XSimGCL: Towards Extremely Simple GraphContrastive Learning for Recommendation 论文+代码解读
趁热打铁接着上篇继续干,上一篇提到在对比学习中图的增强只起次要作用。优化CL损失可以得到更均匀的表示分布,通过在表示中加入有向随机噪声,进行不同的数据增强和对比,提出的方法显著提高了推荐能力。
SimGCL:Are Graph Augmentations Necessary? Simple GraphContrastive Learning for Recommendation 论文代码解读_只想做个咸鱼的博客-CSDN博客
一、前言
这一篇是上一篇的延续,更进一步简化,大致差不多,细节做了更好的改进

我们提出了一种非常简单的图对比学习方法(XSimGCL)作为推荐,该方法摒弃了无效的图增强,而是使用一种简单而有效的基于噪声的嵌入增强来为CL创建视图。
1、介绍
由于CL从未标记的原始数据中学习一般特征的能力是解决数据稀疏性问题的一颗子弹,因此它也推动了推荐的前沿。它主要包括两个步骤:首先用结构扰动(例如,边缘/节点以一定比率丢失)增强原始用户项二部图,然后在联合学习框架下最大化从不同图形增强中学习的表示的一致性

问题1:基于CL的推荐模型真的需要图形增强吗?
联合优化的对比度损失InfoNCE才是真正重要的,而比图形增强更重要。优化这种对比度损失总是会导致更均匀地分布用户/项目表示,而不考虑图形的增强,这会隐式地减轻普遍流行的偏见,并促进长尾项目。
问题2:是否有更有效和高效的增强方法?
SimGCL它放弃了无效的图形增强,而是向学习的表示添加统一的噪声,以实现更高效的表示级别数据增强。这种基于噪声的增强可以直接将嵌入空间正则化为更均匀的表示分布。同时,通过调整噪声的大小,SimGCL可以平滑地调整表示的一致性。得益于这些特点,SimGCL在推荐准确性和培训效率方面均优于基于图形增强的同类产品。
可以得出两个结论:
(1)图形增强确实有效,但没有预期的有效;性能提升的很大一部分来自对比度损失InfoNCE,这可以解释为什么在即使是非常稀疏的图形增强也能提供信息;
(2) 并非所有的图形增强都有积极的影响;要挑选出有用的,需要经过长时间的反复试验。可能的原因是某些图形增强会严重扭曲原始图形。例如,节点丢失很可能会丢失关键节点(例如hub)及其关联边,从而将相关子图分解为不连续的片段。
这样的图扩充与原始图几乎没有可学习的不变性,因此鼓励它们之间的一致性是不合理的。
2、提出SimGCL的不足
核心部分来了,将右侧对比直接合并到左侧,使结构更简单!!!
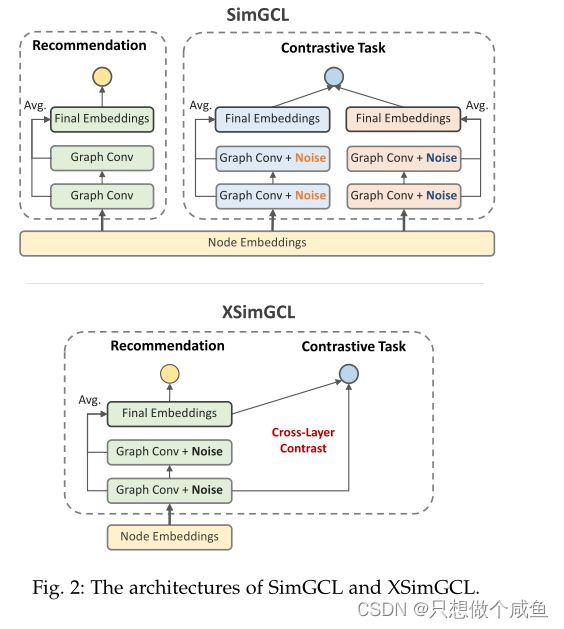
SimGCL的繁琐架构使其不够完美。除了推荐任务的向前/向后传递外,还需要对小批量对比任务进行两次额外的向前/反向传递
这项工作中,提出了一种非常简单的图形对比学习方法(XSimGCL)供推荐。
XSimGCL不仅继承了SimGCL基于噪声的增强,而且通过简化传播过程大大降低了计算复杂性。如图2所示,XSimGCL的推荐任务和对比任务在一个小批量中共享正向/反向传播,而不是拥有单独的管道。具体来说,SimGCL和XSimGCL都使用相同的输入:初始嵌入和邻接矩阵。
不同之处在于SimGCL对比了所学的两种最终表示,使用不同的噪声并依赖于普通表示进行推荐,而XSimGCL对两个任务使用相同的扰动表示,并用跨层对比替换SimGCL中的最终层对比。
二、对比推荐与图形增强
(下面这部分还是那些CL的过往,以及表示方法,看了前几个博客,可直接跳过)
1、传统的CL
他们假设对部分结构扰动保持不变的学习表示是高质量的。我们针对一种具有代表性的基于CL的推荐模型SGL,它执行节点/边缘丢失以增加用户项目图。SGL的联合学习计划制定如下:
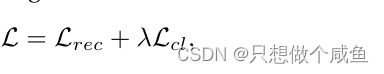
前面的就是我们常用的BPR损失了
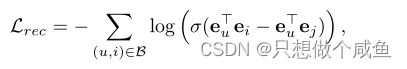
后面的是InfoNCE损失了,CL任务起着辅助作用,其效果由超参数λ调节
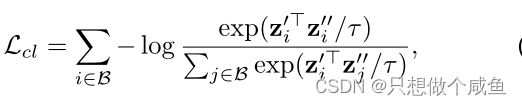
