关于word2vec词向量化
word2vec最主要的目的就是进行文本向量化
词向量维度通常是50-300维,goole官方提供的一般是用300维,有了词向量就可以用各种方法进行相似度计算;一般维度越高,提供的信息越多,计算结果可靠性也更值得信赖。
普通的向量空间模型没有考虑语义、语法以及上下文联系等信息,忽略了中文文本一词多义的现象,容易造成信息遗漏。而基于词语分布式表达的方法( Word2vec)则能够很好地解决上述问题,将每一个特征词转化为固定维度的向量,再选择适当的方法进行加权,便可得到每一条文本对应的向量。同时很好地解决了文本表示时容易产生的高维矩阵稀疏的问题。
词向量将自然语言转换成了计算机能够理解的向量。相对于词袋模型、TF-IDF等模型,词向量能抓住词的上下文、语义,衡量词与词的相似性,在文本分类、情感分析等许多自然语言处理领域有重要作用。
word2vector 包含了两种类型,Continuous Bag-of-Words Model 和 skip-gram model
CBOW模型:
连续词袋模型,就是将文本看成是一个一个单独的词,然后通过一个位置附近的词来推出这个位置可能的值。
图解示意如下:
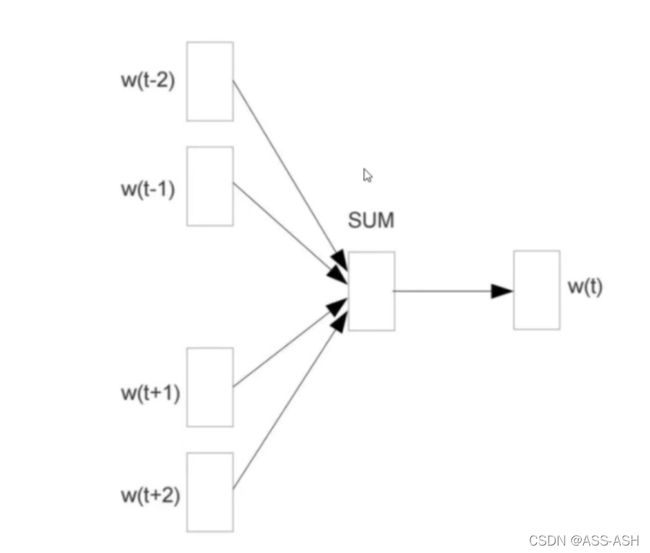
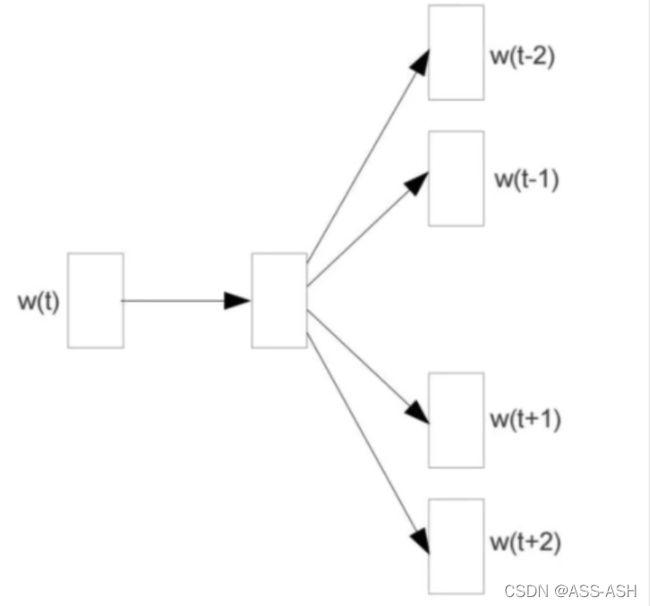
Skip-gram模型:
可以理解为CBOW的倒叙。通过目标词从而预测它周围词的概率。
图解示意如下:
两个模型相比,skip-gram模型能产生更多训练样本,抓住更多词与词之间语义上的细节,在语料足够多足够好的理想条件下,skip-gram模型是优于CBOW模型的。在语料较少的情况下,难以抓住足够多词与词之间的细节,CBOW模型求平均的特性,反而效果可能更好。
在模型拟合的过程中求和矩阵和softmax矩阵相乘计算量太大,又提出了两种解决办法,哈夫曼树和负采样
1) 哈夫曼树(Huffman)
哈夫曼是一种压缩的树状模型,通过统计词出现的概率,来决定这个词所处的树的深度。
想法就是,把整个语料先用haffman给结构化,之后只需要从根结点,对每一个二叉树枝进行二分法的判断就好了,在这个过程中,在每一个分支上的权重,其实可以枝内共用的。
(原理二次叙述)此方法也称作层次化Sofrmax:Hierarchical Softmax
Hierarchical softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。一开始我们可以用以词表中的全部词作为叶子节点,词频作为节点的权,构建Huffman树,作为输出。从根节点出发,到达指定叶子节点的路径是Hierarchical Softmax用来计算指定词的概率,而非用softmax来计算。
[优化一]把 N 分类问题变成 log(N)次二分类,利用哈夫曼树构造很多二分类(sigmoid);
( 使用原始的softmax计算,是N分类,N代表词典个数,所以softmax计算量非常大需要对N个分类下的各自输出值)
[优化二] 层次化softmax不必求神经网络隐藏层中的权值矩阵, 而是改求哈弗曼树中每个节点的权值向量, 这样就减少了计算。
Hierarchical softmax的缺点:虽然我们使用huffman树代替传统的神经网络,可以提高模型训练的效率,但是如果我们训练样本中的中心词w是一个很生僻的词,那么就需要沿着huffman树往下走很多,因为越是高频的词,越是靠近根节点
2)负采样(negative sampling)
什么叫负例?
