python量化低频策略——利用USDA数据、中国统计局PMI构建菜粕期货策略
python量化低频策略——利用USDA数据、统计局PMI数据构建菜粕期货策略
原创内容
笔者属于python初学者,本文所列代码大多内容也是清洗数据、筛选等内容,
各方面还有待提炼与深化。感兴趣的朋友,欢迎私信交流。
一.名词解释:
USDA,全称:United States Department of Agriculture。USDA每月上旬(一般在每月8日-12日之间)会公布World Agricultural Supply and Demand Estimates(全球农作物供需)报告。该报告会对世界多地区多种类主要农作物进行供需方面的预测。本策略主要利用该报告中,中国区域大豆供需数据。
中国统计局PMI:PMI指数全称为urchasing Managers’ Index,中文意思是采购经理指数。是能够反映宏观经济情况的重要指标。中国统计局每月初会公布上一月份的PMI指数。
菜粕期货:为国内郑州商品交易所(下称“郑商所”)的菜粕期货合约。菜粕是油菜籽压榨菜油所产生的副产品,主要用于饲料。
豆粕期货:为国内大连商品期货交易所(下称“大商所”)的豆粕期货合约。豆粕是大豆压榨豆油所产生的副产品,主要用于饲料。国内大豆近八成供应源于进口,同时豆粕与菜粕有一定替代关系,价格上存在强相关性。
二.构建方式
最初,笔者是想利用USDA报告数据及统计局PMI数据,进行多元线性回归分析,预估菜粕与豆粕之间的价差,然后进行跨品种套利操作,结果拟合出来的R^2参数非常低,不具有参考价值。后来,笔者转为利用数据进行多元线性回归分析,仅进行菜粕期货(05合约)单品种的预估,进行单边操作。通过sklearn多次进行训练集、测试集的拟合,R^2在0.4-0.6之间,具备一定参考价值。
由于USDA报告发布时间在国内期货夜盘收市之后,故以USDA报告发布后最近的国内开盘日为策略操作日。判断准则如下:
根据当月之前的各月数据进行回归分析,得出模型结合当月数据进行本月价格预测。
预测价格<开盘价-50(50为手工调参的数据,根据个人风险承受能力调整。该数据越大,入场操作次数会越少)入场做空,每月最后交易日平仓。
(考虑手续费、滑点等情况,交易成本估为20,对于小规模持仓来说,是一个偏高的参数)
三.软件及主要是用的库
本次使用python软件,主要使用的库有:
1.pandas,基于numpy的数据处理利器
2.sklearn,一个机器学习库,具备多种分类、回归和聚类算法。本次用到多元回归分析LinearRegression
3.os 操作系统访问的模块。
4.re 用于进行正则表达式的模块。
5.statsmodels 重要的统计模块包。
四.构建步骤
1处理USDA报告
USDA的月度报告可从以下地址下载:
https://usda.library.cornell.edu/concern/publications/3t945q76s?locale=en
关于中国大豆供需数据在excel的第28页,同时显示了当月及上月的数据,我们主要使用当月数据(请见下图)故读取文件后,进行re的正则表达式进行匹配工作。
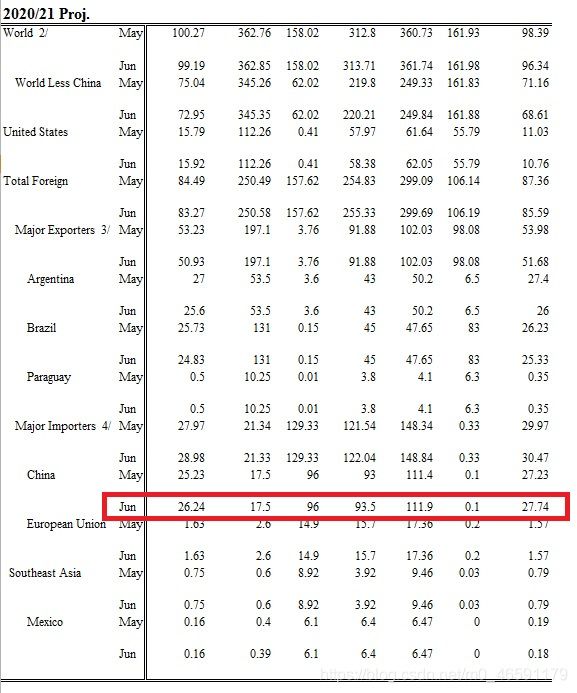
笔者最初使用xlrd进行USDA报告excel文件的读取、处理,后来发现pandas的read_excel方式,效率更高,方便之后的处理工作。代码中,还可见最初xlrd的引用。另外,顺便批评一下USDA,报告excel在早期与近期,编排格式不一致(见下图)。笔者根据近期USDA报告excel编写代码后,用代码跑早期的报告excel,导致错误,故要结合dropna及切片等进行数据清洗。
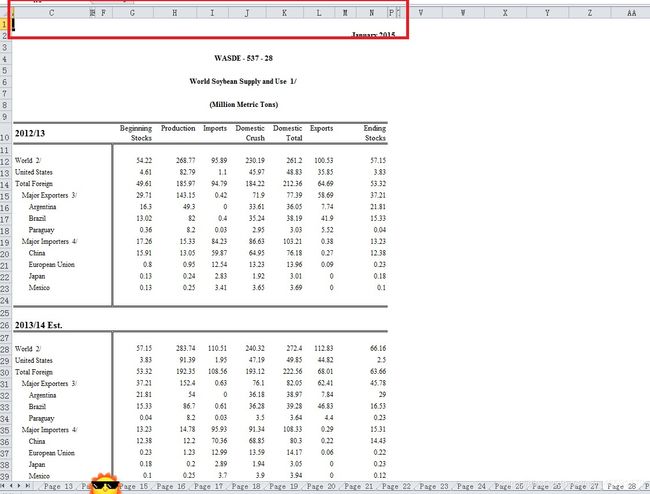
(早期)
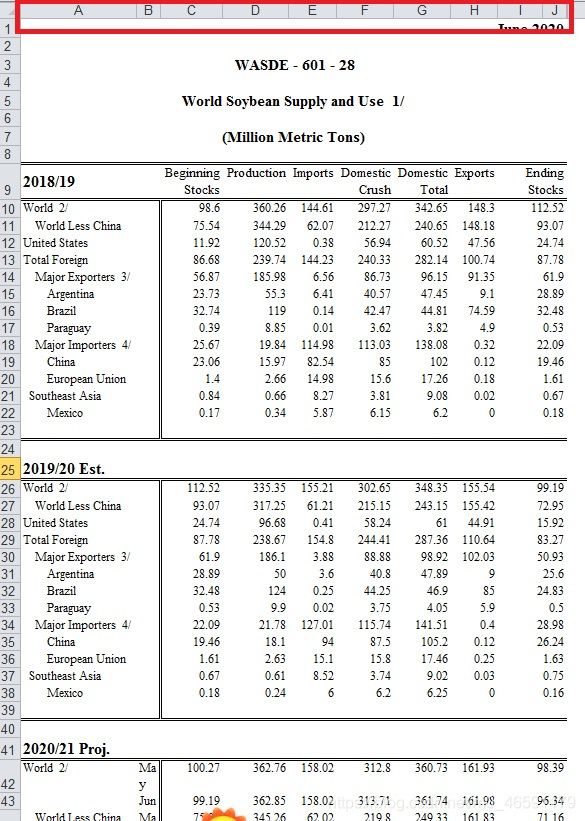
(近期)
USDA报告处理的完整代码:
//
import xlwt
import xlrd
import os
import pandas as pd
import re
pd.set_option('display.width', None)
data=os.listdir('E:\python\data\excel\\usda\month excel')
usda=xlwt.Workbook('E:\python\data\excel\\usda\\usda.xlsx')
usda.add_sheet('usda')
usda_pd=pd.DataFrame(columns=['Nationl','Date','month','Beginning Stocks','Production','Imports','Domestic Crush','Domestic Total','Exports','Ending Stocks'])