其中i和j是批次B中的用户/项目,![]() 和
和![]() 是从两种不同的基于丢包的图形增强学习到的L2规范化表示(F.normalize),而τ>0(例如0.2)是控制样本惩罚强度的温度。InfoNCE的损失鼓励了
是从两种不同的基于丢包的图形增强学习到的L2规范化表示(F.normalize),而τ>0(例如0.2)是控制样本惩罚强度的温度。InfoNCE的损失鼓励了 ![]() 和
和![]() 之间的一致性,它们是彼此的正样本,同时将
之间的一致性,它们是彼此的正样本,同时将 ![]() 和
和![]() 之间的一致性最小化,它们是相互的负样本。优化InfoNCE损失实际上是最大限度地降低相互信息的下限。
之间的一致性最小化,它们是相互的负样本。优化InfoNCE损失实际上是最大限度地降低相互信息的下限。
SGL使用LightGCN[28]作为其编码器,其消息传递过程定义为:
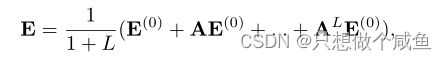
2、特征/密度估计之间的明显对比
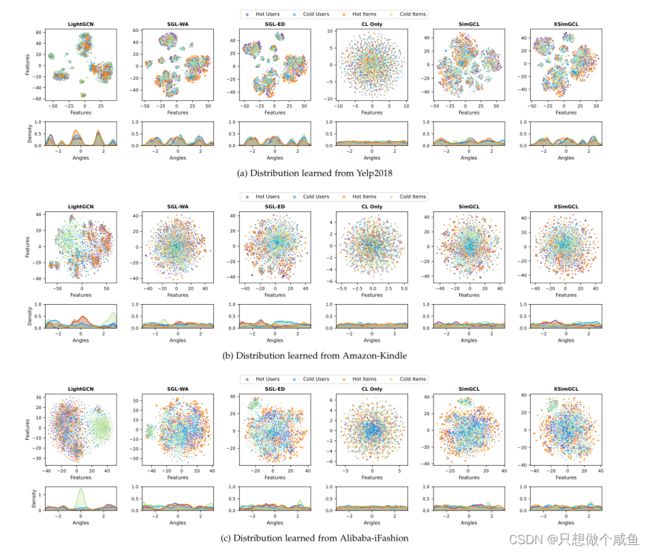
从上图可以观察到LightGCN和基于CL的推荐模型所获得的特征/密度估计之间的明显对比。在最左侧的列中,LightGCN学习高度聚集的特征,密度曲线具有陡峭的上升和下降。此外,很容易注意到,热用户和热物品的分布相似,冷用户也会紧贴热物品;只有少数用户分散在冷物品中。从技术上讲,这是一种有偏见的模式,它将导致模型不断向大多数用户公开热门项目,并生成常规建议。
我们认为,这两个问题可能会导致这种偏颇的分布。
一个是在推荐系统中,一小部分项目通常会导致大多数交互,
另一个是臭名昭著的过度平滑问题,它使嵌入变得局部相似,从而加剧了马太效应。
相比之下,在第二列和第三列中,SGL变体学习的特征分布更均匀,密度估计曲线也不那么清晰,无论是否应用了图形增强。作为参考,在第四列中,我们仅通过优化SGL-ED中的InfoNCE损失来绘制所学的特性。如果没有Lrec的影响,特征几乎服从均匀分布。
学习到的分布的均匀性增加是性能提高的真正原因。它隐式地减轻了流行偏见并促进了长尾项,因为更均匀的分布表示可以保留节点的固有特性并提高泛化能力。这也可以证明SGL-WA具有出乎意料的显著性能。最后,还应指出,均匀性和性能之间的正相关仅在有限范围内保持。过分追求一致性会削弱推荐损失对对齐交互对和类似用户/项目的影响,从而降低推荐性能。
3、统一才是真正重要的
揭示了对比损失InfoNCE是关键。InfoNCE损失的预训练强化了两个特性:
正对特征的对齐,以及单位超球面上标准化特征分布的一致性。
优化CL损失实际上是为了最小化不同节点表示之间的余弦相似性,这将使不同节点彼此远离
三、极简对比学习
1、基于噪声的增强
基于上述发现,我们推测,通过在一定范围内调整学习表征的一致性,对比推荐模型可以达到更好的性能。由于操纵图形结构以实现可控均匀性是困难且耗时的,因此我们将注意力转移到嵌入空间。受通过向图像中添加不可察觉的扰动构造的对抗性示例[36]的启发,我们建议直接向表示中添加随机噪声,以实现有效的增强。

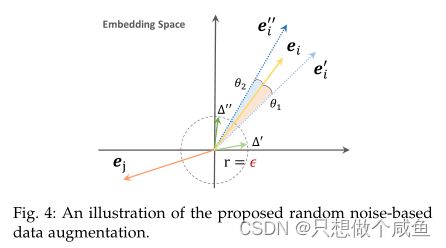
通过将缩放的噪声矢量添加到ei,我们可其旋转两个小角度(图4中所示的θ1和θ2)。每个旋转对应于ei的偏差,并生成一个增强表示(![]() 和
和![]() )。由于旋转足够小,增强表示保留了原始表示的大部分信息,同时也带来了一些差异。特别是,我们也希望学习到的表示能够在整个嵌入空间中展开,以便充分利用空间的表达能力。Zhang等人证明了均匀分布具有这种性质。然后我们选择从均匀分布中产生噪声。虽然用这种方法使所学分布近似均匀分布在技术上很困难,但它可以从统计上为增强带来一致性的暗示。
)。由于旋转足够小,增强表示保留了原始表示的大部分信息,同时也带来了一些差异。特别是,我们也希望学习到的表示能够在整个嵌入空间中展开,以便充分利用空间的表达能力。Zhang等人证明了均匀分布具有这种性质。然后我们选择从均匀分布中产生噪声。虽然用这种方法使所学分布近似均匀分布在技术上很困难,但它可以从统计上为增强带来一致性的暗示。
2、极简对比学习模型

