redis学习归纳
一、概述
- Redis是什么?
Redis(Remote Dictionary Server ),即远程字典服务 ! Nosql数据库
是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。

redis会周期性的把更新的数据写入磁盘或者把修改操作(全量和增量)写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
免费和开源!是当下最热门的 NoSQL 技术之一!也被人们称之为结构化数据库!
- Redis能干嘛?
1、内存存储、持久化,内存中是断电即失、所以说持久化很重要(rdb、aof)
2、效率高,可以用于高速缓存(适用于查询多修改少的场景)
3、发布订阅系统
4、地图信息分析
5、计时器、计数器(浏览量!)
6、…
二、redis基本了解
redis是一个开源的,内存中的数据结构存储结构,它可以用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如字符串(string)、散列表(hash)、列表(list)、集合(set)、有序集合(hset)与范围查询,bitmaps、hyperloglogs和地理空间(geospatial)索引半径查询。
redis内置了复制、LUA脚本、LRU驱动事件,事务和不同级别的磁盘持久化,并通过redis哨兵和自动分区提供高可用。
三、redis的五大数据类型
1、string(字符串)
①添加、查询、追加、获取长度,判断是否存在的操作
添加:set key val
查询:get key
判断是否存在:exists key
追加:append key val
获取长度:strlen key
②自增、自减操作
可用作页面浏览量之类
先初始化一个0数据:set num 0
自增1: incr num
自减1:decr num
自增10: incr num10
自减10: decr num10
③截取、替换字符串操作
GETRANGE key1 04 #截取字符串,相当于java中的subString,下标从0开始,不会改变原有数据
SETRANGE key2 5888 #此语句跟java中replace有点类似,下标也是从0开始,但是有区别:java中是指定替换字符,Redis中是从指定位置开始替换,替换的数据根据你所需替换的长度一致,返回值是替换后的长度
④设置过期时间、不存在设置操作
可用作分布式锁
#设置过期时间,跟Expire的区别是前者设置已存在的key的过期时间,而setex是在创建的时候设置过期时间
setex name 15 ceshi
ttl name # 查看key为name的key的过期时间
#不存在设置
setnx name lhs #如果key为‘name’不存在,新增数据,返回值1证明成功
⑤mset、mget操作
同时设置多个值(原子性操作)或同时获取多个值
⑥添加获取对象、getset操作
getset name1 dingdada1 #先get再set,先获取key,如果没有,set值进去,返回的是get的值
如果有把原来的值替换掉
⑦总结
String是Redis中最常用的一种数据类型,也是Redis中最简单的一种数据类型。首先,表面上它是字符串,但其实他可以灵活的表示字符串、整数、浮点数3种值。Redis会自动的识别这3种值。
- List(列表)
①lpush(左插入)、lrange(查询集合)、rpush(右插入)
②lpop(左移除)、rpop(右移除)
③lindex(查询指定下标元素)、llen(获取集合长度)
④lrem(根据value移除指定的值)
⑤ltrim(截取元素)、rpoplpush(移除指定集合中最后一个元素到一个新的集合中)
⑥lset(更新)、linsert操作
⑦小结:
-
- 实际上是一个链表,before Node after , left,right 都可以插入值
- 如果key 不存在,创建新的链表
- 如果key存在,新增内容
- 如果移除了所有值,空链表,也代表不存在!
- 在两边插入或者改动值,效率最高! 中间元素,相对来说效率会低一点~
- 消息排队!可作为队列 (Lpush Rpop)使用,也可用作 栈( Lpush Lpop)!