除了我们找到的那个答案之外,所有不是答案的备选都叫负例。
在训练过程中,我们在拟合出来每一次的答案之后,和标签比较,调整权重值,而在这个过程中,我们既要使正确答案的特征方程最大化,又要使其他负例的特征方程最小化。
负例要如何采样?
谷歌给出的解决办法是,将词频的大小投影到一个【0,1】线段上,取随机数,点到哪个取哪个。
在取样的过程中,我们把每个词频的值取四分之三次方的时候效果最好。
这样做是因为对频率较大的数进行取3/4次幂,原数字损失的多,反之较小的,去掉的就少,这样做是一种平滑方式。
(原理二次叙述)
Negative Sampling(简写NEG,负采样),这是Noise-Contrastive Estimation(简写NCE,噪声对比估计)的简化版本:把语料中的一个词串的中心词替换为别的词,构造语料 D 中不存在的词串作为负样本。在这种策略下,优化目标变为了:较大化正样本的概率,同时最小化负样本的概率;
[优化] 在训练每个样本时, 原始神经网络隐藏层权重的每次都会更新, 而负采样只挑选部分权重做小范围更新
词汇表的大小决定了我们skip-gram 神经网络将会有一个非常大的权重参数,并且所有的权重参数会随着数十亿训练样本不断调整。negative sampling 每次让一个训练样本仅仅更新一小部分的权重参数,从而降低梯度下降过程中的计算量。
如果 vocabulary 大小为1万时, 当输入样本 ( "fox", "quick") 到神经网络时, “ fox” 经过 one-hot 编码,在输出层我们期望对应 “quick” 单词的那个神经元结点输出 1,其余 9999 个都应该输出 0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们称为 negative word. negative sampling 的想法也很直接 ,将随机选择一小部分的 negative words,比如选 10个 negative words 来更新对应的权重参数。
NEG提高训练速度和精度的优化方法:
1.二次抽样高频词,舍弃
2.对于频次高的词提高采样的命中率
Python使用简易示例:
from gensim.models.word2vec import Word2Vec #pip install gensim安装即可
import jieba
import pandas as pd #导入所需的库
s=open(r'D:\语料.txt','r',encoding='utf-8') #分词
l=[]
for i in s.readlines():
i=' '.join(jieba.cut(i[:-1]))
l.append(i+'\n')
n_dim=300
w2vmodel=Word2Vec(vector_size=n_dim,min_count=10)
w2vmodel.build_vocab(l) #生成词表
w2vmodel.train(l,total_examples=w2vmodel.corpus_count,epochs=10) #在训练集数据上进行建模
def m_avgvec(words,w2vmodel): #各个词向量直接平均的方式生成整句所对应的词向量
return pd.DataFrame([w2vmodel.wv[w]
for w in words if w in w2vmodel.wv]).agg('mean')
train_vec=pd.DataFrame([m_avgvec(a,w2vmodel) for a in l]) #此处a没有实际意义,单纯为了循环
print(train_vec.head())
#显示词向量矩阵前五条,这里为最终得到的建模需用数据集的词向量矩阵
Word2vec词向量化后的前五条示例:

参考:
自然语言处理NLP——从发展历程简述word2vector好在哪里?
层次化softmax与负采样对比