KNN——K近邻
KNN(K-Nearest Neighbor)最邻近分类算法是数据挖掘分类(classification)技术中最简单的算法之一,其指导思想是”近朱者赤,近墨者黑“,即由你的邻居来推断出你的类别。
K近邻(KNN)分类器是有监督学习中普遍使用的分类器之一,将观察值的分类判定为离它最近的k个观察值中所占比例最大的分类。
目录
一、KNN
1,算法介绍
2,计算距离
1,在k维空间中有两个向量,求向量间的距离
2,向量间的距离(多组)
2,题目复习
1,eg1
2,eg2
3,eg3
编辑
4,eg4
二、KNN的使用
1,sklearn库
2,neighbors.KNeighborsClassifier参数设置
3,手写数字识别
一、KNN
1,算法介绍
KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
通用步骤:
1,计算距离(常用欧几里得距离或马氏距离)
n维欧几里得距离:
2,升序排序
3,取前K个
4,加权平均
K得选取:
1,K太大:导致分类模糊
2,K太小:受个例影响,存在波动
如何选取K:
1,经验
2,均方根误差
2,计算距离
1,在k维空间中有两个向量,求向量间的距离
def distance(a, b):
# a:numpy一维数组,表示k维空间中的向量,形状是(k,)。
# b:numpy一维数组,表示k维空间中的向量,形状是(k,)。
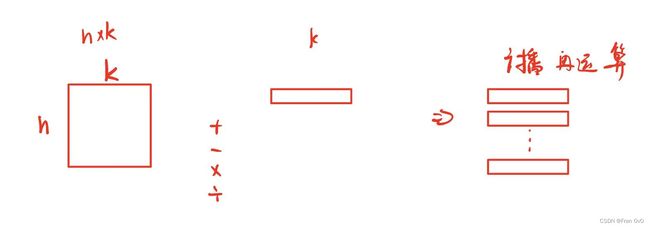
return np.sqrt(((a-b)**2).sum())2,向量间的距离(多组)
def distance(a, b):
# a:numpy二维数组,由n个样本向量组成的数据矩阵,形状是(n,k)。
# b:numpy二维数组,由m个样本向量组成的数据矩阵,形状是(m,k)。
A = a.reshape(a.shape[0],a.shape[1],1)
B = b.T.reshape(1,b.shape[1],b.shape[0])
return np.sqrt(((A-B)**2).sum(axis=1)) 
要得到一个(n,m)的矩阵
利用广播机制:
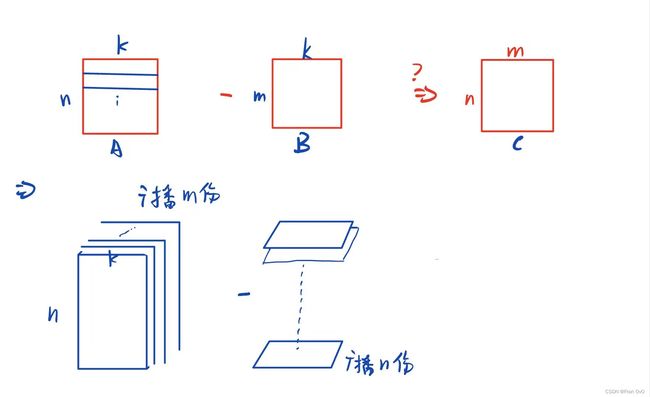
这里我们可以知道是一份(n,k,1)*m份-(1,k,m)*n份的广播方法,所以我们只需要进行(n,k,1)和(1,k,m)的相减就可以了
2,题目复习
1,eg1