3.Set(集合)元素唯一不重复
①sadd(添加)、smembers(查看所有元素)、sismember(判断是否存在)、scard(查看长度)、srem(移除指定元素)
②srandmember(抽随机)
③spop(随机删除元素)、smove(移动指定元素到新的集合中)
④sdiff(差集)、sinter(交集)、sunion(并集)
⑤总结:可用作使用寻找共同好友,共同关注之类需求
4.Hash(哈希)
①hset(添加hash)、hget(查询)、hgetall(查询所有)、hdel(删除hash中指定的值)、hlen(获取hash的长度)、hexists(判断key是否存在)
②hkeys(获取所有key)、hvals(获取所有value)、hincrby(给值加增量)、hsetnx(存在不添加)
③总结:比String类型相比来说更加适合存对象类型数据
5.zSet(有序集合)
①zadd(添加)、zrange(查询)、zrangebyscore(排序小-大)、zrevrange(排序大-小)、zrangebyscore withscores(查询所有值包含key)操作
②zrem(移除元素)、zcard(查看元素个数)、zcount(查询指定区间内的元素个数)操作
③总结:成绩表排序,工资表排序,年龄排序等需求可以用zset来实现
zSet实现是根据跳表的数据结构(和b+树的某个节点类似),时间复杂度为O(logn)
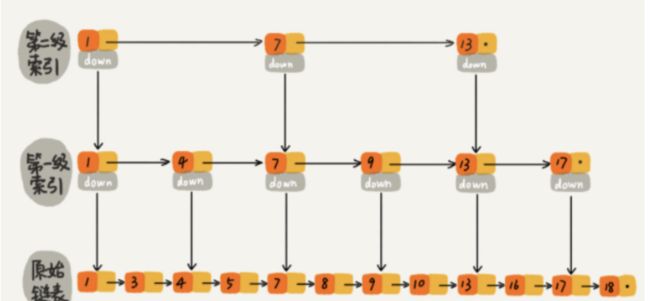
四、三大特殊数据类型
- Bitmap: 位存储
Bitmap 位图,数据结构! 都是操作二进制位来进行记录,就只有0 和 1 两个状态!
①setbit(添加)、getset(获取)、bitcount(统计)操作
setbit login 1 1 #添加周一已登陆 为1
setbit login 2 1
setbit login 3 1
setbit login 4 0 #添加周四未登陆 为0
setbit login 5 1
setbit login 6 1
setbit login 7 1
bitcount login #统计这周登陆的天数
②总结:实际需求中,可能需要我们统计用户的登陆信息,员工的打卡信息等等。只要是事务的只有两个状态的,我们都可以用Bitmap来进行操作!!!
2.Hyperloglog: 基数
首先得明白什么是基数?
再数学层面上可以说是:两个数据集中不重复的元素~
举个列子:比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
但是再Redis中,可能会有一定的误差性。 官方给出的误差率是0.81%。
Hyperloglog的优点: 占用的内存是固定的,2^64个元素,相当于只需要12kb的内存即可。效率极高!
①pfadd(添加数据集)、pfcount(统计数据集)、pfmegre(合并数据集-自动去重)
pfadd dataList 1 2 3 4 5 6 7 #添加数据集
pfcount dataList #统计数据集中的元素
#将dataList 和dataList1 两个数据集合并成一个新的 newdata数据集,并且自动去重
pfmerge newdata dataList dataList1
②总结:如果在实际业务中,允许一定的误差值,我们可以使用基数统计来计算~效率非常高!比如:
统计注册 IP 数
统计每日访问 IP 数
统计页面实时 UV 数
统计在线用户数
统计每天搜索不同词条的个数
统计真实文章阅读数
等等
3.Geospatial: 地理位置
经纬度查询:经纬度查询 - 坐标拾取系统
注意点1:两极无法直接添加,我们一般会下载城市数据,直接通过java程序一次性导入!
