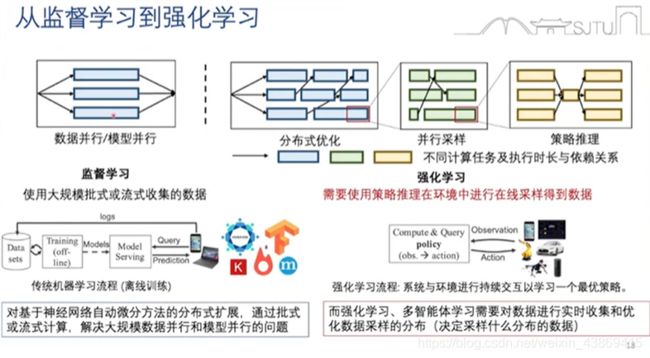

7.1.2 深度(分布式)强化学习系统
为什么需要分布式强化学习:

分布式强化学习:

 其他的分布式强化学习
其他的分布式强化学习
ape-x
R2D3
数据采集效率改进:
数据采集效率是收敛关键。
在强化学习中的数据采样过程:

解决方案:
1.提供复杂环境中的并行采样支持
2.提供简单的分布式采样接口


SeeRL:异构硬件上推理,优化和传输的改进



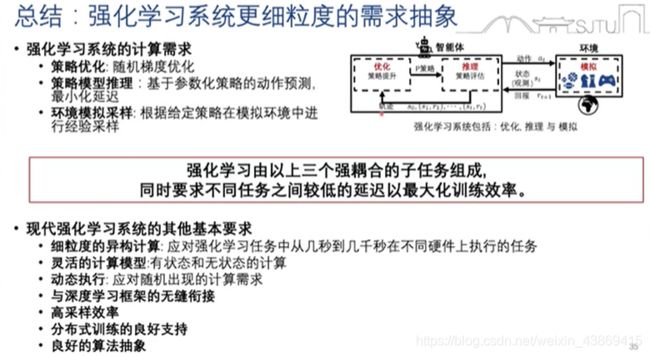
7.1.3 多智能体学习系统的额外挑战
![]() 零和博弈中的非传递性
零和博弈中的非传递性
使用基于种群的续联是提高算法表现和鲁棒性的有效方式(带来额外的复杂性)‘’
具体如下:
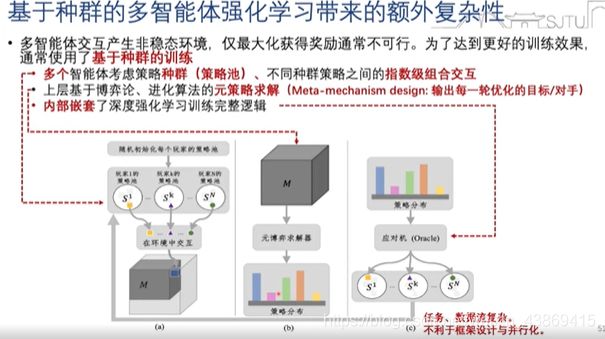

多智能体的系统需求

7.1.4 面向基于种群多智能体强化学习的并行训练框架
MALIB:
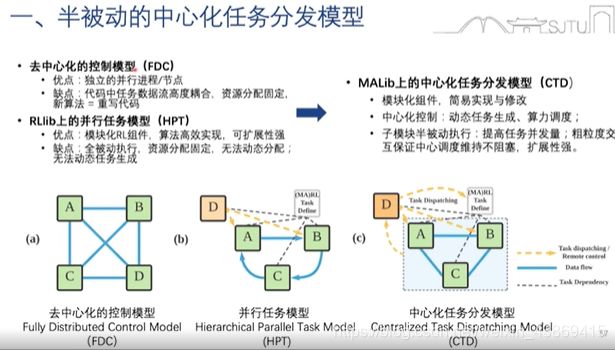
任务数据解耦:
训练模式层面的算法抽象:


7.2 多智能体通信与协同中的博弈论与强化学习
7.2.1 Role of informats in security games
偷猎问题:
 保护者策略:
保护者策略:
 对应的博弈顺序:
对应的博弈顺序:

Direct Defense Plan:
infrent 回报对应的被攻击的target,同时回报他自己的真实type
 用线性规划对于每个target,然后找到其中最优的。
用线性规划对于每个target,然后找到其中最优的。
具体:

偷猎问题的无人机信号:
解决方案(线性规划):

3.考虑对应问题为t轮博弈(偷猎问题)
此时Defender不告知对应的防护策略
且defender不知道attacker对于不同target的重视程度
具体如下:
 即attacker 考虑当前收益和后续的收益(通过保护自己当前的策略)
即attacker 考虑当前收益和后续的收益(通过保护自己当前的策略)
这里目标找到一个均衡的策略。
首先考虑:
找完美贝叶斯均衡
通过反向寻找对应的点。

Coorelated equilibrium

EFCE?
 求解算法:
求解算法:
1.通过subgradient descent method
2.a regret minization-based algorithm
7.2.4 food rescue patform
目标:保证更多的任务能够被完成。
ai的工作:

总结:
7.3 强化学习和游戏AI:技术演进&商业价值探讨


(CFR,DRL)






7.4 深度强化学习的挑战和落地

1.自动构造奖励
2.自动信任分配
Multiagent credit Assignment:

Multiagent Q-value Path Decomposition
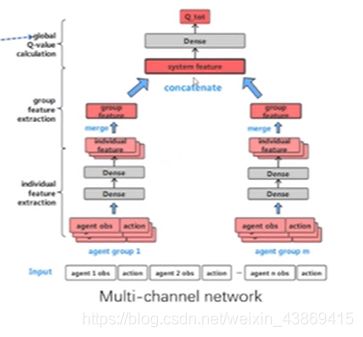 更好的捕捉不同group之间的区别
更好的捕捉不同group之间的区别
global q-value的分解:
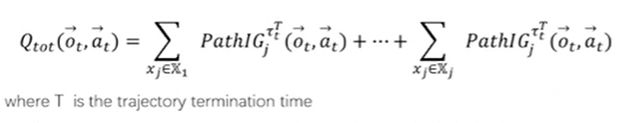
评估每个agent对于总体Q的贡献。
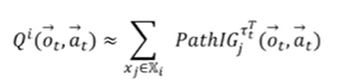
7.4.2

PeVF(Policy extended value function)
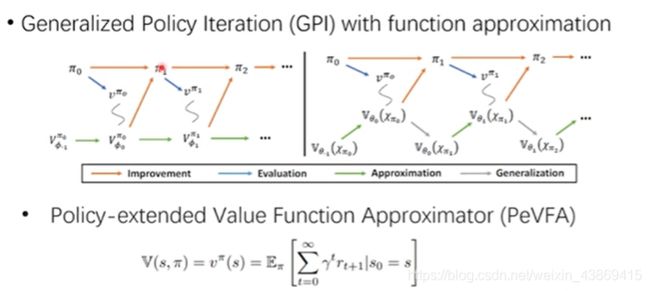 通过采样,然后评估,修改策略,迭代以得到更好的策略。
通过采样,然后评估,修改策略,迭代以得到更好的策略。
如何设计策略表征:
两种表征方式:
1.用神经网络的参数
2.用s,a对来表示
 (策略的相似度,来更好的评估策略表征)
(策略的相似度,来更好的评估策略表征)
2.Environment Dynamics Decomposition Framework
对action的不同的划分(解耦):

7.3
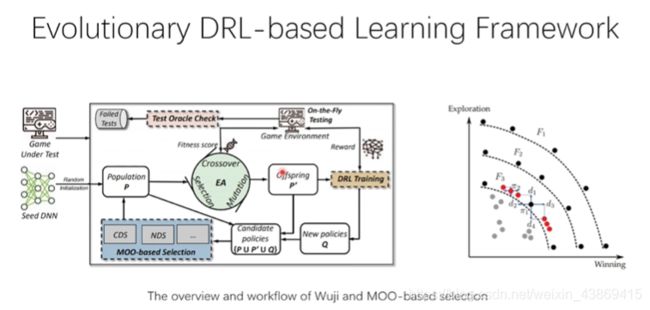 DRL Training 算子,用于生产一些难以得到的行为。
DRL Training 算子,用于生产一些难以得到的行为。
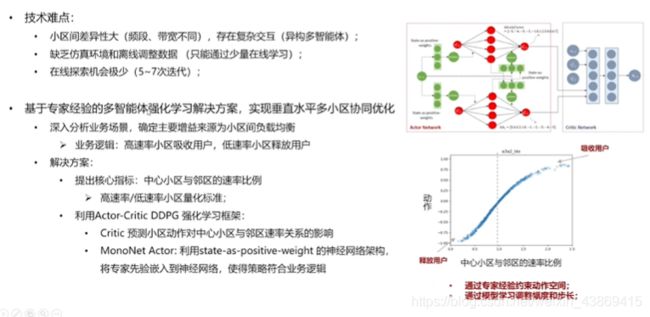
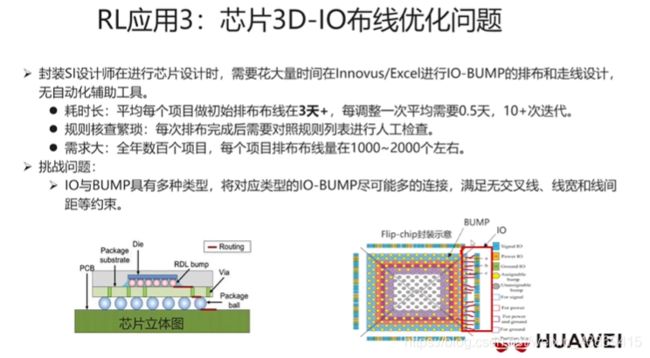
7.4 应用:




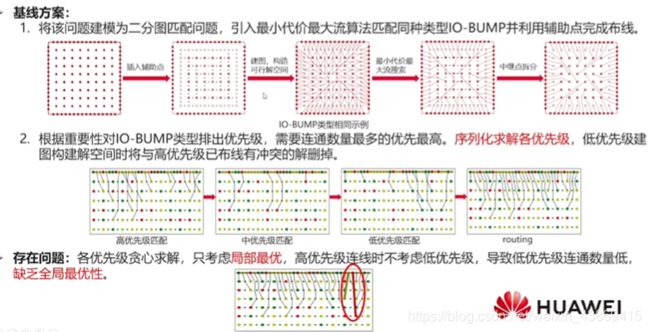

总结:
