Pytorch入门(3)—— 构造网络模型
- 参考:动手学深度学习
- 注意:由于本文是jupyter文档转换来的,代码不一定可以直接运行,有些注释是jupyter给出的交互结果,而非运行结果!!
文章目录
- 1. 模型构造
-
- 1.1 继承 `Module` 类来构造模型
- 1.2 `Module` 的子类
-
- 1.2.1 `Sequential` 类
- 1.2.2 `ModuleList` 类
- 1.2.3 `ModuleDict` 类
- 1.3 构造复杂模型
- 2. 模型参数的访问、初始化和共享
-
- 2.1 访问模型参数
- 2.2 初始化模型参数
-
- 2.2.1 使用 pytorch 自带的初始化方法
- 2.2.2 自定义初始化方法
- 2.3 共享模型参数
- 3. 自定义层
-
- 3.1 不含模型参数的自定义层
- 3.2 含模型参数的自定义层
1. 模型构造
- pytorch 没有特别明显地区别 Layer 和 Module 的区别,不管是自定义层、自定义块还是自定义模型,都通过
nn.Module类实现,它是所有神经网络模块的基类 - 构造模型时一般有两种选择
- 对于简单的模型,直接使用 pytorch 提供的
nn.Module子类进行构造,比如Sequential、ModuleList和ModuleDict等等 - 对于复杂模型,自己继承
nn.Module,再重新实现构造函数__init__(定义需要学习的层) 和forward方法(定义网络结构),pytorch 会通过自动求梯度功能自动生成反向传播所需的backward函数
- 对于简单的模型,直接使用 pytorch 提供的
1.1 继承 Module 类来构造模型
-
这里构造一个用于 Fashion-MNIST 分类的,含单隐藏层的多层感知机,它的输入尺寸为图像尺寸 28 ∗ 28 = 784 28*28=784 28∗28=784,类别总数为 10,有两个全连接层
- 隐藏层,输出大小为256(即隐藏单元个数是256)
- 输出层,输出大小为10(即输出层单元个数是10)
import torch from torch import nn class MLP(nn.Module): # 声明带有模型参数的层,这里声明了两个全连接层 def __init__(self, **kwargs): super(MLP, self).__init__(**kwargs) self.hidden = nn.Linear(784, 256) # 隐藏层 self.act = nn.ReLU() # 激活函数层 self.output = nn.Linear(256, 10) # 输出层 # 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出 def forward(self, x): x = self.hidden(x) x = self.act(x) # 可以换成 torch.nn.functional.relu(x) x = self.output(x) return x实例化
MLP类得到模型变量net,直接net(X)就会调用MLP继承自Module类的__call__函数,这个函数将调用MLP类定义的forward函数来完成前向计算X = torch.rand(2, 784) net = MLP() print(net) net(X)MLP( (hidden): Linear(in_features=784, out_features=256, bias=True) (act): ReLU() (output): Linear(in_features=256, out_features=10, bias=True) ) tensor([[-0.1948, -0.1288, 0.2227, 0.0308, 0.1528, -0.1716, 0.1353, -0.1180, 0.0011, 0.0678], [-0.1717, 0.0203, 0.2850, 0.0811, 0.1573, -0.1836, 0.1892, -0.0589, -0.0782, 0.0492]], grad_fn=) -
重写
__init__和forward函数的一些技巧__init__传入**kwargs参数用来初始化父类nn.Module,这样在构造实例时还可以指定其他函数参数- 有可学习参数的层(如全连接层、卷积层等)通常放在
__init__ - 没有可学习参数的层(如激活函数、dropout、BatchNormanation层)可以放在
__init__中,也可以在forward方法里用nn.functional代替
1.2 Module 的子类
1.2.1 Sequential 类
-
Sequential接收一个 “子模块的有序字典(OrderedDict)”或者“一系列子模块”作为参数来逐一添加Module的实例,得到模型的forward方法将这些实例按添加的顺序逐一计算,适用于模型的前向计算为简单串联各个层的计算的情况 -
Sequential中的每个层都是Module实例,可以用类似列表的[]索引其中的某层,然后也可以类似上面访问其中参数net = nn.Sequential( nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10), ) print(net) print(net(X)) print(net[0](X))Sequential( (0): Linear(in_features=784, out_features=256, bias=True) (1): ReLU() (2): Linear(in_features=256, out_features=10, bias=True) ) tensor([[ 0.0496, 0.2121, 0.1022, -0.0463, 0.0296, -0.0083, -0.2182, 0.0396, -0.2485, 0.0137], [ 0.0525, 0.1603, 0.1662, -0.0540, -0.0024, 0.0356, -0.2116, 0.0876, -0.1516, 0.0286]], grad_fn=) tensor([[-8.9254e-01, -1.7184e-01, 1.4419e-01, 1.8471e-01, 4.9481e-01, -2.2077e-01, 2.9778e-01, -2.6250e-01, 8.2950e-02, 1.9320e-01, 2.0345e-01, -3.2230e-01, 3.6647e-01, -4.5688e-01, -2.6230e-01, -3.6204e-01, -5.2217e-01, -3.0493e-01, -2.5337e-01, 2.0549e-01, 2.0917e-01, 4.2038e-01, -2.3459e-01, -2.9938e-01, -1.3072e-01, ... -
下面利用 1.1 节继承
Module的方法手动模拟Sequential类from collections import OrderedDict class MySequential(nn.Module): def __init__(self, *args): super(MySequential, self).__init__() # 如果传入的是一个OrderedDict if len(args) == 1 and isinstance(args[0], OrderedDict): for key, module in args[0].items(): self.add_module(key, module) # add_module 方法会将 module 添加进 self._modules (一个OrderedDict) # 传入的是一些 Module else: for idx, module in enumerate(args): self.add_module(str(idx), module) def forward(self, input): # self._modules 返回一个 OrderedDict,保证会按照成员添加时的顺序遍历成员 for module in self._modules.values(): input = module(input) return input net = MySequential( nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10), ) print(net) # 观察网络结构 print(net(X)) # 做一次前向传播MySequential( (0): Linear(in_features=784, out_features=256, bias=True) (1): ReLU() (2): Linear(in_features=256, out_features=10, bias=True) ) tensor([[ 0.1127, -0.1448, 0.0931, -0.0545, -0.1346, -0.0632, -0.1710, 0.0960, 0.0854, 0.0366], [ 0.1646, -0.1410, 0.0664, -0.1529, -0.1392, -0.0145, -0.2894, 0.0927, 0.1357, 0.0438]], grad_fn=)
1.2.2 ModuleList 类
-
ModuleList接收一个子模块的列表作为输入,可以类似 pythonList那样进行append和extend操作,它的出现主要是为了让网络定义forward时更加灵活,见下面官网的例子class MyModule(nn.Module): def __init__(self): super(MyModule, self).__init__() self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)]) def forward(self, x): # ModuleList can act as an iterable, or be indexed using ints for i, l in enumerate(self.linears): x = self.linears[i // 2](x) + l(x) return x -
ModuleList的特点有- 仅仅是一个储存各种模块的列表,这些模块之间没有联系也没有顺序(所以不用保证相邻层的输入输出维度匹配),这和
Sequential类不同 - 没有实现
forward功能,需要自己实现(直接执行会报NotImplementedError)net = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()]) # 输入为模块列表 net.append(nn.Linear(256, 10)) # 类似List的append操作 print(net[-1]) # 类似List的索引访问 print(net) # net(torch.zeros(1, 784)) # 没有实现 forward,做 forward 时报 NotImplementedErrorLinear(in_features=256, out_features=10, bias=True) ModuleList( (0): Linear(in_features=784, out_features=256, bias=True) (1): ReLU() (2): Linear(in_features=256, out_features=10, bias=True) ) - 不同于Python 内置 list,加入到
ModuleList里面的所有模块的参数会被自动添加到整个网络中class Module_ModuleList(nn.Module): def __init__(self): super(Module_ModuleList, self).__init__() self.linears = nn.ModuleList([nn.Linear(10, 10)]) class Module_List(nn.Module): def __init__(self): super(Module_List, self).__init__() self.linears = [nn.Linear(10, 10)] net1 = Module_ModuleList() net2 = Module_List() # 加入到 ModuleList 里面的所有模块的参数被添加到 Module 实例中了 print("net1:") for p in net1.parameters(): print(p.size()) # 加入 python list 中的模块的参数没有添加到 Module 实例中 print("net2:") for p in net2.parameters(): print(p)net1: torch.Size([10, 10]) torch.Size([10]) net2:Note:对得到的
Module类实例调用.parameters()方法,这会返回一个生成器,可以按顺序查看网络的参数(同一层先返回 weight 再返回 bias)。详见下面 2.1 节
- 仅仅是一个储存各种模块的列表,这些模块之间没有联系也没有顺序(所以不用保证相邻层的输入输出维度匹配),这和
1.2.3 ModuleDict 类
ModuleDict也是为了让网络定义forward时更加灵活而出现的,它接受一个子模块的字典作为输入,可以类似 pythonDict那样进行添加访问操作ModuleDict的特点有-
ModuleDict实例也是仅仅存放了一个模块的字典,这些模块之间没有联系也没有顺序 -
不会自动生成
forward方法,需要自己定义(直接执行会报 NotImplementedError)net = nn.ModuleDict({ 'linear': nn.Linear(784, 256), 'act': nn.ReLU(), }) net['output'] = nn.Linear(256, 10) # 类似 python Dict 进行添加 print(net['linear']) # 类型 python Dict 进行访问 print(net.output) # 另一种访问 key 'output' 的方法 print(net) # net(torch.zeros(1, 784)) # 报NotImplementedErrorLinear(in_features=784, out_features=256, bias=True) Linear(in_features=256, out_features=10, bias=True) ModuleDict( (linear): Linear(in_features=784, out_features=256, bias=True) (act): ReLU() (output): Linear(in_features=256, out_features=10, bias=True) ) -
加入到
ModuleDict里面的所有模块的参数会被自动添加到整个网络中,python 内置的 Dict 不会
-
1.3 构造复杂模型
-
本节通过继承
Module类构造一个复杂网络FancyMLP。其中- 通过
requires_grad=False创建训练中不被迭代的参数(i.e. 常数参数) - 使用 Tensor 的函数和 Python 控制流多次调用相同的层
class FancyMLP(nn.Module): def __init__(self, **kwargs): super(FancyMLP, self).__init__(**kwargs) self.rand_weight = torch.rand((20, 20), requires_grad=False) # 不可训练参数(常数参数) self.linear = nn.Linear(20, 20) # 这个线性层参数会被训练 def forward(self, x): x = self.linear(x) # 使用创建的常数参数,以及 nn.functional.relu 和 mm 函数 x = torch.mm(x, self.rand_weight.data) + 1 # +1 用广播作用到每个元素上 x = nn.functional.relu(x) # 复用全连接层。等价于两个全连接层共享参数 x = self.linear(x) # 控制流,这里先用 .norm 得到向量的模,再用 .item 来返回标量进行比较 while x.norm().item() > 1: x /= 2 if x.norm().item() < 0.8: x *= 10 return x.sum() # 打印网络结构,做一次前向传播 X = torch.rand(2, 20) net = FancyMLP() print(net) net(X)FancyMLP( (linear): Linear(in_features=20, out_features=20, bias=True) ) tensor(-0.0572, grad_fn=) - 通过
-
这里定义的
FancyMLP作为Module的子类,可以进一步和Sequential等嵌套使用class NestMLP(nn.Module): def __init__(self, **kwargs): super(NestMLP, self).__init__(**kwargs) self.net = nn.Sequential(nn.Linear(40, 30), nn.ReLU()) def forward(self, x): return self.net(x) # 在自定义 Module 中嵌套使用 Sequential net = nn.Sequential(NestMLP(), nn.Linear(30, 20), FancyMLP()) # 在 Sequential 中嵌套使用自定义 Module X = torch.rand(2, 40) print(net) net(X)Sequential( (0): NestMLP( (net): Sequential( (0): Linear(in_features=40, out_features=30, bias=True) (1): ReLU() ) ) (1): Linear(in_features=30, out_features=20, bias=True) (2): FancyMLP( (linear): Linear(in_features=20, out_features=20, bias=True) ) ) tensor(-0.4674, grad_fn=)