注意点2:有效的经度从-180度到180度。
注意点3:有效的纬度从-85.05112878度到85.05112878度。
注意点4:m 为米。km 为千米。mi 为英里。ft 为英尺。
①geoadd(添加)、geopos(查看)、geodist(计算距离)操作
#添加城市经纬度 语法格式: geoadd key 经度 纬度 name +++可多个添加#添加成功后返回添加成功的数量值
geoadd city 118.8921 31.32751 nanjing
117.30794 31.79322 hefei
102.82147 24.88554 kunming
ZRANGE city 0 -1 #查看录入城市信息
geopos city nanjing #查看看指定城市的经纬度信息
geodist city nanjing hefei #计算南京到合肥之间的距离,默认返回单位是m
geodist city nanjing hefei km #km 千米
②georadius(查询附近位置)操作
#查看指定位置的1000公里范围内有哪些城市
georadius city 120 38 1000 km
③ georadiusbymember (查找指定元素指定范围内的元素)、geohash (返回经纬度的hash值)、zrange、zrem(使用zset命令操作geo)
④总结:实际需求中,我们可以用来查询附近的人、计算两人之间的距离等。
五、Redis中的事务和乐观锁如何实现?
- 事务
①原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做。
②一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
③隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
④持久性(durability)。持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
在Redis事务没有没有隔离级别的概念!
在Redis单条命令式保证原子性的,但是事务不保证原子性!
- 乐观锁
①当程序中可能出现并发的情况时,就需要保证在并发情况下数据的准确性,以此确保当前用户和其他用户一起操作时,所得到的结果和他单独操作时的结果是一样的。
②没有做好并发控制,就可能导致脏读、幻读和不可重复读等问题。
在Redis是可以实现乐观锁的!
一、Redis如何实现事务?
①正常执行事务
开启事务命令:multi
set name lhs #添加数据
set age 22 #添加数据
exec 执行事务
事务执行成功才能获取数据
②放弃事务
开启事务命令:multi
set name lhs #添加数据
set age 22 #添加数据
discard #放弃事务
放弃事务将不能获取数据
③编译时异常,代码有问题,或者命令有问题,所有的命令都不会被执行
命令输错时会导致编译异常,整个事务不会生效
④运行时异常,除了语法错误不会被执行且抛出异常后,其他的正确命令可以正常执行
比如:对字符串进行了自增操作,其他动作不会影响,只是自增操作不会执行
⑤总结:Redis是支持单条命令事务的,但是事务并不能保证原子性!
二、Redis如何实现乐观锁?
使用watch命令,进行监视
乐观锁和悲观锁的区别。
悲观锁: 认为什么时候都会出问题,所以一直监视着,每次执行需要先获取锁,没有执行当前步骤完成前,不让任何线程执行,十分浪费性能!一般不使用!
乐观锁: 只有更新数据的时候去判断一下,在此期间是否有人修改过被监视的这个数据,没有的话正常执行事务,反之执行失败。例如:通过版本进行cas,如果被修改就重新执行
六、redis持久化方式
Redis 是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以 Redis 提供了持久化功能 !
redis有两种持久化方式
-
- rdb
- aof
一、rdb(快照)持久化
在redis.conf文件中可以配置,一般持久化方式时使用的rdb的持久化方式
rdb文件就是一个二进制文件,恢复数据时很快占用空间小。
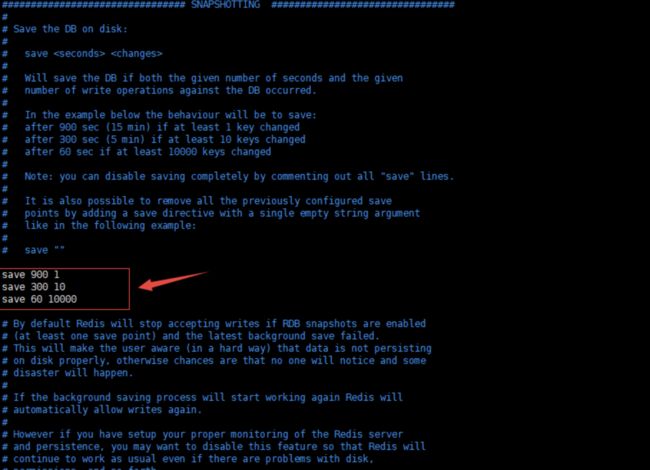
上面的配置代表每900s内进行一次操作就进行一次持久化
300s内进行10次操作和60s内进行10000次操作进行一次持久化
触发时机:
- save命令
- bgsave命令
- serverCron定时任务,满足持久化条件时
- 主从全量复制落盘方式
- aof重写(aof和rdb混合使用方式)
- 优缺点:
优点:
1、适合大规模的数据恢复!