usda.save('E:\python\data\excel\\usda\\usda.xls')
for i in range(0,len(data)):
path=os.path.join('E:\python\data\excel\\usda\month excel',data[i])
rw=xlrd.open_workbook(path) #rw=read workbook
rs=rw.sheet_by_name('Page 28') #rs=read sheet
col=rs.col(0)
pdd=pd.read_excel(path,"Page 28",header=None,skiprows=40).dropna(how='all').dropna(axis=1,how='all')
pdd.columns=['Nationl','month','Beginning Stocks','Production','Imports','Domestic Crush','Domestic Total','Exports','Ending Stocks']
bool=pdd['Nationl'].str.contains('\s{2}China', na=False,regex=True)
data_index=pdd[bool].index[-1]
t_pd=pdd.loc[data_index+1]
t_pd['Nationl']='China'
t_pd['Date']=data[i][:-4]
t_pd.name=data[i][:-6]
usda_pd=usda_pd.append(t_pd)
usda_pd.to_excel("E:\\python\data\\excel\\usda.xls",sheet_name='usda',index='time')
2.处理郑商所、大商所及统计局数据:
大商所历史数据下载地址:
http://www.dce.com.cn/dalianshangpin/xqsj/lssj/index.html
郑商所历史数据下载地址:
http://www.czce.com.cn/cn/jysj/lshqxz/H770319index_1.htm
统计局网址:
http://data.stats.gov.cn/easyquery.htm?cn=A01
主要通过正则表达式、库、切片进行数据清理,通过sklearn进行回归分析的训练、预测,并可用statesmodels进行相关系数及具体回归分析的检验。
具体代码如下:
//
import pandas as pd
import numpy as np
import os
import sklearn
from sklearn.linear_model import LinearRegression
import statsmodels.formula.api as sm
pd.set_option('display.width', None)
RM_data=os.listdir('E:\python\data\excel\zss\RM')
M_data=os.listdir('E:\python\data\excel\dss\M')
t_data=pd.DataFrame()
t_m_data=pd.DataFrame()
project=pd.read_excel('E:\\python\\data\\excel\\usda.xls',sheet_name='usda',index_col=0)
project['FTD_RM']=0
project['FTD_M']=0
for i in range(0,len(RM_data)):
path=os.path.join("E:\\python\data\excel\zss\RM",RM_data[i])
RM_t_pd=pd.read_excel(path,skiprows=1,sheet_name=0,thousands=',')
RM_t_pd['交易日期']=RM_t_pd['交易日期'].apply(lambda x: x[0:4]+x[5:7]+x[8:10])
for i in range(0,13):
bool1=RM_t_pd['交易日期'].str.contains('^[\w]{4}'+'[0]?'+str(i)+'[\w]{2}$',regex=True)
bool2=RM_t_pd['品种代码'].str.contains('.+5$',regex=True)
t_pd=RM_t_pd[(bool1)&(bool2)]