2. 模型参数的访问、初始化和共享
- 先定义一个含单隐藏层的多层感知机,使用默认方式初始化它的参数,并做一次前向计算(jupyter 文档,后面会用到这里定义的
X,Y,net等变量)import torch from torch import nn net = nn.Sequential(nn.Linear(4, 3), nn.ReLU(), nn.Linear(3, 1)) # pytorch已进行默认初始化 print(net) X = torch.rand(2, 4) Y = net(X).sum()
该网络结构如下所示Sequential( (0): Linear(in_features=4, out_features=3, bias=True) (1): ReLU() (2): Linear(in_features=3, out_features=1, bias=True) )
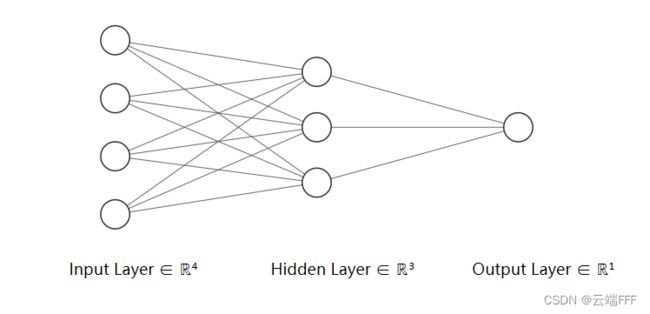
2.1 访问模型参数
-
在 1.2.1 节已经提到过,可以对
Module实例调用.parameters方法得到一个模型参数的生成器,除此以外,还可以调用.named_parameters方法得到一个带名字(含层数前缀)的参数生成器,如下print(type(net.parameters())) for param in net.parameters(): print(param.size()) print('\n', type(net.named_parameters())) for name, param in net.named_parameters(): print(name, param.size())torch.Size([3, 4]) torch.Size([3]) torch.Size([1, 3]) torch.Size([1]) 0.weight torch.Size([3, 4]) 0.bias torch.Size([3]) 2.weight torch.Size([1, 3]) 2.bias torch.Size([1]) -
pytorch 不区分层和模型,用
[]索引出Sequential中的某层,也可以类似上面访问其中参数for name, param in net[0].named_parameters(): print(name, param.size(), type(param))weight torch.Size([3, 4])bias torch.Size([3]) 观察输出可见
- 只有一个层,参数名字中没有层数索引前缀了
- 返回的
param类型为torch.nn.parameter.Parameter,这其实这是Tensor的子类,如果一个Tensor是Parameter,那么它会自动被添加到模型的参数列表里class MyModel(nn.Module): def __init__(self, **kwargs): super(MyModel, self).__init__(**kwargs) self.weight1 = nn.Parameter(torch.rand(20, 20)) # 直接定义成 Parameter 实例,自动加入模型参数列表 self.weight2 = torch.rand(20, 20) # 普通 Tensor 实例不会加入模型参数列表 def forward(self, x): pass n = MyModel() for name, param in n.named_parameters(): print(name) # 只打印 weight1
-
Parameter本质是Tensor,可以做Tensor能做的任何操作,比如用.data访问参数值,用.grad访问参数梯度等# 这里 net 是第2节最开始的多层感知机 weight_0 = list(net[0].parameters())[0] # 拿出第一层的 weight Parameter print(weight_0.data) # 访问参数值 print(weight_0.grad) # 反向传播前梯度为 None Y.backward() # 对 net 进行反向传播 print(weight_0.grad) # 查看反向传播后梯度tensor([[-0.2071, -0.3790, -0.3439, -0.1824], [-0.0715, -0.0847, -0.2867, 0.0100], [ 0.0529, 0.3474, 0.2165, 0.3396]]) None tensor([[ 0.0000, 0.0000, 0.0000, 0.0000], [ 0.0000, 0.0000, 0.0000, 0.0000], [-0.1004, -0.1238, -0.0492, -0.0901]])
2.2 初始化模型参数
-
模型参数初始化是很重要的一件事,考虑第2节最初的含一个隐藏层的神经网络,假设将每个隐藏单元的参数都初始化为相等的值,由于各个单元的激活函数也一致,那么
- 正向传播时每个隐藏单元计算并输出的值都相等
- 反向传播时每个隐藏单元的参数梯度值相等,因此这些参数在使用基于梯度的优化算法迭代后值依然相等。之后的迭代也是如此
可见这种情况下,无论隐藏单元有多少,隐藏层本质上只有1个隐藏单元在发挥作用。因此我们通常将神经网络的模型参数,特别是权重参数,进行随机初始化。
-
pytorch
nn.Module中的模块参数都采取了较为合理的初始化策略,所以其实不考虑初始化问题也是可以的(不同类型的 layer 具体的初始化方式也不同,可以参考源码)。如果一定要用其他方式初始化参数,也有两种途径
2.2.1 使用 pytorch 自带的初始化方法
-
