NeurIPS 2022 | SlotCon: 以对象为中心的自监督表征学习

©作者 | 温鑫
单位 | 香港大学博士生
研究方向 | 自监督学习 & 概念发现

论文链接:
https://arxiv.org/abs/2205.15288
代码链接:
https://github.com/CVMI-Lab/SlotCon
项目主页:
https://wen-xin.info/slotcon/
Slides:
https://wen-xin.info/res/papers/NeurIPS_2022_SlotCon_slides.pdf
Poster:
https://wen-xin.info/res/papers/NeurIPS_2022_SlotCon_poster.pdf
Object Discovery 旨在无监督地发现图像中的物体,而此前该领域中的工作长期局限于合成数据集。在发表于 NeurIPS 2022 的工作 Self-Supervised Visual Representation Learning with Semantic Grouping(SlotCon)中,我们试图传达这样的消息:在大规模真实世界图像数据上,无监督且可学习的 object discovery 是可行的,并且可以与 object-centric 自监督表征学习结合,互利彼此。

Context:基于场景数据的自监督预训练

▲ 左:object-centric 数据与 scene-centric 数据对比;右:建立在不同粒度 feature 上的对比学习范式。
这篇工作主要面向的问题是基于场景数据的自监督视觉表征学习(预训练)。传统的视觉预训练框架往往局限于类似 ImageNet 的 object-centric 数据集:每张图往往聚焦于一个醒目而单一的物体;而我们希望将这种范式推广到更为 general 的场景数据上(如 COCO):每张图片上可能有多个物体,大小各异,且分布多样。
这种推广的好处是显而易见的:对收集数据有更低的要求、预训练数据与下游(检测与分割)数据有更小的 gap、单张图片包含的信息更为丰富。然而,直接将先前的图像级对比学习框架应用到场景数据上并不自然,因为现在代表一个图像的 vector 不再表示一个物体,而是一整个场景。
在上图右侧我们对比了三种不同的对比学习范式:两个 view 间对比学习 loss 的一致性关系建立在图像级、像素级,还是对象级表征之间。图像级表征对于场景数据过于粗糙,而像素级表征又过于精细,这条线的工作往往还要加一个图像级的 loss 来补充 high-level 的信息。
最右这种对于每种物体/语义单独表示,再在 object-level representation 之间进行对比学习的范式较好地平衡了表征的粒度,也更适合场景数据。然而,这里引出了一个关键问题:如何无监督地找到这些物体(object discovery)?

Object Discovery
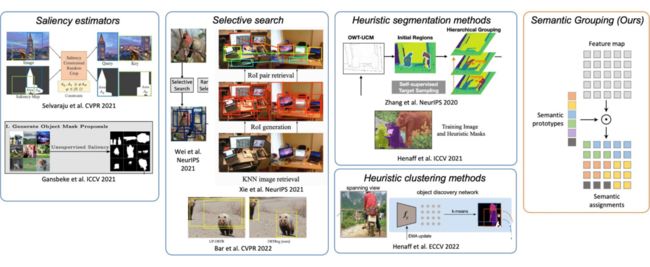
▲ Objectness priors
往期工作为了获取 objectness prior,往往采用一些 hand-crafted method,例如 saliency,selective-search,传统分割方法,k-means clustering 等。然而这里有一个 concern:手工设计的 objectness prior 可能会限制所学 representation 的 upperbound,那么我们是否可以让 object discovery 这部分也 end-to-end 地学习呢?
Object discovery 其实也是个挺热门的领域(详细的 review 见 paper related work),但是这方面的工作一直主要局限于合成数据集(如 CLEVER),学习范式基本也是 autoencoder +重建。在真实场景数据 work 的工作往往基于视频,且依赖 motion 或 depth 作为 condition。
概括来讲,它们的 philosophy 都是基于 bottom-up 的策略(texture, motion, depth, ...)去获得 objectness,对于合成数据怎么搞都行,但是真实场景中 low-level cue 的组合就太过复杂,难以从单张图像中 compose 出 object。
这里我们转而采用 top-down 的策略,从整个 dataset 中总结 high-level 的共性:如上图右侧所示,我们学习一些含有语义的prototype(每个 prototype 绑定到不同语义),这样对于 feature map 中的每个 pixel,只需要 assign 它最近邻的 prototype 作为 label,单张图中 label 相同的 pixel 即构成了一个 object(严格意义上应当称为 semantic object)。
OK,听上去好像不错,那么这些 semantic prototype 从哪来?我们采用的技巧可以简单概括为 pixel-level deep clustering。Deep clustering 旨在于采用可学习的方式得到有意义的 prototypes,其核心 insight 为:同一张图的不同增广版本应当有同样的 prototype assignment(pseudo label),另外需要一些正则项来保证 prototypes 的多样性。
这个套路应用到 pixels 上也同样有效,并且在 unsupervised semantic segmentation 上也有成功的先例(PiCIE) 。我们的方法可以理解为综上技巧的有机结合。