2、对数据的完整性要求不高!
缺点:
1、需要一定的时间间隔进程操作!如果redis意外宕机了,这个最后一次修改数据就没有的了!
2、fork进程的时候,会占用一定的内容空间!
- 总结:
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的。
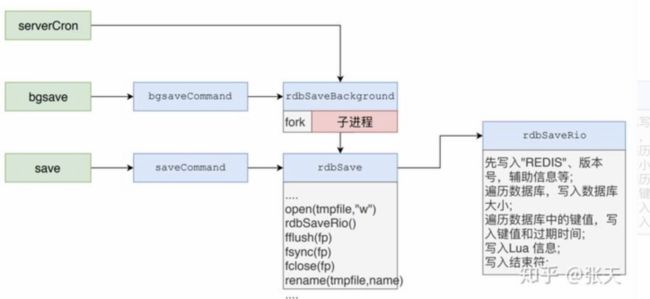
这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。我们默认的就是RDB,一般情况下不需要修改这个配置!
恢复rdb文件
只需将备份的rdb文件放在我们的redis启动目录即可,Redis启动的时候会自动检查dump.rdb文件并恢复其中的数据!
二、aof持久化
①Redis默认使用的是RDB模式,所以需要手动开启AOF模式!
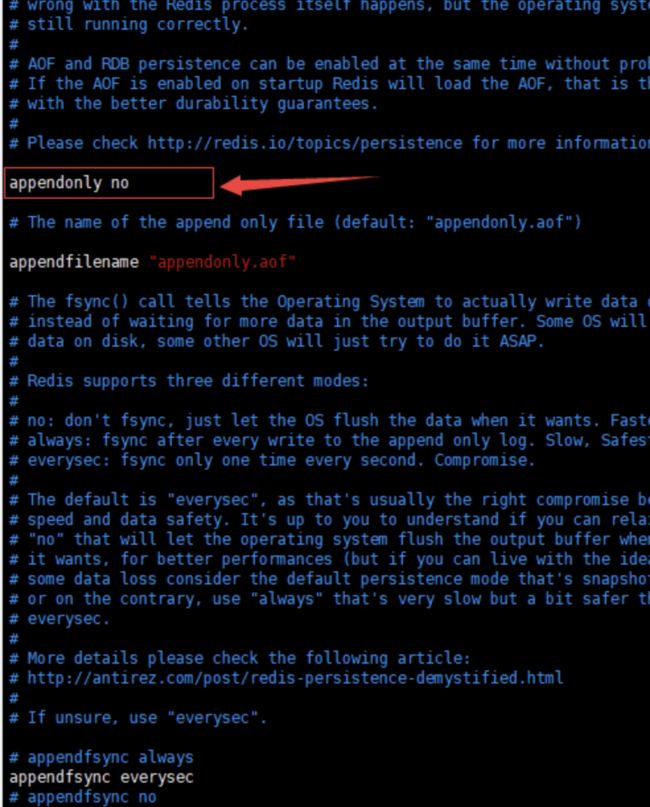
将no改为yes即可
aof文件里就是一条一条的命令,默认在添加数据是会在文件最后面追加添加的命令
# appendfsync always # 每次修改都会 sync。消耗性能
appendfsync everysec # 每秒执行一次 sync,可能会丢失这1s的数据! # appendfsync no # 不执行 sync,这个时候操作系统自己同步数据,速度最快!
appendfilename "appendonly.aof" # 持久化的文件的名字
appendonly no # 默认是不开启aof模式的,默认是使用rdb方式持久化的,在大部分所有的情况下, rdb完全够用!
auto-aof-rewrite-percentage 100 #写入百分比
auto-aof-rewrite-min-size 64mb #写入的文件最大值是多少,一般在实际工作中我们会将其设置为5gb左右!
