文档图像分类、信息提取、信息结构化之 LayoutLM、LayoutLMv2、LayoutXLM —— 论文阅读笔记
LayoutLMFT
- Document Understanding Tasks
- LayoutLM
-
- Overview
- LayoutLM
-
- Pre-training
- Fine-tuning
-
- Experiments
- Model Pre-training
- StructuralLM
- LayoutLM v2
-
- Overview
- LayoutLM v2
-
- Model Architecture
- Pre-training
- Fine-tuning
-
- Experiments
- LayoutXLM
-
- Pre-training Data
- XFUND
Paper : LayoutLM、LayoutLMv2, LayoutXLM,StructuralLM
Code : LayoutLM、LayoutLMv2、LayoutXLM
Dataset:
IIT-CDIP Test Collection 1.0
FUNSD Dataset
SROIE Dataset
RVL-CDIP Dataset
CORD
Kleister-NDA
DocVQA
XFUND
TableBank
DocBank
ReadingBank
MSRA Document AI
Document Understanding Tasks


LayoutLM

Overview
针对图像的布局和结构信息对文档图像理解是重要的,提出了 LayoutLM 模型,可以通过扫描文档图像对文本和布局信息进行联合建模,除此之外还利用了文本的图像信息。
可以做表单理解、票据理解和文档图像分类

LayoutLM

LayoutLM 利用来自文档布局的丰富的视觉信息,并将此与输入文本对齐,这样可以极大的改善文档的语义表示。
- 文档布局信息:文本的相对位置对于语义表示是很重要的,把文本的相对位置信息编码为二维位置表示。基于自注意力机制,把二维位置特征编码进语言表示会更好地将布局信息与语义表示对齐。
- 视觉信息:对于文档图像整体的视觉信息可以体现文档的布局,对文档图像的分类是一个重要的因素。对于文本的视觉信息,粗体、下划线和斜体等样式也是序列标注任务的重要因素。因此,文中认为把文本表示和图像特征结合起来可以带来更好的语义表示。
LayoutLM 使用 BERT 作为主干网络,并添加两个新的输入向量:一个二维位置向量和一个图像向量。二维位置向量可以捕捉到文档中字段之间的关系,同时图像向量可以捕捉到一些外观特征,如字体方向、类型、颜色等。
- 二维位置向量:与序列中单词位置的位置向量不同,二维的位置向量是为了对文档图像中的相对空间位置进行建模。文本的边界框表示为 ( x 0 , y 0 , x 1 , y 1 ) (x_0, y_0, x_1, y_1) (x0,y0,x1,y1) 。使用四个位置信息和两个向量层,其中表示相同维度的向量层共享。
- 图像向量:为了利用文档的图像特征并且与文本对齐,添加了图像向量层来表示语义表示的图像特征。利用 OCR 结果中每个文本的边界框,将图像分割为多个与文本一一对应的图像块。使用 Faster R-CNN 来生成这些图像块的图像区域特征作为图像向量。对于 [CLS] 字段,同样也使用 Faster R-CNN 生成整张图像的特征。
Pre-training
IIT-CDIP Test Collection 1.0 : 包含超过 600 万份文档,超过 1100 万份扫描文档图像,包括很多类别(信函、备忘录、电子邮件、表格、手写、发票、广告、新闻文章、演示文稿、科学出版物、问卷、简历、科学报告等),每个文档都有对应的文本和存储在 XML 文件中的元数据。
Masked visual-Language Model
随机 mask 输入的字段,保持对应的二维位置向量,然后训练模型根据上下文去预测 mask 的部分。这样,LayoutLM 不仅可以理解语言上下文而且也可以利用对应的二维位置信息,可以增强视觉模态和语言语言模态的关联。
Multi-label Document Classification
给一组扫描文件,用文件的标签监督训练的过程,以便模型可以对来自不同领域的知识进行聚类,生成更好的文档级表示。因为多标签文档分类损失需要每个文档图像的标签,由于数据集的限制,文中对于这个预训练是可选的,不在大模型上训练。
Fine-tuning
将预训练好的 LayoutLM 在三个文档理解任务上微调,包括表单理解、票据理解和文档图像分类。对于表单和票据理解任务, LayoutLM 预测每个字段的 {B,I,E,S,O} 并且使用序列标签检测数据集中的每种实体类型。对于文档图像分类任务,LayoutLM 使用 [CLS] 标记的表示来预测类标签。
在三个文档图像理解任务上验证 LayoutLM 模型:表单理解、票据理解和文档图像分类。
- 表单理解:该任务需要对表单的文本内容进行抽取和结构化。目的是从扫描的表单图像中提取键值对。该任务包括两个子任务 : 语义标注和语义链接。语义标注是将词汇作为语义实体进行聚合,并为它们指定预定义标签的任务。语义链接是指预测语义实体之间的关系。文中主要关注语义标注任务,而语义链接则不在文中范围之内。为了在此任务中微调 LayoutLM,我们将语义标记视为序列标记问题。我们将最终表示传递到一个线性层,然后是一个 softmax 层,以预测每个字段的标签。该模型训练 100 个epoch ,batch size=16,lr=5e-5。
- 票据理解:该任务需要根据扫描到的接收图像填充几个预先定义的语义槽。例如,给定一组收据,我们需要填写特定的槽(例如,公司、地址、日期和总数)。与表单理解任务(需要标记所有匹配的实体和键值对)不同,语义槽的数量是用预定义的键固定的。因此,模型只需要使用序列标注方法预测相应的值即可。
- 文档图像分类:给定一个视觉丰富的文档,该任务旨在预测每个文档文档图像的相应类别。与现有的基于图像的方法不同,我们的模型不仅包括图像表示,还使用 LayoutLM 中的多模态架构包含文本和布局信息。因此,我们的模型可以更有效地将格式中的文本、布局和图像组合在一起。为了在此任务上微调我们的模型,我们将 LayoutLM 模型的输出与整个图像向量连接起来,然后是用于类别预测的softmax层。我们对模型进行了30个 epoch 的微调,batch size=40,lr=2e-5
Experiments
- FUNSD Dataset : 表单理解数据集,该数据集包括199个真实的、完整标注的、扫描的表单,包含 9707个语义实体和 31485 个单词。这些表单被组织成相互链接的语义实体列表。每个语义实体包括一个唯一标识符、一个标签(即,问题、答案、标题或其他)、一个边界框、一个与其他实体的链接列表和一个单词列表。数据集分为 149 个训练样本和 50 个测试样本。
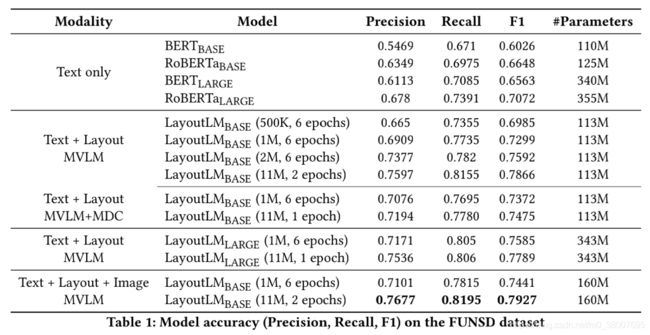
- SROIE Dataset : 票据信息提取数据集,该数据集包含 626 条用于训练的票据和 347 条用于测试的票据。每个票据都被组织成带有边框的文本行列表。每张票据都标有四种类型的实体,它们是 {公司,日期,地址,总数}。