bool4=(t_pd['交易日期']==t_pd['交易日期'].max())
d=t_pd['交易日期'].max()
d=str(d)[0:6]
if d=='nan':
pass
else:
if int(d) not in project.index.values:
pass
else:
d_1=project.at[int(d),'Date']
j=0
while int(t_pd['交易日期'].iloc[j])<=int(d_1):
j=j+1
else:
project['FTD_RM'].loc[int(d)]=t_pd['今开盘'].iat[int(j)] #FTD_RM为USDA报告公布后最近交易日的菜粕期货开盘价
t_pd=t_pd[bool4]
t_data=t_data.append(t_pd)
t_data.index=t_data['交易日期'].apply(lambda x:x[0:-2])
for i in range(0,len(M_data)):
path=os.path.join("E:\python\data\excel\dss\\M",M_data[i])
M_t_pd=pd.read_excel(path,skiprows=0,sheet_name=0)
M_t_pd['日期']=M_t_pd['日期'].astype(str)
for i in range(0,13):
bool1=M_t_pd['日期'].str.contains('^[\w]{4}'+'[0]?'+str(i)+'[\w]{2}$',regex=True)
bool2=M_t_pd['合约'].str.contains('.+5$',regex=True)
t_m_pd=M_t_pd[(bool1)&(bool2)]
bool4=(t_m_pd['日期']==t_m_pd['日期'].max())
t_m_pd=t_m_pd[bool4]
t_m_data=t_m_data.append(t_m_pd)
t_m_data=t_m_data.drop_duplicates(keep='first')
m_time=t_m_data['日期'].tolist()
for i in range(0,len(m_time)):
m_time[i]=m_time[i][0:6]
t_m_data.index=m_time
t_m_data=t_m_data.drop_duplicates()
meal_data=t_data.join(t_m_data,rsuffix='_m')
meal_data.index=meal_data.index.astype(int)
project=project.join(meal_data)
project['今收盘']=project['今收盘'].fillna(int(0))
project['收盘价']=project['收盘价'].fillna(int(0))
project['基差']=project['今收盘']-project['收盘价']
tjj=pd.read_excel('E:\python\data\\tjj\月度数据制造业.xls',skiprows=2,skipfooter=15,sheet_name=0,header=0)
tjj=tjj.T
tjj=tjj.drop(index='指标')
tjj_time=list(tjj.index)
for i in range(0,len(tjj_time)):
tjj_y=tjj_time[i].split('年')[0]
tjj_m=tjj_time[i].split('年')[1].split('月')[0]
if int(tjj_m) < 10:
tjj_m='0'+tjj_m
tjj_time[i]=tjj_y+tjj_m
del tjj_time[-1]
if tjj_time[0][-2]=='12':
first=str(int(tjj_time[0:4])+1)+'01'
tjj_time.insert(0,first)
else:
first=str(int(tjj_time[0])+1)
tjj_time.insert(0,first)
tjj.index=tjj_time
tjj.index=tjj.index.astype(int)
tjj.columns=['上月制造业PMI']
project=project.join(tjj)
project['RM_M_收盘比']=project['今收盘']/project['收盘价']
project.to_excel("E:\\python\\data\\excel\\project.xls",sheet_name='project')