新体系结构在小型批处理计算中只有一次向前/向后传递。我们将这种新方法命名为XSimGCL,它是极简单图形对比学习的缩写。XSimGCL的联合损失公式为:
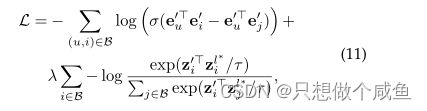
这里 ![]() 表示与最终层对比的层。对比两个中间层是可选的,实验表明,涉及最后一层可获得最佳性能
表示与最终层对比的层。对比两个中间层是可选的,实验表明,涉及最后一层可获得最佳性能
在XSimGCL中,我们可以通过更改 的值来明确控制扩展表示与原始表示的偏差程度。直觉上,一个更大的将导致更统一的表示分布。这是因为在优化对比度损失时,添加的噪声也会作为梯度的一部分传播。由于噪声是从均匀分布中采样的,原始表示被大致地正则化为更高的均匀性。我们进行了以下实验来证明它。
的值来明确控制扩展表示与原始表示的偏差程度。直觉上,一个更大的将导致更统一的表示分布。这是因为在优化对比度损失时,添加的噪声也会作为梯度的一部分传播。由于噪声是从均匀分布中采样的,原始表示被大致地正则化为更高的均匀性。我们进行了以下实验来证明它。
核心还是下面的这个图:
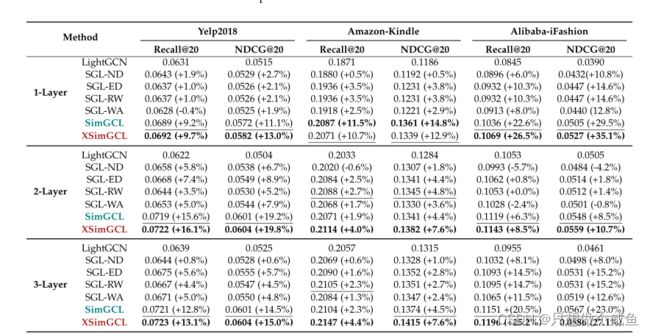
实验结果
四、pytorch代码
1、数据集介绍
模型实现:
def forward(self, perturbed=False):
ego_embeddings = torch.cat([self.embedding_dict['user_emb'], self.embedding_dict['item_emb']], 0) #7297*64
all_embeddings = []
all_embeddings_cl = ego_embeddings
for k in range(self.n_layers):
ego_embeddings = torch.sparse.mm(self.sparse_norm_adj, ego_embeddings)#7297*64
if perturbed:
#2random_noise = torch.rand_like(ego_embeddings).cuda()
random_noise = torch.rand_like(ego_embeddings)
ego_embeddings += torch.sign(ego_embeddings) * F.normalize(random_noise, dim=-1) * self.eps
all_embeddings.append(ego_embeddings) #list 2
if k==self.layer_cl-1: #存储第一次聚合的加噪声embedding
all_embeddings_cl = ego_embeddings
final_embeddings = torch.stack(all_embeddings, dim=1) #7297*2*64
final_embeddings = torch.mean(final_embeddings, dim=1) #7297*64
user_all_embeddings, item_all_embeddings = torch.split(final_embeddings, [self.data.user_num, self.data.item_num]) #得到加噪声的 embedding聚合结果(final embed)
user_all_embeddings_cl, item_all_embeddings_cl = torch.split(all_embeddings_cl, [self.data.user_num, self.data.item_num]) #得到加噪声的 第一层embedding聚合结果(first embed)
if perturbed:
return user_all_embeddings, item_all_embeddings,user_all_embeddings_cl, item_all_embeddings_cl
return user_all_embeddings, item_all_embeddings先BPR损失函数过一下
rec_user_emb, rec_item_emb, cl_user_emb, cl_item_emb = model(True)