- RVL-CDIP Dataset : 文档图像分类数据集,该数据集由 16 类 40 万张灰度图像组成,每类 25000 张图像。有 32 万张训练图像,4 万张验证图像和 4 万张测试图像。图像被调整大小,因此它们的最大尺寸不超过 1000 像素。这16个类别包括 : 书信、表格、电子邮件、手写体、广告、科学报告、科学出版物、说明书、文件夹、新闻文章、预算、发票、演示文稿、问卷、简历、备忘录等。

Model Pre-training
使用预训练好的 BERT(Base | Large)模型初始化 LayoutLM 的权重。
Base-model : 12 层 Transformer(768 隐藏层大小和 12 个注意力头),包含 113M 参数。
Larg-model : 24 层 Transformer(1024 隐藏层大小和 16 个注意力头),包含 343M 参数。
选择输入字段的的 15% 进行预测,其中 80% 使用 [MASK] 代替,10% 随机代替,10% 不变。使用交叉熵损失。
考虑到文档图像有不同的大小,文中把实际的坐标缩放到虚拟的坐标:把实际的坐标缩放到 0-1000 范围内。使用基于 ResNet-101 的 Faster R-CNN,预训练在 Visual Genome 数据集上。
在 8 个 NVIDIA Tesla V100 32GB GPU 上训练,batch size 大小 80,Adam 优化器初始学习率 5e-5 并且线性衰减。Base 模型需要 80 小时完成 1100 万个文档上的一个 epoch,Large 模型将近 170小时一个 epoch。
StructuralLM
网络架构与 LayoutLM 一样,只是输入的处理方式不一样,使用预训练的 RoBERTa 初始化
认为模型知道哪些单词在一个 cell 里是很重要的,所以 StructuralLM 学习了 cell 级别的布局信息。