torch.nn.init模块里提供了多种预设初始化方法,以下代码来自 Pytorch - nn.init 参数初始化方法import torch import torch.nn as nn from torch.nn import init w = torch.empty(2, 3) # 1. 均匀分布 - u(a,b) # torch.nn.init.uniform_(tensor, a=0, b=1) nn.init.uniform_(w) # tensor([[ 0.0578, 0.3402, 0.5034], # [ 0.7865, 0.7280, 0.6269]]) # 2. 正态分布 - N(mean, std) # torch.nn.init.normal_(tensor, mean=0, std=1) nn.init.normal_(w) # tensor([[ 0.3326, 0.0171, -0.6745], # [ 0.1669, 0.1747, 0.0472]]) # 3. 常数 - 固定值 val # torch.nn.init.constant_(tensor, val) nn.init.constant_(w, 0.3) # tensor([[ 0.3000, 0.3000, 0.3000], # [ 0.3000, 0.3000, 0.3000]]) # 4. 对角线为 1,其它为 0 # torch.nn.init.eye_(tensor) nn.init.eye_(w) # tensor([[ 1., 0., 0.], # [ 0., 1., 0.]]) # 5. Dirac delta 函数初始化,仅适用于 {3, 4, 5}-维的 torch.Tensor # torch.nn.init.dirac_(tensor) w1 = torch.empty(3, 16, 5, 5) nn.init.dirac_(w1) # 6. xavier_uniform 初始化 # torch.nn.init.xavier_uniform_(tensor, gain=1) # From - Understanding the difficulty of training deep feedforward neural networks - Bengio 2010 nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu')) # tensor([[ 1.3374, 0.7932, -0.0891], # [-1.3363, -0.0206, -0.9346]]) # 7. xavier_normal 初始化 # torch.nn.init.xavier_normal_(tensor, gain=1) nn.init.xavier_normal_(w) # tensor([[-0.1777, 0.6740, 0.1139], # [ 0.3018, -0.2443, 0.6824]]) # 8. kaiming_uniform 初始化 # From - Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification - HeKaiming 2015 # torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu') nn.init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu') # tensor([[ 0.6426, -0.9582, -1.1783], # [-0.0515, -0.4975, 1.3237]]) # 9. kaiming_normal 初始化 # torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu') nn.init.kaiming_normal_(w, mode='fan_out', nonlinearity='relu') # tensor([[ 0.2530, -0.4382, 1.5995], # [ 0.0544, 1.6392, -2.0752]]) # 10. 正交矩阵 - (semi)orthogonal matrix # From - Exact solutions to the nonlinear dynamics of learning in deep linear neural networks - Saxe 2013 # torch.nn.init.orthogonal_(tensor, gain=1) nn.init.orthogonal_(w) # tensor([[ 0.5786, -0.5642, -0.5890], # [-0.7517, -0.0886, -0.6536]]) # 11. 稀疏矩阵 - sparse matrix # 非零元素采用正态分布 N(0, 0.01) 初始化. # From - Deep learning via Hessian-free optimization - Martens 2010 # torch.nn.init.sparse_(tensor, sparsity, std=0.01) nn.init.sparse_(w, sparsity=0.1) # tensor(1.00000e-03 * # [[-0.3382, 1.9501, -1.7761], # [ 0.0000, 0.0000, 0.0000]]) -
下面将权重参数初始化成服从 N ( 0 , 0.0 1 2 ) N(0,0.01^2) N(0,0.012) 的随机数,将偏置初始化为常数
for name, param in net.named_parameters(): if 'weight' in name: init.normal_(param, mean=0, std=0.01) print(name, param.data) if 'bias' in name: init.constant_(param, val=0) print(name, param.data)0.weight tensor([[-0.0171, -0.0112, 0.0001, -0.0026], [ 0.0006, 0.0125, -0.0181, 0.0049], [-0.0083, -0.0032, -0.0037, 0.0103]]) 0.bias tensor([0., 0., 0.]) 2.weight tensor([[ 0.0071, -0.0074, -0.0086]]) 2.bias tensor([0.])