x=project[['Beginning Stocks','Production','Imports','Domestic Crush','Domestic Total','Exports','Ending Stocks','上月制造业PMI']]
x.fillna(0,inplace=True)
x=x.applymap(pd.to_numeric)
y=project['FTD_RM']
y=y.map(pd.to_numeric)
x_train,x_test,y_train,y_test=sklearn.model_selection.train_test_split(x,y,test_size=0.25)
linreg=LinearRegression()
model=linreg.fit(x_train,y_train)
print('R2:',linreg.score(x_train,y_train))
print('特征向量:',linreg.coef_)
print('截距:',linreg.intercept_)
print(linreg.predict(x_test))
print(linreg.predict(x_test)-y_test)
print(sm.ols('FTD_RM ~Exports+Imports+Production',data=project).fit().summary())
x.corr().to_excel('E:\python\data\excel\corr.xlsx',sheet_name='corr')
3.预测工作及回测:
利用sklearn的线性回归进行分析,并进行简单的回测工作。
(本次利用2015年1月-2020年6月之间的数据)
代码如下:
//
import pandas as pd
import sklearn
from sklearn.linear_model import LinearRegression
project=pd.read_excel('E:\python\data\excel\project.xls',sheet_name='project',index_col=0,header=0)
linreg=LinearRegression()
project['predict_rm']=0
project['profit_rm']=0
for i in range(2,len(project)+1):
x=project[['Beginning Stocks','Production','Imports','Domestic Crush','Domestic Total','Exports','Ending Stocks','上月制造业PMI']].iloc[0:(i-1)]
y=project['FTD_RM'].iloc[0:int(i-1)]
x_predict=project[['Beginning Stocks','Production','Imports','Domestic Crush','Domestic Total','Exports','Ending Stocks','上月制造业PMI']].iloc[(i-1):(i)]
model=linreg.fit(x,y)
project['predict_rm'].iat[i-1]=linreg.predict(x_predict)
for i in range(1,len(project)):
if project['predict_rm'].iat[i]<int(project['FTD_RM'].iat[i]-50):
project['profit_rm'].iat[i]=project['FTD_RM'].iat[i]-project['今收盘'].iat[i]-20
else:
pass
project.to_excel("E:\\python\\data\\excel\\project.xls",sheet_name='project')
最后输出的excel,盈亏栏数据(局部):
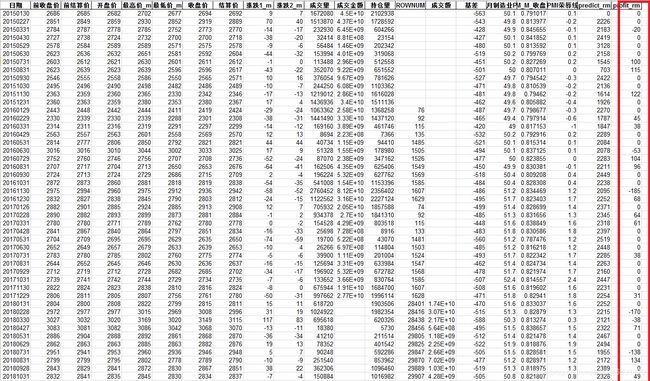
如果是一手菜粕期货进行交易,该时间段最终盈利335点(即3350元人民币)一手菜粕期货保证金约为2200-2500左右(根据价格波动)
最大月亏损为226点,出现在2020年3月(新冠肺炎时期的剧烈波动)
五.后记及不足
1.策略还需要严格的资金管理策略
2.对于市场出现的特殊情况(如新冠肺炎等),没有严格的止损措施。
3.通过corr分析,可以得知USDA报告中几个参数,存在一定自相关的情况,有一定的优化空间。