Masked visual-Language Model
Cell Position Classification
把一张图像分成相同大小的 N 个区域,mask 一些 cell 的位置,让模型去预测这些 cell 属于哪个区域,这样,模型就能学习到 cell 和 layout 的关联



LayoutLM v2

Overview
与 LayoutLM 的不同以及改进点:
- LayoutLM 是在微调阶段与图像向量相结合,而 LayoutLMv2 在预训练阶段就将图像向量相结合,这样可以利用 Transformer 学习文本和视觉信息的交互信息。
- LayoutLMv2 在预训练阶段不仅使用了 Masked visual-Language Model 而且还使用了文本图像对齐(text-image alignment)和文本图像匹配(text-image matching)策略。
- LayoutLMv2 使用了空间感知自注意力机制(spatial-aware self-attention mechanism)。
LayoutLM v2


Model Architecture
LayoutLMv2 使用多模态 Transformer 作为主干网络。多模态 Transformer 接受三个模态的输入:文本、图像和布局。每个模态的输入都转换到向量空间,通过编码器进行融合。
Text Embedding
使用现成的 OCR 工具和 PDF 解析器识别文本并按照合理的阅读顺序把他们连接起来。我们使用 WordPiece 对文本序列进行标记化,并将每个标记分配给特定的片段 s i ∈ { [ A , B ] } s_i \in \{[A, B]\} si∈{[A,B]} 。使用 [CLS] 作为序列的开始,[SEP] 作为文本段的结束。限制文本序列的长度,以确保最终序列的长度不大于最大序列长度 L。如果文本序列仍然比 L 短,会在 [SEP] 后边进行填补 [PAD]。
最终的文本向量是三个向量部分之和。词向量表示词本身,一维位置向量表示字段的索引,片段向量用来区分不同的文本片段。则第 i 个文本向量表示为:
t i = TokEmb ( w i ) + PosEmb1D ( i ) + SegEmb ( s i ) , 0 ≤ i ≤ L \mathbf{t}_i = \text{TokEmb}(w_i) + \text{PosEmb1D}(i) + \text{SegEmb}(s_i), 0 \leq i \leq L ti=TokEmb(wi)+PosEmb1D(i)+SegEmb(si),0≤i≤L
Visual Embedding
使用 ResNeXt-FPN 作为视觉编码器的主干网络。给定文档图像 I I I,缩放到 224 × 224 224 \times 224 224×224 大小输入到视觉主干网络中,然后将特征图通过平均池化转换为固定尺寸( W × H W \times H W×H),接下来把它展平为 WH 的视觉向量序列。因为 CNN 视觉主干不能捕获位置信息,所以增加了一维位置向量。这个一维位置向量和文本向量层的是共享的。对于片段向量,全部都设置为视觉片段 [C]。则第 i 个视觉向量表示为:
v i = Proj ( VisTokEmb ( I ) i ) + PosEmb1D ( i ) + SegEmb ( [ C ] ) , 0 ≤ i ≤ W H \mathbf{v}_i = \text{Proj}(\text{VisTokEmb}(I)_i) + \text{PosEmb1D}(i) + \text{SegEmb}([C]), 0 \leq i \leq WH vi=Proj(VisTokEmb(I)i)+PosEmb1D(i)+SegEmb([C]),0≤i≤WH
Layout Embedding
布局向量是将空间布局信息进行向量表示,空间布局信息使用视觉的边界框(用角点坐标和框形状标识)来表示。与 LayoutLM 相同,把全部的坐标都缩放到 0-1000 之间,使用两个向量层去编码 x 轴和 y 轴的位置特征。给定标准化的第 i 个文本/视觉标记的边界框 box i = ( x 0 , x 1 , y 0 , y 1 , w , h ) \text{box}_i = (x_0, x_1, y_0, y_1, w, h) boxi=(x0,x1,y0,y1,w,h) ,布局向量层把六个边界框特征拼接起来构成一个布局向量,即二维的位置向量:
l i = Concat ( PosEmb2D x ( x 0 , x 1 , w ) , PosEmb2D y ( y 0 . y 1 , h ) ) , 0 ≤ i ≤ W H + L \mathbf{l}_i = \text{Concat}(\text{PosEmb2D}_x(x_0, x_1, w), \text{PosEmb2D}_y(y_0. y_1, h)), 0 \leq i \leq WH + L li=Concat(PosEmb2Dx(x0,x1,w),PosEmb2Dy(y0.y1,h)),0≤i≤WH+L