user_emb, pos_item_emb, neg_item_emb = rec_user_emb[user_idx], rec_item_emb[pos_idx], rec_item_emb[neg_idx]
rec_loss = bpr_loss(user_emb, pos_item_emb, neg_item_emb)def bpr_loss(user_emb, pos_item_emb, neg_item_emb):
pos_score = torch.mul(user_emb, pos_item_emb).sum(dim=1) #2048
neg_score = torch.mul(user_emb, neg_item_emb).sum(dim=1) # 2048
loss = -torch.log(10e-8 + torch.sigmoid(pos_score - neg_score))# 2048
return torch.mean(loss)然后InfoNCE损失函数
cl_loss = self.cl_rate * self.cal_cl_loss([user_idx,pos_idx],rec_user_emb,cl_user_emb,rec_item_emb,cl_item_emb) def cal_cl_loss(self, idx, user_view1,user_view2,item_view1,item_view2): # xx rec_user cl_user rec_item cl_item
#u_idx = torch.unique(torch.Tensor(idx[0]).type(torch.long)).cuda()
#i_idx = torch.unique(torch.Tensor(idx[1]).type(torch.long)).cuda()
u_idx = torch.unique(torch.Tensor(idx[0]).type(torch.long))
i_idx = torch.unique(torch.Tensor(idx[1]).type(torch.long))
user_cl_loss = InfoNCE(user_view1[u_idx], user_view2[u_idx], self.temp)
item_cl_loss = InfoNCE(item_view1[i_idx], item_view2[i_idx], self.temp)
return user_cl_loss + item_cl_loss
def InfoNCE(view1, view2, temperature):
view1, view2 = F.normalize(view1, dim=1), F.normalize(view2, dim=1) # 标准化 第一个加了干扰的 eu1 第二个加了干扰的eu2
pos_score = (view1 * view2).sum(dim=-1) #1563
pos_score = torch.exp(pos_score / temperature) #分子
ttl_score = torch.matmul(view1, view2.transpose(0, 1))
ttl_score = torch.exp(ttl_score / temperature).sum(dim=1) # 分母 1563
cl_loss = -torch.log(pos_score / ttl_score) #1563
return torch.mean(cl_loss)batch_loss = rec_loss + l2_reg_loss(self.reg, user_emb, pos_item_emb) + cl_loss总结
重新访问了推荐中的图CL,并研究了它如何增强图推荐模型。令人惊讶的是,InfoNCE的损失是决定性能提高的主要因素,而精心设计的图形增强仅起到次要作用。优化InfoNCE损失会导致更均匀的代表分布,这有助于在推荐场景中推广长尾项目。有效的基于噪声的增强方法,可以通过CL平滑地调整表示分布的均匀性。还提出了一个极其简单的模型XSimGCL,为基于CL的推荐提供了一个超轻架构。