2.2.2 自定义初始化方法
-
如果我们需要的初始化方法没有在
init模块中提供,可以自己手动实现一个初始化方法,从而能够像使用其他初始化方法那样使用它 -
我们先来看看 PyTorch 是怎么实现内置初始化方法的,例如
torch.nn.init.normal_def normal_(tensor, mean=0, std=1): with torch.no_grad(): return tensor.normal_(mean, std)可以看到这就是一个 inplace 改变 Tensor 值的函数,而且这个过程是不记录梯度的。 我们可以类似地实现一个自定义初始化方法。下面我们令权重有一半概率初始化为 0,有另一半概率初始化为 [ − 10 , − 5 ] [−10,−5] [−10,−5] 和 [ 5 , 10 ] [5,10] [5,10] 两个区间里均匀分布的随机数
def init_weight_(tensor): with torch.no_grad(): tensor.uniform_(-10, 10) tensor *= (tensor.abs() >= 5).float() for name, param in net.named_parameters(): if 'weight' in name: init_weight_(param) print(name, param.data)0.weight tensor([[ 0.0000, 0.0000, 0.0000, -0.0000], [-5.3037, 9.3310, 0.0000, 0.0000], [ 0.0000, 7.8593, -0.0000, 0.0000]]) 2.weight tensor([[-6.5195, 0.0000, 0.0000]]) -
另外考虑到
Parameter本质是Tensor,我们还可以通过改变这些参数的.data,在不影响梯度的情况下改写模型参数值for name, param in net.named_parameters(): if 'bias' in name: param.data += 1 print(name, param.data)0.bias tensor([1., 1., 1.]) 2.bias tensor([1.])
2.3 共享模型参数
- 有时我们想在多个层之间共享参数,因为模型参数里包含了梯度,所以在反向传播计算时,这些共享的参数的梯度是累加的
- 有两种共享参数的方法
-
在
Module的forward方法中多次调用同一个层class SharePara(nn.Module): def __init__(self, **kwargs): super(SharePara, self).__init__(**kwargs) self.linear = nn.Linear(1, 1, bias=False) def forward(self, x): x = self.linear(x) x = self.linear(x) return x net = SharePara() print(net) for name, param in net.named_parameters(): init.constant_(param, val=3) print(name, param.data)SharePara( (linear): Linear(in_features=1, out_features=1, bias=False) ) linear.weight tensor([[3.]])x = torch.ones(3,1) print(net(x)) y = net(x).sum() print(y) y.backward() print(net.linear.weight.grad) # 单次梯度是3,每个样本算两次为6,三个样本一共18tensor([[9.], [9.], [9.]], grad_fn=) tensor(27., grad_fn= ) tensor([[18.]]) -
将同一个
Module实例多次传入Sequential模块linear = nn.Linear(1, 1, bias=False) net = nn.Sequential(linear, linear) print(net) for name, param in net.named_parameters(): init.constant_(param, val=3) print(name, param.data)Sequential( (0): Linear(in_features=1, out_features=1, bias=False) (1): Linear(in_features=1, out_features=1, bias=False) ) 0.weight tensor([[3.]])x = torch.ones(3,1) print(net(x)) y = net(x).sum() print(y) y.backward() print(net[0].weight.grad) # 单次梯度是3,每个样本算两次为6,三个样本一共18tensor([[9.], [9.], [9.]], grad_fn=) tensor(27., grad_fn= ) tensor([[18.]])
