Pytorch基础(Tensor)
文章目录
- 前言
- 环境
- tensor 与 numpy
- tensor 使用
-
- 基本使用
- numpy与tensor转换
- 有“_”尾巴的函数
- 梯度
-
- 梯度使用
- 取消梯度
- 复制
「这是我参与2022首次更文挑战的第7天,活动详情查看: 2022首次更文挑战」
本博文优先在掘金社区发布!
前言
ok,现在到了我们第五个大工具的使用(前面的sklearn在本系列当中已经有了,当然后续会不断介绍(学习)新的算法,进行补充更新,所以现在我们来熟悉熟悉我们的第五个工具pytorch,这里申明一点的是,这些工具没有高低之分,学起来其实都是一样的,前提是前面的三大工具必须掌握)。你用sklearn少不了pandas,你用pytorch也差不多。同样的这个工具也不难,不管后面玩不玩人工智能,能够用这个加上树莓派做一个好玩的东西其实也不错,当然我肯定是要玩的,要么成为牛叉的架构师,要么成为算法落地工程师!
首先pytorch是一个框架,所以pytorch它实际上分为了好几个模块,一个是专门读取数据,类型转换的模块,一个是构建神经网络的模块,还有一个是模型评估模块,当然pytorch本身还是一个numpy的增强工具,所以本身还有一些来自numpy的属性。所以我们先来说说它本身来自numpy的属性。
(如何下载安装就别问了,前面说过本系列都是需要python基础的)
环境
这里注意一下,我的环境是Windows10,N卡,装的pytorch版本是GPU版本,CUDA驱动版本是10.1(10.2也是一样的)
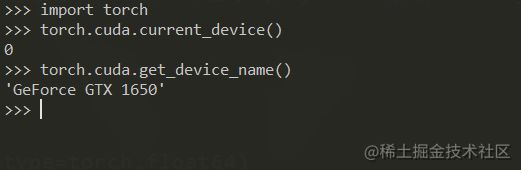
可以看到,我这边的显卡是GTX1650
没有显卡的朋友不要慌,我们可以使用谷歌实验室,当然你得会那啥。免费,一个礼拜30个小时的使用时长,代码你可以在本地写好,然后改成GPU版本,放到实验平台先跑一下,能过,然后在完整地训练一下。
tensor 与 numpy
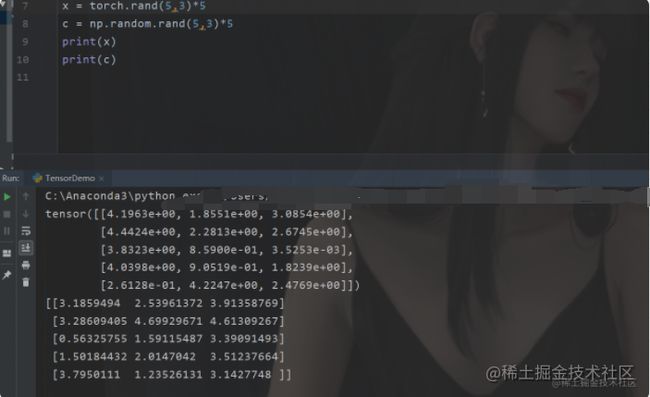
在我们的pytorch包括TensorFlow里面经常会出现Tensor这个词,这个其实就是它的基本数据结构,这个玩意其实和我们的numpy的那个结构是一样的,其实就是那个结构,只是他现在叫Tensor,区别就是在我们的深度学习框架里面这个Tensor可以做GPU加速!你们可以先感受一下
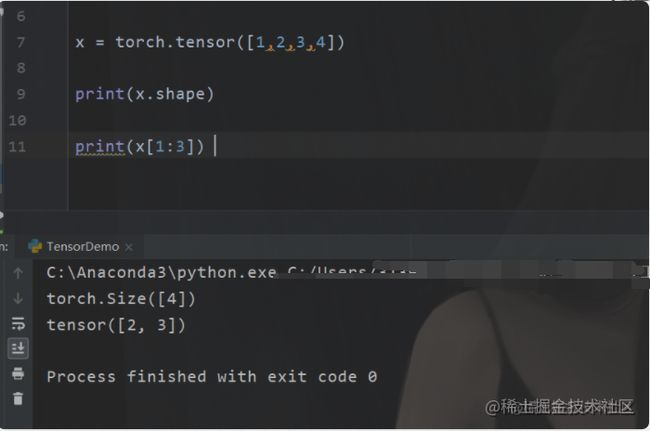
所以其实tensor的一些操作(除了CURD)基本上和numpy其实差不多,而numpy又具备了很多list的特性,所以tensor也一样
所以python就是老流氓嘛,用python写算法直接开挂。
在flink里面我想用元组,我还得调用scale封装的API Tuple,python直接一个小括号搞定,直接耍流氓。
当然回到主题,我们说tensor还能够在GPU里面运行,那我们来看看例子。
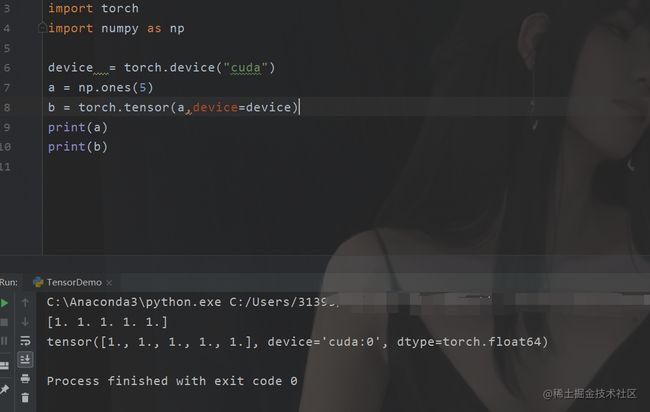
现在我们的代码就已经在我们的GPU里面了。那么除此之外还有什么差别嘛,有的。梯度
这个梯度 就是我们高数里面的内容。Pytorch可以自动求导,主要是在神经网络里面需要反向传播嘛。(好吧不太理解神经网络的话,这个确实不好理解,我前面也有博文提到了这个,应该是算是说的比较明白了,也是在本专栏)
tensor 使用
基本使用
这部分内容不多,也不复杂,很多和numpy类似,具体的可以查看这篇文章
Tensor 常用操作
我这里主要说说,不一样的细节。
numpy与tensor转换
