【GCN-RS】对比学习SGL:Self-supervised Graph Learning for Recommendation (SIGIR‘21)
Self-supervised Graph Learning for Recommendation (SIGIR‘21)
还是何向南组提出的图自监督学习框架,对用户-物品的二部图上的节点、边做dropout等方法实现数据增强,产生许多子视图,在多个子视图上进行对比学习,实现自监督。再配合监督学习,多任务学习。
作者提出的图自监督学习框架SGL可以改善长尾、提高鲁棒。SGL只是一个框架,里面的图表示学习方法可以用LightGCN等。
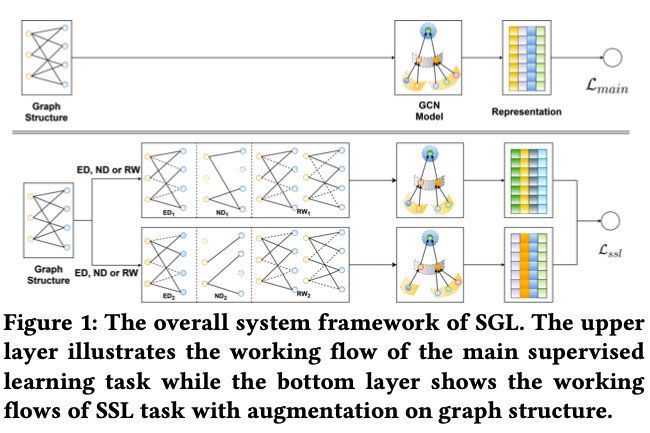
数据增强
一般GNN对节点编码的方式:
Z 1 ( l ) = H ( Z 1 ( l − 1 ) , G ) \boldsymbol{Z}_{1}^{(l)}=H\left(\boldsymbol{Z}_{1}^{(l-1)}, \mathcal{G}\right) Z1(l)=H(Z1(l−1),G)
在本文里需要对原图 G \mathcal{G} G做两次增强操作 s 1 , s 2 s_1,s_2 s1,s2,形成两个不同的子图 s 1 ( G ) s_1(\mathcal{G}) s1(G), s 2 ( G ) s_2(\mathcal{G}) s2(G)。再各自进行图卷积操作形成节点的表征 Z 1 ( l ) , Z 2 ( l ) \boldsymbol{Z}_{1}^{(l)}, \boldsymbol{Z}_{2}^{(l)} Z1(l),Z2(l):
Z 1 ( l ) = H ( Z 1 ( l − 1 ) , s 1 ( G ) ) , Z 2 ( l ) = H ( Z 2 ( l − 1 ) , s 2 ( G ) ) , s 1 , s 2 ∼ S \mathbf{Z}_{1}^{(l)}=H\left(\mathbf{Z}_{1}^{(l-1)}, s_{1}(\mathcal{G})\right), \mathbf{Z}_{2}^{(l)}=H\left(\mathbf{Z}_{2}^{(l-1)}, s_{2}(\mathcal{G})\right), s_{1}, s_{2} \sim \mathcal{S} Z1(l)=H(Z1(l−1),s1(G)),Z2(l)=H(Z2(l−1),s2(G)),s1,s2∼S
具体的数据增强操作包括以下三种:
Node Dropout (ND)
以一定概率 ρ \rho ρ 丢掉结点以及该结点相连的边:
s 1 ( G ) = ( M ′ ⊙ V , E ) , s 2 ( G ) = ( M ′ ′ ⊙ V , E ) s_{1}(\mathcal{G})=\left(\mathbf{M}^{\prime} \odot \mathcal{V}, \mathcal{E}\right), \quad s_{2}(\mathcal{G})=\left(\mathbf{M}^{\prime \prime} \odot \mathcal{V}, \mathcal{E}\right) s1(G)=(M′⊙V,E),s2(G)=(M′′⊙V,E)
其中 M ′ , M ′ ′ ∈ 0 , 1 ∣ V ∣ \mathbf{M}^{\prime},\mathbf{M}^{\prime \prime} \in 0,1 ^{|\mathcal{V}|} M′,M′′∈0,1∣V∣是mask向量,通过伯努利分布 m ∼ B e r n o u l l i ( ρ ) m∼Bernoulli(ρ) m∼Bernoulli(ρ)来随机产生, M ′ , M ′ ′ \mathbf{M}^{\prime},\mathbf{M}^{\prime \prime} M′,M′′完全独立。
Edge Dropout (ED)
以一定概率 ρ \rho ρ 丢掉部分边:
s 1 ( G ) = ( V , M 1 ⊙ E ) , s 2 ( G ) = ( V , M 2 ⊙ E ) s_{1}(\mathcal{G})=\left( \mathcal{V}, \mathbf{M}_1 \odot\mathcal{E}\right), \quad s_{2}(\mathcal{G})=\left( \mathcal{V}, \mathbf{M}_2 \odot\mathcal{E}\right) s1(G)=(V,M1⊙E),s2(G)=(V,M2⊙E)
其中 M 1 , M 2 ∈ 0 , 1 ∣ E ∣ \mathbf{M}_1,\mathbf{M}_2 \in 0,1 ^{|\mathcal{E}|} M1,M2∈0,1∣E∣,这里类似Node Dropout。
Random Walk (RW)
前两种子视图在不同卷积层中是共享的,即不同层之间面对的子视图是一样的。random walk想要产生layer-aware的子视图,即不同卷积层面对的子图结构是不同的。实现方法是针对不同卷积层都随机生成不同的mask向量,每一层dropout掉不同的边,从而实现了每一层的随机游走,示例如下图:
s 1 ( G ) = ( V , M 1 ( l ) ⊙ E ) , s 2 ( G ) = ( V , M 2 ( l ) ⊙ E ) s_{1}(\mathcal{G})=\left( \mathcal{V}, \mathbf{M}_1^{(l)} \odot\mathcal{E}\right), \quad s_{2}(\mathcal{G})=\left( \mathcal{V}, \mathbf{M}_2^{(l)} \odot\mathcal{E}\right) s1(G)=(V,M1(l)⊙E),s2(G)=(V,M2(l)⊙E)
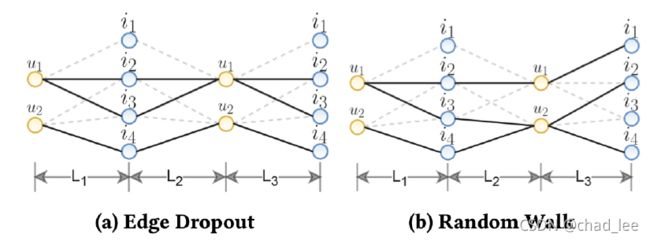
到此为止我们看到,对数据做增强没有引入任何训练参数。
对比学习
同一个结点在不同视图下,可以产生不同的表征向量。作者将同一结点不同视图下的表征看成一对正样本,即 ( z u ′ , z u ′ ′ ) ∣ u ∈ U (z_u^{\prime},z_u^{\prime\prime})|u \in \mathcal{U} (zu′,zu′′)∣u∈U,不同的结点的表征当作负样本 ( z u ′ , z v ′ ′ ) ∣ u , v ∈ U , u ≠ v (z_u^{\prime},z_v^{\prime\prime})|u,v \in \mathcal{U}, u\neq v (zu′,zv′′)∣u,v∈U,u=v 。
对比学习的目标期望最大化同一结点不同视图表征向量之间的相似性,最小化不同结点表征之间的相似性:
L s s l u s e r = ∑ u ∈ U − log exp ( s ( z u ′ , z u ′ ′ ) / τ ) ∑ v ∈ U exp ( s ( z u ′ , z v ′ ′ ) / τ ) \mathcal{L}_{s s l}^{u s e r}=\sum_{u \in \mathcal{U}}-\log \frac{\exp \left(s\left(\mathbf{z}_{u}^{\prime}, \mathbf{z}_{u}^{\prime \prime}\right) / \tau\right)}{\sum_{v \in \mathcal{U}} \exp \left(s\left(\mathbf{z}_{u}^{\prime}, \mathbf{z}_{v}^{\prime \prime}\right) / \tau\right)} Lssluser=u∈U∑−log∑v∈Uexp(s(zu′,zv′′)/τ)exp(s(zu′,zu′′)/τ)
其中 s s s是相似性函数,作者采用的是cosine, τ \tau τ是温度参数。item侧和user侧是对称的。则最终的自监督学习损失函数为:
L s s l = L s s l u s e r + L s s l i t e m \mathcal{L}_{ssl} = \mathcal{L}_{ssl}^{user} + \mathcal{L}_{ssl}^{item} Lssl=Lssluser+Lsslitem
Multi-task Training
和推荐系统常用的BPR-pairwise损失函数 L m a i n \mathcal{L}_main Lmain结合起来联合训练:
L = L m a i n + λ 1 L s s l + λ 2 ∣ ∣ Θ ∣ ∣ 2 2 \mathcal{L} = \mathcal{L}_{main}+\lambda_1\mathcal{L}_{ssl} + \lambda_2||Θ||_2^2 L=Lmain+λ1Lssl+λ2∣∣Θ∣∣22
SGL框架没有引入任何学习参数。
性能
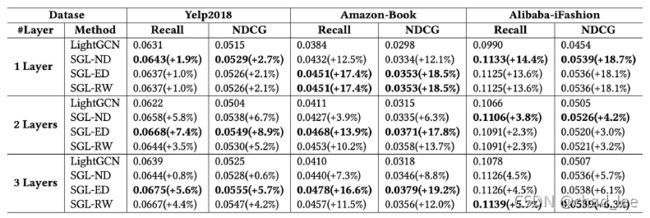
实验效果上强过SOTA LightGCN:
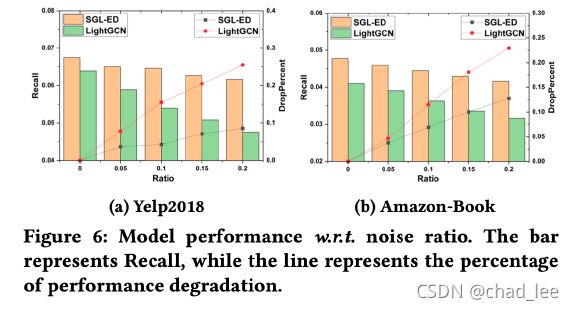
鲁棒性强,能够从数据结构中学出有用的pattern,而不是仅仅依靠重要的结点和边,从而抵抗噪声干扰: