mmdetection初步使用
关于环境
在linux上部署非常简单,直接按照本篇知乎操作即可(虽然作者起的名字是在windows上部署)windows下安装mmdetection。windows上可能会有各种小问题。
其中,cuda的安装和配置需要注意的就是版本对应问题,mmcv 需要注意一定要安装mmcv-full,还有下载链接后面的一大串,对应不同的cu版本和torch版本:
![]()
然后github上clone项目,安装即可。mmdet 是自定义的库函数组件,也是这一步才安装的。
关于框架
先放一个官方文档的链接,Welcome to MMDetection’s documentation! — MMDetection 2.25.0 documentation。下面是有助于初次使用的一些整理和理解。

【重点】一般情况下,用人话来形容,我们需要使用 tools 目录下的驱动脚本,训练(train.py),推理(test.py)或者分析(analysis_tools 目录下) 通过 configs 定义的模型。而 mmdet 目录对使用者而言则不太接触,往往是被调用的一些组件。
这里详细介绍一下configs目录,里面有众多网络的核心配置,但其实我们只需要掌握 _base_目录,就可以快速的入手进行训练,这里部分参考了mmdetection的初步使用 - 知乎 (zhihu.com)做出总结:
-
datasets文件目录下的,为数据集相关配置文件;这里你需要定义的有【数据集名称,路径,数据集格式,数据集预处理方式和读取方式】,举个栗子:
# dataset settings # 数据集名称,路径参数 dataset_type = 'CocoDataset' data_root = 'data/coco/' # 标准化处理的配置,色彩通道的转化 img_norm_cfg = dict( mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) # 训练(测试)时的pipeline顺序,一般是封装好的强化操作 train_pipeline = [...] test_pipeline = [...] # 数据集(路径,类型,图片前缀等) data = dict( # 每个GPU的batch_size,注意不能让其超过显存 samples_per_gpu=2, # 每个GPU的workers workers_per_gpu=2, train=dict(...),, val=dict(...), test=dict(...) # 每隔interval个epoch会进行一次evaluation,指标为bbox evaluation = dict(interval=1, metric='bbox')如果说,这里我们想要使用自定义的数据集,首先是要符合定义的几种格式,然后一般情况下需要修改的就只有路径。因为数据增强往往和基础网络挂钩,每个都有着最好的固定参数。
不过,需要额外关注的一点在于有关
batch_size的问题,每个GPU的batch_size乘以GPU数量就是总的。而学习率lr需要和总batch_size成正比。 -
models文件目录下,为一些经典模型配置;他们以字典的形式定义,一个完整的网络结构包含backbone, neck, head以及其他配置,这里面会涉及怎么选取,还有调参问题,要针对不同的数据集类型和网络进行配置。
- 其中,backbone为基础网络,也就是预训练好的通用物体识别模型,比如
resnet,darknet,vgg等。 “核心在于能为检测提供若干种感受野大小和中心步长的组合,以满足对不同尺度和类别的目标检测”(Lighthouse - 知乎 (zhihu.com)有三个部件的具体讲解视频)。 - neck为对复杂特征的提取,其作用是“将具有不同感受野大小的特征图进行耦合,从而增强表达能力”,往往使用
FPN,它对Backbone提取到的重要特征,进行再加工及合理利用,有利于下一步head的具体任务学习。 - head则是针对特定任务的输出部分,往往可以简单的通过看有没有anchor,有没有quality两个方面来学习。往往结构较为简单,通过分类和回归来确定最终框的类别和位置,通过quality进行简单的评估或者置信调整。
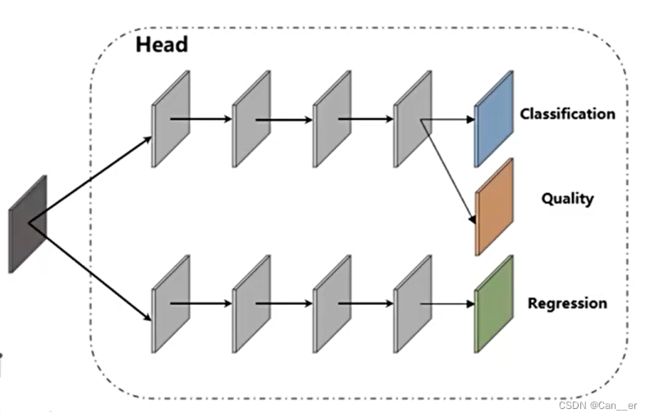
- 其中,backbone为基础网络,也就是预训练好的通用物体识别模型,比如
-
schedules文件目录下,主要是对potimizer和lr,以及runner组件的配置,看一个例子就明白了。有关学习率的参数定义可以看这里 教程 6:如何自定义优化策略 — MMClassification 0.23.1 文档,基本和pytorch中的接口一致。
# optimizer
optimizer = dict(type='Adam', lr=0.0001, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=200,
warmup_ratio=0.001,
step=[5, 8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)
- 此外,在同级目录还有一个default_runtime.py文件,对运行环境,输出,hook等做出了规定,一般我们需要关注的只有前两行。
# checkpoints hook配置文件,每隔多少epoch保存一次pth文件
checkpoint_config = dict(interval=1)
# 多少个样本输出一次hook信息,每隔多少epoch保存一次logger
log_config = dict(
interval=100,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
关于使用
上面的框架结构清楚之后,我们修改自己需要定义的部分,然后用一个文件连接起来,这里以自带的faster_rcnn为示例,对应的就是上面介绍的几个文件。
# faster_rcnn
_base_ = [
# 模型
'../_base_/models/faster_rcnn_r50_fpn.py',
# 数据集
'../_base_/datasets/coco_detection.py',
# 优化器
'../_base_/schedules/schedule_1x.py',
# 训练方式
'../_base_/default_runtime.py'
]
此外,会发现并不是所有的框架都是采用上面这4个组件构成的方式,这是因为在许多网络的变体上,仅仅变了某一部分,我们可以在 _base_ 目录中给出的几个基本框架上,通过在代码中 “引用+覆写” 的形式构成新网络。
当然,直接把上面的几个组件写到同一个文件,或者仅采取某几个重用的文件也是同样可以的,比如yolo和fcos,都是_base_中没有核心模型,而是在自己的目录下单独定义的:
_base_ = [
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# model settings
model = dict(
type='FCOS',
# 模型单独定义
}
我们使用命令行的方式运行该py文件,就可以完成训练等操作,譬如这里我自己定义的包含以上组件的网络叫做 mynetwork.py,那我只需要:
python tools/train.py mynetwork.py
同样的,利用tools中的工具,可以完成预测,标注,结果检测等很多工作~