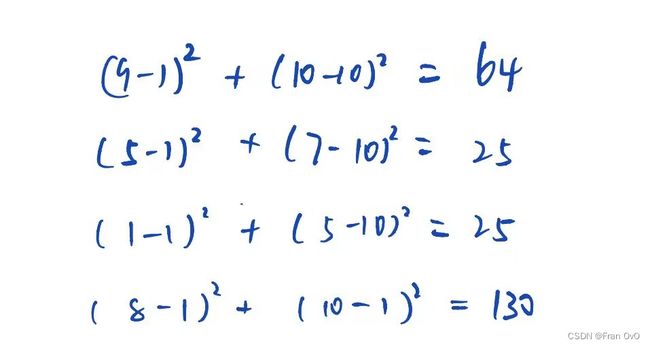
距离要开根号,我没开
D,最大
2,eg2

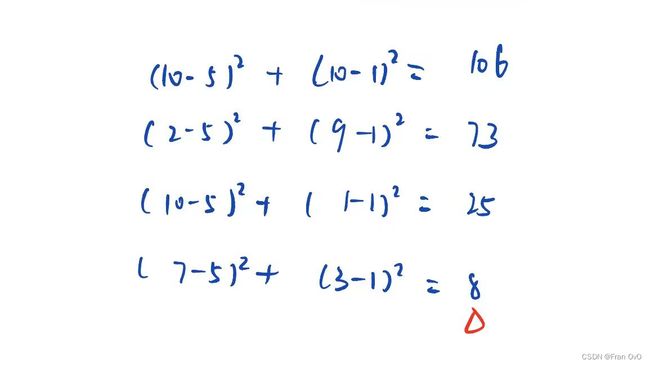
C
3,eg3
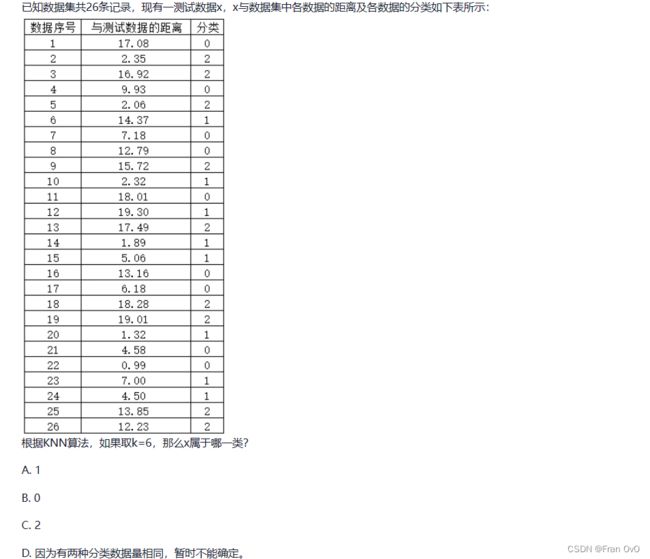

A,升序排序前k个(这里k是6),选类别多的1
4,eg4

标准化在上一篇BP里面讲过,标准化的主要目的就是统一量纲
我的答案:特征尺度不一,目的是统一量纲,降低误差
标答:KNN在计算距离的时候,因为不同特征的尺度不一样,导致大的数值对距离的影响较大,使得距离比较效果不够好。
意思差不多就行,都是因为特征的量纲不同带来的影响
二、KNN的使用
1,sklearn库
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 数据生成
X, y = make_moons(noise=0.3)
#数据切分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#模型搭建
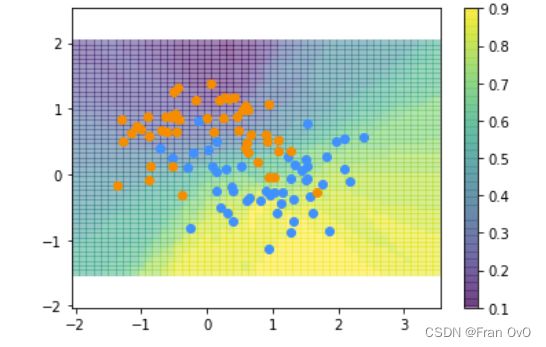
model = KNeighborsClassifier(n_neighbors=30)
model.fit(X_train, y_train) # 训练
y_pred = model.predict(X_test)
accuracy_score(y_pred, y_test) # 评估 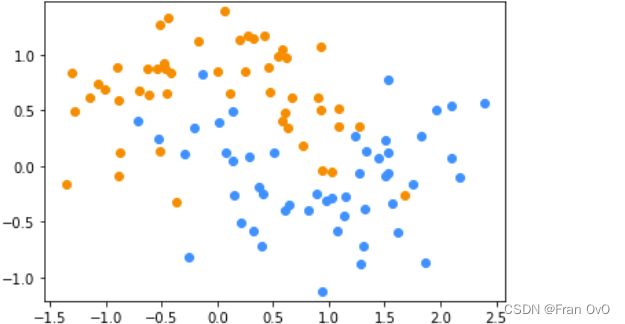
![]()
2,neighbors.KNeighborsClassifier参数设置
n_neighbors: int, 可选参数(默认为 5)用于kneighbors查询的默认邻居的数量
3,手写数字识别
knn一定要标准化,建议建立通道一步解决
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
#获取数据
digits = load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#建立通道
p = Pipeline([
('ss', StandardScaler()),
('md', KNeighborsClassifier(n_neighbors=5)),
])
#训练
p.fit(X_train, y_train)
score = p.score(X_test, y_test)
print(f"acc: {score}")