需要注意的是,CNN 进行了局部变换,可以将视觉向量逐个映射回图像区域,既不重叠也不省略。在布局向量层中,视觉向量可以看作是一些均匀划分的网格,因此它们的边界框坐标很容易计算。[CLS]、 [SEP] 和 [PAD]标记的布局向量特征使用空的边界框 box P A D = ( 0 , 0 , 0 , 0 , 0 , 0 ) \text{box}_{PAD} = (0, 0, 0, 0, 0, 0) boxPAD=(0,0,0,0,0,0)
Multi-modal Encode with Spatial-Aware Self-Attention Mechanism
编码器将视觉向量和文本向量拼接到统一的序列 X X X,并且添加布局向量融合空间信息,得到第一层的输入 x ( 0 ) \mathbf{x}^{(0)} x(0)
x i ( 0 ) = X i + l i , where X = { v 0 , . . . , v W H − 1 , t 0 , . . . , t L − 1 } \mathbf{x}_i^{(0)} = X_i + \mathbf{l}_i, \text{where} \; X = \{\mathbf{v}_0,...,\mathbf{v}_{WH-1}, \mathbf{t}_0, ...,\mathbf{t}_{L-1}\} xi(0)=Xi+li,whereX={v0,...,vWH−1,t0,...,tL−1}
因为原始的自注意力机制只能隐式地捕获带有绝对位置提示的输入标记之间的关系,为了有效地对文档布局中的局部不变形建模,需要明确地插入相对位置信息。因此,文中提出了空间感知的自注意力机制。原始的自注意力机制通过映射 query x i \mathbf{x}_i xi 和 key x j \mathbf{x}_j xj 这两个向量,然后计算它们两个的注意力分数:
α i j = 1 d h e a d ( x i W Q ) ( x j W k ) ⊤ \alpha_{ij} = \frac{1}{\sqrt{d_{head}}} (\mathbf{x}_iW^Q)(\mathbf{x}_jW^k)^{\top} αij=dhead1(xiWQ)(xjWk)⊤
文中将语义相对位置和空间相对位置作为偏置项,并明确地将它们添加到注意力得分中。 b 1 D , b 2 D x , b 2 D y \mathbf{b}^{1D},\mathbf{b}^{2D_x}, \mathbf{b}^{2D_y} b1D,b2Dx,b2Dy 分别表示一维和二维相对位置偏置。不同的注意力头偏置使不同的,但是在全部的编码器层是共享的。假设 ( x i , y i ) (x_i, y_i) (xi,yi) 表示第 i 个边界框的左上角坐标,则空间感知注意力得分为
α i j ′ = α i j + b j − i 1 D + b x j − x i 2 D x + b y j − y i 2 D y \alpha_{ij}' = \alpha_{ij} + \mathbf{b}^{1D}_{j-i} + \mathbf{b}^{2D_x}_{x_j - x_i} + \mathbf{b}^{2D_y}_{y_j - y_i} αij′=αij+bj−i1D+bxj−xi2Dx+byj−yi2Dy
最终,输出向量表示为全部映射 value 向量相对于归一化空间感知得分的加权平均值:
h j = ∑ j exp ( α i j ′ ) ∑ k exp ( α i k ′ ) x j W V \mathbf{h}_j = \sum_j \frac{\exp(\alpha_{ij}')}{\sum_k \exp(\alpha_{ik}')} \mathbf{x}_j W^V hj=j∑∑kexp(αik′)exp(αij′)xjWV
Pre-training
与 LayoutLM 一样,在 IIT-CDIP Test Collection 1.0 做预训练
Mask Visual-Language Modeling
作为对 LayoutLM 1.0 的扩展,2.0使用的 mask 视觉语言模型任务要求模型根据图文和布局信息中的上下文还原文本中被遮盖的词,对文本中的词和图像中的对应区域 mask,但保留空间位置信息。更关注模型的语言能力。
Text-Image Alignment
文档图像上随机按行 mask 一部分文本,利用模型的文本部分输出进行词级别二分类,预测每个词是否被 mask 。文本—图像对齐任务帮助模型对齐文本和图像的位置信息。有助于帮助模态信息对齐。
Text-Image Matching
随机地替换或舍弃一部分文档图像,构造图文失配的负样本。以文档级二分类的方式预测图文是否匹配,以此来对齐文本和图像的内容信息。
Fine-tuning
只需要在 LayoutLMv2 的输出上构建一个指定任务的头部,并使用恰当的损失对整个模型进行微调。LayoutLMv2 将文本、布局和图像信息整合到一个单一的多模态框架中,从而获得了更好的性能,与 LayoutLM 相比,这大大提高了跨模态的相关性。
Experiments
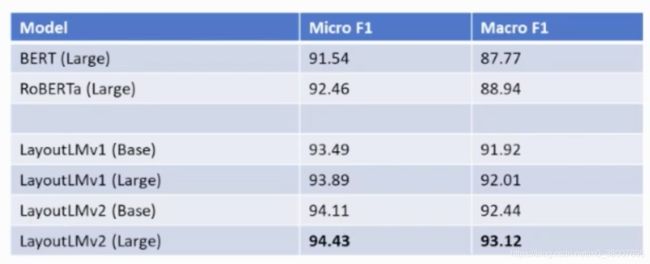
- FUNSD