-
3. 自定义层
- 现代术语“深度学习”诉诸于学习多层次组合这一普遍原理。理论上讲,“宽度学习”(使用足够宽的单隐藏层神经网络)也能拟合任何形状的目标函数,但是其需要的参数量要远多于将神经元进行层次组合的“深度学习”。“深度学习”的模型表示更加“高效”,这样模型复杂度就可以相对低,在不发生过拟合的前提下,尽量减少对数据量的要求
- pytorch 中不区分“层”、“块”和“模型”,都统一用
nn.Module库实现
3.1 不含模型参数的自定义层
-
如果一个层中不含可训练参数,比如 ReLU、dropout、BatchNormanation 等,则它和之前 1.1 节定义的模型类似,可以通过继承
nn.Module类并重写__init__和forward函数来实现。下面的CenteredLayer自定义了一个将输入减掉均值后输出的层,层的计算定义在forward函数里,该层不含模型参数import torch from torch import nn class CenteredLayer(nn.Module): def __init__(self, **kwargs): super(CenteredLayer, self).__init__(**kwargs) def forward(self, x): return x - x.mean() layer = CenteredLayer() layer(torch.tensor([1, 2, 3, 4, 5], dtype=torch.float))tensor([-2., -1., 0., 1., 2.]) -
自定义层可以和其他层、块等混合使用,构造更复杂的模型
net = nn.Sequential(nn.Linear(8, 128), CenteredLayer()) y = net(torch.rand(4, 8)) y.mean().item() # 返回 1.862645149230957e-09,加上 CenteredLayer 后输出小了好几个数量级
3.2 含模型参数的自定义层
-
2.1.1 节已经介绍了
Tensor的子类Parameter,如果一个Tensor是Parameter,那么它会自动被添加到模型的参数列表里,所以在自定义含模型参数的层时,我们应该将参数定义成Parameter。具体来说有三种定义方法-
直接像 2.1.1 节一样将参数定义为
Parameter类的实例,如self.weight1 = nn.Parameter(torch.rand(20, 20)) -
使用
ParameterList定义参数的列表。它接收一个Parameter实例列表作为输入,得到一个ParameterList实例,使用的时候可以用索引来访问某个参数,也可像 python list 一样使用append和extend在列表后面新增参数class MyListDense(nn.Module): def __init__(self): super(MyListDense, self).__init__() self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)]) # 有三个 Parameter 实例的 ParameterList self.params.append(nn.Parameter(torch.randn(4, 1))) # 再添加一个 Parameter 实例 def forward(self, x): for i in range(len(self.params)): x = torch.mm(x, self.params[i]) return x net = MyListDense() print(net)MyListDense( (params): ParameterList( (0): Parameter containing: [torch.FloatTensor of size 4x4] (1): Parameter containing: [torch.FloatTensor of size 4x4] (2): Parameter containing: [torch.FloatTensor of size 4x4] (3): Parameter containing: [torch.FloatTensor of size 4x1] ) ) -
使用
ParameterDict定义参数的字典。它接收一个Parameter实例的字典作为输入,得到一个ParameterDict实例,使用时可以按照字典的规则使用了,如使用update()新增参数,使用keys()返回所有键值,使用items()返回所有键值对等等。详见 官方文档class MyDictDense(nn.Module): def __init__(self): super(MyDictDense, self).__init__() self.params = nn.ParameterDict({ 'linear1': nn.Parameter(torch.randn(4, 4)), 'linear2': nn.Parameter(torch.randn(4, 1)) }) # 有两个 Parameter 实例的 ParameterDict self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))}) # 新增 def forward(self, x, choice='linear1'): return torch.mm(x, self.params[choice]) net = MyDictDense() print(net) print('\n可以根据键值选择层进行前向传播') x = torch.ones(1, 4) print(net(x, 'linear1')) print(net(x, 'linear2')) print(net(x, 'linear3'))MyDictDense( (params): ParameterDict( (linear1): Parameter containing: [torch.FloatTensor of size 4x4] (linear2): Parameter containing: [torch.FloatTensor of size 4x1] (linear3): Parameter containing: [torch.FloatTensor of size 4x2] ) ) 可以根据键值选择层进行前向传播 tensor([[-1.3125, 3.8159, 2.0206, 0.2005]], grad_fn=) tensor([[-0.2396]], grad_fn= ) tensor([[-0.3586, -1.7440]], grad_fn= )
-
-
自定义层可以和其他层、块等混合使用,构造更复杂的模型
net = nn.Sequential( MyDictDense(), MyListDense(), ) print(net) print(net(x))Sequential( (0): MyDictDense( (params): ParameterDict( (linear1): Parameter containing: [torch.FloatTensor of size 4x4] (linear2): Parameter containing: [torch.FloatTensor of size 4x1] (linear3): Parameter containing: [torch.FloatTensor of size 4x2] ) ) (1): MyListDense( (params): ParameterList( (0): Parameter containing: [torch.FloatTensor of size 4x4] (1): Parameter containing: [torch.FloatTensor of size 4x4] (2): Parameter containing: [torch.FloatTensor of size 4x4] (3): Parameter containing: [torch.FloatTensor of size 4x1] ) ) ) tensor([[-7.0746]], grad_fn=)