方法概述

▲ SlotCon整体框架
我们的框架完全随机初始化,在没有任何 label 的情况下,end-to-end 地同时学习解决 object discovery 以及 object-centric representation learning 两个task。技术上,最最简单的理解可以认为是 pixel-level DINO+object level MoCo v3。
对于 object discovery,我们在 pixel-level assignment maps 上将两个 view 中的 overlap 区域切出来并在空间上 align 好,对于每个位置相同的 pixel-pair,要求其对 prototypes 的 assignment 一致;对于 representation learning,我们在 feature map 上将语意相同的 pixels 聚合到一起(称为 slot,即 object-level representation),在不同 view 间的 slots 上进行 contrastive learning。两个 objective 相互促进,共同优化。

实验
4.1 对representation learning的评估
这里和其他做 pretrain 的工作类似,只取 backbone 然后在 object detection/instance segmentation/semantic segmentation 任务上做 transfer learning 来做评估。

▲ COCO pretrain结果
我们在场景数据 pretrain 的基准 setting 为 COCO pretrain 800 epochs。在不采用 multi crop 这种 trick 以及不采用 objectness prior 的情况下,我们的方法相对于先前工作在所有下游任务上都体现了显著的提升。

▲ COCO+ pretrain结果
更进一步,我们把 COCO unlabeled 子集也加进来,构成 COCO+(大概两倍 COCO 大小),效果进一步显著提升。

更为激动人心的是,COCO+ 只有 ImageNet-1K 的 1/5 大小,而我们却可以得到和 ImageNet-1K 近似的表现,这说明我们的方法成功利用到了场景数据中蕴含的更为丰富的信息。

▲ ImageNet-1K pretrain结果
我们也汇报了在经典的 object-centric 数据集 ImageNet-1K 上 pretrain 的结果。在不针对检测任务做特别设计(带 FPN head 一起 pretrain),以及不利用 objectness prior 的情况下,我们的方法也有着不错的表现。
4.2 对object discovery的评估

▲ Unsupervised semantic segmentation结果
需要注意的是我们的框架 focus 在 representation learning,所以采用了很低的分辨率(7x7)。这里在 unsupervised semantic segmentation 上的评测只是为了对网络的 object discovery 能力有定性和定量的认识,而非在该 task 上提出一个新的 SOTA。这里 prototype 和真实 class 的匹配采用了 hungarian matching。尽管 boundary 并不太好,这个质量对于 pretraining 来说已经完全够用了。

▲ prototype可视化
我们进一步可视化了每个 prototype 的 nearest neighbors,如上图,prototypes 可以绑定到一系列不同的语义上,它们范围广泛,而且对物体大小或遮挡与否并不敏感。这个结果可以说非常有趣了。
4.3 消融实验

比较值得注意的消融实验有两个:一是要把 prototype 的数量设定在一个比较接近 pretrain 数据集真实语义数量的值(COCO 设 256);二是 data augmentation 中 geometric augmentation 非常重要,如果一直采用两个 identical crops,模型就学不到 objectness,representation 质量也会明显下降。更详细的 ablation study 请参见 paper。

其他discussions
5.1 如何学到有意义的objects
经验上我们总结了3个关键点:
1. geometric covariance 和 photometric invariance:前者对应 resize,flip 等变换,后者对应 color jitter,gaussian blur 等变换。
2. 避免坍缩:follow deep clustering 中避免 prototypes 坍缩的技巧。
3. 把 prototype 数量设定在一个比较小,接近数据集真实 semantic 数量的数值(默认 COCO 采用 256,ImageNet 采用 2048)。
5.2 模型的bias
作为一个 learnable 的方法,总是要有些bias的。我们发现模型对 COCO 中的头部类别:human 相关概念有特别的偏好,会慷慨地分配很多 prototype 给与人相关的运动以及身体部位。我们分析是网络认为这样会更容易解决 pretext task。而对于更少出现的其他动物,分配一个 prototype 就好。如何更好的引入类别粒度的先验会是一个值得讨论的问题。

▲ 模型学到的human-related prototypes
而在更为极端的 pretrain 数据,例如自动驾驶场景上,模型表现也有一定程度降低。在这种长尾且多样性较差的场景数据上如何进行更有效的 pretrain 也是值得进一步研究的问题。

5.3 一些关于slots的数据
我们也统计了一些关于 slots 的数据。在训练过程中,随着模型表征能力与 object discovery 能力逐渐增强,每张图上的 slot 数量逐渐降低,最终收敛到与真实的平均单图物体数(7.3)接近的水平。至于每个 prototype 被激活的频率,则与真实类别分布类似(因为每个 prototype 绑定到一种语义)。

原文附录内容很丰富,欢迎check。

总结
我们的方法说明:自然场景的分解(scene decomposition)可以和 representation 一起 learn from scratch;semantic grouping 的范式让大规模真实场景图像数据中的 object discovery 成为可能;二者的结合促生了一种在场景数据上进行自监督预训练的有效方法。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏
·
·