- CORD:票据关键信息提取数据集,数据集包括 800 张训练集票据,100 张验证集票据和 100 张测试集票据。每张票据都配有一张照片和一张 OCR 标注列表。由于背景中可能有不相关的东西,因此每个照片都提供了包含接收区域区域的 ROI。我们只使用ROI作为输入,而不是原始照片。数据集定义了4个类别下的 30个字段,任务的目的是将每个单词标记到正确的字段。

- SROIE

- Kleister-NDA:包含从 EDGAR 数据库中收集的保密协议,其中训练文件 254 份,验证文件 83 份,测试文件 203 份。定义此任务是为了提取四个固定键的值。我们从官方的评估工具中得到实体级别的 F1 得分。从原始PDF文件中提取单词和边框。文中使用启发式来定位实体跨度,因为规范化的标准答案可能不会出现在话语中。

- RVL-CDIP
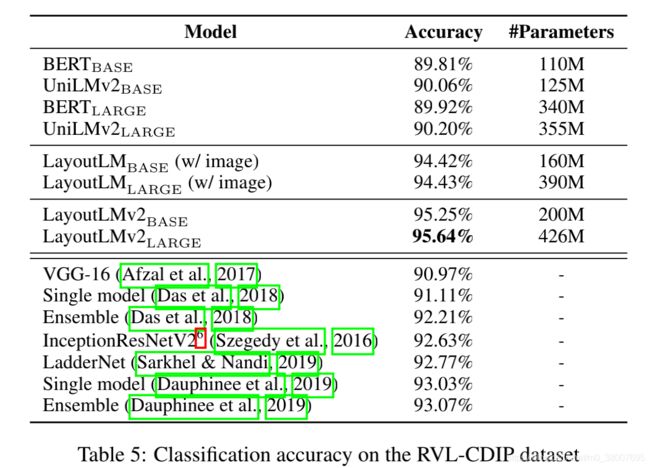
- DocVQA:文档理解领域的 VQA 数据集,由 50000 个问题组成,在超过 12000 页的文件中定义。页面被分成训练集、验证集和测试集,比例约为 8:1:1。数据集被组织为一组三元组 (图像,问题,答案) 。使用 Microsoft Read API 从图像中提取文本和边框。启发式被用来在抽取的文本中寻找给定的答案。该任务使用基于编辑距离的度量 ANLS (即平均归一化Levenshtein相似性) 进行评估。考虑到人类在测试集上的性能约为 98% 的ANLS,可以合理地假设在训练和验证集上达到超过97%的ANLS的ground truth 足以训练一个模型。测试集的结果由官方评估站点提供。

- Invoice Understanding (微软内部数据)
训练:10000,测试 600, 16个实体类

LayoutXLM
多语言通用文档理解预训练模型LayoutXLM
使用 SOTA 多语言预训练 InfoXLM 模型初始化
Mask Visual-Language Modeling
LayoutLMv2 是把每个单词作为一个 token,而对于多语言这种策略不适用,所以 LayoutXML 获取到每个字符的 bbox,然后使用 SentencePiece 分词,在把通过合并字符的 bbox 得到分词后的 bbox。
Pre-training Data
在 53 种语言的数据上做预训练,多语言文档数据集 2200 万(数字文档),英文数据集 800 万(扫描文档)
XFUND
https://github.com/doc-analysis/XFUND
- 八种语言:
英文、中文、日文、西班牙语、法语、意大利语、德语、葡萄牙语 - 每种语言 199 个文档图像(无重复模板)
149 训练,50 测试 - Labels
Header,Key-Value,Others
SER: Semantic Entity Recognition (headers, keys, values)
RE: Relation extraction for key-value pairs