我们的numpy和tensor是可以相互转换的。
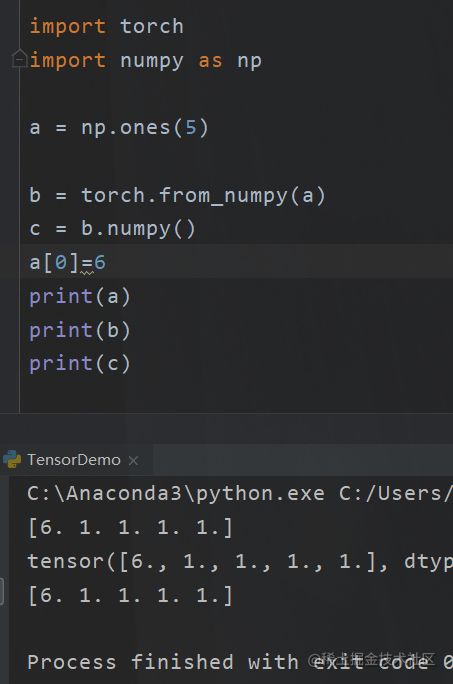
但是注意两点,第一
只有都在CPU上的才能相互转换
第二点
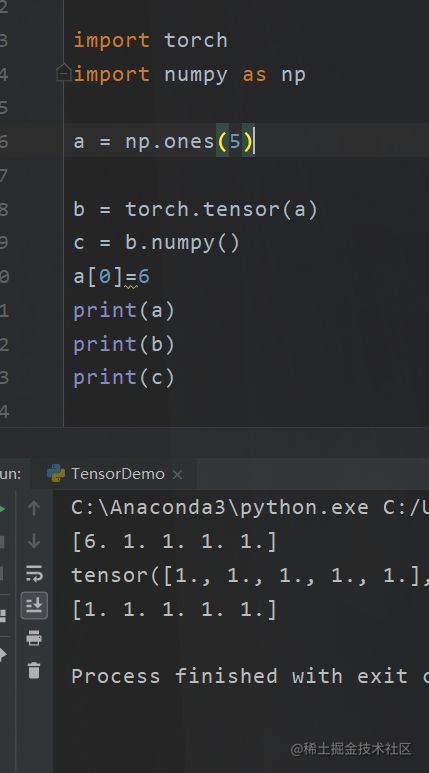
直接使用from_numpy的是指向了同一个地址
如果想创建新的
b = torch.tensor(a)
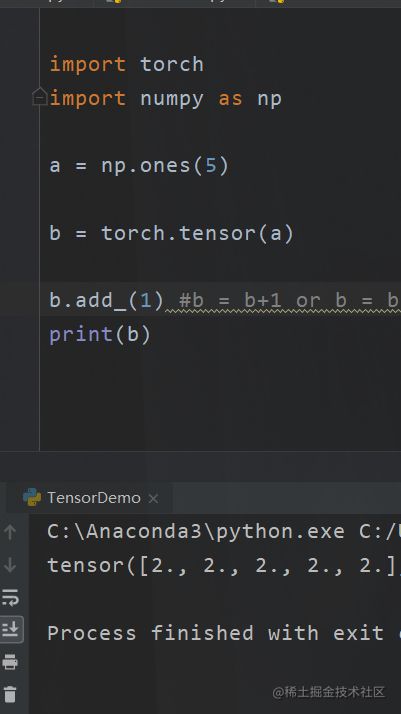
有“_”尾巴的函数
在pytorch当中你会见到很多这样的类型的函数add_()
最后面有个“_“
这个函数的意思是说,把处理后的值进行覆盖。例如
梯度
梯度使用
这个是tensor里面很重要的东西之一。
顾名思义就是求梯度,先来一个例子你们就明白了。
import torch
a = torch.tensor([[1,1,4,4],[4,4,4,4]],requires_grad=True,dtype=torch.float) #初始化的tensor a
b = a**2 # 等价与 x ^2
c = b.sum() # 求和
print(c)
c.backward() # 反向传递(相当于求导)
print(a.grad) #结果,指的是有 a 到 c 的变化的梯度
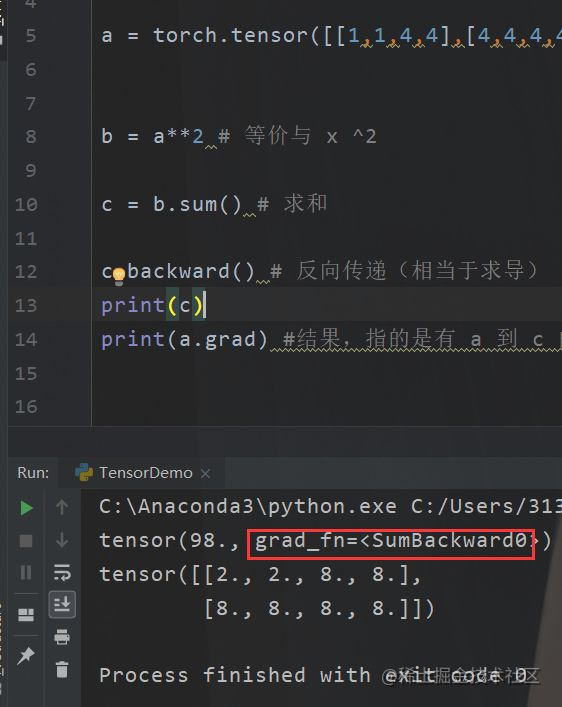
这个我其实可以解释一下,看好了
首先是 a 我们把a想象成一个函数
A(x) = {[X1,X2,4*(X3),4*(X4)],[...]}
现在我们乘以^2
于是就变成了
A^2(x) = {[X1^2,X2^2,4*(X3^2)...]}
后面我们求和
于是又变成了
Sum(A^2) = {[X1^2+X2^2+4*(X3^2) ...])