AOF流程
- Redis Server启动,如果AOF机制打开那么初始化AOF状态,并且如果存在AOF文件,读取AOF文件。
- 随着Redis不断接受命令,每个写命令都被添加到AOF文件,AOF文件膨胀到需要rewrite时又或者接收到客户端的bgrewriteaof命令。
- fork出一个子进程进行rewrite,而父进程继续接受命令,现在的写操作命令都会被额外添加到一个aof_rewrite_buf_blocks缓冲中。
- 当子进程rewrite结束后,父进程收到子进程退出信号,把aof_rewrite_buf_blocks的缓冲添加到rewrite后的文件中,然后切换AOF的文件fd。rewrite任务完成,继续第二个步骤
- 优缺点!
优点:
1、每一次修改都同步,文件的完整性会更加好!
2、每秒同步一次,最多会丢失一秒的数据!
3、从不同步,效率最高的!
缺点:
1、相对于数据文件来说,aof远远大于 rdb,修复的速度也比 rdb慢!
2、Aof 运行效率也要比 rdb 慢,所以我们redis默认的配置就是rdb持久化!
- 总结:以下来自伟大的网友总结!
1、RDB 持久化方式能够在指定的时间间隔内对你的数据进行快照存储
2、AOF 持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以Redis 协议追加保存每次写的操作到文件末尾,Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
3、只做缓存,如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化
4、同时开启两种持久化方式
在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
RDB 的数据不实时,同时使用两者时服务器重启也只会找AOF文件,那要不要只使用AOF呢?建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有AOF可能潜在的Bug,留着作为一个万一的手段。
- 性能建议
因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留 save 900 1 这条规则。
如果Enable AOF ,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了,代价一是带来了持续的IO,二是AOF rewrite(在aof文件慢了之后就会将所有数据重新转换成一条一条的命令) 的最后将 rewrite 过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上,默认超过原大小100%大小重写可以改到适当的数值。
如果不Enable AOF ,仅靠 Master-Slave Repllcation 实现高可用性也可以,能省掉一大笔IO,也减少了rewrite时带来的系统波动。代价是如果Master/Slave 同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个 Master/Slave 中的 RDB文件,载入较新的那个,微博就是这种架构。
七、redis的主从复制模式
一、概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave 以读为主。
主要作用:
①数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
②故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
③负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
④高可用(集群)基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
复制原理:
主从复制过程大体可以分为3个阶段
- 建立连接阶段(即准备阶段)
-
- 主从节点进行socket连接和进行身份验证
- 数据同步阶段
- 命令传播阶段制的工作流程

Slave 启动成功连接到 master 后会发送一个sync同步命令
Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制: Master 继续将新的所有收集到的修改命令依次传给slave,完成同步但是只要是重新连接master,一次完全同步(全量复制)将被自动执行! 我们的数据一定可以在从机中看到!
主从复制,读写分离! 80% 的情况下都是在进行读操作!减缓服务器的压力!架构中经常使用! 一主二从!
八、哨兵模式
一、概述
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑 哨兵模式 。Redis从2.8开始正式提供了Sentinel(哨兵) 架构来解决这个问题。
谋朝篡位 的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的 进程 ,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