对这个函数求偏导,然后再还原成矩阵的样子,不就是
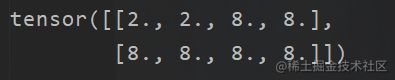
这里开始注意一个细节,那就是,我们是a – >c的过程的反向传播,也就会a --> c的梯度,a 是我们的根节点,只有a才会有我们的梯度。
不然你可以看看b 的梯度。
之所以要说这个是因为一方面是我们的后面要用,还有一方面使我们关于 tensor的复制
取消梯度
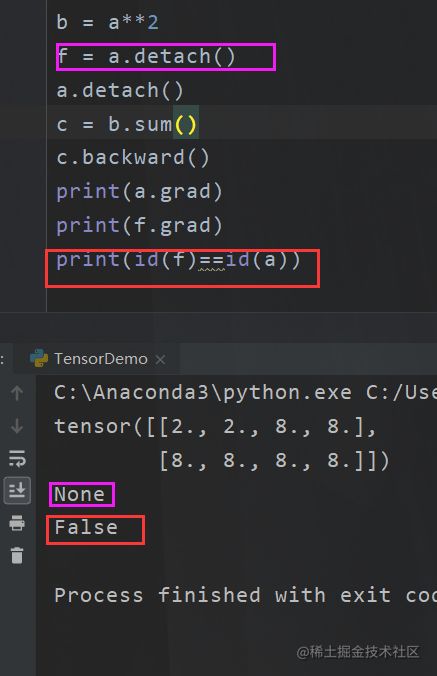
当你声明detach()的时候就不会有了,此外
import torch
import numpy as np
a = torch.tensor([[1,1,4,4],[4,4,4,4]],requires_grad=True,dtype=torch.float)
a.requires_grad_(False) # 等价 torch.tensor(数据,requires_grad=True)
a.detach()
b = a**2
f = a.detach()
a.detach()
c = b.sum()

直接不让,也行,或者
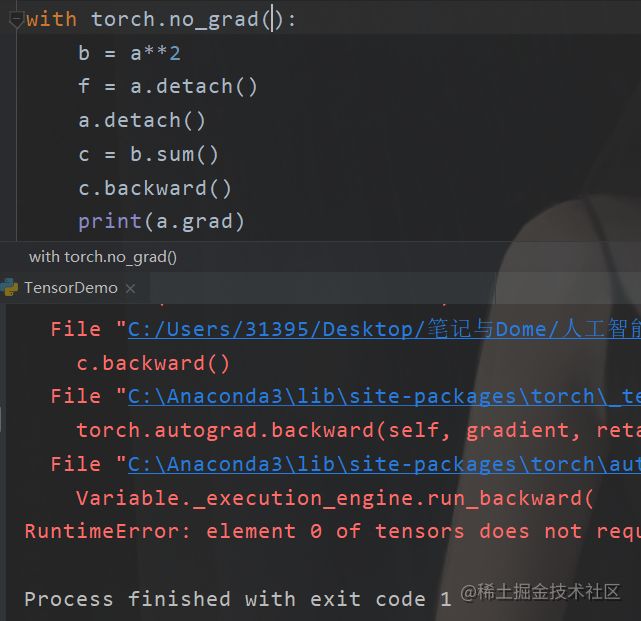
复制
之所以要先说梯度,原因是一方面要用,还有一方面是复制的时候要注意,还记得深度拷贝嘛,假设我们要用的话.
首先我们想要克隆或者深度拷贝,一个玩意。我们注意,前面我们不是说只要叶子节点最后才能拿到梯度吗。我们想要拷贝使用clone() 或者 copy_() 都类似(前者常用)

所以有时候为了拿到梯度,让两个变量彻底无关,所以我们要
>>> a = torch.tensor(1.0, requires_grad=True)
>>> b = a.clone().detach()
基本上这些就是我们关于tensor的一些细节,明天开始就介绍,pytorch工具箱,
介绍搭建神经网络,我们搭建一个简单的CAIRF10,也就是一个CNN的分类模型。