二、哨兵架构
哨兵模式的配置文件 sentinel.conf
# sentinel monitor 被监控的名称 host port 1 (代表自动投票选举大哥!)
sentinel monitor myredis 127.0.0.1 6379 1
配置好之后启动即可,它是一个独立的进程。
- 哨兵之间也是互相监控的,基于心跳模式对主机和从机进行监控,当主机宕机之后会自动切换为从机,宕机的主机恢复之后会成为新主机的从机。
- 一般的主从模式➕哨兵模式如下图,
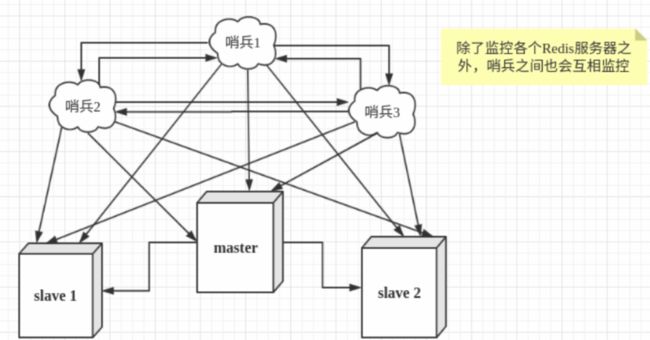
- 优缺点
优点
①哨兵集群,基于主从复制模式 ,所有的主从配置优点,它全有
②主从可以切换,故障可以转移 ,系统的 可用性 就会更好
③哨兵模式就是主从模式的升级,手动到自动,更加健壮!
2、缺点
①Redis 不好在线扩容 的,集群容量一旦到达上限,在线扩容就十分麻烦!
②实现哨兵模式的配置其实是很 麻烦 的,里面有很多选择!
九、redis实现分布式锁
一、概括
在聊分布式锁之前,有必要先解释一下,为什么需要分布式锁。
与分布式锁相对就的是单机锁,我们在写多线程程序时,避免同时操作一个共享变量产生数据问题,通常会使用一把锁来互斥以保证共享变量的正确性,其使用范围是在同一个进程中。如果换做是多个进程,需要同时操作一个共享资源,如何互斥呢?现在的业务应用通常是微服务架构,这也意味着一个应用会部署多个进程,多个进程如果需要修改MySQL中的同一行记录,为了避免操作乱序导致脏数据,此时就需要引入分布式锁了。
想要实现分布式锁,必须借助一个外部系统,所有进程都去这个系统上申请加锁。而这个外部系统,必须要实现互斥能力,即两个请求同时进来,只会给一个进程加锁成功,另一个失败。这个外部系统可以是数据库,也可以是Redis或Zookeeper,但为了追求性能,我们通常会选择使用Redis或Zookeeper来做。
Redis本身可以被多个客户端共享访问,正好就是一个共享存储系统,可以用来保存分布式锁。而且 Redis 的读写性能高,可以应对高并发的锁操作场景。本文主要探讨如何基于Redis实现分布式锁以及实现过程中可能面临的问题。
二、实现方案
- 使用set和nx和ex 以及value为某个线程的唯一标识
-
- 通过nx加锁
- 如果加锁的客户端宕机就会导致锁无法释放,我们可以通过ex设置过期时间
- 为防止其他线程释放掉锁,可以将value设置为自己线程才能识别的值,再释放锁
伪代码如下:
if(jedis.set(key_resource_id, uni_request_id, "NX", "EX", 100s) == 1){ //加锁
try {
do something //业务处理
}catch(){
}
finally {
//判断是不是当前线程加的锁,是才释放
if (uni_request_id.equals(jedis.get(key_resource_id))) {
jedis.del(lockKey); //释放锁
}
}
}
- 上面的分布式锁是单机版的,如果要在集群中保证分布式锁就需要使用redlock
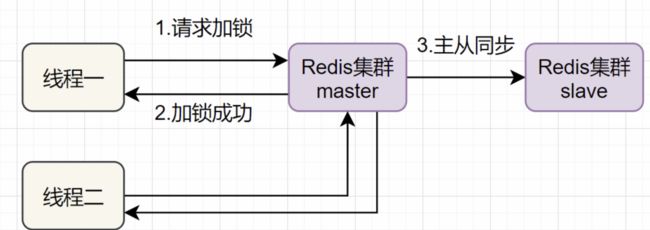
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
Redlock核心思想是这样的:
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
步骤如下:
- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于3个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!